La nouvelle façon de créer des pipelines sur Databricks : Présentation de l'IDE pour l'ingénierie des données
Une nouvelle expérience développeur spécialement conçue pour la création de pipelines déclaratifs Spark Lakeflow
par Adriana Ispas, Lennart Kats, Camiel Steenstra et Monica Alvarez Vicente
- Les pipelines déclaratifs Spark disposent désormais d'une expérience développeur IDE dédiée dans l'espace de travail Databricks.
- Le nouvel IDE améliore la productivité et le débogage grâce à des fonctionnalités telles que les graphes de dépendances, les aperçus et les informations d'exécution.
- L'IDE prend en charge l'intégration rapide et les cas d'utilisation avancés tels que l'intégration Git, CI/CD et l'observabilité.
Lors du Data + AI Summit de cette année, nous avons présenté l'IDE pour l'ingénierie des données : une nouvelle expérience développeur conçue pour la création de pipelines de données directement dans l'espace de travail Databricks. En tant que nouvelle expérience de développement par défaut, l'IDE reflète notre approche réfléchie de l'ingénierie des données : déclarative par défaut, modulaire dans sa structure, intégrée à Git et assistée par l'IA.
En bref, l'IDE pour l'ingénierie des données est tout ce dont vous avez besoin pour créer et tester des pipelines de données - le tout au même endroit.
Avec cette nouvelle expérience de développement disponible en aperçu public, nous aimerions utiliser ce blog pour expliquer pourquoi les pipelines déclaratifs bénéficient d'une expérience IDE dédiée et mettre en évidence les fonctionnalités clés qui rendent le développement de pipelines plus rapide, plus organisé et plus facile à déboguer.
L'ingénierie des données déclarative obtient une expérience développeur dédiée
Les pipelines déclaratifs simplifient l'ingénierie des données en vous permettant de déclarer ce que vous voulez accomplir au lieu d'écrire des instructions détaillées étape par étape sur la façon de le construire. Bien que la programmation déclarative soit une approche extrêmement puissante pour construire des pipelines de données, travailler avec plusieurs jeux de données et gérer le cycle de vie complet du développement peut devenir difficile à gérer sans outils dédiés.
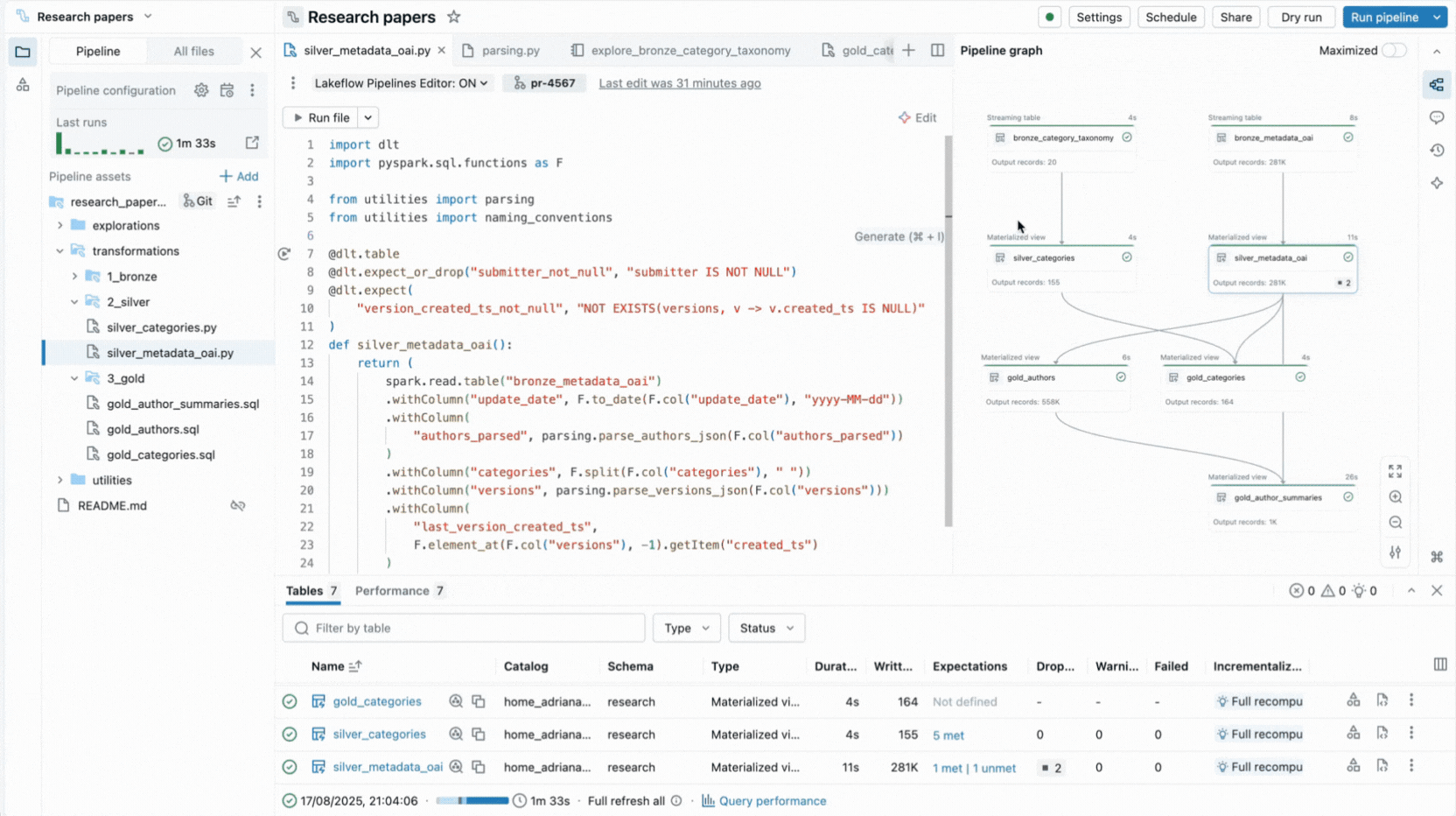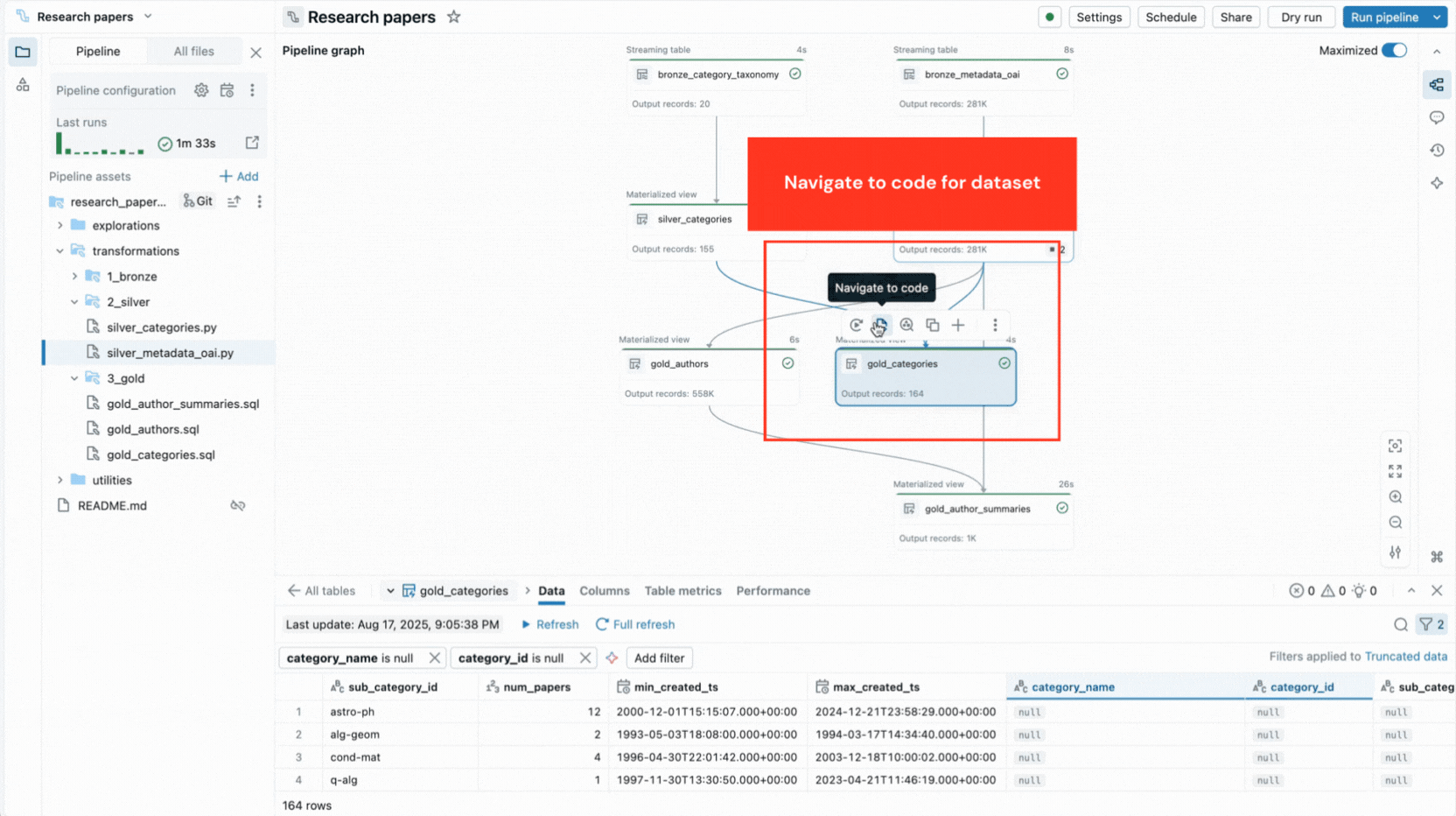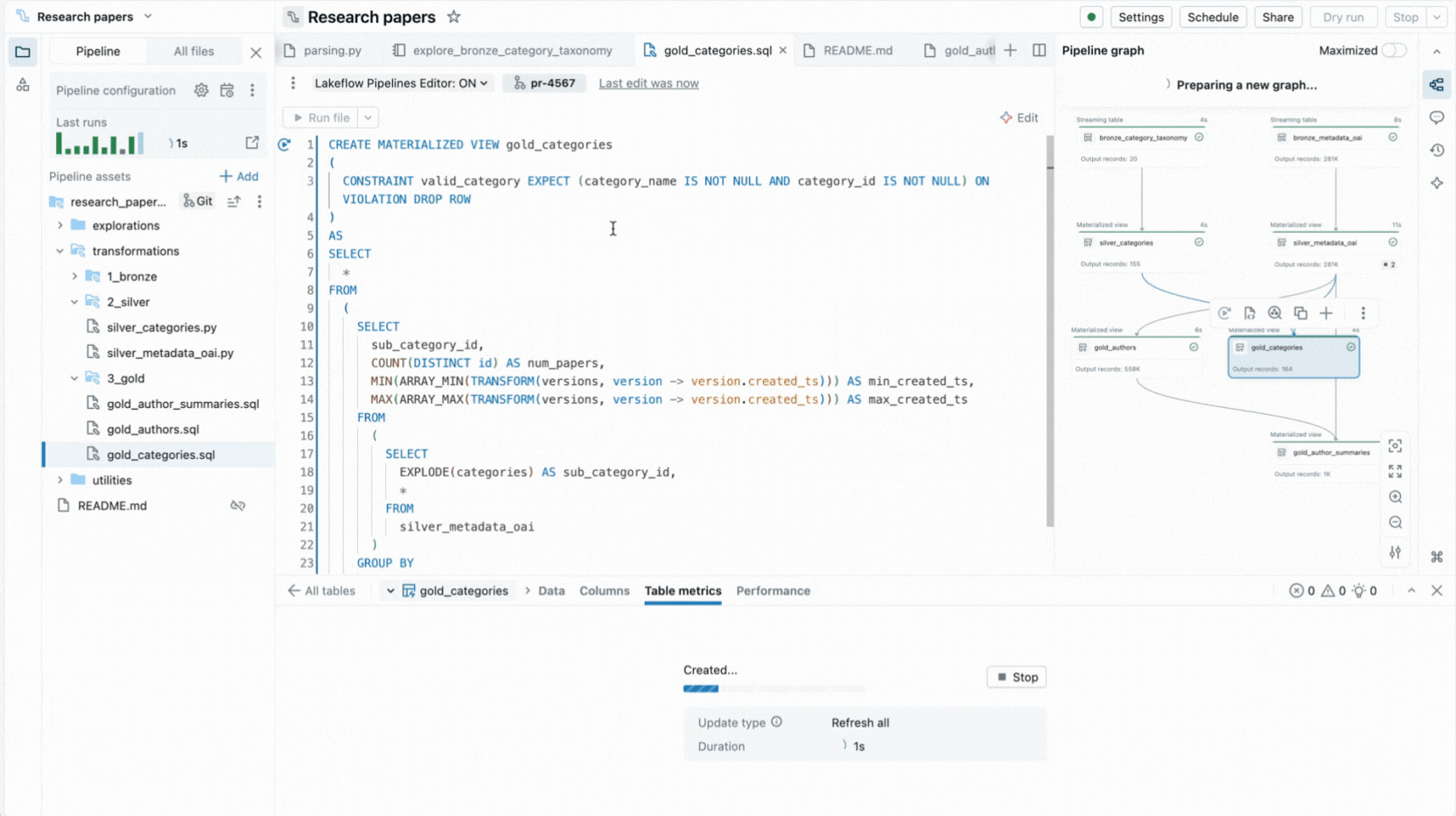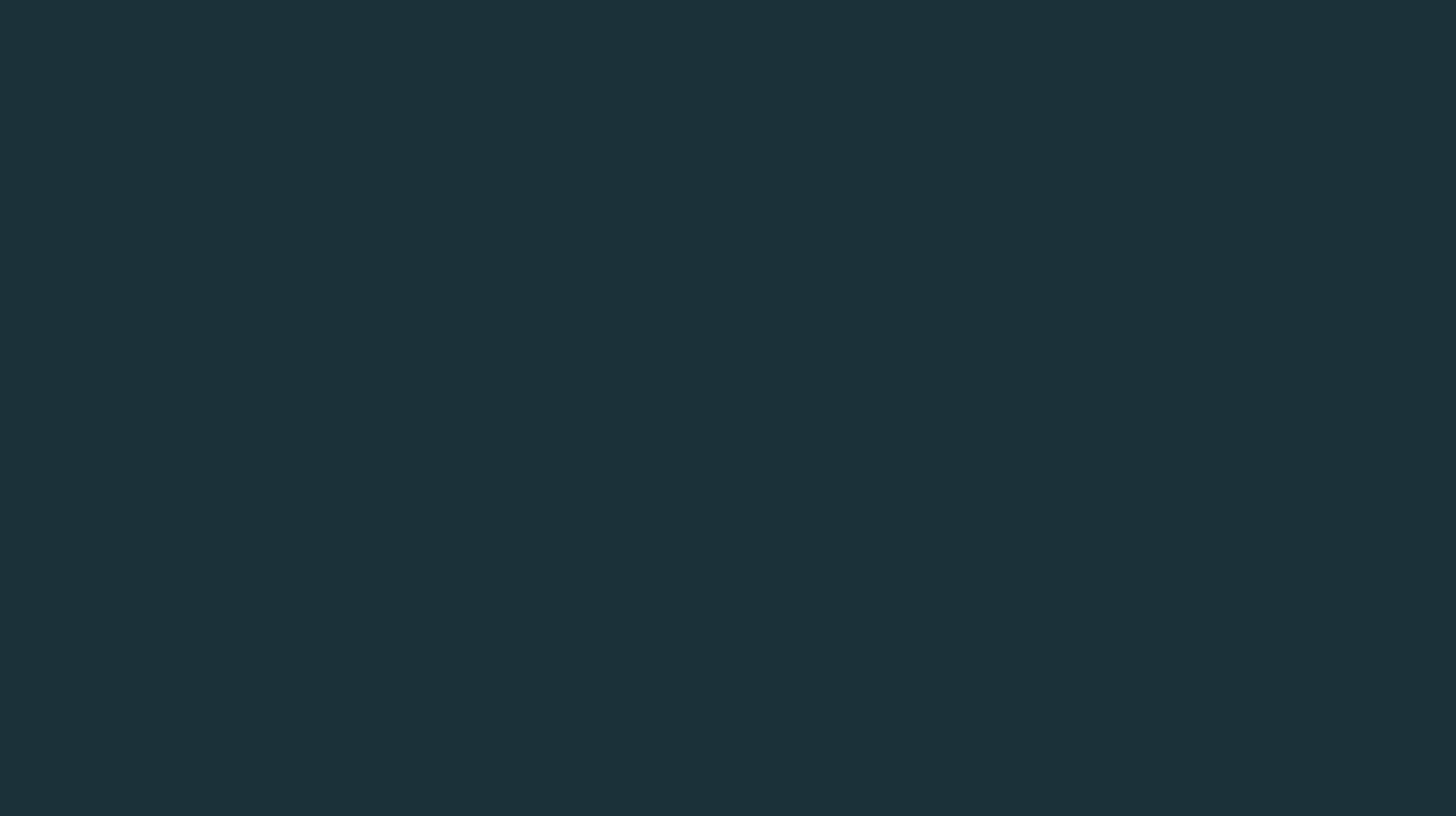
C'est pourquoi nous avons créé une expérience IDE complète pour les pipelines déclaratifs directement dans l'espace de travail Databricks. Disponible en tant que nouvel éditeur pour Lakeflow Spark Declarative Pipelines, il vous permet de déclarer des jeux de données et des contraintes de qualité dans des fichiers, de les organiser en dossiers et de visualiser les connexions via un graphe de dépendances généré automatiquement affiché à côté de votre code. L'éditeur évalue vos fichiers pour déterminer le plan d'exécution le plus efficace et vous permet d'itérer rapidement en réexécutant des fichiers uniques, un ensemble de jeux de données modifiés ou l'ensemble du pipeline.
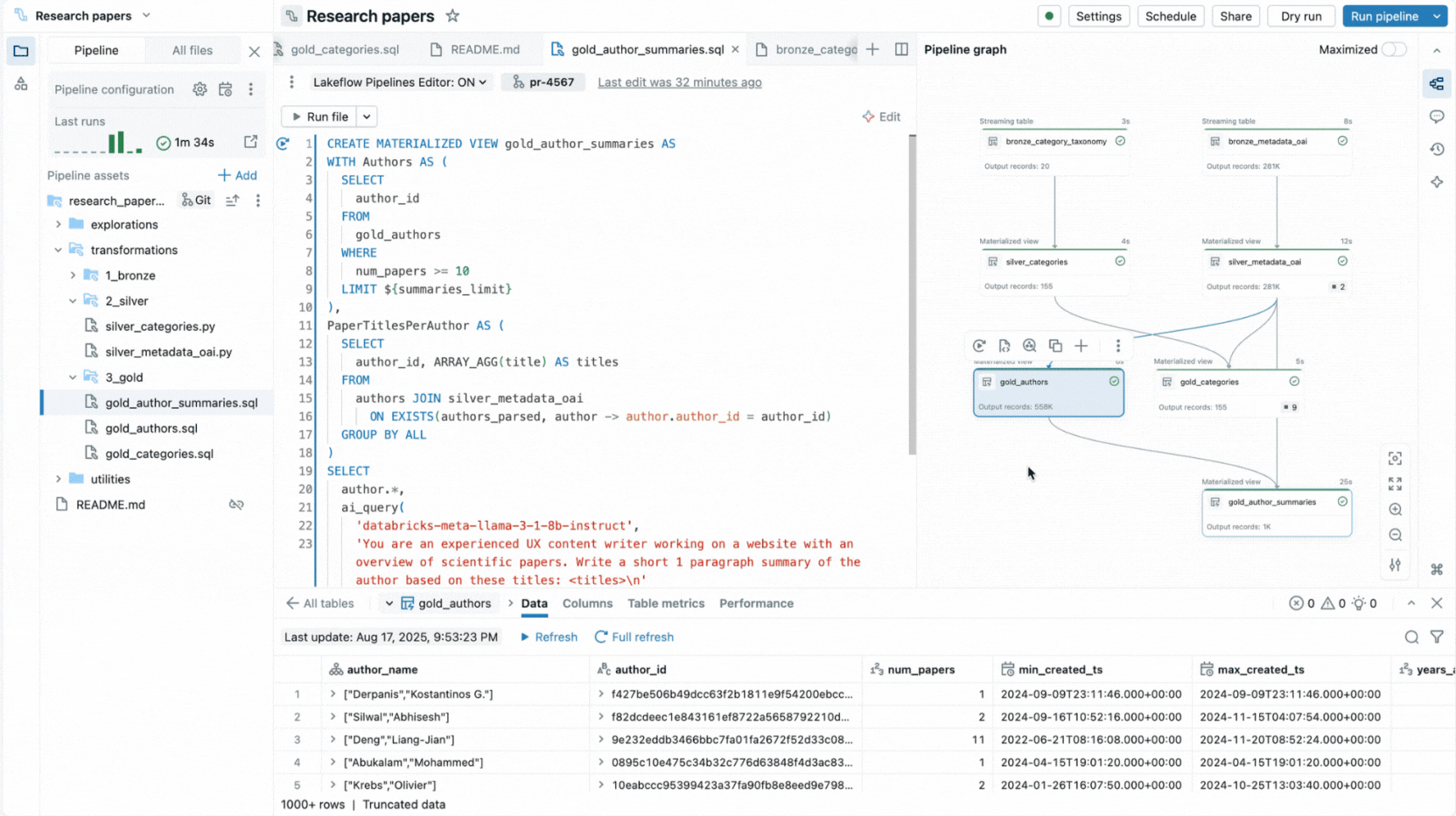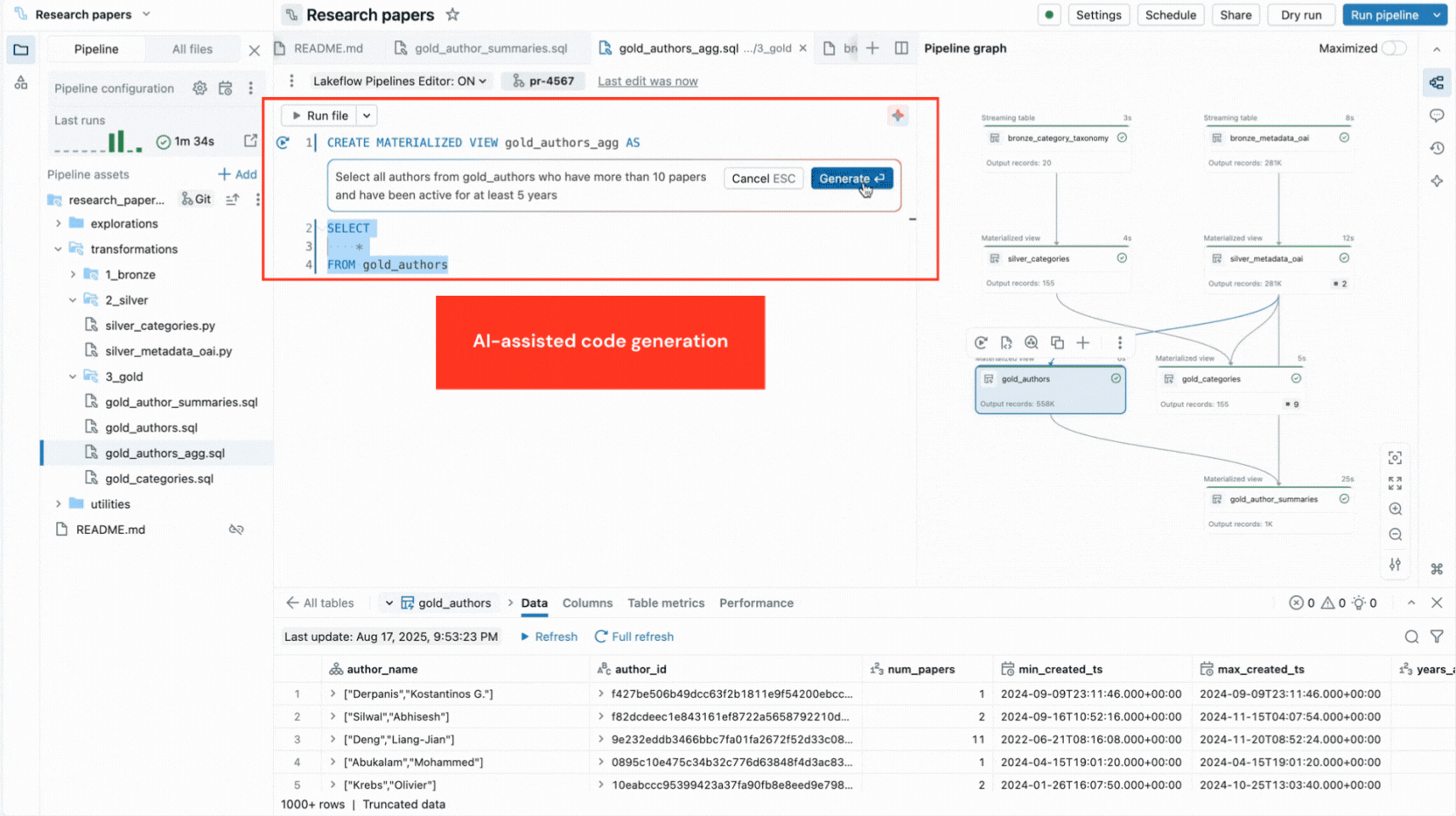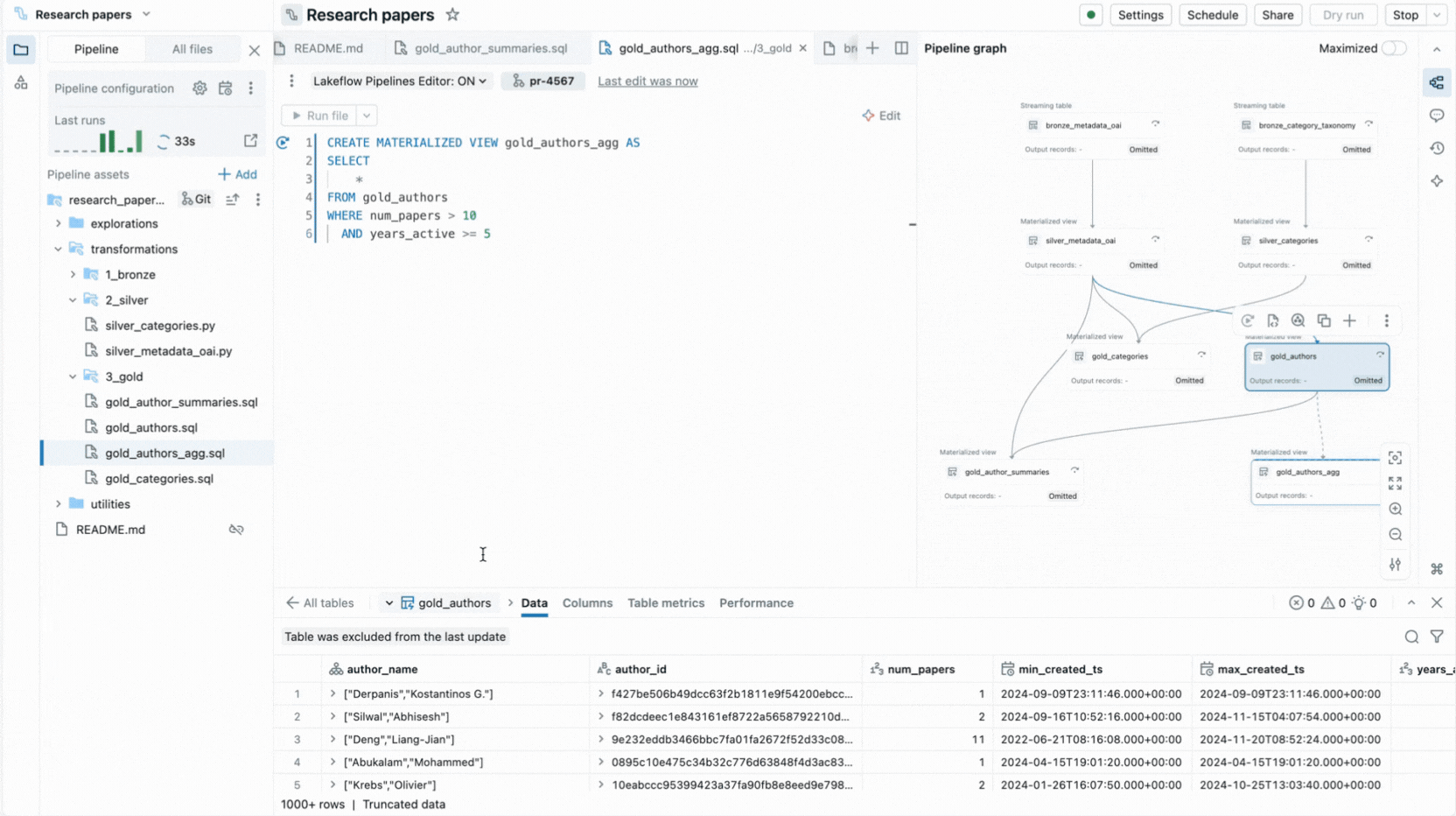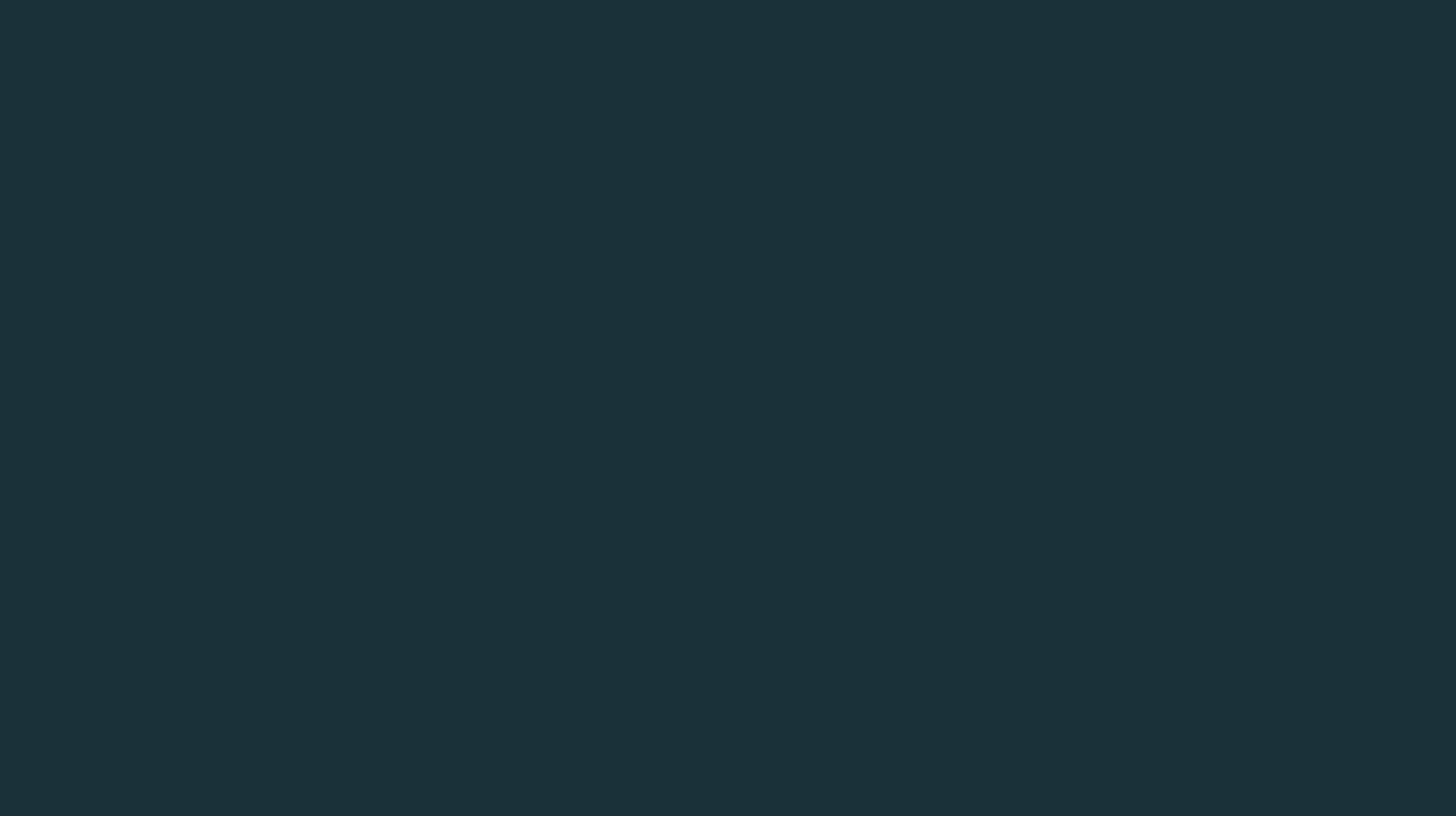
L'éditeur affiche également des informations sur l'exécution, fournit des aperçus de données intégrés et inclut des outils de débogage pour vous aider à affiner votre code. Il s'intègre également au contrôle de version et à l'exécution planifiée avec Lakeflow Jobs. Ainsi, vous pouvez effectuer toutes les tâches liées à votre pipeline à partir d'une seule surface.
En consolidant toutes ces capacités dans une seule surface de type IDE, l'éditeur permet les pratiques et la productivité que les ingénieurs de données attendent d'un IDE moderne, tout en restant fidèle au paradigme déclaratif.
La vidéo intégrée ci-dessous montre ces fonctionnalités en action, avec plus de détails couverts dans les sections suivantes.
"Le nouvel éditeur rassemble tout en un seul endroit : le code, le graphe du pipeline, les résultats, la configuration et le dépannage. Fini le jonglage entre les onglets du navigateur ou la perte de contexte. Le développement semble plus ciblé et efficace. Je peux voir directement l'impact de chaque modification de code. Un clic me mène à la ligne d'erreur exacte, ce qui accélère le débogage. Tout est connecté : le code aux données ; le code aux tables ; les tables au code. Changer de pipeline est facile, et des fonctionnalités comme les dossiers utilitaires auto-configurés éliminent la complexité. C'est comme cela que le développement de pipelines devrait fonctionner."—Chris Sharratt, Data Engineer, Rolls-Royce
"À mon avis, le nouvel éditeur de pipelines est une amélioration considérable. Je trouve beaucoup plus facile de gérer des structures de dossiers complexes et de passer d'un fichier à l'autre grâce à l'expérience multi-onglets. La vue DAG intégrée m'aide vraiment à maîtriser des pipelines complexes, et la gestion améliorée des erreurs change la donne : elle m'aide à identifier rapidement les problèmes et rationalise mon flux de travail de développement."—Matt Adams, Senior Data Platforms Developer, PacificSource Health Plans
Facilité de démarrage
Nous avons conçu l'éditeur de manière à ce que même les utilisateurs novices du paradigme déclaratif puissent rapidement construire leur premier pipeline.
- La configuration guidée permet aux nouveaux utilisateurs de commencer avec du code d'exemple, tandis que les utilisateurs existants peuvent configurer des configurations avancées, telles que des pipelines avec CI/CD intégré via Databricks Asset Bundles.
- Les structures de dossiers suggérées fournissent un point de départ pour organiser les actifs sans imposer de conventions rigides, de sorte que les équipes puissent également mettre en œuvre leurs propres modèles organisationnels établis. Par exemple, vous pouvez regrouper les transformations dans des dossiers pour chaque étape du médaillon, avec un jeu de données par fichier.
- Les paramètres par défaut permettent aux utilisateurs d'écrire et d'exécuter leur premier code sans frais généraux de configuration importants, et d'ajuster les paramètres plus tard, une fois leur charge de travail de bout en bout définie.
Ces fonctionnalités aident les utilisateurs à devenir rapidement productifs et à transformer leur travail en pipelines prêts pour la production.
Efficacité dans la boucle de développement interne
La construction de pipelines est un processus itératif. L'éditeur rationalise ce processus avec des fonctionnalités qui simplifient la création et accélèrent le test et le raffinement de la logique :
- La génération de code assistée par l'IA et les modèles de code accélèrent la définition des jeux de données et des contraintes de qualité des données, et éliminent les étapes répétitives.
- L'exécution sélective vous permet d'exécuter une seule table, toutes les tables d'un fichier ou l'ensemble du pipeline.
- Le graphe de pipeline interactif fournit une vue d'ensemble des dépendances des jeux de données et offre des actions rapides telles que des aperçus de données, des réexécutions, la navigation vers le code ou l'ajout de nouveaux jeux de données avec un code boilerplate généré automatiquement.
- Les aperçus de données intégrés vous permettent d'inspecter les données des tables sans quitter l'éditeur.
- Les erreurs contextuelles apparaissent à côté du code pertinent, avec des suggestions de correction de l'assistant Databricks.
- Les panneaux d'informations sur l'exécution affichent les métriques des jeux de données, les attentes, les performances des requêtes, avec un accès aux profils de requête pour l'optimisation des performances.
Ces capacités réduisent le changement de contexte et maintiennent les développeurs concentrés sur la construction de la logique du pipeline.
Une seule surface pour toutes les tâches
Le développement de pipelines implique plus que l'écriture de code. La nouvelle expérience développeur rassemble toutes les tâches connexes sur une seule surface, de la modularisation du code pour la maintenabilité à la configuration de l'automatisation et de l'observabilité :
- Organisez le code adjacent, tel que les notebooks exploratoires ou les modules Python réutilisables, dans des dossiers dédiés, modifiez les fichiers dans plusieurs onglets et exécutez-les séparément de la logique du pipeline. Cela permet de retrouver facilement le code associé et de garder votre pipeline bien rangé.
- Le contrôle de version intégré via des dossiers Git permet un travail sûr et isolé, des revues de code et des demandes de tirage vers des dépôts partagés.
- La CI/CD avec la prise en charge de Databricks Asset Bundles pour les pipelines connecte le développement en boucle interne au déploiement. Les administrateurs de données peuvent imposer des tests et automatiser la promotion en production à l'aide de modèles et de fichiers de configuration, le tout sans ajouter de complexité au flux de travail d'un praticien de données.
- L'automatisation et l'observabilité intégrées permettent l'exécution planifiée des pipelines et fournissent un accès rapide aux exécutions passées pour la surveillance et le dépannage.
En unifiant ces capacités, l'éditeur rationalise à la fois le développement quotidien et les opérations de pipeline à long terme.
Découvrez la vidéo ci-dessous pour plus de détails sur toutes ces fonctionnalités en action.
Prochaines étapes
Nous ne nous arrêtons pas là. Voici un aperçu de ce que nous explorons actuellement :
- Prise en charge native des tests de données dans Lakeflow Spark Declarative Pipelines et des exécuteurs de tests dans l'éditeur
- Génération de tests assistée par l'IA pour accélérer la validation
- Expérience d'agent pour Lakeflow Spark Declarative Pipelines.
Faites-nous savoir ce que vous aimeriez voir d'autre : vos commentaires guident ce que nous construisons.
Commencez dès aujourd'hui avec la nouvelle expérience développeur
L'IDE pour l'ingénierie des données est disponible sur tous les clouds. Pour l'activer, ouvrez un fichier associé à un pipeline existant, cliquez sur la bannière 'Lakeflow Pipelines Editor: OFF' et activez-la. Vous pouvez également l'activer lors de la création d'un pipeline avec une bascule similaire, ou depuis la page des paramètres utilisateur.
Apprenez-en davantage en utilisant ces ressources :
- Consultez la documentation.
- Regardez la présentation Authoring Data Pipelines With the New Editor au Data + AI Summit 2025.
- Découvrez Lakeflow in Production: CI/CD, Testing and Monitoring at Scale au Data + AI Summit 2025.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.