Conformité BSA/AML moderne sur Databricks
Comment la Databricks Data Intelligence Platform unifie les systèmes AML cloisonnés, le scoring de risque ML et un ensemble d'agents AI dans un workflow unique et gouverné : de l'alerte au dépôt du SAR.
par Kateryna Savchyn , Pavithra Rao, Mimi Park et Emerson Bayuk
- De quoi s'agit-il ? Une expérience unifiée, augmentée par des agents AI et le machine learning, pour les analystes AML et les décideurs, s'appuyant sur la Databricks Data Intelligence Platform.
- Quel problème cela résout-il ? Elle consolide les systèmes cloisonnés qui consomment la majeure partie du temps des analystes lors d'une enquête AML, enrichit la détection basée sur des règles avec un scoring de risque basé sur le ML, et accélère la création de rapports SAR de quelques heures à quelques minutes — le tout au sein d'un environnement unique et gouverné.
- Quels résultats les équipes AML peuvent-elles attendre ? Un traitement des dossiers 8 à 10 fois plus rapide, une réduction de 75 % des faux positifs et de 50 à 150 millions de dollars d'économies annuelles pour les institutions de taille moyenne à grande.
La fonction de lutte contre le blanchiment d'argent (AML) dans les services financiers s'est historiquement organisée autour de deux responsabilités : le traitement des alertes d'activités potentielles de blanchiment d'argent et la documentation de la résolution de chaque cas, y compris le dépôt de rapports d'activités suspectes (SAR) lorsque cela est justifié, tout en maintenant l'efficacité du programme et l'auditabilité des processus. Ce modèle est aujourd'hui sous pression. L'évolution des typologies de criminalité financière, les attentes réglementaires en matière d'explicabilité en temps réel et la maturité de l'AI générative redéfinissent ce à quoi ressemble une pratique AML moderne. On attend de plus en plus des responsables AML qu'ils orientent le temps des analystes vers un véritable travail d'enquête sur la criminalité financière, plutôt que vers la collecte de données, le tri des faux positifs et la rédaction de rapports qui dominent aujourd'hui la charge de travail.
La contrainte est rarement liée au talent ou à l'intention. Il s'agit plutôt du frein structurel imposé à chaque alerte par des systèmes fragmentés, des scores d'éditeurs opaques et l'assemblage manuel des preuves. Tant que ce frein n'est pas levé, les programmes AML, aussi bien financés soient-ils, restent bloqués dans un mode de traitement des retards accumulés.
Pourquoi les opérations AML se heurtent à un mur de productivité
Le cycle d'investigation AML typique est aujourd'hui manuel et sujet aux erreurs. Les analystes passent de trois à six heures par cas à extraire et corréler des données provenant de 10 systèmes cloisonnés ou plus, notamment : la connaissance du client (KYC), la surveillance des transactions, le filtrage des sanctions, la gestion des cas, les médias indésirables, les bénéficiaires effectifs, le CRM interne, les journaux d'agence et les bases de connaissances réglementaires — le tout assemblé dans des feuilles de calcul et des modèles Word. La majeure partie de ce temps est consacrée aux faux positifs : PwC estime que 90 à 95 % de toutes les alertes générées par les systèmes de surveillance des transactions ne sont pas exploitables, mais chacune d'elles nécessite le même effort d'investigation qu'un vrai positif car rien ne relie automatiquement les preuves. La surveillance basée sur des règles de première génération est de plus en plus dépassée par les techniques de fraude modernes basées sur l'AI.
Ce frein se manifeste à quatre niveaux :
- Plus de 10 systèmes cloisonnés. Les analystes constituent de fait la couche d'intégration. Chaque alerte nécessite de s'authentifier à nouveau sur plusieurs portails de fournisseurs, de copier des valeurs dans un document de travail et de rapprocher les identifiants à la main.
- Taux élevé de faux positifs. Les règles et modèles de détection qui ne sont pas continuellement actualisés face à l'évolution des typologies de criminalité financière peuvent s'écarter des schémas d'activité réels, générant des alertes sur des transactions qui s'avèrent finalement légitimes. Chaque alerte consomme toujours les mêmes 3 à 6 heures d'effort d'investigation, quel que soit le résultat.
- Documentation manuelle des cas. Chaque cas nécessite une décision écrite — escalade, rejet en tant que faux positif ou dépôt de SAR — documentée et archivée pour l'audit réglementaire. Les analystes rédigent ces comptes rendus à la main à partir de zéro, en citant les mêmes réglementations et en structurant les mêmes dossiers de preuves cas après cas. Les données de l'enquête du Bank Policy Institute évaluent l'effort des banques pour les seuls dépôts de SAR à environ 21,4 heures par dépôt — soit plus de dix fois l'estimation du Paperwork Reduction Act du FinCEN lui-même.
- Scores d'éditeurs opaques. Les plateformes AML prêtes à l'emploi exposent généralement des seuils de scénarios pour l'ajustement, mais les artefacts de modèle sous-jacents, l'ingénierie des caractéristiques et la cadence de réentraînement résident souvent dans l'environnement du fournisseur — ce qui rend plus difficile pour les institutions de satisfaire aux normes de gestion du risque de modèle (par exemple, SR 11-7) et de répondre rapidement lorsque les régulateurs demandent comment un score particulier a été produit.
L'effet cumulatif est un retard accumulé qui augmente plus vite que la capacité des équipes à le traiter. Dans l'enquête PwC EMEA AML Survey 2024, 44 % des institutions financières citent l'intensification des réglementations sur la criminalité financière comme le facteur le plus pressant compliquant les opérations de conformité — et les typologies de la prochaine décennie (paiements en temps réel, finance intégrée, passerelles crypto-fiat, identité synthétique à grande échelle) ne feront qu'élargir ce fossé.
La solution : la plateforme Databricks Data Intelligence Platform
Pour passer du traitement des retards à l'investigation, les équipes AML ont besoin d'une plateforme qui ne se contente pas de stocker les alertes, mais qui les analyse intelligemment, et ce, dans le cadre de gouvernance attendu par un régulateur. La plateforme Databricks Data Intelligence Platform rassemble la surveillance des transactions, le KYC, le filtrage des sanctions, les connaissances réglementaires et les agents AI sous la gouvernance d'Unity Catalog, avec une traçabilité complète, de la transaction brute au SAR déposé. Chaque composant est modulable plutôt que d'être proposé en tout ou rien : les institutions peuvent adopter l'intégralité de la suite de bout en bout ou intégrer des éléments individuels dans leurs flux de travail existants, ce qui est particulièrement utile pour les équipes qui commencent tout juste à se moderniser. Six capacités distinguent cette approche des solutions AML traditionnelles :
1. Une couche de données de conformité unifiée gouvernée par Unity Catalog
Unity Catalog consolide plus de 10 systèmes cloisonnés en un seul lakehouse gouverné. Le core banking, les flux de surveillance des transactions, les profils KYC, les correspondances de sanctions, l'historique des cas et la bibliothèque de documents de politique AML de l'institution sont intégrés via Lakeflow Connect dans une architecture médaillon Bronze → Silver → Gold, avec une qualité de données imposée par Delta, un masquage de colonnes pour les PII des clients et une sécurité au niveau des lignes liée à l'équipe et au rôle. Chaque artefact en aval — le score de risque, la chaîne de preuves de l'agent, le rapport SAR — fait l'objet d'un suivi de traçabilité jusqu'à sa ligne d'origine et son horodatage d'intégration. Lorsque l'examinateur demande ce qui a déclenché l'alerte, quelles preuves ont soutenu le dépôt ou comment l'institution a traité des cas structurellement similaires, la réponse est une requête reproductible plutôt que le souvenir d'un analyste. La gouvernance, la traçabilité et le respect de la qualité sont des propriétés intrinsèques de la plateforme, et non une couche supplémentaire.
2. Le ML de bout en bout pour la détection et le scoring des risques
Les moteurs de règles statiques sont enrichis, et non remplacés. La plateforme Databricks Data Intelligence Platform offre aux équipes de data science et de lutte contre la criminalité financière les bases nécessaires pour développer, entraîner et déployer des modèles ML de pointe, adaptés à l'historique des transactions, à la clientèle et au profil de risque propres à l'institution — alimentant ainsi en signaux plus riches la file d'attente des alertes et le contexte de l'investigation. Les modèles sont enregistrés dans MLflow avec des alias champion/challenger et un suivi complet des expériences ; Model Serving expose le modèle actif ; Lakehouse Monitoring observe la dérive et les performances en production ; et les tables d'inférence capturent les retours des analystes pour alimenter le réentraînement du challenger. À mesure que les challengers s'avèrent supérieurs, les équipes les promeuvent via la gestion du cycle de vie de MLflow. Chaque alerte peut afficher une explication des règles métier et des signaux ML qui l'ont déclenchée, de sorte que l'analyste ouvre un dossier en sachant déjà pourquoi il a atterri dans la file d'attente. Le résultat est une réduction de 75 % des faux positifs atteignant la file d'attente des analystes — sans avoir à remplacer le moteur de règles de surveillance des transactions sous-jacent.
3. Une flotte d'agents AI spécialisés travaillant de concert
Le cœur de cette modernisation est un assistant de chat multi-agent qui orchestre une flotte de sous-agents spécialisés lors d'une investigation, s'appuyant sur Agent Bricks. Plutôt que de se connecter à plusieurs systèmes pour corréler manuellement les données, l'analyste travaille à partir d'une page d'investigation unique qui présente les notes de diligence passées, les notes de dossier, les dépôts de SAR antérieurs, les schémas de transaction et les relations entre entités dans une vue unique. La flotte d'agents parcourt l'ensemble du réseau de données disponibles et renvoie une recommandation éclairée sur la manière de traiter le cas, l'humain restant pleinement décisionnaire pour le choix final : escalader vers une équipe spécialisée, rejeter en tant que faux positif ou procéder au dépôt de SAR. L'effet de bout en bout : une investigation qui nécessitait auparavant trois à six heures de travail manuel se réduit à quelques minutes d'examen assisté par agent.

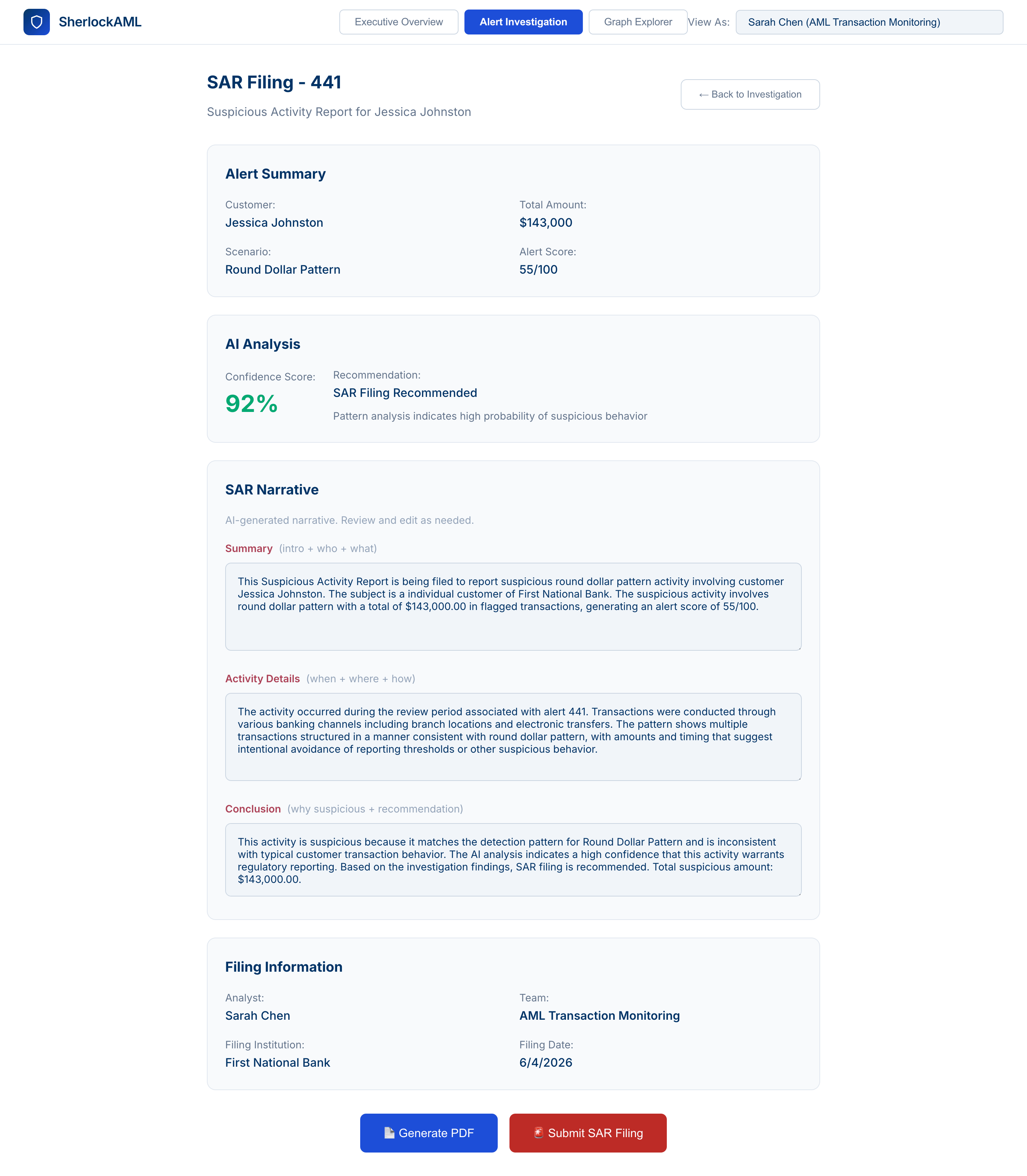
4. Génération de SAR assistée par l'AI, de quelques heures à quelques minutes
Lorsque l'analyste procède au dépôt du SAR, la même flotte d'agents pré-remplit les métadonnées contextuelles recueillies au cours de l'enquête et rédige un aperçu et un récit personnalisés pour le rapport. L'analyste vérifie les faits, personnalise et génère le PDF ; l'AI structure le document pour respecter les spécifications de format requises par l'institution avant la soumission. Les rapports déposés sont envoyés vers le backend avec un enregistrement entièrement traçable du point de vue de l'auditabilité. La création de rapports SAR, qui prenait traditionnellement des heures, se fait désormais en quelques minutes. De plus, cela boucle automatiquement la boucle et fait instantanément remonter la déclaration en tant que contexte et preuve supplémentaires pour les cas activement analysés en parallèle par le reste de l'équipe AML.
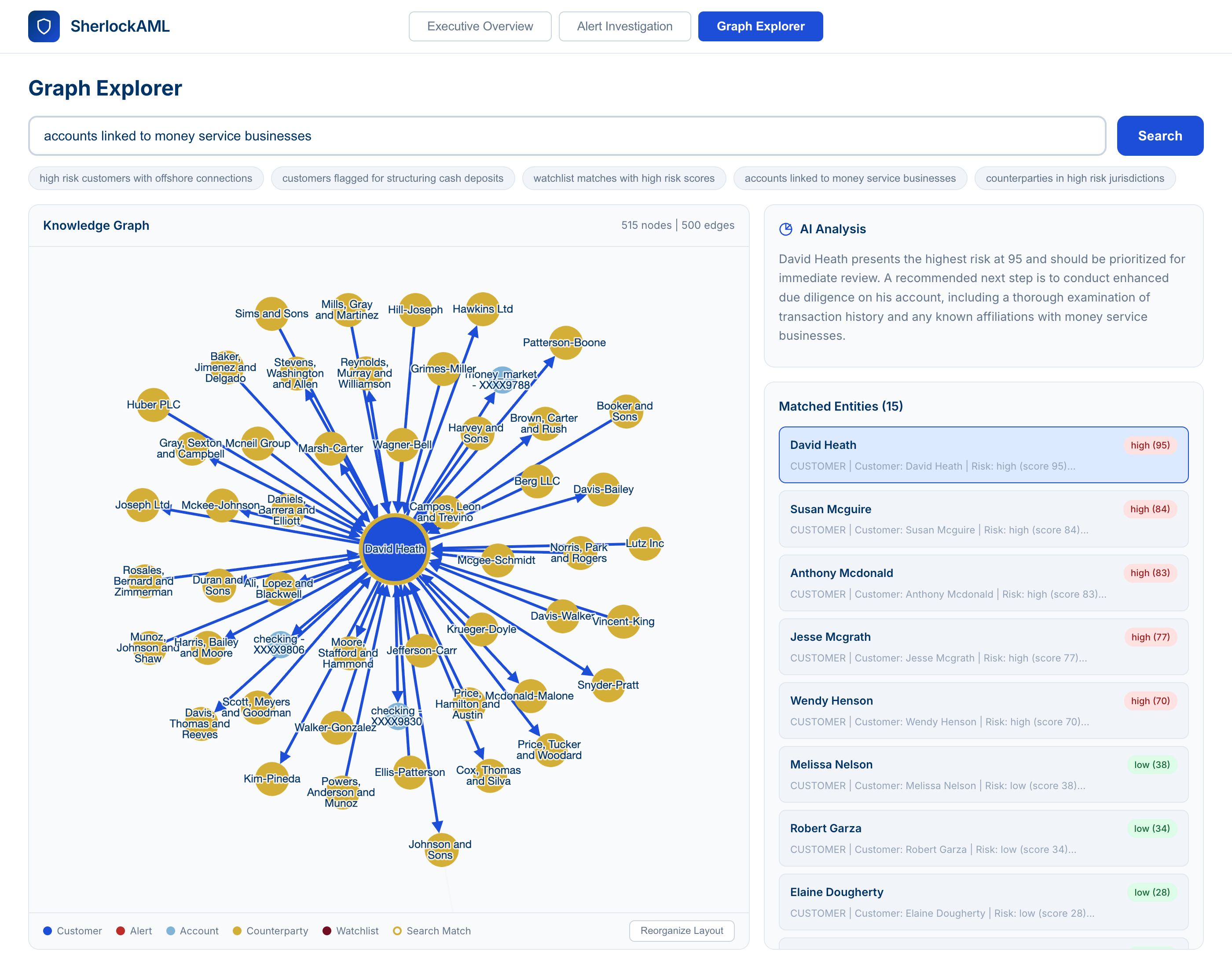
5. Visualisation de graphes pour la détection de schémas de réseau
Une couche de graphe, mise en évidence par des visualisations interactives dans l'espace de travail de l'analyste, permet à ce dernier de passer de la page d'enquête à une vue complète du graphe, de poser des questions en langage naturel au graphe lui-même ou d'accéder à n'importe quelle entité individuelle pour explorer les relations de contrepartie. Cela permet de découvrir les schémas de réseau cachés que les systèmes basés sur des règles ne détectent pas : sociétés écrans, structures de superposition et flux de fonds circulaires.
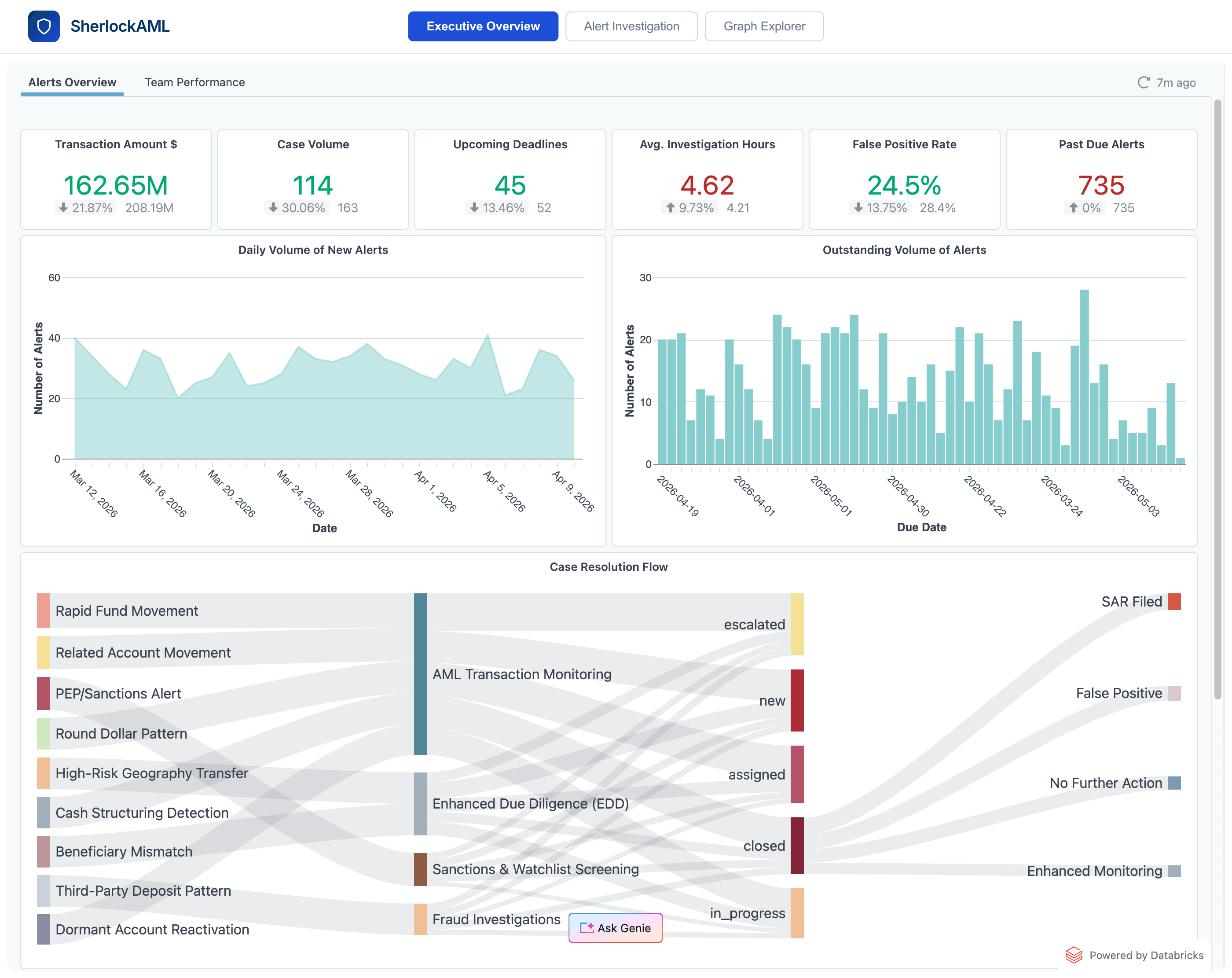
6. Rapports de direction avec interface en langage naturel
La direction AML accède à une vue exécutive qui présente les KPI de volume de cas, les heures passées et les alertes en retard ; des courbes de tendance pour la détection et l'ancienneté ; une visualisation du flux de processus, de la détection à la résolution en passant par l'attribution aux équipes ; et des répartitions par scénario et criticité. Une vue Performance de l'équipe permet d'analyser en détail le débit d'incidents, la pression des échéances et le temps de traitement moyen par type de détection et par équipe, ce qui permet d'identifier facilement les goulots d'étranglement dans le processus et les opportunités de rééquilibrer l'équipe pour respecter les échéances critiques. Le chat en langage naturel sur ces mêmes données gouvernées permet des analyses approfondies en libre-service sur les tendances sans attendre l'équipe d'analystes : Genie permet aux responsables AML de poser des questions telles que « Quelles relations de conseillers ont déclenché le plus d'alertes de structuration au cours du dernier trimestre, et quel est le taux de faux positifs par équipe ? » et de recevoir une réponse prête pour l'audit en quelques secondes.
Conclusion : une nouvelle norme pour la direction AML
Les équipes AML n'ont plus à choisir entre la productivité des analystes et la défendabilité réglementaire. Une Data Intelligence Platform gouvernée, où les alertes, les preuves, les agents et les pistes d'audit coexistent dans le même environnement avec suivi de la traçabilité, offre les deux. L'approche traditionnelle consistant à accumuler « plus d'analystes, plus de fournisseurs, plus de feuilles de calcul » n'est plus compétitive face aux institutions qui ont unifié leurs données de conformité et laissent les agents AI gérer la charge des investigations multi-sources. Cette transition n'est pas une aspiration future ; c'est une décision opérationnelle disponible dès aujourd'hui.
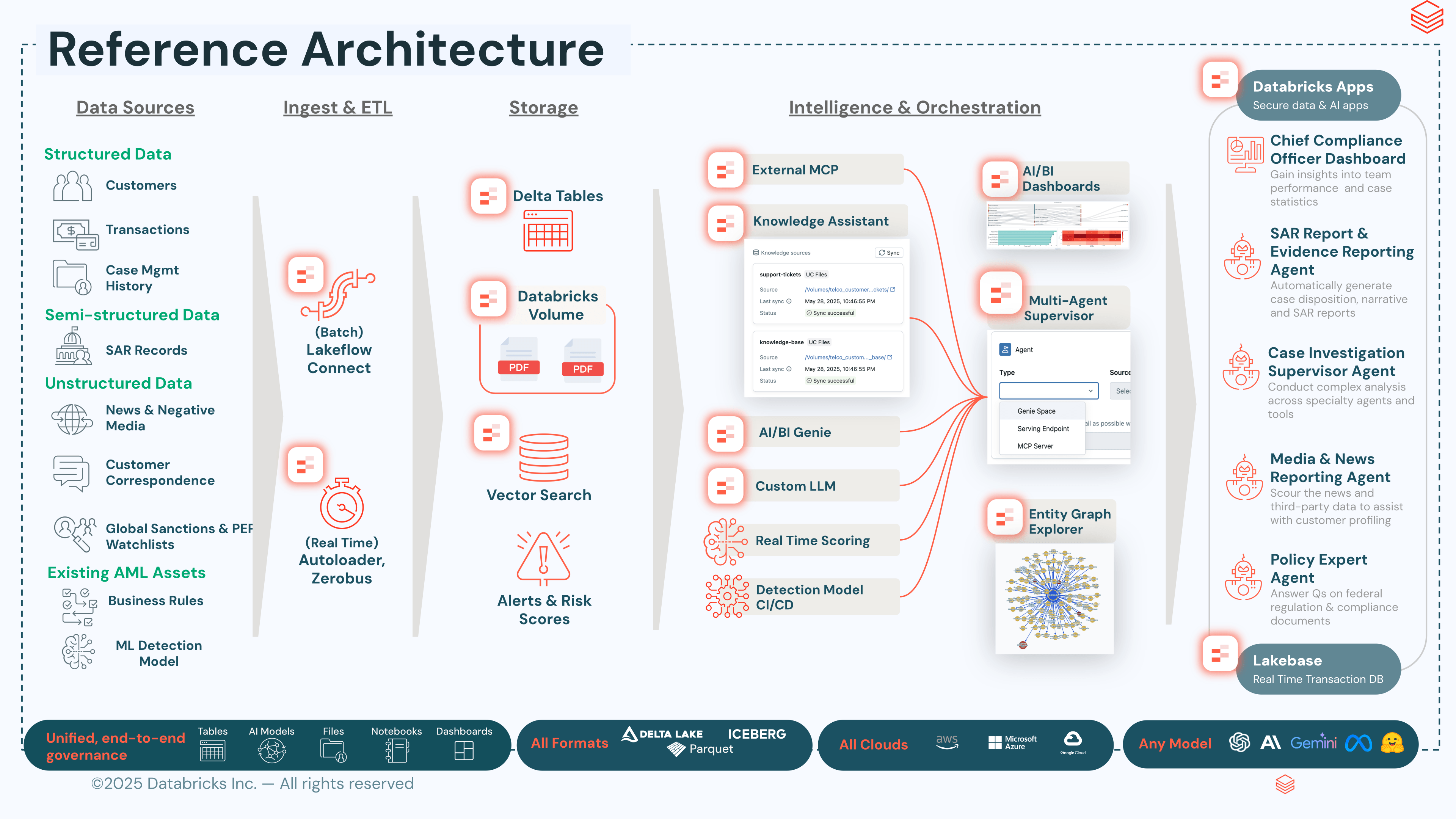
L'architecture en bref
La solution se compose de temps de cinq fonctionnalités disponibles sur la Data Intelligence Platform de Databricks :
- Ingestion et gouvernance. Lakeflow Connect achemine les données bancaires de base, les flux de surveillance des transactions, les profils KYC, les correspondances de sanctions, l'historique des cas et les documents de politique générale dans un médaillon Bronze → Silver → Gold dans Delta, avec Unity Catalog appliquant le masquage des colonnes, la sécurité au niveau des lignes et la traçabilité de bout en bout.
- Scoring. Les modèles de détection — adaptés à l'historique des transactions et au profil de risque propres à l'institution — sont entraînés et déployés via MLflow avec des alias champion/challenger ; Model Serving expose le modèle actif ; Lakehouse Monitoring surveille la dérive ; et les tables d'inférence capturent les retours des analystes qui alimentent le réentraînement du challenger.
- Raisonnement. Un assistant multi-agent basé sur Agent Bricks orchestre les agents Genie pour les requêtes structurées, les assistants de connaissances RAG s'appuyant sur Vector Search pour parcourir la bibliothèque de réglementations et de politiques de l'institution, les agents externes mis à disposition via le MCP Marketplace, et une couche de graphe qui résout les entités et découvre les structures de contrepartie cachées.
- État opérationnel. Databricks Lakebase — une base de données Postgres gérée et entièrement intégrée au lakehouse — sert de backend opérationnel pour les agents et les applications. L'état des cas, les notes des analystes, l'historique des conversations des agents, les brouillons de SAR et le statut du flux de travail sont conservés dans Lakebase avec des lectures et écritures à faible latence, tout en restant synchronisés avec les tables Delta sous la même gouvernance, traçabilité et contrôles d'accès de Unity Catalog qui s'appliquent aux données analytiques.
- Expérience des analystes et des dirigeants. Databricks Apps fournit l'espace de travail d'investigation des analystes, la vue exécutive, l'explorateur de graphes et l'interface de soumission des SAR, lisant et écrivant l'état opérationnel via Lakebase avec une traçabilité d'audit complète sur les rapports déposés.
Déploiement modulaire
Les cinq couches peuvent être déployées indépendamment ou sous forme de pile complète. Une banque qui utilise déjà son propre moteur de surveillance des transactions peut adopter uniquement les couches de scoring ou de raisonnement pour ajouter le scoring de risque ML et l'investigation augmentée par l'AI en plus des alertes existantes ; une banque disposant d'une gestion des cas mature mais de données fragmentées peut commencer par la couche d'ingestion et de gouvernance pour consolider d'abord les sources. Comme chaque composant partage la même Data Intelligence Platform et la même gouvernance Unity Catalog, les déploiements partiels s'accumulent pour former l'architecture complète sans changement de plateforme.
Déploiement modulaire
Les cinq couches peuvent être déployées indépendamment ou sous forme de pile complète. Une banque qui utilise déjà son propre moteur de surveillance des transactions peut adopter uniquement les couches de scoring ou de raisonnement pour ajouter le scoring de risque ML et l'investigation augmentée par l'AI en plus des alertes existantes ; une banque disposant d'une gestion des cas mature mais de données fragmentées peut commencer par la couche d'ingestion et de gouvernance pour consolider d'abord les sources. Comme chaque composant partage la même Data Intelligence Platform et la même gouvernance Unity Catalog, les déploiements partiels s'accumulent pour former l'architecture complète sans changement de plateforme.
Découvrez-le en action
▸ Déployez la solution dans votre espace de travail
▸ Contactez-nous : contactez votre équipe de compte Databricks pour intégrer cela à votre flux de travail AML existant dès aujourd'hui !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.