LLM sur le lakehouse : une r�évolution pour le secteur public
par Tim Lortz, Parth Vakil et Lisa Sion

Au cours des derniers mois, l'intérêt des agences du secteur public pour les grands modèles linguistiques (LLM) a grimpé en flèche, car les LLM modifient fondamentalement les attentes des gens dans leurs interactions avec les ordinateurs et les données. Du point de vue de Databricks, pratiquement tous les clients et prospects du secteur public avec lesquels nous interagissons se sentent obligés d'intégrer les LLM dans leur mission. On nous pose régulièrement des questions sur ce que sont les LLM (comme Dolly de Databricks), sur leurs domaines d'application et sur la manière dont le Lakehouse de Databricks prendra en charge les applications liées aux LLM. Dans cet article, nous aborderons ces questions dans le contexte des besoins, des opportunités et des contraintes uniques des organisations du secteur public. Nous nous concentrerons également sur les avantages de créer, de posséder et de gérer votre propre LLM, par rapport à l'adoption d'une Technologie qui nécessite le Data Sharing avec des tiers, comme ChatGPT.
Que sont les LLM ?
Les LLM d'aujourd'hui représentent la dernière version d'une série d'innovations en traitement du langage naturel, ayant débuté vers 2017 avec l'essor de l'architecture du modèle transformer. Ces modèles de type Transformer possèdent depuis longtemps d'étonnantes capacités à comprendre le langage humain suffisamment bien pour accomplir des tâches telles que l'identification des sentiments, l'extraction de noms de personnes, de lieux et d'objets, et la traduction de documents d'une langue à l'autre. Ils sont également capables de générer du texte intéressant à partir d'une invite, avec des degrés variables de qualité et de précision. Plus récemment, les chercheurs et les développeurs ont découvert que de très grands modèles de langage, "pré-entraînés" sur des sources de texte très vastes et diversifiées, peuvent être "affinés" pour suivre diverses instructions d'un humain afin de générer des informations utiles.
Auparavant, la meilleure pratique consistait à entraîner des modèles distincts pour chaque tâche liée au langage. Le processus d'entraînement des modèles nécessitait des Ressources : des données organisées, du compute (généralement un ou plusieurs GPU) et une expertise avancée en Data Science et en développement logiciel. Bien que ces modèles puissent être très précis, il existe clairement des contraintes de ressources, tant en termes de calcul que d'effort humain, lors de la mise à l'échelle de leur utilisation. Avec l'ascension fulgurante de ChatGPT, nous constatons maintenant qu'un seul LLM, avec la quantité de contexte appropriée et le bon prompt, peut être utilisé pour effectuer de nombreuses tâches différentes, parfois avec une meilleure précision qu'un modèle plus spécialisé. Et la capacité des LLM à générer du nouveau texte, l'« IA générative », est à la fois fascinante et extrêmement utile.
À quoi peuvent servir les LLM dans le secteur public ?
Les organisations du secteur privé ont signalé les avantages incroyables des LLM, tels que la génération et la migration de code, la catégorisation et les réponses automatisées aux commentaires des clients, les chatbots de centre d'appels, la génération de rapports et bien plus encore. En tant que microcosme de nombreux Secteurs d'activité, les organismes du secteur public ont les mêmes opportunités en matière de LLM, en plus d'autres besoins spécifiques. Les cas d'usage courants dans le secteur public comprennent :
- Aide à la conformité réglementaire. Grâce à sa capacité à interpréter et à traiter du texte, un LLM peut aider à déterminer les exigences de conformité en analysant les documents réglementaires, les textes juridiques et la jurisprudence pertinente. Il peut aider les agences gouvernementales et les entreprises à comprendre les implications des réglementations et à garantir le respect de la loi.
- Assistant de formation et d'éducation. Montez en charge et accélérez l'apprentissage des étudiants en agissant comme un instructeur virtuel, en répondant aux questions, en expliquant des concepts complexes, en récupérant des extraits pertinents d'enregistrements de cours ou en recommandant des offres du catalogue de cours.
- Résumé et réponse aux questions à partir de documents techniques. Le cas d'usage le plus courant lié aux LLM dans le secteur public consiste peut-être à extraire des connaissances de milliers ou de millions de documents, y compris des PDF et des e-mails, dans un format permettant de trouver rapidement du contenu pertinent en fonction de critères de recherche, puis d'utiliser ce contenu pour générer des résumés ou des rapports.
- Renseignement open source. Les LLM peuvent considérablement améliorer l'analyse du renseignement open source (OSINT) par la Communauté du renseignement en traitant et en analysant de grandes quantités d'informations multilingues accessibles au public. Les LLM peuvent extraire des entités clés, des relations, des sentiments et une compréhension contextuelle à partir de diverses sources telles que les réseaux sociaux, les articles de presse et les rapports, puis résumer et organiser efficacement ces informations, aidant ainsi les analystes à comprendre rapidement et à extraire des insights de grands volumes de données OSINT.
- Modernisation des bases de code héritées. Les agences gouvernementales continuent de migrer leurs charges de travail de données depuis les mainframes, les data warehouse on-premise et les logiciels analytique propriétaires. En mettant des assistants de codage à la disposition des développeurs et des analystes pour leur suggérer du code au fur et à mesure, ou en entraînant des LLM personnalisés pour gérer la conversion de code en masse, le rythme de la migration peut s'accélérer tandis que les professionnels acquièrent en douceur les compétences logicielles pertinentes.
- Ressources humaines. En tant que plus grand employeur du pays, le gouvernement fédéral est confronté à des défis uniques en matière de recrutement et de satisfaction des employés. L'utilisation des LLM dans le domaine des RH peut aider à relever ces défis en automatisant la sélection des CV, en faisant correspondre les candidats aux descriptions de job et en analysant les retours des employés pour améliorer les processus de recrutement et renforcer l'engagement du personnel. De plus, les LLM peuvent aider à garantir la conformité avec les politiques RH, à soutenir les initiatives en matière de diversité et d'inclusion, et à fournir des recommandations personnalisées pour l'intégration et le développement de carrière.
Comment Databricks répondra-t-il aux besoins des organisations du secteur public dans un monde où les LLM sont omniprésents ?
Bien que certainement puissants, les LLM introduisent également un nouvel ensemble de défis qui sont amplifiés par certaines des contraintes opérationnelles propres aux organisations du secteur public. Analysons quelques-uns de ces défis et alignons-les sur les capacités de Databricks Lakehouse :
Défi n°1 : Souveraineté et gouvernance des données
Le défi ?
La plupart des organisations du secteur public sont soumises à des contrôles réglementaires stricts concernant leurs données. Ces contrôles existent pour des raisons de confidentialité, de sécurité et, dans certains cas, pour préserver le secret. Même la simple tâche de poser une ou plusieurs questions à un LLM pourrait révéler des informations exclusives. De plus, la plupart des agences fédérales devront affiner les LLM pour répondre à leurs exigences particulières. Pour ces raisons, il est logique de supposer que les agences du secteur public seront limitées dans leur utilisation des modèles publics. Il est probable qu'elles exigeront que les modèles soient affinés dans un environnement qui garantit leur confidentialité et leur sécurité, et que les interactions avec les modèles via diverses méthodes de prompting soient également confidentielles.
Solutions Databricks
La Databricks Lakehouse Platform dispose des outils nécessaires pour développer et déployer des applications LLM de bout en bout. (Nous y reviendrons plus tard.) De plus, Databricks possède les certifications nécessaires pour traiter les données de la grande majorité des organisations du secteur public américain. Databricks est un partenaire fiable et compétent pour les organisations qui cherchent à exploiter toute la puissance des LLM sans les risques liés à l'utilisation de LLM propriétaires en tant que service comme ChatGPT ou Bard.
Au-delà de Databricks, le secteur constate de plus en plus que les LLM open source, utilisés de manière appropriée, peuvent fournir des résultats qui approchent la parité avec les principaux LLM propriétaires. Les preuves sont les plus solides dans les cas d'utilisation où les LLM propriétaires doivent comprendre un contexte ou des instructions nuancés sur lesquels ils n'ont pas été entraînés auparavant. Dans ces cas, les LLM open source peuvent être soit sollicités avec des prompts, soit affinés sur des données spécifiques à l'organisation pour fournir des résultats stupéfiants. Dans cette architecture de solution, les organisations peuvent obtenir des résultats de classe mondiale avec des quantités modestes de compute et de temps de développement, sans que les données ne quittent jamais les frontières approuvées. Pour les organisations du secteur public, cela représente un avantage significatif qui ne peut être négligé.
La conviction de Databricks quant à la puissance des LLM open source est renforcée par la sortie de Dolly 2.0, le premier LLM open source capable de suivre des instructions, affiné sur un dataset d'instructions généré par des humains et sous licence pour la recherche et l'utilisation commerciale. La sortie de Dolly a été suivie par une vague d'autres LLM open source performants, dont certains affichent des performances très impressionnantes. Databricks s'efforce de fournir aux organisations du secteur public une plateforme pour créer des applications avec le LLM de leur choix (open source ou commercial) et nous sommes impatients de voir ce que l'avenir nous réserve.

Défi n° 2 : Complexité de l'architecture
Le défi ?
La modernisation du patrimoine de données reste une priorité absolue pour la plupart des responsables techniques du secteur public. L'époque des data warehouses on-premise est en grande partie révolue ; ils sont généralement remplacés par un data warehouse ou un lakehouse dans le cloud. Les organisations qui n'ont pas encore migré vers le cloud, ou qui ont opté pour un data warehouse dans le cloud, sont maintenant confrontées à un nouveau point d'inflexion : comment adopter les LLM dans une architecture qui ne peut pas les prendre en charge ? Étant donné l'immense potentiel des LLM à impacter les missions des agences et les fonctionnaires qui les accomplissent, il est essentiel d'établir une architecture pérenne. Entrez dans le lakehouse.
Solutions Databricks
Databricks est depuis longtemps une plateforme performante pour les charges de travail de machine learning (ML) et d'intelligence artificielle (IA). Les clients utilisent depuis des années des LLM de qualité production et leurs prédécesseurs sur Databricks, en profitant de fonctionnalités telles que :
- compute évolutive pour le prétraitement de données non structurées telles que le texte, les images et l'audio.
- L'accès à la suite complète des bibliothèques ML/IA open source
- Un environnement de développement de Notebooks natif et de premier ordre, offrant également une excellente prise en charge de l'intégration IDE.
- Fonctionnalités de gouvernance des données via Unity Catalog qui garantissent des contrôles d'accès appropriés aux
- Données structurées (bases de données et tables)
- Données non structurées (fichiers, images, documents)
- Modèles (LLM ou autres)
- Options de compute GPU pour l'entraînement des modèles de ML et les prédictions à partir de ceux-ci – désormais une condition préalable pour travailler avec des LLM basés sur des transformeurs
- Gestion de bout en bout du cycle de vie des modèles avec MLflow et Unity Catalog. Les modèles sont traités comme des citoyens de première classe, avec un lignage jusqu'à leurs données sources et leurs événements d'entraînement, et peuvent être déployés en mode batch ou en temps réel.
- Capacités de mise en service de modèles, qui deviennent de plus en plus critiques à mesure que les organisations affinent, hébergent et déploient leurs propres LLM.
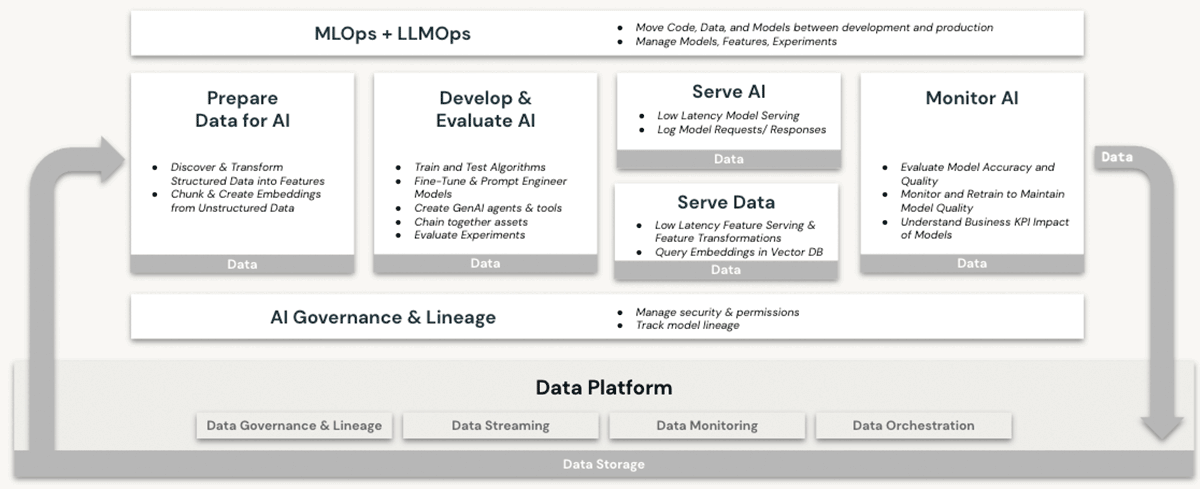
Aucune de ces fonctionnalités n'est proposée dans un data warehouse, même dans le cloud. Pour utiliser les LLM conjointement avec un data warehouse, une organisation devrait se procurer d'autres services logiciels pour toutes les facettes des processus d'entraînement et de déploiement des modèles, et échanger des données entre ces services. Seule l'architecture Databricks Lakehouse offre la simplicité architecturale nécessaire pour effectuer toutes les opérations LLM sur une plateforme unique, ce qui permet de bénéficier pleinement des avantages expliqués dans notre discussion ci-dessus sur la souveraineté des données.
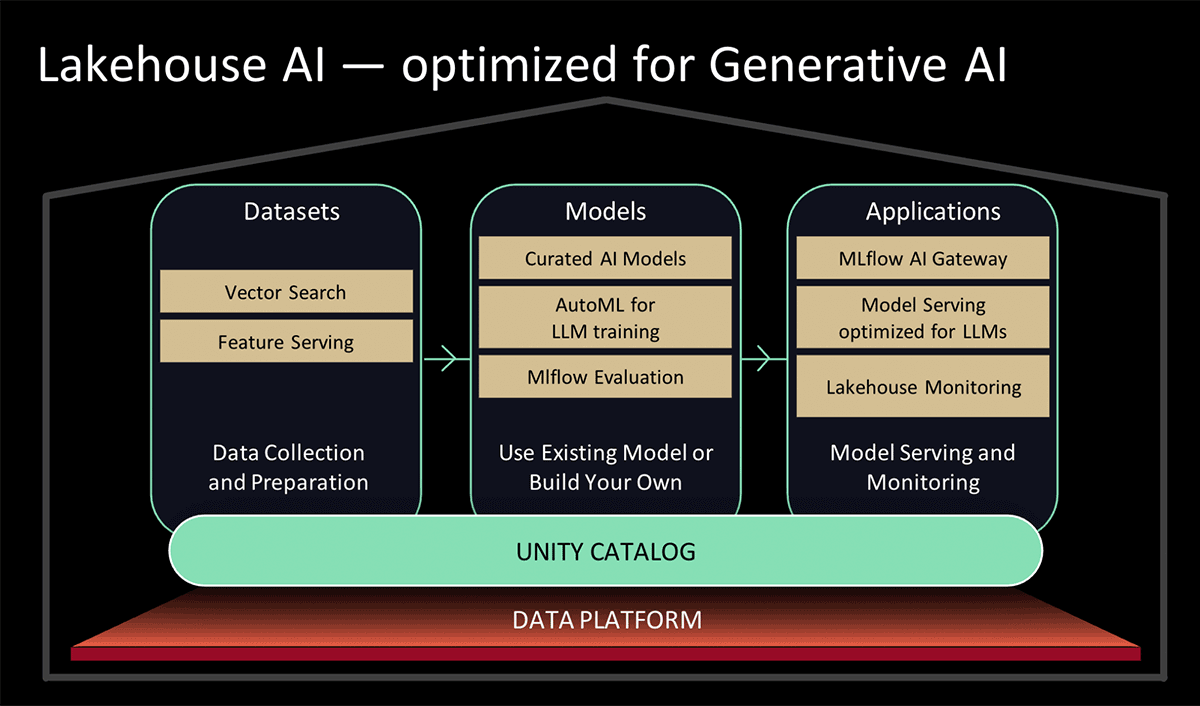
Lors du Data and AI Summit 2023, Databricks a présenté Lakehouse AI, qui ajoute plusieurs nouvelles fonctionnalités majeures liées aux LLM qui simplifient considérablement l'architecture pour le LLMOps, notamment :
- Recherche vectorielle pour l'indexation. Une base de données vectorielles hébergée par Databricks aide les équipes à indexer rapidement les données de leurs organisations sous forme de vecteurs d'embedding et à effectuer des recherches de similarité vectorielle à faible latence dans des déploiements en temps réel.
- Monitoring du Lakehouse Le premier service unifié de monitoring des données et de l'IA qui permet aux utilisateurs de suivre simultanément la qualité de leurs données et de leurs assets d'IA.
- Fonction d'IA. Les data analysts et les data engineers peuvent désormais utiliser des LLM et d'autres Modèles de machine learning dans une query SQL interactive ou un pipeline ETL SQL/Spark.
- Gouvernance unifiée des données & de l'IA. Améliorations du Unity Catalog pour fournir une gouvernance complète et un suivi du lignage des assets de données et d'IA dans une seule et même expérience unifiée.
- Passerelle IA MLflow La MLflow AI Gateway, qui fait partie de MLflow 2.5, est une passerelle d'API au niveau du workspace qui permet aux organisations de créer et de partager des routes, lesquelles peuvent ensuite être configurées avec diverses limites de débit, une mise en cache, une attribution des coûts, etc. afin de gérer les coûts et l'utilisation.
- MLflow 2.4. Cette version fournit un ensemble complet d'outils LLMOps pour l'évaluation des modèles
Défi n°3 : Manque de compétences
Le défi ?
Ces dernières années, les agences gouvernementales ont été confrontées à une « fuite des cerveaux » persistante, en particulier pour les postes qui touchent à des tendances technologiques de pointe telles que la cybersécurité, le cloud computing et le ML/IA. L'attention intense actuellement portée aux LLM génère une demande encore plus forte de praticiens talentueux en ML/IA. Inévitablement, l'attrait et les avantages liés à un emploi dans les grandes entreprises technologiques et le monde des startups exacerberont la pénurie de talents dans le secteur public. Les dirigeants gouvernementaux doivent avoir accès à des plateformes et à des partenariats qui les aideront à adopter facilement les LLM et à donner à leurs employés les moyens de devenir autonomes avec ces outils.
Solutions Databricks
Databricks déploie activement des fonctionnalités qui simplifient et étendent les capacités existantes pour travailler avec les LLM sur la plateforme lakehouse. selon les besoins :
- Modèles simplifiés pour utiliser les LLM pré-entraînés de Hugging Face pour des tâches d'inférence dans les pipelines de données, ou pour les affiner afin d'obtenir de meilleures performances sur vos propres données dans Databricks.
- Simplification du processus et amélioration des performances de chargement des données depuis Apache Spark vers Hugging Face pour les Jobs d'entraînement ou d'affinement de modèles.
- Des accélérateurs de solution LLM spécifiques à un secteur, présentant des modèles d'implémentation reproductibles pour des gains rapides, tels que l'analytique du service client et la découverte de produits
- La version 2.3 de MLflow, avec prise en charge native des LLM, en particulier :
- Trois toutes nouvelles saveurs de modèles : Hugging Face Transformers, fonctions OpenAI et LangChain.
- Vitesse de download et de upload des modèles depuis et vers les services cloud considérablement améliorée grâce au download et au upload en plusieurs parties pour les fichiers de modèle.
- Une fonction Databricks SQL intégrée permettant aux utilisateurs d'accéder aux LLM directement depuis SQL. Cette fonctionnalité peut contourner les processus de développement de modèles de langage longs et complexes en permettant aux analystes de simplement créer des prompts LLM efficaces.
- Comme annoncé lors du Data & AI Summit 2023,
- Ajouts au service AutoML basé sur l'interface utilisateur de Databricks qui permettront d'affiner les LLM pour la classification de texte ainsi que les modèles d'embedding ; et
- Des modèles sélectionnés, optimisés par le service Model Serving pour des performances élevées. Plutôt que de passer du temps à rechercher les meilleurs modèles d'IA générative open source pour votre cas d'usage, vous pouvez vous fier aux modèles sélectionnés par les experts Databricks pour les cas d'usage courants.
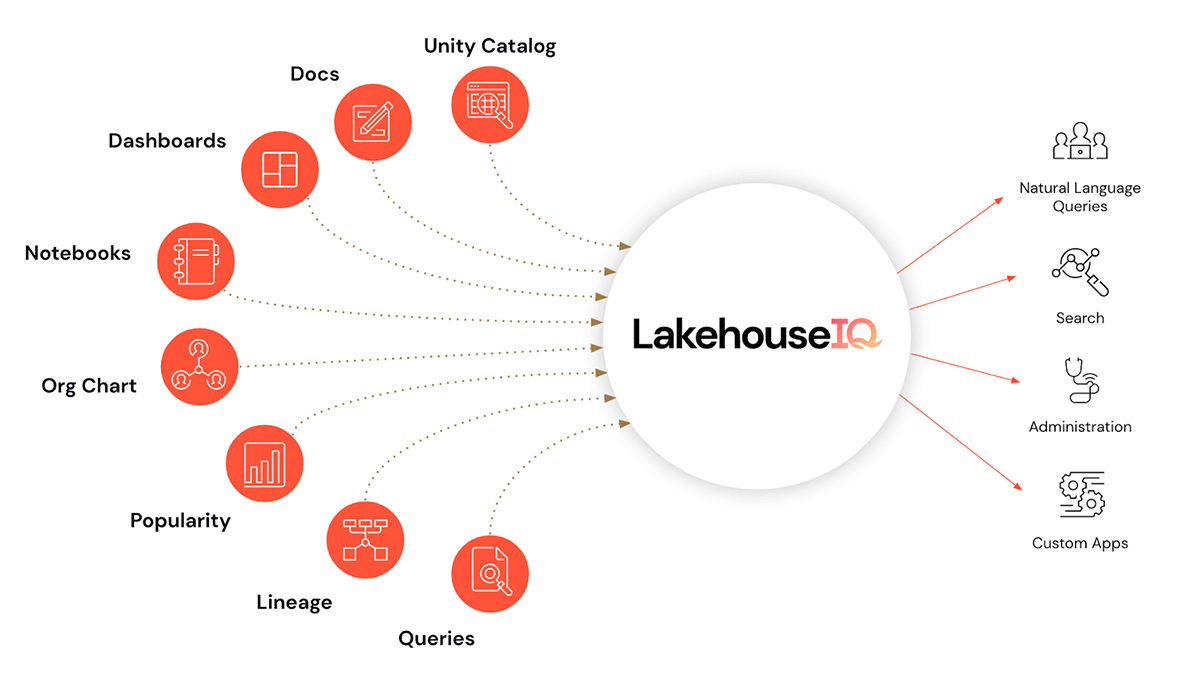
- Et, cerise sur le gâteau, LakehouseIQ, un moteur de connaissances qui apprend les nuances uniques de votre entreprise et de vos données pour y permettre un accès en langage naturel dans un large éventail de cas d'utilisation.
En plus de faciliter l'utilisation des LLM dans Databricks, nous introduisons également des programmes de formation et d'habilitation aux LLM pour aider les organisations à accroître leur maîtrise des LLM. Ils sont fournis à un niveau accessible pour les utilisateurs du secteur public de Databricks.
- Partenariat avec EdX pour proposer des cours en ligne dirigés par des experts, spécifiquement axés sur la création et l'utilisation de modèles de langage dans les applications modernes
Conclusions et prochaines étapes
Les opportunités d'exploiter les LLM pour accélérer les cas d'usage du secteur public abondent. Une immense valeur reste enfouie dans les données existantes, attendant simplement d'être découverte et appliquée aux problèmes actuels. Venez en apprendre davantage sur la manière dont Databricks peut vous aider à adopter les LLM dans le cadre de votre mission en participant à notre webinar Les grands modèles linguistiques dans le secteur public le 2 août à midi, EDT. Consultez également les inscriptions aux aperçus des fonctionnalités répertoriées dans l'annonce de Lakehouse AI et voyez celles auxquelles votre organisation est éligible.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.