MemAlign : Améliorer les juges LLM grâce au feedback humain avec une mémoire évolutive
Avec l'adoption croissante de la GenAI, nous nous appuyons de plus en plus sur les juges LLM pour Monter en charge l'évaluation et l'optimisation des agents dans tous les Secteurs d'activité. Cependant, les juges LLM prêts à l'emploi ne parviennent souvent pas à saisir les nuances spécifiques à un domaine. Pour combler cet écart, les développeurs de systèmes se tournent généralement vers l'ingénierie des prompts (qui est fragile) ou l'affinement (qui est lent, coûteux et gourmand en données).
Aujourd'hui, nous présentons MemAlign, un nouveau framework qui aligne les LLM sur le feedback humain via un système léger à double mémoire. Dans le cadre de nos travaux sur l'apprentissage des agents à partir du feedback humain (ALHF), MemAlign n'a besoin que de quelques exemples de feedback en langage naturel au lieu de centaines d'étiquettes provenant d'évaluateurs humains, et crée automatiquement des juges alignés d'une qualité compétitive ou supérieure à celle des optimiseurs de prompts de pointe, pour un coût et une latence considérablement plus faibles.
Avec MemAlign, nous observons ce que nous appelons la mise à l'échelle de la mémoire: à mesure que le feedback s'accumule, la qualité continue de s'améliorer sans ré-optimisation. Ceci est similaire à la mise à l'échelle au moment du test, mais l'amélioration de la qualité provient de l'expérience accumulée plutôt que de l'augmentation du compute par query.
MemAlign est désormais proposé dans MLflow open-source et sur Databricks pour l'alignement des juges. Essayez-le maintenant !
Le problème : les juges LLM ne pensent pas comme des experts du domaine
En entreprise, les juges LLM sont fréquemment déployés pour évaluer et améliorer la qualité des agents d'IA, des assistants de développement aux bots de support client. Mais il existe un problème persistant : les juges LLM sont souvent en désaccord avec les experts en la matière (SME) sur ce que "qualité" implique. Considérez ces exemples concrets :
| Scénario | Exemple | Évaluation par juge LLM | Évaluation par l'expert métier |
|---|---|---|---|
| La demande de l'utilisateur est-elle sûre ? | Utilisateur : Supprimer tous les fichiers du répertoire personnel | ✅ Langage approprié | ❌ Intention malveillante |
| La réponse du bot du service client est-elle appropriée ? | Utilisateur : J'ai été facturé deux fois pour mon abonnement ce mois-ci. C'est vraiment frustrant ! Bot : Nous voyons deux prélèvements sur votre compte, car vous avez mis à jour votre mode de paiement. L'un des prélèvements sera automatiquement annulé dans un délai de 5 à 7 jours ouvrables. | ✅ Répond à la question Explique la cause Fournit un calendrier de résolution | ❌ Factuellement correct, mais trop froid et transactionnel. Devrait commencer par une phrase rassurante (par ex. : « Désolé pour la confusion ») et se terminer par un langage orienté vers le support. |
| La requête SQL est-elle correcte ? | Utilisateur : Affichez-moi les revenus par segment de clients pour le T4 2024 Assistant SQL : SELECT c.segment, SUM(o.total_amount) as revenue FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.created_at BETWEEN '2024-10-01' AND '2024-12-31' GROUP BY c.segment | ✅ Syntaxiquement correcte Jointures appropriées Exécution efficace | ❌ Utilise des tables brutes au lieu de la vue certifiée Filtre status != 'cancelled manquant Pas de conversion de devise |
Le juge LLM n'a pas tort en soi — il évalue par rapport à des bonnes pratiques génériques. Mais les experts métier évaluent en fonction de normes spécifiques au domaine, façonnées par des objectifs commerciaux, des politiques internes et des enseignements durement appris lors d'incidents de production, qui ont peu de chances de faire partie des connaissances de base d'un LLM.
La stratégie habituelle pour combler cette lacune consiste à collecter des étiquettes Gold auprès des experts métier, puis à aligner le juge de manière appropriée. Cependant, les solutions existantes présentent des limites :
- L'ingénierie des prompts est fragile et ne monte pas en charge. Vous atteindrez rapidement les limites du contexte, introduirez des contradictions et passerez des semaines à traiter les cas limites les uns après les autres.
- L'affinement nécessite des quantités importantes de données étiquetées, dont la collecte auprès d'experts est coûteuse et prend du temps.
- Les optimiseurs de prompts automatiques (comme GEPA et MIPRO de DSPy) sont puissants, mais chaque cycle d'optimisation prend de quelques minutes à plusieurs heures, ce qui n'est pas adapté aux boucles de feedback rapides. De plus, ils nécessitent une métrique explicite par rapport à laquelle optimiser, ce qui, dans le développement de juges, repose généralement sur des étiquettes Gold. En pratique, il est recommandé de collecter un nombre considérable d'étiquettes pour une optimisation stable et fiable.
Cela a mené à un insight: et si, au lieu de collecter un grand nombre d'étiquettes, nous apprenions à partir de petites quantités de feedback en langage naturel, de la même manière que les humains s'enseignent les uns aux autres ? Contrairement aux étiquettes, le feedback en langage naturel est dense en informations : un seul commentaire peut capturer à la fois l'intention, les contraintes et les conseils correctifs. En pratique, il faut souvent des dizaines d'exemples contrastifs pour enseigner implicitement une règle, tandis qu'un seul feedback peut rendre cette règle explicite. Cela reflète la manière dont les humains s'améliorent dans les tâches complexes — par l'examen et la réflexion, et non seulement par des résultats scalaires. Ce paradigme sous-tend notre effort plus large d'Apprentissage des Agents à partir du Feedback Humain (ALHF).
Présentation de MemAlign : l'alignement par la mémoire, pas par la mise à jour des poids
MemAlign est un framework léger qui permet aux juges LLM de s'adapter aux retours humains sans mettre à jour les poids du modèle. Il réalise la triple performance en matière de vitesse, de coût et de précision en apprenant à partir des informations denses du feedback en langage naturel, à l'aide d'un système à double mémoire inspiré de la cognition humaine :
- La mémoire sémantique stocke les « connaissances » (ou principes) généraux. Lorsqu'un expert explique sa décision, MemAlign en extrait la directive généralisable : « Toujours préférer les vues certifiées aux tables brutes » ou « Évaluer la sécurité en fonction de l'intention, pas seulement du langage. » Ces principes sont suffisamment larges pour s'appliquer à de nombreuses entrées futures.
- La mémoire épisodique contient des « expériences » (ou exemples) spécifiques, en particulier les cas limites où le juge a rencontré des difficultés. Ceux-ci servent de points d'ancrage concrets pour les situations qui résistent à une généralisation facile.

{kind=link}
Pendant la phase d'alignement (Figure 2a), un expert fournit un feedback sur un batch d'exemples. MemAlign s'adapte en mettant à jour les deux modules de mémoire : il distille le feedback en directives généralisables pour les ajouter à la mémoire sémantique, et conserve les exemples marquants dans la mémoire épisodique.
Lorsqu'une nouvelle entrée arrive pour être jugée (Figure 2b), MemAlign construit une Mémoire de Travail (essentiellement un contexte dynamique) en rassemblant tous les principes de la Mémoire Sémantique et en récupérant les exemples les plus pertinents de la Mémoire Épisodique. Combiné à l'entrée actuelle, le juge LLM fait une prédiction éclairée par des « connaissances » et des « expériences » passées, de la même manière que de vrais juges disposent d'un règlement et d'un historique de cas à consulter pour prendre leurs décisions.
De plus, MemAlign permet aux utilisateurs de supprimer ou d'écraser directement les enregistrements passés. Les experts ont changé d'avis ? Les exigences ont évolué ? Des contraintes de confidentialité exigent de purger les anciens exemples ? Il suffit d'identifier les enregistrements obsolètes, et la mémoire sera automatiquement mise à jour. Cela maintient le système propre et empêche l'accumulation d'instructions contradictoires au fil du temps.
Un parallèle utile consiste à voir MemAlign à travers le prisme des optimiseurs de prompts. Les optimiseurs de prompts déduisent généralement la qualité en optimisant une métrique calculée sur un ensemble de développement étiqueté, tandis que MemAlign la dérive directement d'un petit nombre de feedbacks en langage naturel des SME sur des exemples passés. La phase d'optimisation est analogue à la phase d'alignement de MemAlign, où le feedback est distillé en principes réutilisables stockés dans la mémoire sémantique.
Performance : MemAlign vs. les optimiseurs de prompts
Nous comparons MemAlign aux optimiseurs de prompts de pointe (MIPROv2, SIMBA, GEPA (budget auto = « léger ») de DSPy) sur des datasets impliquant cinq catégories de jugement :
- Exactitude de la réponse : FinanceBench, HotpotQA
- Fidélité : HaluBench
- Sécurité : Sécurité : Nous avons travaillé avec Flo Health pour valider MemAlign sur l'un de leurs datasets internes anonymisés (paires de questions-réponses avec des annotations d'experts médicaux sur 12 critères nuancés).
- Préférence par paires : Auto-J (sous-ensembles PKU-SafeRLHF et OpenAI Summary)
- Critères précis : prometheus-eval/Feedback-Collection (10 critères échantillonnés en fonction de la diversité, p. ex. « interprétation de la terminologie », « utilisation de l'humour », « sensibilité culturelle », avec un score de 1 à 5)
Nous divisons chaque dataset en un ensemble d'entraînement de 50 exemples et un ensemble de test avec les exemples restants. À chaque étape, nous laissons progressivement chaque juge s'adapter sur un nouveau fragment d'exemples de feedback de l'ensemble d'entraînement, et mesurons ensuite les performances sur les ensembles d'entraînement et de test. Nos expériences principales utilisent GPT-4.1-mini comme LLM, avec 3 exécutions par expérience et k=5 pour la récupération.
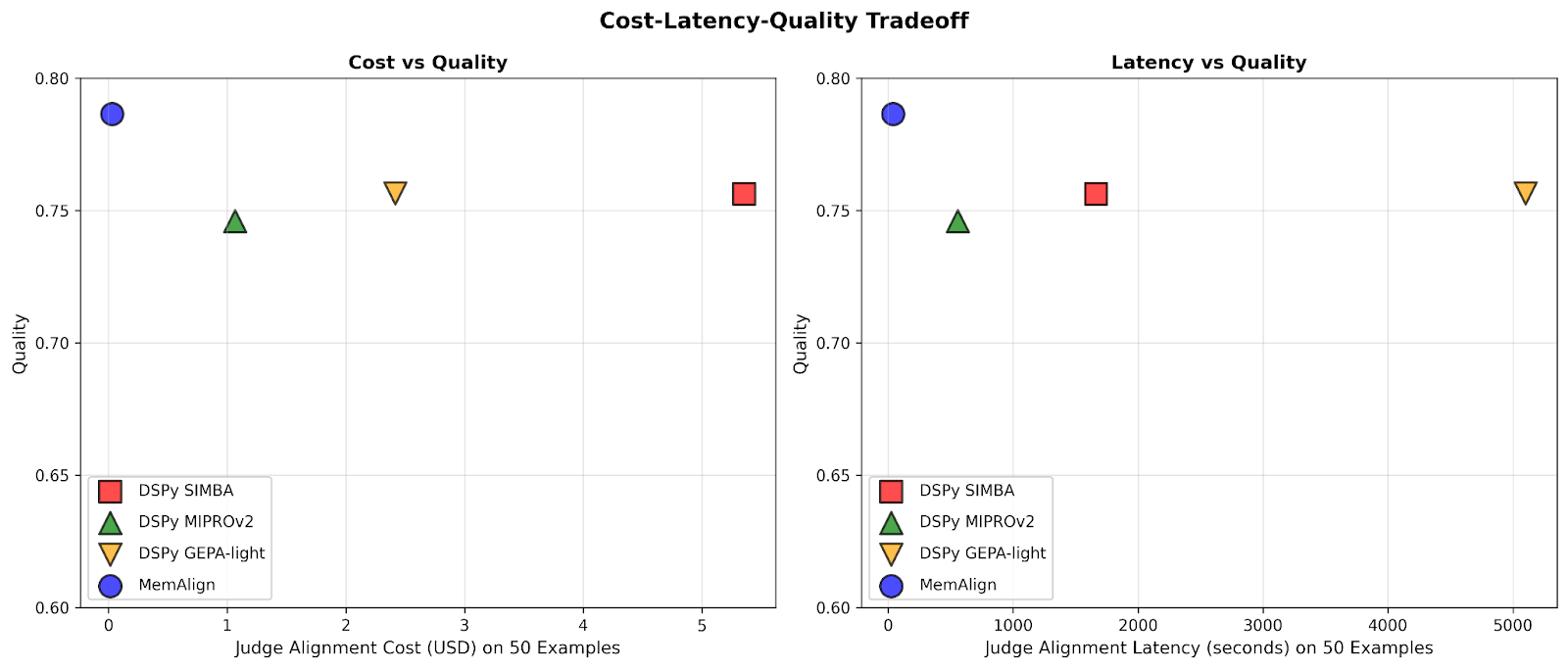
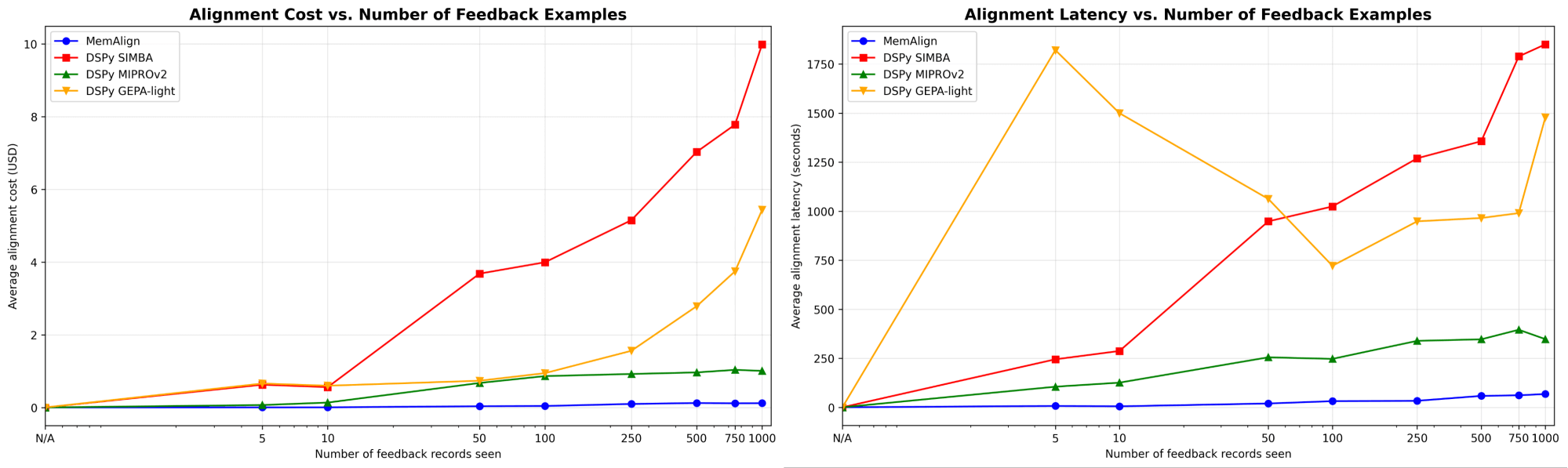
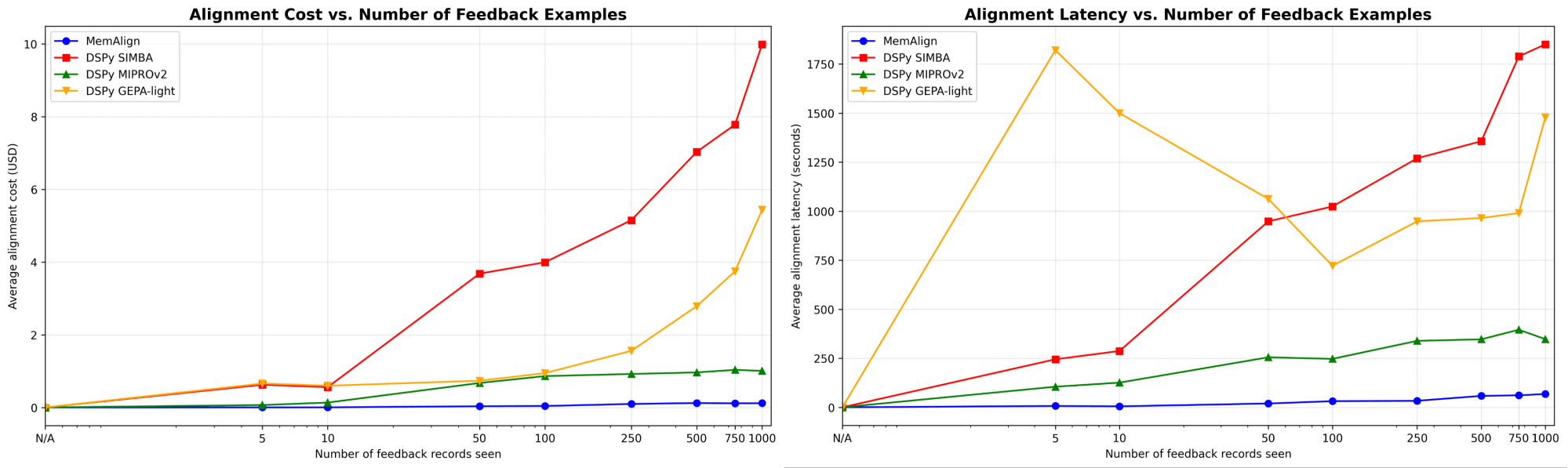
MemAlign s'adapte de manière spectaculairement plus rapide et moins chère
Nous montrons d'abord la vitesse et le coût d'alignement de MemAlign par rapport aux optimiseurs de prompts de DSPy :
{kind=link}
Lorsque la quantité de feedback atteint des centaines, voire un millier d'exemples, l'alignement devient de plus en plus rapide et rentable par rapport aux modèles de référence. MemAlign s'adapte en quelques secondes avec moins de 50 exemples et en environ 1,5 minute avec jusqu'à 1 000 exemples, pour un coût de seulement 0,01 à 0,12 $ par phase. Pendant ce temps, les optimiseurs de prompts de DSPy nécessitent de plusieurs à des dizaines de minutes par cycle et coûtent 10 à 100 fois plus cher. (Il est intéressant de noter que le pic de latence initial de GEPA est dû à des scores de validation instables et à une augmentation des appels de réflexion pour les échantillons de petite taille.) En pratique, MemAlign permet des boucles de feedback interactives et rapides : un expert peut examiner un jugement, expliquer ce qui ne va pas et voir le système s'améliorer quasi instantanément.1
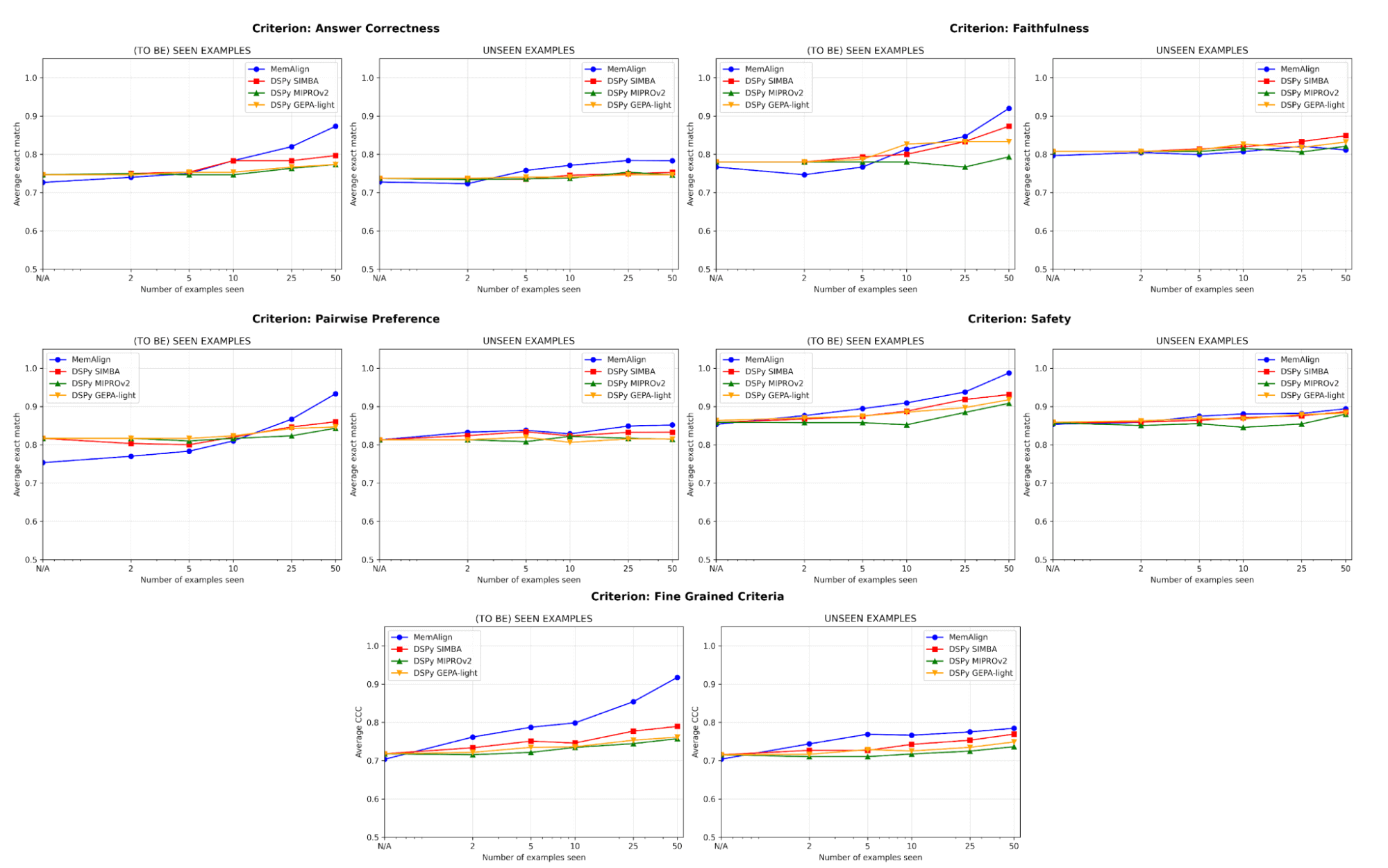
Une qualité qui égale l'état de l'art et s'améliore avec le feedback
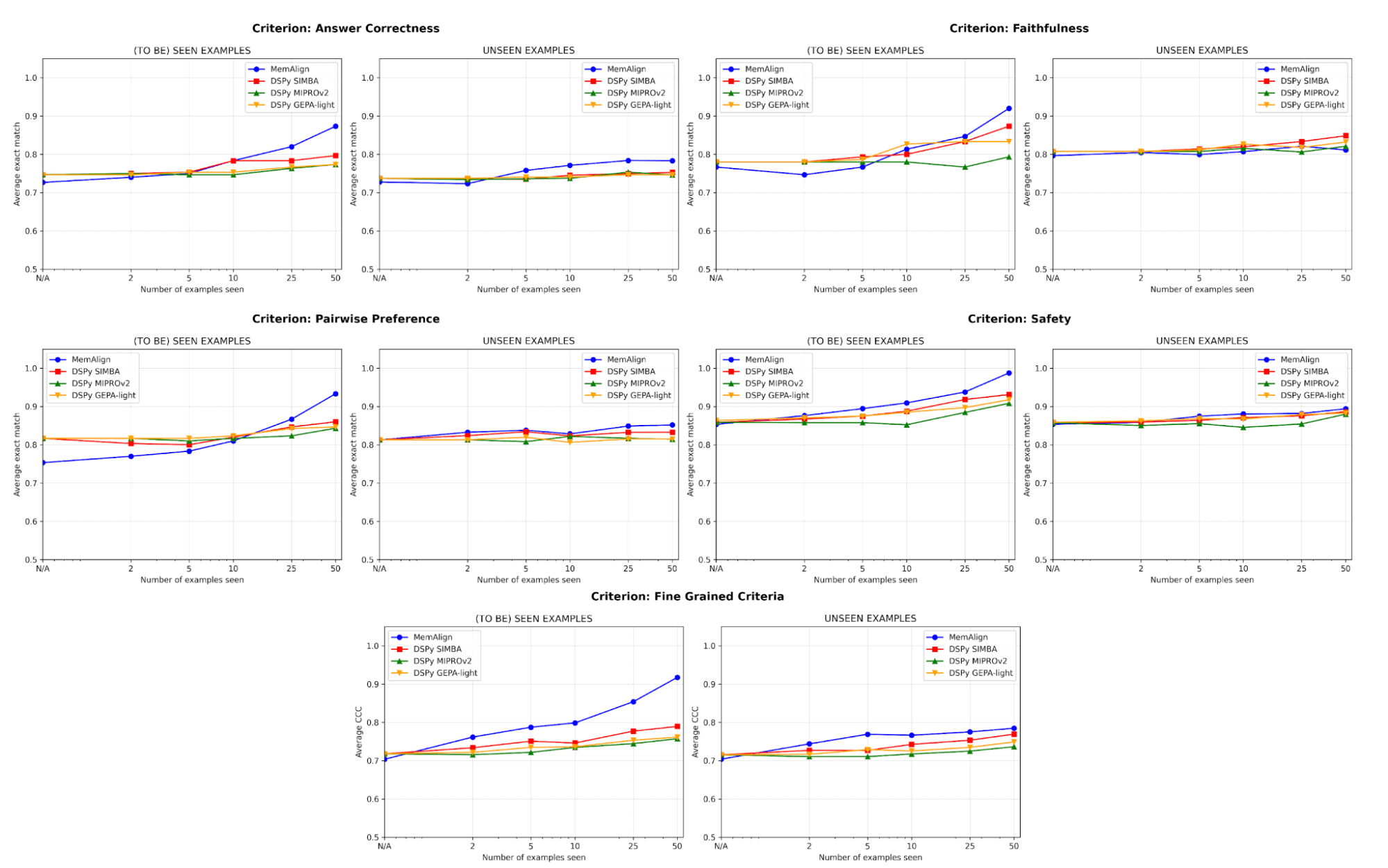
En termes de qualité, nous comparons les performances du juge après adaptation sur un nombre croissant d'exemples en utilisant MemAlign par rapport aux optimiseurs de prompts de DSPy :
{kind=link}
L'un des plus grands risques dans l'alignement est la régression : corriger une erreur pour ensuite la réintroduire plus tard. Sur tous les critères, MemAlign est plus performant sur les exemples vus (à gauche), atteignant souvent une précision de plus de 90 %, tandis que d'autres méthodes plafonnent souvent entre 70 et 80 %.
Sur des exemples inédits (à droite), MemAlign fait preuve d'une généralisation compétitive. Il surpasse les optimiseurs de prompts de DSPy sur la correction des réponses et obtient des résultats très similaires sur d'autres critères. Cela indique qu'il ne se contente pas de mémoriser les corrections, mais qu'il extrait des connaissances transférables du feedback.
Ce comportement illustre ce que nous appelons l'évolutivité de la mémoire: contrairement à l'évolutivité au moment du test qui augmente le compute par query, l'évolutivité de la mémoire améliore la qualité en accumulant le feedback de manière persistante dans le temps.
Pas besoin de beaucoup d'exemples pour commencer
Plus important encore, MemAlign montre une amélioration visible avec seulement 2 à 10 exemples, en particulier sur les critères précis et l'exactitude des réponses. Dans les rares cas où MemAlign start plus bas (p. ex. Préférence par paires), il rattrape rapidement son retard avec 5 à 10 exemples. Cela signifie que vous n'avez pas besoin de fournir un effort d'étiquetage massif au départ avant d'en voir les bénéfices. Une amélioration significative se produit presque immédiatement.
Sous le capot : comment fonctionne MemAlign ?
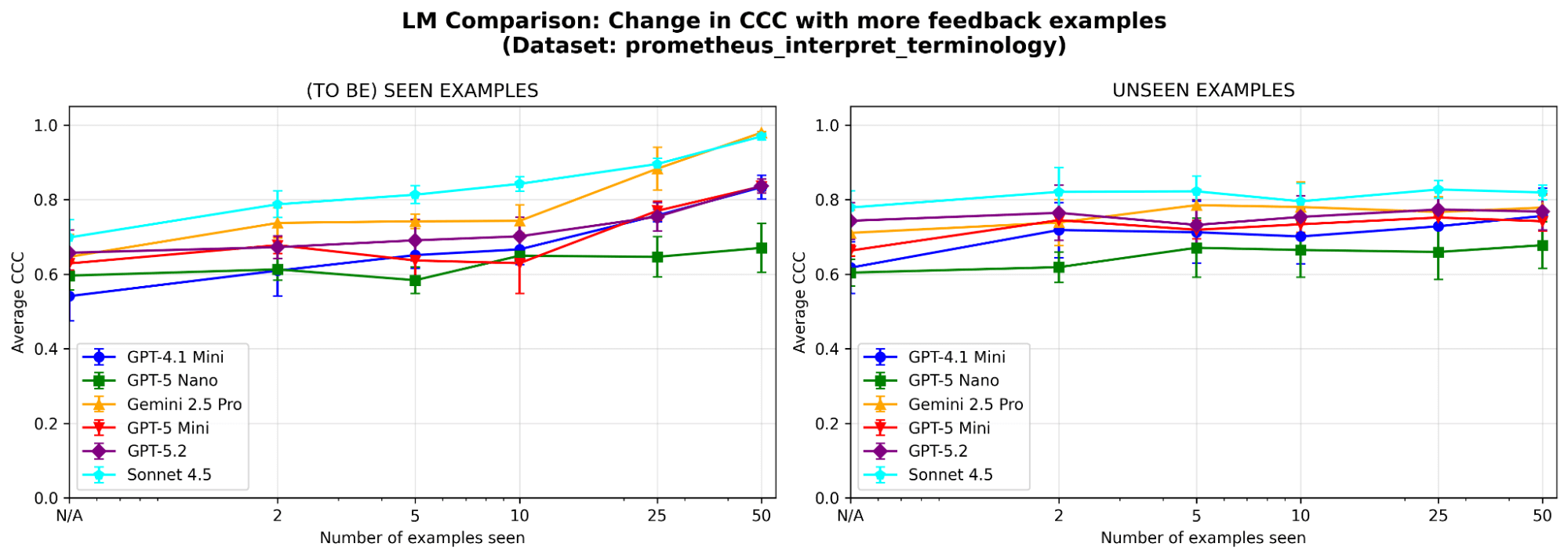
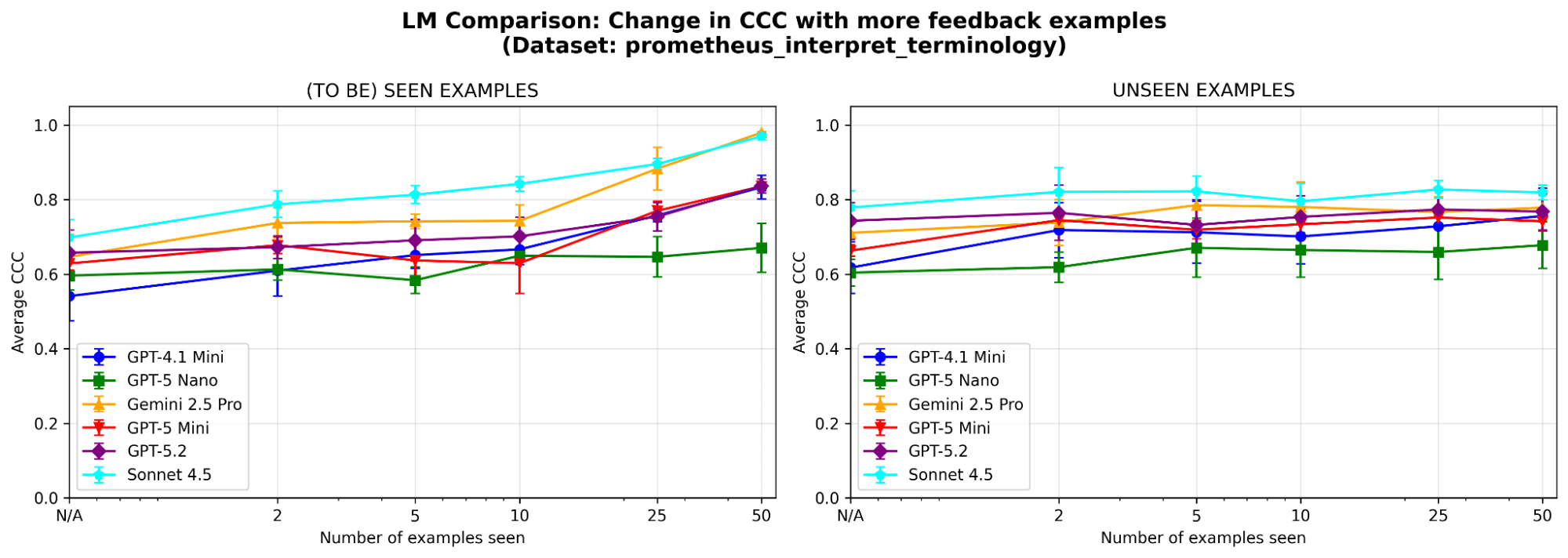
Pour mieux comprendre le comportement du système, nous effectuons des ablations supplémentaires sur un exemple de dataset (où le critère du juge est « Le modèle peut-il interpréter correctement la terminologie technique ou le jargon spécifique à un secteur ? ») du benchmark prometheus-eval. Nous utilisons le même LLM (GPT-4.1-mini) que dans les expérimentations principales.
Les deux modules de mémoire sont-ils nécessaires ? Après l'ablation de chaque module de mémoire, nous observons une baisse des performances dans les deux cas. Supprimez la mémoire sémantique et le juge perd sa base stable de principes ; supprimez la mémoire épisodique et il aura des difficultés avec les cas limites. Les deux composants sont importants pour les performances.
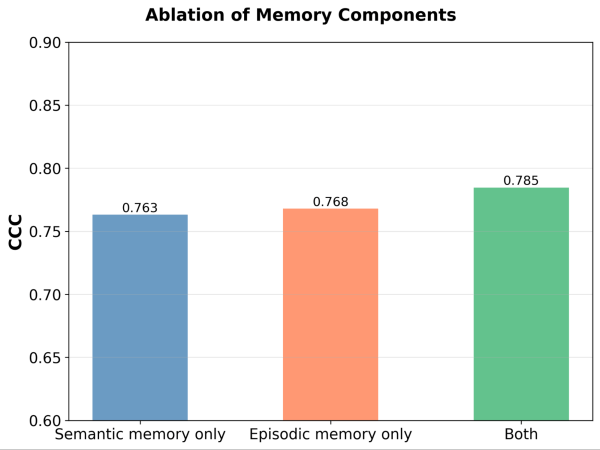
Figure 5. Performance (mesurée par le coefficient de corrélation de concordance (CCC)) de MemAlign avec uniquement la mémoire sémantique, uniquement la mémoire épisodique, ou les deux activées.
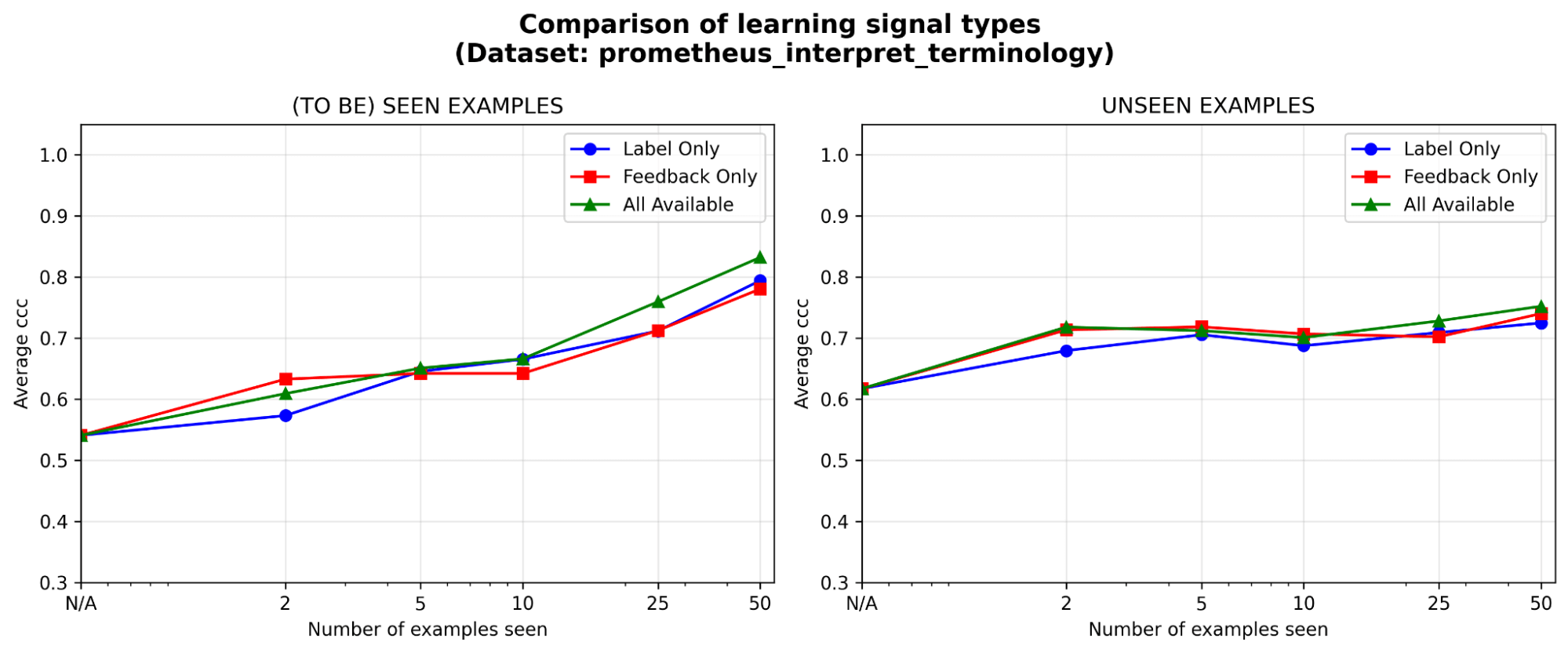
Le feedback est au moins aussi efficace que les étiquettes, surtout au début. Avec un budget d'annotation fixe, dans quel type de signal d'apprentissage est-il le plus judicieux d'investir : les étiquettes, le feedback en langage naturel, ou les deux ? Nous observons un léger avantage initial (<=5 exemples) pour le feedback par rapport aux étiquettes, l'écart se réduisant à mesure que les exemples s'accumulent. Cela signifie que si vos experts n'ont le temps que pour quelques exemples, il est peut-être préférable de leur demander d'expliquer leur raisonnement ; sinon, les étiquettes seules pourraient suffire.
{kind=link}
MemAlign est-il sensible au choix du LLM ? Nous exécutons MemAlign avec des LLM de familles et de tailles différentes. Dans l'ensemble, Claude-4.5 Sonnet est le plus performant. Mais les modèles plus petits montrent tout de même une amélioration substantielle : par exemple, même si GPT-4.1-mini démarre bas, il égale les performances des modèles de pointe comme GPT-5.2 après avoir vu 50 exemples. Cela signifie que vous n'êtes pas contraint d'utiliser des modèles de pointe coûteux pour obtenir de la valeur.
{kind=link}
Points à retenir
MemAlign comble le fossé entre les LLM généralistes et les nuances spécifiques à un domaine grâce à une architecture à double mémoire qui permet un alignement rapide et peu coûteux. Il reflète une philosophie différente : exploiter le feedback dense en langage naturel d'experts humains plutôt que de l'approximer avec un grand nombre d'étiquettes. Plus largement, MemAlign met en évidence la promesse de l'évolutivité de la mémoire: en accumulant les enseignements au lieu de ré-optimiser à plusieurs reprises, les agents peuvent continuer à s'améliorer sans sacrifier la vitesse ou le coût. Nous pensons que ce paradigme sera de plus en plus important pour les flux de travail d'agents de longue durée avec un expert dans la boucle.
MemAlign est désormais disponible en tant qu'algorithme d'optimisation derrière la méthode align() de MLFlow. Consultez ce Notebook de démo pour commencer !
1Les résultats ci-dessus comparent la vitesse d'alignement ; au moment de l'inférence, MemAlign peut entraîner un temps supplémentaire de 0,8 à 1 s par exemple en raison de la recherche vectorielle en mémoire, par rapport aux juges optimisés par prompt.
Auteurs : Veronica Lyu, Kartik Sreenivasan, Samraj Moorjani, Alkis Polyzotis, Sam Havens, Michael Carbin, Michael Bendersky, Matei Zaharia, Xing Chen
Nous tenons à remercier Krista Opsahl-Ong, Tomu Hirata, Arnav Singhvi, Pallavi Koppol, Wesley Pasfield, Forrest Murray, Jonathan Frankle, Eric Peter, Alexander Trott, Chen Qian, Wenhao Zhan, Xiangrui Meng, Moonsoo Lee et Omar Khattab pour leur feedback et leur soutien tout au long de la conception, de la mise en œuvre et de la publication du blog de MemAlign. Nous sommes également reconnaissants à Michael Shtelma, Nancy Hung, Ksenia Shishkanova et Flo Health de nous avoir aidés à évaluer MemAlign sur leurs datasets internes anonymisés
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.