Du système hérité au Lakehouse : Comment Mazda a accéléré la GenAI pour les opérations de service technique
Comment une équipe agile a construit un assistant GenAI gouverné à l'aide de RAG, Unity Catalog et de la recherche vectorielle
par Tim Marx (Mazda), Foon Hoe Campbell-Wong (Mazda), Jiayi Wu, Arthur Dooner et Olivia Zhang
- Comment Mazda a utilisé le Databricks Lakehouse pour rassembler l'historique des services, les diagnostics et les documents comme base pour GenAI
- Comment l'équipe a conçu l'assistant GenAI, y compris la récupération des bons documents et la logique de partage entre l'interface utilisateur et l'agent
- Comment Mazda est passée des tests GenAI ad hoc à des évaluations et des cas de test reproductibles à l'aide de MLflow
Les organisations de service automobile sont sous pression. Le volume des appels ne cesse d'augmenter, les véhicules électriques introduisent une complexité de diagnostic nouvelle, et les voitures connectées génèrent plus de données que les agents des centres d'appels ne peuvent raisonnablement en analyser. Chaque année modèle apporte des centaines de documents d'information de service (SI), chacun avec des procédures et des conditions uniques. Lorsque quelque chose change, les agents des centres d'appels ont besoin de temps pour l'assimiler avant de pouvoir guider avec confiance les techniciens à travers des problèmes inconnus. Ce délai est important lorsqu'un client attend.
Mazda disposait déjà des ingrédients bruts pour résoudre ce problème : un lac de données en croissance contenant des informations sur les garanties, les rappels, les codes de diagnostic, l'historique des services et des véhicules, ainsi qu'une bibliothèque constamment mise à jour de documents de service. Le défi consistait à rassembler ces actifs d'une manière qui améliore la capacité des agents à faire leur travail avec précision, cohérence et confiance.
C'est là que Databricks est intervenue. L'équipe de science des données de Mazda a agi rapidement et a appris en faisant, passant du lancement à un concept fonctionnel en environ huit semaines. Il n'y a pas eu de longue phase de planification. L'équipe a construit, testé, cassé des choses et ajusté au fur et à mesure, livrant un pilote qui a eu un impact et une valeur réels pour Mazda.
Point de départ : Une équipe restreinte aux grandes ambitions
Ce projet a été l'une des premières initiatives GenAI de bout en bout de Mazda, entièrement construite sur sa nouvelle plateforme de données cloud. L'équipe était petite – deux scientifiques des données itérant rapidement – et les outils étaient rudimentaires. Des pipelines de données devaient être construits. Des documents devaient être extraits et transformés en index de recherche vectorielle. Les expériences vivaient dans des notebooks isolés, et le succès reposait davantage sur la mémoire que sur la traçabilité.
Pour une équipe aussi restreinte, la surcharge d'infrastructure devait être minimale. Ce fut un facteur majeur dans le choix de Databricks. La plateforme a permis la souplesse : pas de gestion de bases de données vectorielles, pas de configuration de frameworks de calcul distribué, pas d'orchestration sur mesure, pas de services de liaison pour tout assembler. L'accent est mis sur la création de valeur, pas sur l'infrastructure.
Construction du pilote
Au début du pilote, l'équipe s'est concentrée sur une conception de Génération Augmentée par Récupération (RAG), l'objectif principal étant de connecter un LLM à notre corpus personnalisé. Bientôt, Mazda a remarqué que les testeurs voulaient souvent que les agents aient d'abord une image complète du véhicule : son historique de service, les rappels en cours, les escalades antérieures du centre d'appels, le statut de la garantie.
Cette observation a façonné un choix architectural délibéré : le frontend et l'agent partagent le code et les outils. L'accès aux données du véhicule, la transformation et la logique de génération d'invites sont implémentées une seule fois et utilisées de manière identique par l'interface Streamlit et le point de terminaison de l'agent déployé.
Lorsqu'un agent de service entre un VIN au début d'une session, le frontend précharge le contexte complet du véhicule (historique de réparation, escalades du centre d'appels, données de garantie, statut des rappels) et l'injecte dans l'invite système avant l'envoi du premier message. Cela élimine les appels d'outils et offre une interactivité immédiate.
D'autre part, si l'agent IA est invoqué sans ce contexte préchargé, il utilisera la même boîte à outils que celle avec laquelle les utilisateurs interagissent. La sortie est structurellement identique dans les deux cas, et l'invite système gère explicitement les deux chemins : utiliser le contexte injecté s'il est présent, appeler les outils sinon. Une invite, deux modes d'exécution, pas de dérive comportementale entre les surfaces.
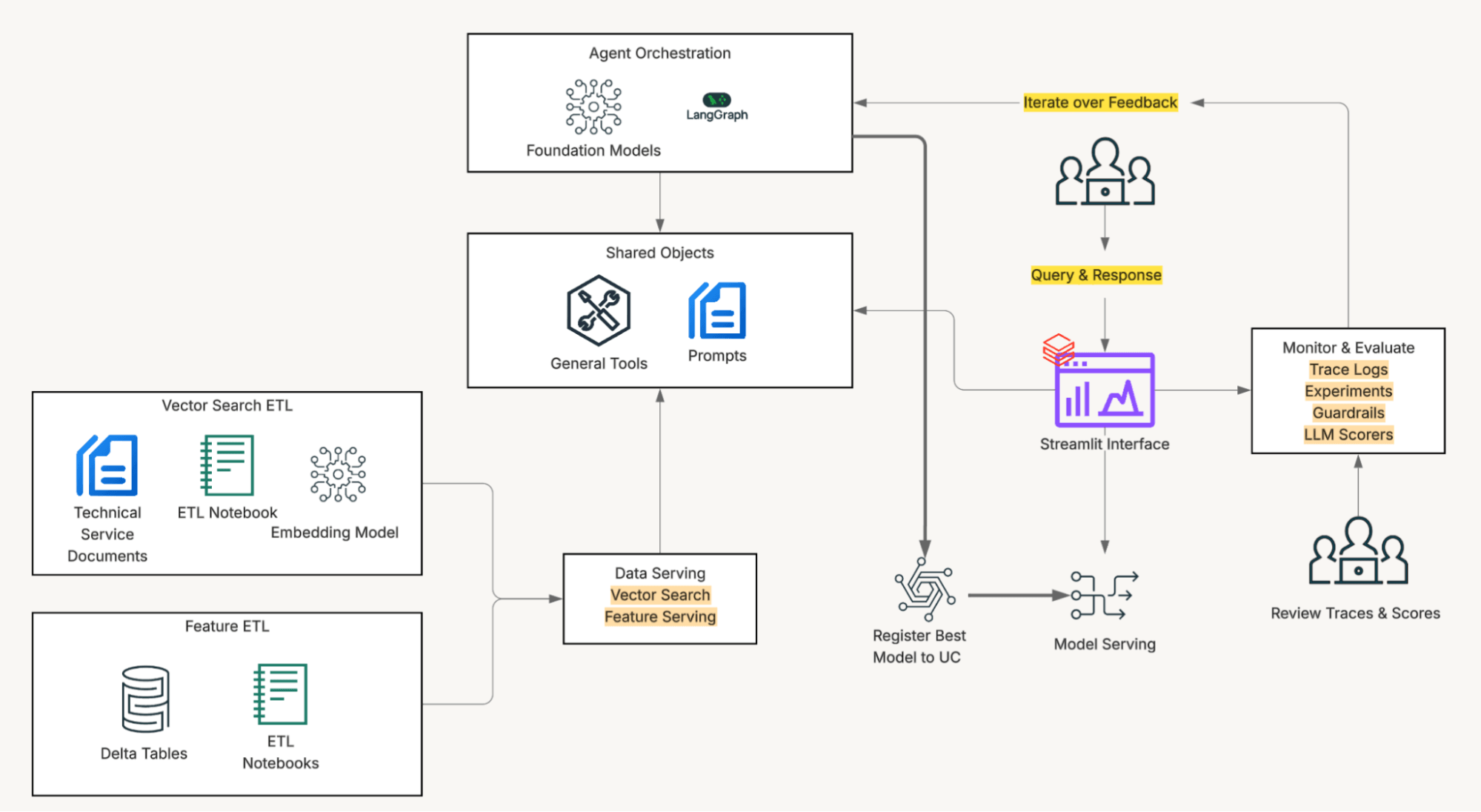
Unity Catalog
La solution est alimentée par le Databricks Lakehouse. Unity Catalog fournit un accès gouverné aux données sur lesquelles les agents de service s'appuient chaque jour, et où les embeddings, la recherche vectorielle, les appels d'outils SQL et la mise à disposition de modèles s'exécutent dans le même environnement, simplifiant le développement et éliminant les frictions d'intégration. Mazda a utilisé des LLM via l'API des modèles fondamentaux (paiement à l'usage) et des modèles d'embedding via le point de terminaison de recherche vectorielle géré.
Tout se trouve dans Unity Catalog : documents SI, tables Delta avec historique des véhicules et codes de diagnostic, index de recherche vectorielle, transformations de données et modèles. La gouvernance unifiée signifie la capacité d'isoler l'accès à des sous-ensembles spécifiques de données, d'effectuer des modifications à la volée et d'en observer l'impact immédiatement. Ensuite, Databricks Apps relie le tout avec un frontend Streamlit que les équipes de service peuvent utiliser sans nouvelle formation ni outils.
Filtrage précis du corpus, activé par les fonctions Unity Catalog
Une recherche vectorielle naïve sur l'ensemble du corpus renvoie des résultats sémantiquement plausibles mais pas nécessairement applicables au véhicule devant le technicien. Obtenir une récupération correcte signifiait résoudre un problème de périmètre avant de résoudre un problème de pertinence.
L'équipe a implémenté le filtrage via des fonctions définies par l'utilisateur dans Unity Catalog. Avant toute exécution de recherche vectorielle, le système appelle une fonction UC qui mappe le VIN (ou le code de diagnostic de défaut) au sous-ensemble de documents applicables pour ce véhicule, limitant la correspondance sémantique uniquement aux documents qui s'appliquent.
Héberger cette logique en tant que fonction Unity Catalog plutôt qu'en tant que code d'application signifiait que les règles d'applicabilité vivaient aux côtés des données qu'elles gouvernent, étaient accessibles à la fois à l'agent et à toute autre application en aval, et pouvaient être mises à jour indépendamment du cycle de déploiement de l'agent.
Des tests ad hoc au développement piloté par les tests
Mazda a expérimenté l'application avec 10 testeurs agents de service. Au début du pilote, l'itération était basée sur les retours : les testeurs signalaient des problèmes, l'équipe ajustait les invites ou la configuration de récupération, et évaluait le résultat de manière informelle. Cela a fonctionné pour le développement initial mais n'a pas évolué à mesure que le système devenait plus complexe.
Le framework d'évaluation GenAI natif de MLflow 3 a changé le flux de travail de l'équipe. MLFlow 3 fournit un moyen complet de créer des ensembles de données d'évaluation et une variété de scorers LLM et déterministes. Pour des tests rapides, les ébauches d'ensembles de données d'évaluation sont définies en YAML avant d'être promues à l'ensemble de données d'évaluation standard. Lorsque les testeurs signalaient une lacune, l'équipe l'ajoutait à l'ensemble de données d'évaluation et considérait la réussite de ces cas comme le critère d'acceptation de toute correction. Lorsque de nouvelles fonctionnalités et sources de données étaient ajoutées, de nouveaux cas d'évaluation étaient rédigés avant que l'intégration ne soit acceptée.
Le résultat a été un passage de "c'est mieux" à "c'est mieux, et voici les preuves". Les traces d'expériences capturaient les invites, les stratégies de récupération, les nombres de jetons et les métriques de qualité des réponses, de sorte que les changements pouvaient être comparés objectivement plutôt que par la mémoire.
Capacité multilingue
Le succès initial rapide a soulevé la question de savoir si la même architecture pouvait servir d'autres régions. Après avoir expérimenté des modèles d'embedding multilingues, l'équipe s'est rendu compte que le LLM pouvait traduire les invites utilisateur et la réponse finale, sans modifier l'architecture et les outils principaux. Cela a des implications pour les plans plus larges de Mazda d'étendre l'application à travers les marchés.
Gouvernance
L'alignement des autorisations entre les Applications, les clusters, les entrepôts, les points de terminaison et les agents a nécessité une courbe d'apprentissage, mais une fois standardisé, il a créé un modèle de gouvernance réutilisable, sécurisé et applicable aux futures applications GenAI. Le modèle qui a fonctionné : router tout accès via le principal de service du point de terminaison de mise à disposition, et définir les autorisations au niveau du catalogue et du schéma pour les groupes de contrôle d'accès basé sur les rôles. Une fois cela établi, il est devenu réutilisable – l'intégration d'un nouveau modèle ou d'une nouvelle source de données signifiait accorder l'accès au même principal de service contre le même schéma, sans renégocier la structure d'autorisation. Combiné à une connectivité privée pour le trafic IA, cela offre à Mazda un chemin contrôlé et sécurisé entre les applications et les données gouvernées.
Le partenariat avec l'équipe d'ingénierie terrain de Databricks a permis à Mazda d'agir plus rapidement, guidé par les meilleures pratiques et en anticipant les obstacles.
Impact et prochaines étapes
Mazda dispose désormais d'une base répétable pour les applications GenAI qui combinent des données structurées et non structurées, le tout à l'intérieur du lakehouse : index de recherche vectorielle, mise à disposition de modèles, évaluations, observabilité, gouvernance au niveau du catalogue et livraison frontale via une application web. Avoir ces capacités sur une seule plateforme a éliminé la nécessité de relier plusieurs services, ce qui a considérablement accéléré le développement.
Deux scientifiques des données qui ont commencé avec des notebooks isolés exécutent maintenant des applications et des expériences IA avec une traçabilité complète sur Databricks. L'équipe étend l'approche à des flux de travail de diagnostic supplémentaires et explore comment les agents génératifs peuvent soutenir les techniciens, les ingénieurs de terrain et le support client.
Ce changement n'est pas seulement technique. Il fait passer Mazda de la reporting descriptif à des applications intelligentes et génératives construites directement sur des données d'entreprise gouvernées.
À retenir
Vous n'avez pas besoin d'une grande équipe ou d'une pratique MLOps mature pour créer des applications GenAI significatives. Mazda avait deux data scientists, des délais serrés et beaucoup à apprendre. Databricks en tant que plateforme a porté une plus grande partie du travail que prévu, et Databricks nous a aidés à livrer quelque chose de concret, rapidement.
À la base, le projet est une expression de l'omotenashi — le principe directeur de Mazda d'hospitalité de tout cœur. Donner aux agents de service technique de Mazda de meilleurs outils les aide à mieux prendre soin de ses clients. Et maintenant, avec cette base en place, l'équipe ne fait que commencer.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.