Repenser l'ETL SQL pour les plateformes de données modernes
Réduisez les coûts et la complexité en unifiant les pipelines SQL fragmentés sur une seule plateforme
par Matt Jones et Shanelle Roman
- L'ETL SQL fragmenté entraîne des coûts cachés, des pipelines fragiles et une résolution lente des incidents
- L'exécution de l'ETL sur plusieurs entrepôts de données, orchestrateurs et outils crée une charge opérationnelle qui augmente avec chaque pipeline
- Une plateforme unifiée pour tout l'ETL SQL élimine les frais généraux de coordination et permet aux équipes de livrer plus rapidement sur un système gouverné unique
Le SQL est le fondement du travail moderne sur les données. C'est ainsi que les ingénieurs en analytique définissent les transformations, que les ingénieurs en entrepôts de données gèrent les pipelines, et que les analystes explorent et affinent les données.
Mais si le SQL lui-même est standardisé, les systèmes utilisés pour exécuter l'ETL SQL ne le sont pas du tout.
Dans la plupart des organisations, les pipelines SQL sont répartis sur une combinaison d'outils : un entrepôt de données pour l'exécution, un cadre de transformation pour la modélisation, un orchestrateur pour la planification, et des systèmes distincts pour la surveillance, la lignée et la qualité des données. Chaque couche répond à un besoin spécifique, mais ensemble, elles créent un environnement fragmenté difficile à exploiter et de plus en plus difficile à faire évoluer.
À mesure que les équipes de données se développent, cette fragmentation commence à se manifester dans les opérations quotidiennes. Les pipelines échouent sur plusieurs systèmes, les dépendances sont difficiles à suivre, et la résolution des problèmes nécessite souvent de passer d'un outil à l'autre qui n'ont jamais été conçus pour fonctionner ensemble. En même temps, les attentes augmentent. Les équipes sont invitées à fournir des données plus récentes, à prendre en charge davantage de cas d'utilisation et à agir plus rapidement, sans augmenter la charge opérationnelle.
C'est là que de nombreuses stratégies de plateforme de données commencent à échouer. Même lorsque les organisations investissent dans une infrastructure moderne, l'ETL SQL reste souvent distribué sur plusieurs systèmes, perpétuant la même complexité et les mêmes contraintes.
Le défi n'est pas le SQL lui-même, mais la manière dont l'ETL SQL est implémenté.
Si l'ETL SQL était conçu dès le départ pour la façon dont les équipes travaillent réellement aujourd'hui, il serait très différent. En pratique, cela signifierait :
- Une plateforme unique pour l'ETL
- Un support pour chaque praticien SQL
- Des pipelines ouverts et prêts pour l'avenir
Ensemble, ces principes définissent une approche plus simple et plus durable de l'ETL SQL — une approche qui réduit la fragmentation aujourd'hui tout en soutenant l'évolution des charges de travail de données au fil du temps.
Exécuter et opérer l'ETL SQL sur une seule plateforme
Le défi de l'ETL SQL n'est pas d'écrire des transformations — c'est d'opérer des pipelines lorsqu'ils s'étendent sur plusieurs systèmes.
En pratique, cela signifie coordonner l'exécution dans l'entrepôt de données, l'orchestration dans un système distinct, et l'observabilité ajoutée par la suite. Maintenir les pipelines en fonctionnement nécessite d'assembler ces éléments — suivre les dépendances, diagnostiquer les échecs et gérer les nouvelles tentatives entre des outils qui ne partagent pas de contexte.
À mesure que les pipelines augmentent en nombre et en importance, cette coordination devient une charge opérationnelle importante.
Une plateforme unifiée simplifie ce modèle en regroupant ces capacités. Lorsque l'exécution, l'orchestration, l'observabilité et la gouvernance font partie du même système, les pipelines deviennent plus faciles à gérer par conception. Les dépendances sont suivies automatiquement, et les problèmes peuvent être identifiés et résolus plus rapidement car le contexte pertinent est disponible en un seul endroit.
Sur Databricks, l'ETL SQL est défini et exécuté au sein d'une plateforme unique. Les pipelines s'exécutent avec une orchestration intégrée, tandis que la lignée et l'observabilité sont capturées automatiquement à chaque étape. Les contrôles de qualité des données et de gouvernance sont intégrés directement dans l'exécution du pipeline plutôt que gérés par des outils distincts.
Cette approche est renforcée par une infrastructure sans serveur et une optimisation basée sur l'IA. L'optimisation des performances, la gestion des ressources et la mise à l'échelle sont gérées automatiquement, permettant aux équipes de se concentrer sur la fourniture de données fiables plutôt que sur l'exploitation des systèmes.
Après la transition de nos pipelines Databricks vers le calcul sans serveur, HP a réalisé des économies de cloud de plus de 32 % et a réduit le temps d'exécution combiné des tâches de 36 %. La gestion d'infrastructure sans effort fournie par le sans serveur a fait de cette décision un choix évident et stratégique. —Luis Alonso, Responsable de la stratégie et de l'ingénierie des données chez HP Marketing
Le résultat est une base plus rationalisée et fiable pour l'ETL SQL — une base qui réduit la charge opérationnelle tout en améliorant les performances et la fiabilité à grande échelle.
Soutenir la façon dont les équipes construisent réellement les pipelines SQL
L'ETL SQL est fragmenté non seulement à cause des outils, mais parce que les équipes ne construisent pas toutes les pipelines de la même manière.
Les ingénieurs en analytique – qui se concentrent sur la définition de la logique métier en SQL – souhaitent souvent un moyen de construire des pipelines sans gérer l'infrastructure sous-jacente, avec des tests, un contrôle de version et des dépendances gérés automatiquement. Les ingénieurs en entrepôts de données ont tendance à s'appuyer sur des scripts SQL et des procédures stockées, souvent dans des environnements d'exécution étroitement contrôlés. Les analystes peuvent créer des transformations directement dans des outils sans code ou des interfaces SQL légères.
De nombreuses plateformes favorisent implicitement l'une de ces approches. À mesure que les organisations se développent, elles introduisent souvent des systèmes supplémentaires pour prendre en charge d'autres personas, ce qui entraîne des environnements parallèles difficiles à standardiser et à maintenir.
Une approche plus efficace consiste à standardiser la plateforme plutôt que l'interface.
Databricks prend en charge une gamme de workflows ETL SQL au sein du même environnement. Les équipes peuvent exécuter des workflows dbt existants directement sur la plateforme, migrer le SQL de style entrepôt vers des scripts et des procédures stockées, accélérer les charges de travail BI avec les vues matérialisées dans Databricks SQL, définir des pipelines déclaratifs qui simplifient les workflows de production, ou utiliser des outils sans code pour les analystes métier construits sur la même plateforme. Bien que ces approches diffèrent dans la manière dont les pipelines sont créés, elles partagent le même moteur d'exécution, le même modèle de gouvernance et le même cadre d'observabilité.

Cette cohérence permet aux organisations de prendre en charge plusieurs styles de développement sans introduire de fragmentation dans la manière dont les pipelines sont exécutés. Les équipes peuvent travailler au niveau d'abstraction qui correspond à leurs besoins, tout en bénéficiant d'une lignée, d'une surveillance et de contrôles opérationnels partagés.
Cela garantit également que les scripts SQL de style entrepôt existants et les nouvelles approches peuvent coexister sur la même base. Les équipes n'ont pas besoin de choisir entre maintenir ce qu'elles ont et adopter de nouveaux modèles — elles peuvent faire les deux au sein d'un seul système.
Chacun de ces workflows se reflète dans une expérience de création dédiée.
1. Pour les ingénieurs en entrepôts de données exécutant des scripts SQL et des procédures stockées :
Éditeur SQL pour les procédures stockées et les vues matérialisées
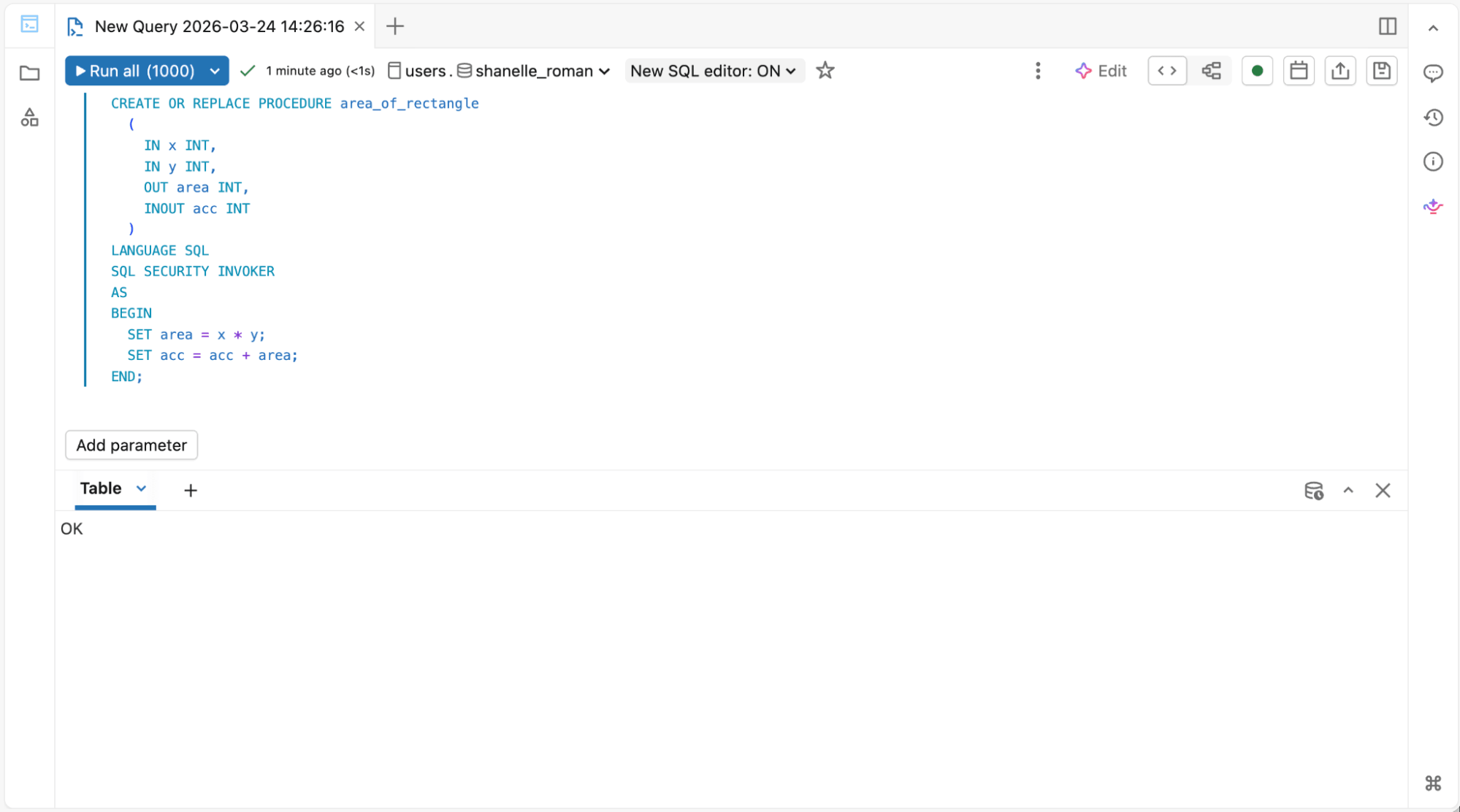
{kind=link}
2. Pour les ingénieurs en analytique construisant des pipelines de production avec SQL :
Éditeur de pipelines déclaratifs Spark
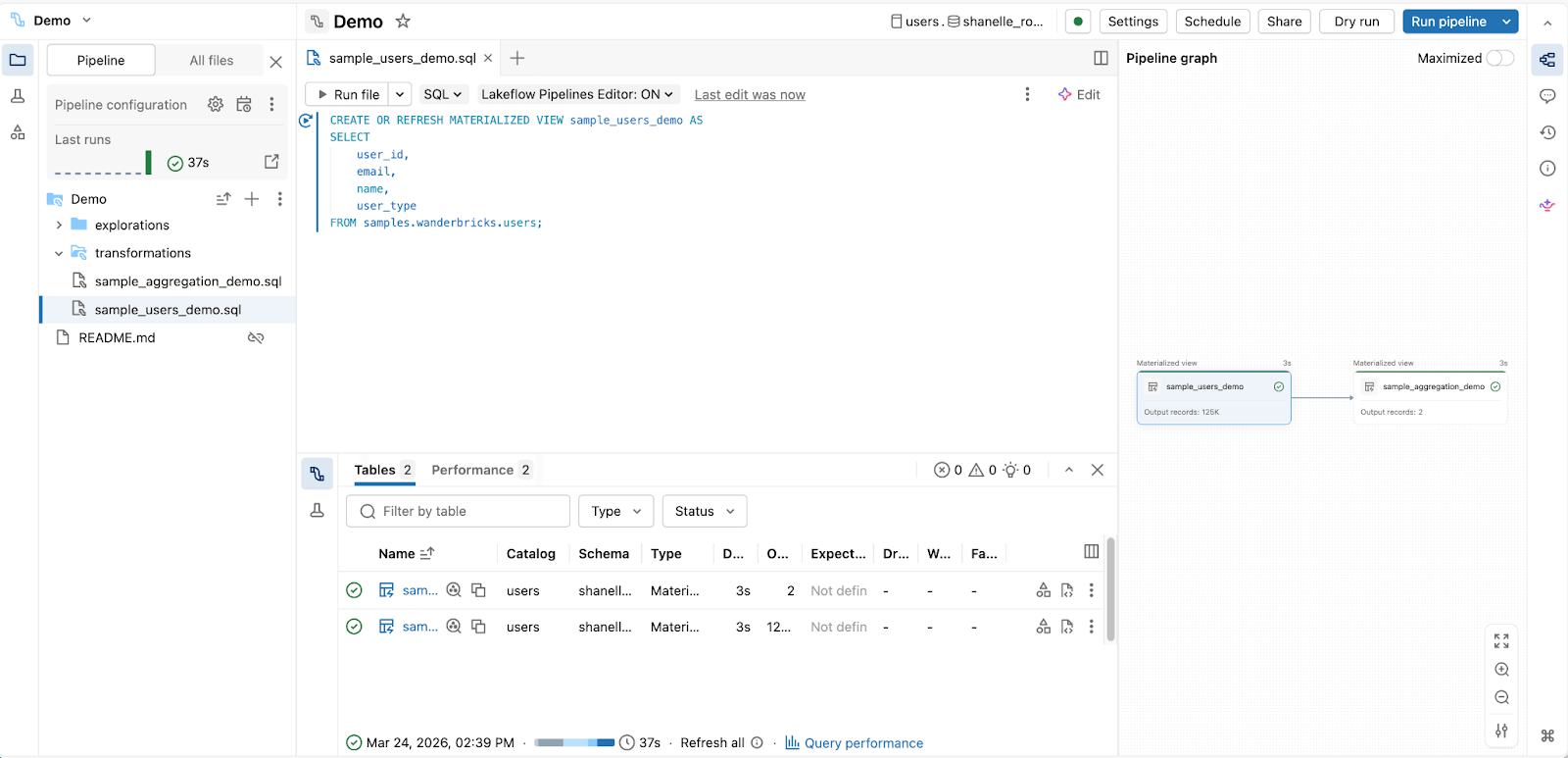
3. Pour les analystes et les utilisateurs métier préparant des données sans code :
Lakeflow Designer
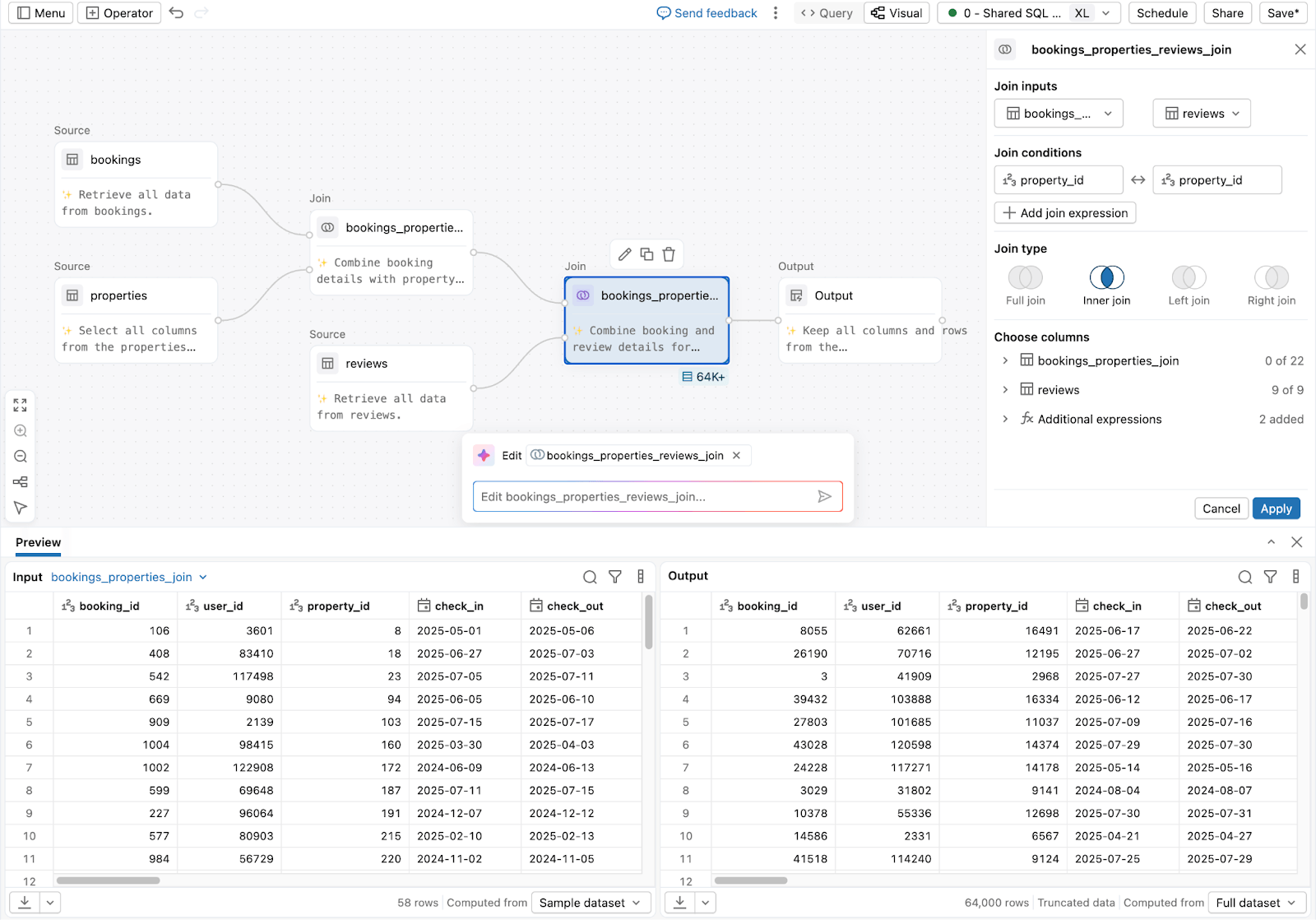
Le résultat est un environnement plus cohérent pour l'ETL SQL, où la collaboration s'améliore et la complexité opérationnelle n'augmente pas avec l'échelle.
Construire des pipelines SQL qui évoluent avec vos charges de travail
À mesure que de nouvelles sources de données, des cas d'utilisation en temps réel et des charges de travail d'IA émergent, les équipes sont souvent contraintes d'introduire des systèmes supplémentaires ou de réécrire les pipelines existants — ajoutant complexité et coût au fil du temps.
De nombreuses solutions ETL SQL introduisent ces contraintes par le biais de formats propriétaires, de modèles d'exécution étroitement couplés, ou d'hypothèses sur la manière dont les données seront traitées. Ces contraintes peuvent ne pas être immédiatement apparentes, mais elles ont tendance à apparaître à mesure que les organisations s'étendent à de nouvelles charges de travail, nécessitent des données plus récentes ou prennent en charge un ensemble plus large de cas d'utilisation.
Une approche de l'ETL SQL prête pour l'avenir privilégie l'ouverture et la flexibilité dès le départ.
Databricks construit l'ETL SQL sur des formats de table ouverts et le SQL ANSI, contribuant à garantir que les pipelines restent portables et interopérables entre les systèmes. Cela réduit le risque de verrouillage et permet aux organisations de conserver le contrôle de leurs données et de leur logique à mesure que leur architecture évolue.
En même temps, Databricks fournit un modèle SQL unifié qui prend en charge les cas d'utilisation d'analyse par lots et en temps réel. Plutôt que de nécessiter des systèmes distincts pour différentes charges de travail, la même approche basée sur SQL peut être appliquée à un large éventail de cas d'utilisation.
Cette flexibilité permet aux pipelines d'évoluer en même temps que l'organisation. Les équipes peuvent continuer à exécuter les workflows SQL existants tout en adoptant des modèles plus avancés – tels que le traitement incrémental ou les pipelines déclaratifs – lorsque cela est nécessaire.
La conversion aux vues matérialisées a entraîné une amélioration drastique des performances des requêtes, le temps d'exécution passant de 8 minutes à seulement 3 secondes. Cela permet à notre équipe de travailler plus efficacement et de prendre des décisions plus rapides basées sur les informations obtenues à partir des données. De plus, les économies de coûts supplémentaires ont vraiment été utiles. —Karthik Venkatesan, Responsable principal de l'ingénierie logicielle de sécurité, Adobe
En évitant les contraintes architecturales rigides, cette approche offre une base stable capable de prendre en charge les exigences actuelles et futures sans nécessiter de changements perturbateurs.
Pourquoi le SQL ETL devrait façonner votre stratégie de plateforme de données
Les discussions sur les plateformes de données se concentrent souvent sur l'endroit où les données sont stockées et la manière dont les requêtes sont exécutées. En pratique, cependant, l'efficacité d'une plateforme dépend tout autant de la manière dont les pipelines de données sont construits et maintenus, et s'ils sont définis de manière ouverte et interopérable pour éviter le verrouillage à long terme.
Si le SQL ETL reste fragmenté sur plusieurs systèmes, les organisations sont susceptibles de conserver la même complexité opérationnelle et les mêmes inefficacités, même après l'adoption d'une nouvelle plateforme. Avec le temps, cela limite la valeur de la plateforme et rend plus difficile la mise à l'échelle des opérations de données.
Une approche plus efficace consiste à évaluer dans quelle mesure une plateforme prend en charge le SQL ETL tout au long de son cycle de vie complet – du développement et de l'exécution à la surveillance et à la gouvernance. Cela inclut la capacité à prendre en charge différents styles de travail, à réduire les frais généraux opérationnels et à s'adapter aux exigences évolutives sans introduire de systèmes supplémentaires.
Databricks répond à ces besoins en combinant l'exécution SQL, la gestion des pipelines, la gouvernance et l'optimisation au sein d'une seule plateforme. Cette approche unifiée permet aux équipes de construire et d'opérer des pipelines SQL plus efficacement tout en conservant la flexibilité nécessaire pour prendre en charge un large éventail de charges de travail.
Conclusion
Le SQL continuera de jouer un rôle central dans la manière dont les organisations travaillent avec les données.
Par conséquent, la manière dont le SQL ETL est mis en œuvre a un impact direct sur l'efficacité de la plateforme de données globale. Les approches fragmentées introduisent de la complexité et ralentissent les équipes, tandis que les approches unifiées simplifient les opérations et améliorent l'évolutivité.
Pour les organisations qui évaluent comment faire évoluer leurs plateformes de données, le SQL ETL est une considération essentielle. Databricks propose un modèle de SQL ETL unifié et pérenne qui rassemble l'exécution, la gestion des pipelines et la gouvernance au sein d'une seule plateforme, tout en restant ouvert et adaptable à mesure que les exigences évoluent.
En pratique, la plupart des organisations ne partent pas de zéro. La modernisation du SQL ETL est souvent bloquée car le coût et le risque de réécrire les pipelines de production sont trop élevés. Plutôt que d'imposer une refonte perturbatrice, une approche plus efficace consiste à évoluer de manière incrémentale – en exécutant d'abord les pipelines existants, en consolidant les systèmes au fil du temps et en modernisant étape par étape.
C'est ainsi que les équipes peuvent réduire la fragmentation aujourd'hui tout en construisant une plateforme de données plus unifiée et pérenne au fil du temps. Nous approfondirons cette approche dans un prochain article. En attendant, vous pouvez en savoir plus sur la construction, l'exécution et la mise à l'échelle des pipelines SQL sur une plateforme lakehouse unifiée dans cet ebook, Un guide pour construire des pipelines ETL avec SQL.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.