Présentation de l'optimisation prédictive : des requêtes plus rapides, un stockage moins cher, sans effort
par Sirui Sun, Vijayan Prabhakaran, Naga Raju Bhanoori, Rajesh Parangi Sharabhalingappa, Jintian Liang, Kam Cheung Ting, Vivek Narasimhan, Sunitha Beeram, Himanshu Raja, Rahul Potharaju, Reynold Xin, Matei Zaharia et Susan Pierce
Nous sommes ravis d'annoncer la préversion publique de Databricks Predictive Optimization. Cette fonctionnalité optimise intelligemment le Layout des données de vos tables pour améliorer les performances et la rentabilité.
L'optimisation prédictive s'appuie sur Unity Catalog et Lakehouse AI pour déterminer les meilleures optimisations à effectuer sur vos données, puis exécute ces opérations sur une infrastructure serverless spécialement conçue. Cela simplifie considérablement votre parcours sur le lakehouse, ce qui vous libère du temps pour vous concentrer sur la création de valeur commerciale à partir de vos données.
Cette fonctionnalité est la dernière d'une longue série de fonctionnalités Databricks qui exploitent l'IA pour effectuer des actions de manière prédictive en fonction de vos données et de leurs modèles d'accès. Précédemment, nous avons publié les I/O prédictives pour les lectures et les mises à jour, qui appliquent ces techniques lors de l'exécution de queries de lecture et de mise à jour.
Défis
Les tables Lakehouse bénéficient grandement des optimisations en arrière-plan qui améliorent le Layout de leurs données. Cela inclut le compactage des fichiers pour garantir des tailles de fichier adéquates, ou le vacuum pour supprimer les fichiers de données inutiles. Une optimisation appropriée améliore considérablement les performances tout en réduisant les coûts.
Cependant, cela représente un défi permanent pour les équipes d'ingénierie des données, qui doivent déterminer :
- Quelles optimisations exécuter ?
- Quelles tables doivent être optimisées ?
- À quelle fréquence faut-il exécuter ces optimisations ?
Alors que les plateformes lakehouse montent en charge et deviennent de plus en plus en libre-service, il est pratiquement impossible pour les équipes de plateforme de répondre efficacement à ces questions. Un sentiment que nos clients nous expriment souvent est qu'ils n'arrivent pas à optimiser le nombre de tables créées pour tous les nouveaux cas d'usage métier.
En outre, même une fois que des réponses ont été apportées à ces questions épineuses, les équipes doivent encore gérer la charge opérationnelle de la planification et de l'exécution de ces optimisations, par exemple la planification des Jobs, le diagnostic des pannes et la gestion de l'infrastructure sous-jacente.
Fonctionnement de l'Optimisation prédictive
Avec l'Optimisation prédictive, Databricks s'attaque pour vous à ces problèmes épineux, vous libérant ainsi un temps précieux pour vous concentrer sur la création de valeur commerciale à partir de vos données. L'Optimisation prédictive peut être activée en un seul clic. À partir de là, il fait tout le gros du travail.

Tout d'abord, l'Optimisation prédictive détermine intelligemment les optimisations à exécuter et leur fréquence. Notre modèle d'IA prend en compte un large éventail d'entrées, y compris les schémas d'utilisation de vos tables, leur layout de données existantes et leurs caractéristiques de performance. Elle produit ensuite le calendrier d'optimisation idéal, en soupesant les avantages attendus de l'optimisation par rapport aux coûts de compute prévus.
Une fois le programme généré, l'Optimisation prédictive exécute automatiquement ces optimisations sur l'infrastructure serverless spécialement conçue. Il gère automatiquement le lancement du nombre et de la taille corrects des machines, et s'assure que les tâches d'optimisation sont correctement regroupées et planifiées pour une efficacité optimale.
L'ensemble du système fonctionne de bout en bout sans qu'il soit nécessaire de procéder à des ajustements et à des réglages manuels, et il apprend de l'utilisation de votre organisation au fil du temps, optimisant les tables importantes pour votre organisation tout en dépriorisant celles qui ne le sont pas. Seul le compute sans serveur nécessaire pour effectuer les optimisations vous est facturé. Par défaut, toutes les opérations sont consignées dans une table système, afin que vous puissiez facilement auditer et comprendre leur impact et leur coût.
Impact
Au cours des derniers mois, nous avons inscrit un certain nombre de clients au programme d'aperçu privé de Predictive Optimization. Beaucoup ont observé qu'il est capable de trouver le juste milieu entre deux extrêmes courants :
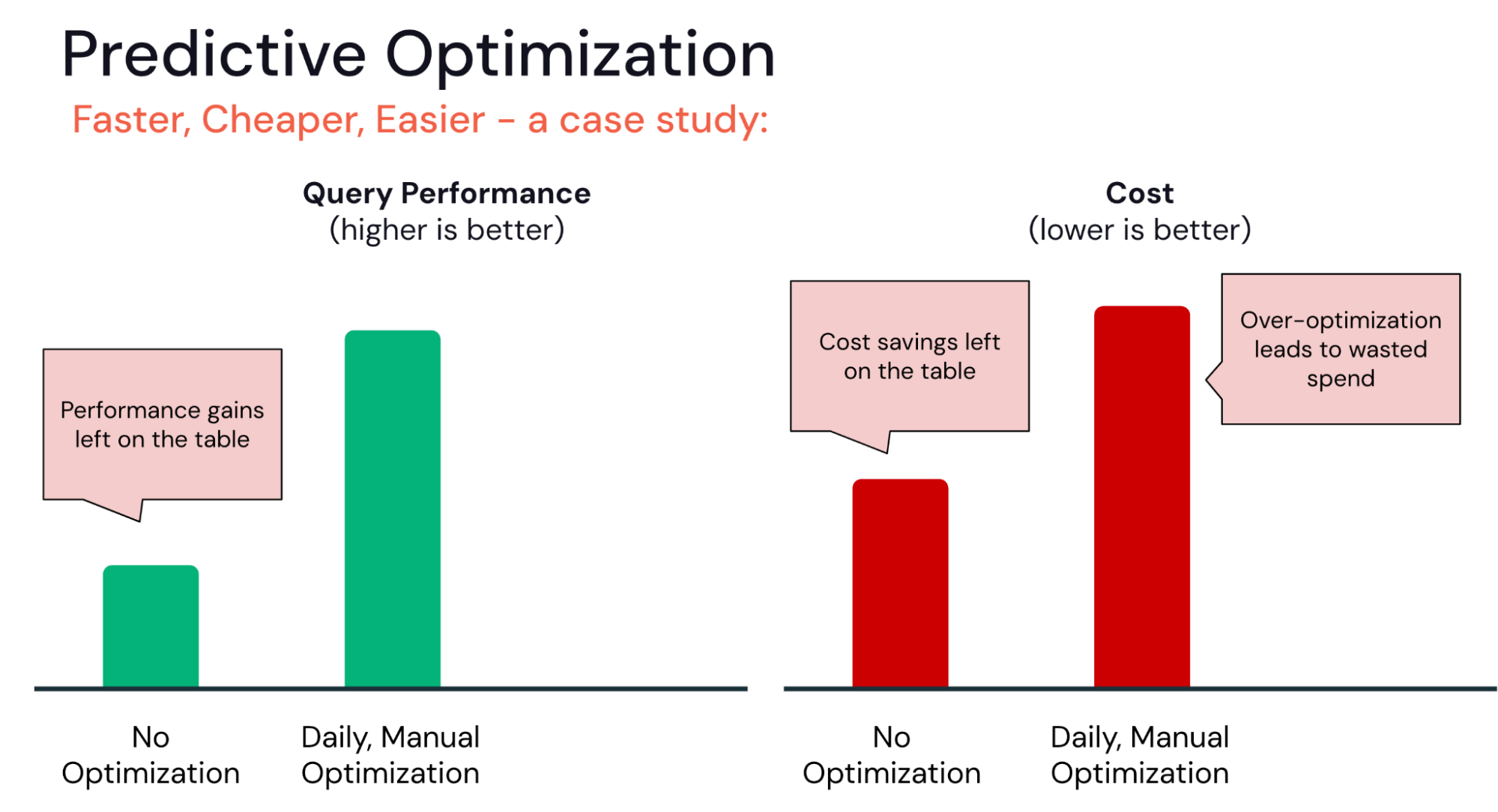
D'un côté, certaines organisations n'ont pas encore mis en place de pipelines sophistiqués d'optimisation des tables. Avec l'Optimisation prédictive, ils peuvent instantanément start à optimiser leurs tables sans avoir à déterminer le meilleur calendrier d'optimisation ou à gérer l'infrastructure.
À l'autre extrême, certaines organisations surinvestissent peut-être dans l'optimisation. Par exemple, pour une équipe qui automatise ses pipelines d'optimisation, il est tentant d'exécuter des Jobs OPTIMIZE ou VACUUM toutes les heures ou tous les jours. Cependant, celles-ci s'exposent au risque de rendements décroissants. Les mêmes gains de performance pourraient-ils être obtenus avec moins d'opérations d'optimisation ?
L'optimisation prédictive aide à trouver le juste équilibre, en garantissant que les optimisations ne sont exécutées que lorsque le retour sur investissement est élevé :
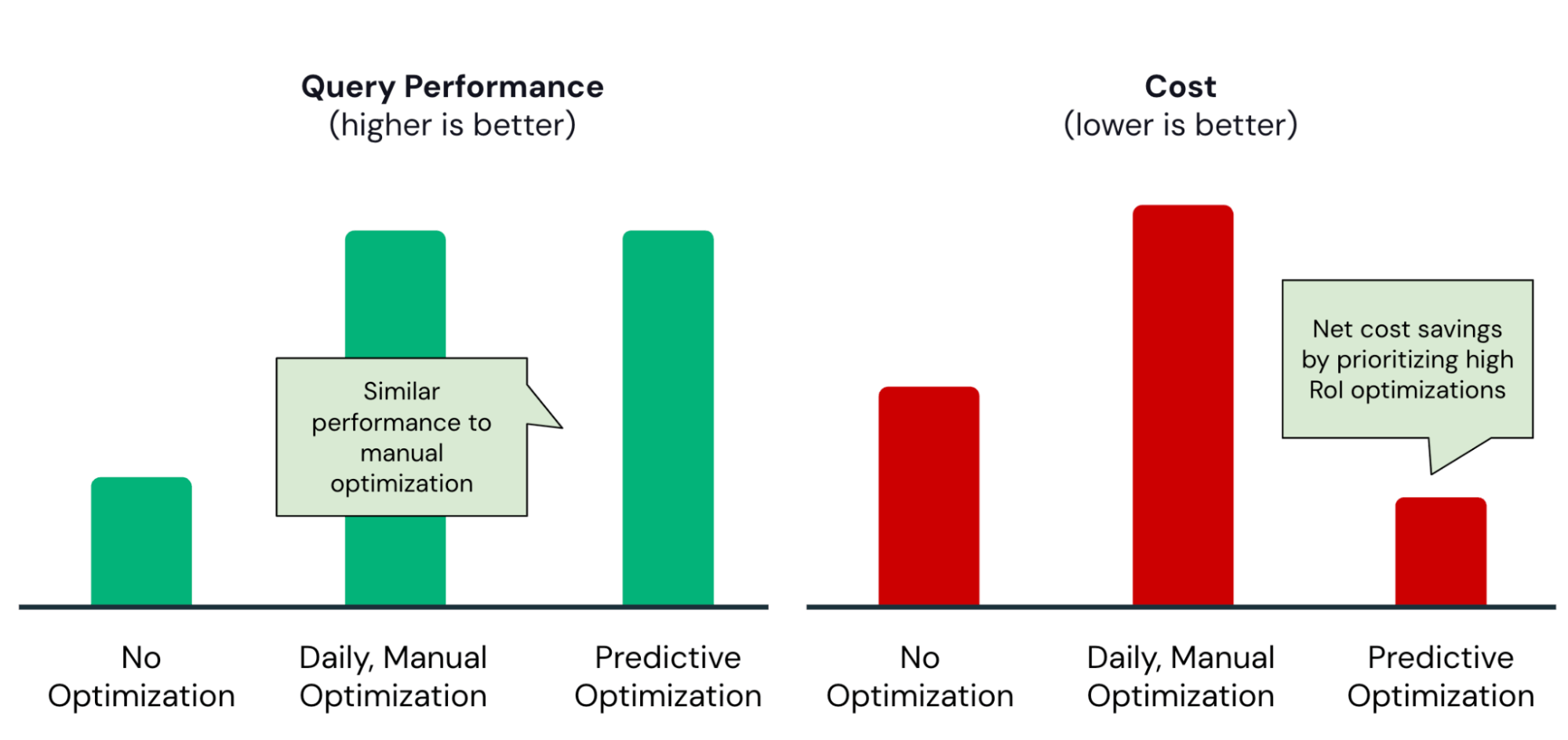
À titre d'exemple concret, l'équipe Data Engineering de Anker a activé l'Optimisation prédictive et a rapidement constaté les avantages suivants :
Réduction de 50 % des coûts de stockage annuels
|
|
 Requêtes 2x plus rapides
Requêtes 2x plus rapides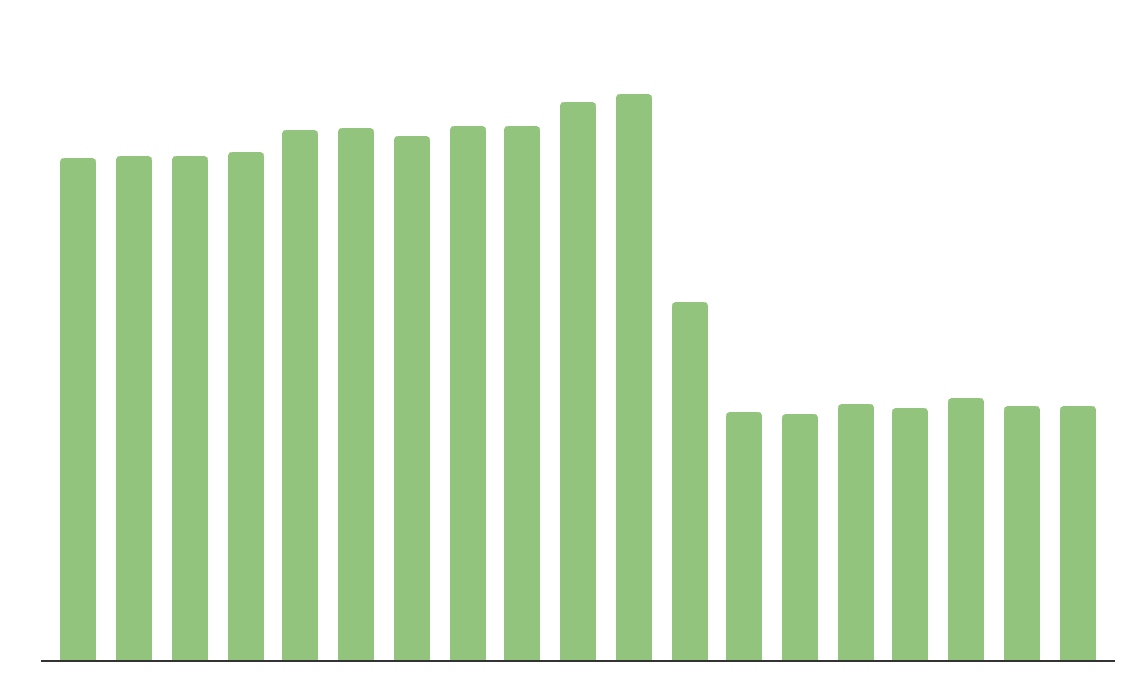
Démarrer
Dès aujourd'hui, l'Optimisation prédictive est disponible en préversion publique. Son activation devrait prendre moins de cinq minutes. En tant qu'administrateur de compte, il vous suffit de vous rendre dans la console du compte > paramètres > tab d'activation des fonctionnalités et d'activer le paramètre Predictive Optimization :
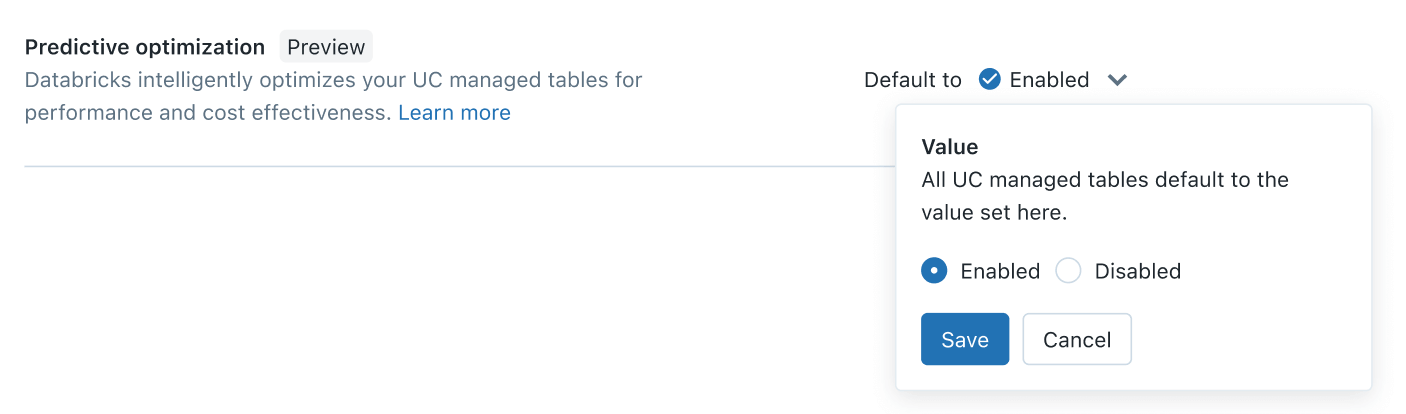
En un seul clic, vous bénéficierez de la puissance des Layouts de données optimisées par l'IA sur vos tables gérées par Unity Catalog, rendant vos données plus rapides et plus rentables.
Et nous ne faisons que commencer. Au cours des prochains mois, nous continuerons d'ajouter de nouvelles optimisations à cette fonctionnalité. Restez à l'écoute pour plus de nouveautés.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.