Apprentissage supervisé vs. non supervisé : Comprendre les différences et les capacités de chaque approche d'apprentissage automatique
- L'apprentissage supervisé et non supervisé servent des objectifs différents : l'apprentissage supervisé utilise des données étiquetées pour faire des prédictions et des classifications précises, tandis que l'apprentissage non supervisé trouve des motifs cachés dans des données brutes non étiquetées, rendant chacun mieux adapté à différents objectifs commerciaux.
- Le ML moderne combine les deux approches : des techniques comme l'apprentissage semi-supervisé et auto-supervisé combinent les forces de chaque paradigme.
- Le véritable défi est de construire des systèmes : le ML d'entreprise réussi dépend de l'orchestration des deux approches au sein de pipelines de données fiables, d'une gouvernance solide et d'une évaluation continue tout au long du cycle de vie du modèle.
Les systèmes d'apprentissage automatique apprennent à partir des données pour faire des prédictions, classifier des informations ou découvrir des modèles qu'il serait difficile pour les humains d'identifier manuellement.
Qu'est-ce que l'apprentissage supervisé ?
Dans l'apprentissage supervisé, les modèles sont entraînés à l'aide de données étiquetées, où chaque entrée est associée à une sortie connue. Le modèle apprend en comparant ses prédictions à ces réponses correctes et en réduisant itérativement l'erreur.
Au cœur de ce processus se trouvent les modèles d'apprentissage automatique qui apprennent les relations explicites entre les caractéristiques et les résultats. La présence de données étiquetées fournit des directives claires, rendant l'apprentissage supervisé bien adapté aux problèmes où la précision, la traçabilité et la répétabilité sont essentielles.
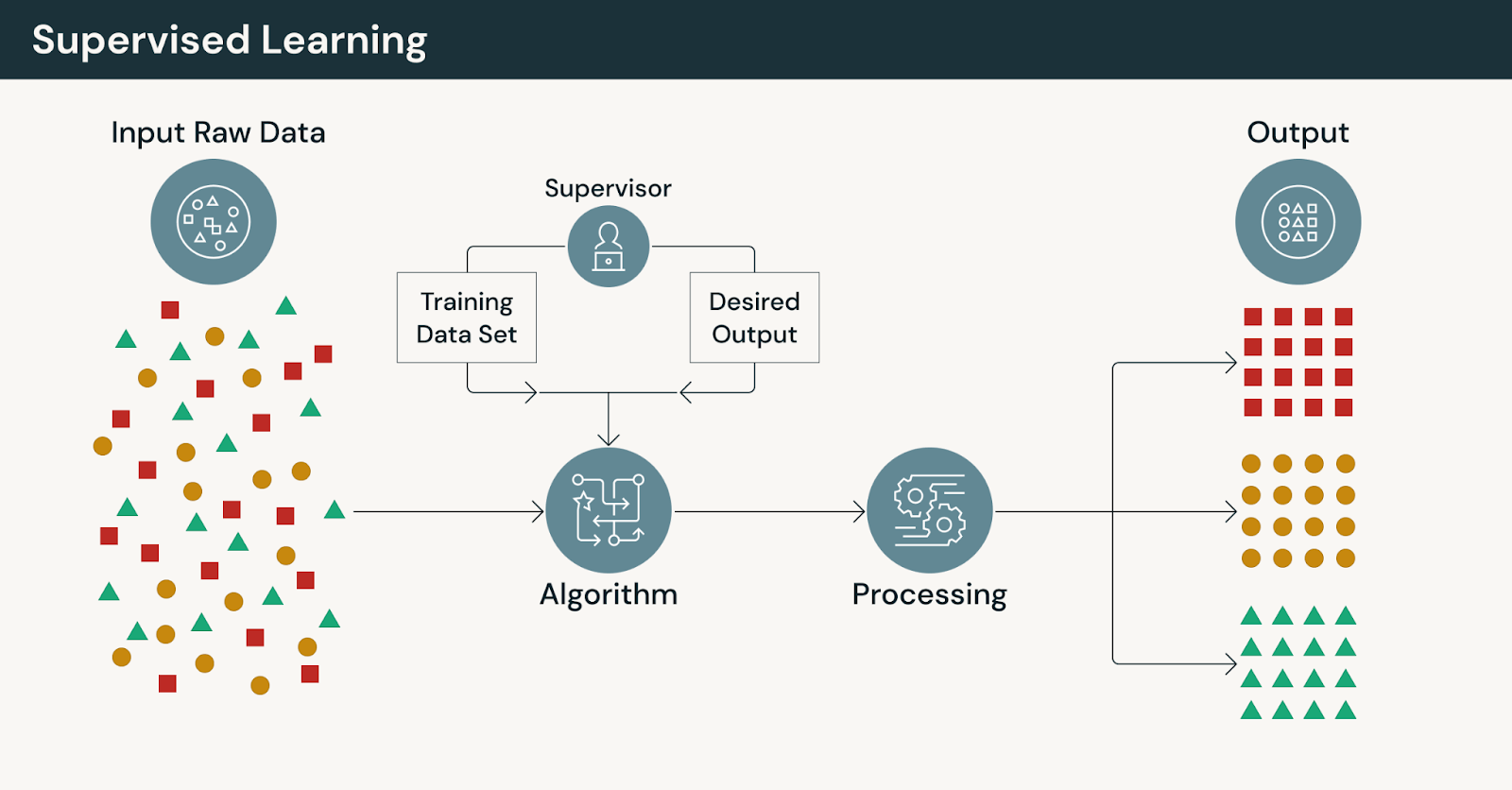
Comment fonctionne l'apprentissage supervisé
Un flux de travail typique d'apprentissage supervisé comprend :
- La collecte de données d'entraînement historiques avec des résultats connus
- La préparation et la validation des ensembles de données d'entraînement étiquetés
- L'ingénierie des caractéristiques qui capturent les signaux pertinents
- L'entraînement et l'évaluation des modèles par rapport à la vérité terrain
- Le déploiement des modèles et le suivi des performances au fil du temps
Ce flux de travail dépend de la disponibilité et de la qualité des étiquettes — une contrainte qui devient souvent plus prononcée à mesure que le volume de données augmente.
Types d'apprentissage supervisé
Les problèmes d'apprentissage supervisé se répartissent généralement en deux catégories :
- Classification : Attribution de données d'entrée à des classes prédéfinies, telles que spam ou e-mail légitime, ou sentiment positif ou négatif.
- Régression : Prédiction de valeurs continues, telles que les prévisions de demande, la tarification ou les scores de risque. Les compagnies de transport utilisent des modèles de régression pour prédire les temps de vol en fonction des performances historiques des itinéraires, des modèles saisonniers et des facteurs opérationnels, aidant ainsi à optimiser la planification et à définir des attentes précises pour les clients.
Dans les deux cas, les performances du modèle peuvent être mesurées directement par rapport aux résultats connus, ce qui simplifie l'évaluation et la responsabilité.
Applications courantes de l'apprentissage supervisé
L'apprentissage automatique supervisé est couramment utilisé pour :
- Le filtrage des e-mails et la modération de contenu
- L'analyse des sentiments dans les commentaires des clients
- La prévision et l'analyse prédictive
- La classification d'images et de documents
De nombreuses applications de traitement du langage naturel reposent sur le réglage fin supervisé pour adapter les modèles à usage général à des tâches, des politiques ou des vocabulaires spécifiques à un domaine.
Apprentissage supervisé dans tous les secteurs
Les applications d'apprentissage supervisé couvrent pratiquement tous les secteurs, certaines utilisations étant devenues fondamentales pour l'infrastructure numérique moderne.
Cybersécurité : Les systèmes de détection de spam analysent des milliards d'e-mails chaque jour, en utilisant des modèles supervisés entraînés sur des exemples étiquetés de messages légitimes et malveillants. La détection moderne de spam va au-delà de la simple correspondance de mots-clés, en intégrant la réputation de l'expéditeur, la structure du message, l'analyse des pièces jointes et les modèles comportementaux.
Santé et sciences de la vie : L'apprentissage supervisé implique l'entraînement de modèles prédictifs sur des données biomédicales et génomiques étiquetées pour identifier les modèles associés aux variants liés aux maladies et aux cibles thérapeutiques. En appliquant ces modèles au sein d'une plateforme d'analyse évolutive, les chercheurs peuvent quantifier les relations entre les caractéristiques génétiques et les résultats cliniques, permettant une prédiction plus précise des cibles médicamenteuses et accélérant la découverte basée sur des hypothèses.
Services financiers : L'apprentissage supervisé a été utilisé pour entraîner des modèles de détection de risques et de fraude sur des données de transactions historiques étiquetées, permettant au système de distinguer les activités légitimes des activités suspectes. En apprenant à partir de résultats connus — tels que des cas de fraude confirmés ou des comportements clients validés — les modèles ont amélioré la précision de la détection en temps réel tout en réduisant les faux positifs. Déployés au sein d'une plateforme de données évolutive, ces modèles supervisés ont soutenu une prise de décision plus rapide et une gestion des risques financiers plus résiliente.
Commerce de détail et biens de consommation : En utilisant des données historiques de ventes, de prix et de promotions étiquetées, des modèles prédictifs ont été entraînés pour prévoir la demande et optimiser les décisions d'inventaire à grande échelle. En apprenant à partir de résultats connus — tels que les mouvements de produits antérieurs et les modèles de demande régionaux — le système a amélioré la précision des prévisions sur des milliers d'emplacements. Cela a permis un réapprovisionnement plus précis, réduit les ruptures de stock et un alignement plus étroit entre les opérations de la chaîne d'approvisionnement et la demande des clients.
Expériences client : Des modèles prédictifs ont été entraînés sur des données unifiées et étiquetées d'interactions et de profils clients pour apprendre les modèles qui aident à segmenter les audiences et à prédire les comportements clients. Ces modèles supervisés ont permis d'obtenir des informations clients plus précises, soutenant des stratégies de marketing ciblé et de personnalisation. Cela a entraîné une livraison plus rapide d'informations exploitables qui améliorent l'engagement et l'expérience client sur tous les canaux.
Médias et divertissement : Des données de jeu, d'engagement et comportementales étiquetées ont été utilisées pour entraîner des modèles prédictifs qui identifient les modèles d'activité des joueurs et d'interaction avec le contenu. En apprenant à partir de résultats connus — tels que les signaux de désabonnement, les comportements en jeu et les tendances de la communauté — le système a permis une prévision plus précise et une optimisation plus rapide du contenu. Cela a soutenu une amélioration des expériences des joueurs, de meilleures décisions d'exploitation en direct et un développement axé sur les données dans un écosystème de jeu mondial.
Chaque application partage une exigence commune : des données d'entraînement étiquetées fiables qui représentent fidèlement l'espace du problème et une surveillance continue pour détecter la dégradation des performances du modèle.
Qu'est-ce que l'apprentissage non supervisé ?
Plutôt que d'apprendre à partir d'exemples étiquetés, l'apprentissage automatique non supervisé analyse des données non étiquetées pour identifier des modèles, des structures ou des relations sans cibles prédéfinies.
Cela rend l'apprentissage non supervisé particulièrement précieux au début des projets ML, lorsque les équipes ne savent peut-être pas encore quelles questions poser — ou lorsque l'étiquetage des données est impraticable ou trop coûteux.
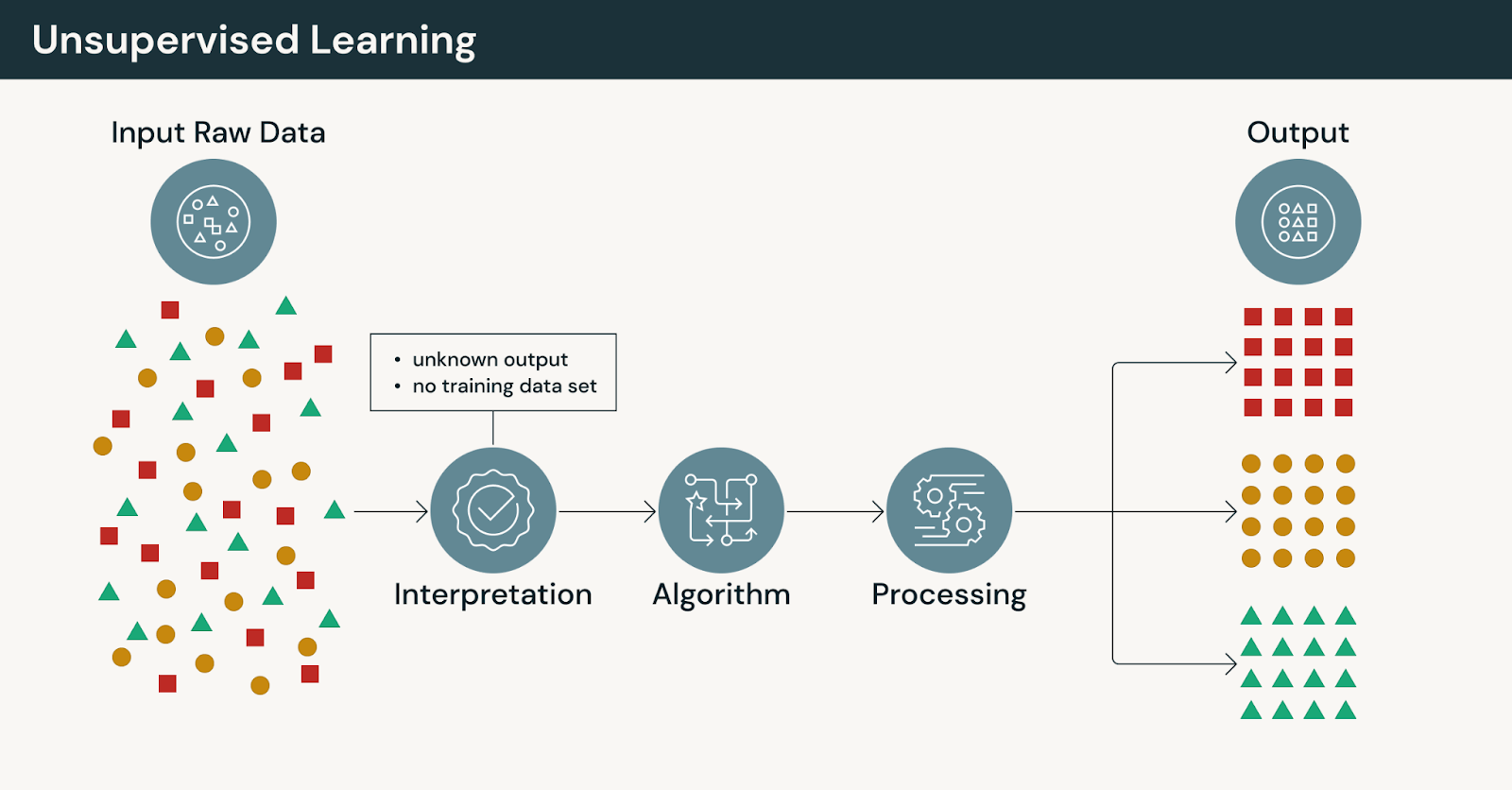
Comment fonctionne l'apprentissage non supervisé
Dans l'apprentissage non supervisé :
- Les modèles fonctionnent sans étiquettes explicites fournies par l'homme
- Les algorithmes regroupent, compressent ou organisent les données en fonction de leur similarité
- Les sorties nécessitent une interprétation et une validation par des experts du domaine
Comme il n'y a pas de réponses correctes, l'apprentissage non supervisé met l'accent sur l'exploration plutôt que sur la prédiction.
Types d'apprentissage non supervisé
Les techniques non supervisées courantes comprennent :
- Clustering : Regroupement de points de données similaires pour révéler la structure
- Réduction de dimensionnalité : Simplification de jeux de données complexes pour l'analyse
- Apprentissage de règles d'association : Identification des relations entre les variables
Beaucoup de ces méthodes s'appuient sur des algorithmes de clustering pour faire apparaître des modèles qui n'étaient pas explicitement définis à l'avance.
Applications courantes de l'apprentissage non supervisé
L'apprentissage automatique non supervisé est largement utilisé pour :
- Les stratégies de segmentation client en marketing et personnalisation, en utilisant le clustering pour regrouper des points de données similaires par comportement, préférences et valeur plutôt que par catégories prédéterminées
- Les systèmes de détection d'anomalies pour la prévention de la fraude et la surveillance opérationnelle
- L'analyse exploratoire des données et la découverte de modèles comportementaux
- La recherche et le regroupement de similarités à grande échelle
- L'analyse du panier de marché et les systèmes de recommandation de produits, où des algorithmes comme l'algorithme Apriori découvrent des modèles d'achat et des associations de produits sans qu'on leur dise quels articles doivent être liés
À mesure que les organisations accumulent davantage de données brutes, l'apprentissage non supervisé offre un moyen d'en extraire de la valeur sans attendre des efforts d'étiquetage exhaustifs.
Principales différences entre l'apprentissage supervisé et non supervisé
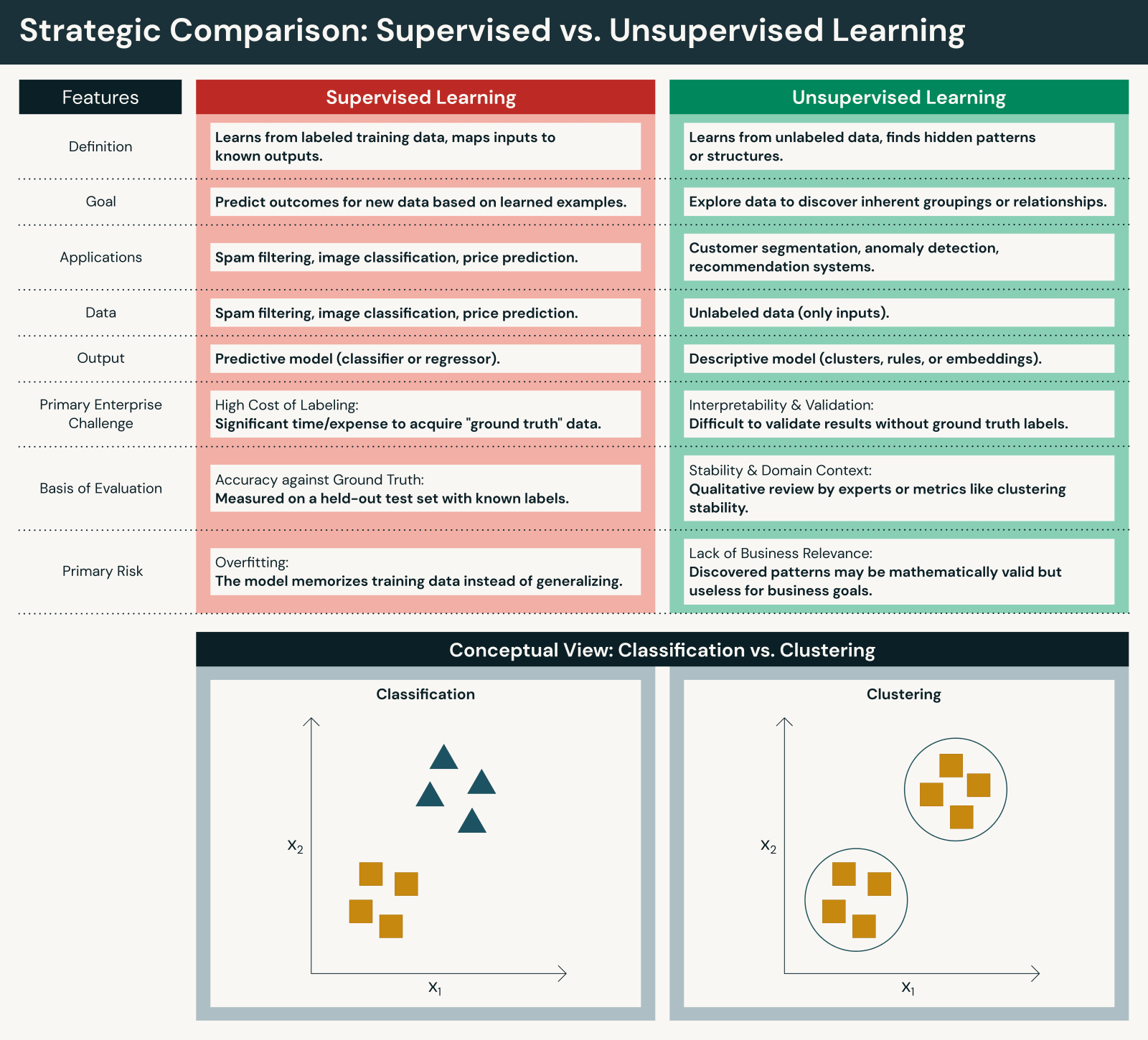
Bien que les deux approches soient fondamentales, elles diffèrent de manière importante :
Données et effort humain
- L'apprentissage supervisé nécessite des ensembles de données étiquetés, souvent créés par annotation manuelle ou revue par des experts. Bien que l'apprentissage automatique supervisé nécessite une intervention humaine importante pour l'étiquetage, cette intervention humaine garantit que la précision correspond aux objectifs commerciaux.
- L'apprentissage non supervisé fonctionne directement sur des données brutes, réduisant la préparation initiale mais augmentant l'effort d'interprétation. L'apprentissage automatique non supervisé réduit l'intervention humaine pendant l'entraînement mais nécessite une intervention humaine pour interpréter les résultats.
Objectifs
- L'apprentissage supervisé se concentre sur la prédiction et la classification par rapport à des résultats connus afin de prédire les résultats avec précision.
- L'apprentissage non supervisé se concentre sur la découverte et la génération d'informations pour découvrir des modèles dans les données.
Évaluation et transparence
- Les modèles supervisés peuvent être évalués à l'aide de métriques de performance claires par rapport aux bonnes réponses (précision, rappel, score F1, RMSE, etc.).
- Les modèles d'apprentissage non supervisé nécessitent une évaluation indirecte et un contexte de domaine pour évaluer leur utilité (scores de silhouette, méthode du coude, validation par des experts du domaine, etc.).
Scalabilité
- L'apprentissage supervisé est souvent plus lent en raison des contraintes d'étiquetage.
- L'apprentissage non supervisé s'adapte naturellement au volume des données, mais peut produire des résultats plus bruités.
Dans les environnements d'entreprise, ces différences clés poussent les équipes vers des approches hybrides plutôt que des choix exclusifs.
Le guide pratique de l'IA agentique pour l'entreprise

Apprentissage semi-supervisé et auto-supervisé
Les systèmes d'IA modernes combinent de plus en plus de paradigmes :
L'apprentissage semi-supervisé combine un petit ensemble de données étiquetées avec un pool beaucoup plus large de données non étiquetées, réduisant les coûts d'étiquetage tout en conservant la précision prédictive.
L'apprentissage auto-supervisé va plus loin en permettant aux modèles de générer leurs propres signaux d'entraînement à partir de données brutes. Cette approche sous-tend de nombreux modèles fondamentaux modernes et a fait de l'apprentissage supervisé un rôle de raffinement plutôt qu'un point de départ.
Ces techniques permettent aux organisations de :
- Exploiter les actifs de données existants à grande échelle
- S'adapter plus rapidement aux nouvelles distributions de données
- Réduire la dépendance à l'étiquetage manuel
Il convient de noter que l'apprentissage supervisé et non supervisé ne représentent pas l'intégralité du paysage de l'IA. L'apprentissage par renforcement est un troisième paradigme majeur dans lequel les agents apprennent des comportements optimaux par essais et erreurs en interagissant avec des environnements, recevant des récompenses ou des pénalités pour leurs actions. Bien que l'apprentissage par renforcement sorte du spectre supervisé vs non supervisé, les systèmes modernes combinent de plus en plus les trois approches en fonction des exigences de la tâche.
Quand utiliser l'apprentissage supervisé par rapport à l'apprentissage non supervisé
En pratique, le bon choix dépend des données, des objectifs et des contraintes opérationnelles.
Évaluez vos données
- Disposez-vous de labels fiables aujourd'hui ?
- Pouvez-vous maintenir la qualité de l'étiquetage à mesure que les données augmentent ?
- À quelle fréquence vos données changent-elles ?
Définissez votre objectif
- Prédire des résultats ? L'apprentissage supervisé convient.
- Explorer une structure inconnue ? L'apprentissage non supervisé est souvent le bon point d'entrée.
Planifiez pour le cycle de vie complet
Quelle que soit l'approche, les systèmes performants dépendent de pipelines d'ingénierie des données fiables qui déplacent les données de l'ingestion à l'entraînement et à la production de manière cohérente.
De nombreuses équipes commencent par une exploration non supervisée, puis introduisent l'apprentissage supervisé une fois que les cibles et les métriques sont bien définies.
Pourquoi la gouvernance unifiée des données et de l'IA est essentielle pour une stratégie d'IA d'entreprise
À mesure que les systèmes d'IA évoluent, les entreprises doivent gérer l'accès, la lignée, la conformité et la responsabilité.
C'est là que la gouvernance unifiée des données devient essentielle. La gouvernance cohérente des données et des modèles dans tous les flux de travail garantit que les informations sont fiables et que les systèmes restent audibles à mesure qu'ils évoluent.
Répondre aux questions courantes
La régression linéaire est-elle supervisée ou non supervisée ?
La régression linéaire est un apprentissage supervisé car elle nécessite des valeurs de sortie étiquetées.
Quelle est la principale différence entre l'apprentissage supervisé et non supervisé ?
L'apprentissage supervisé prédit des résultats connus à l'aide de données étiquetées. L'apprentissage non supervisé découvre des modèles dans des données non étiquetées.
Ce que vous devez savoir pour aller de l'avant
Plusieurs tendances remodèlent l'IA d'entreprise :
- L'apprentissage auto-supervisé domine l'entraînement des modèles fondamentaux.
- L'apprentissage supervisé sert de plus en plus de couche de précision.
- Le clustering et les embeddings deviennent des capacités d'entreprise clés.
- L'évaluation et la gouvernance prennent de plus en plus d'importance à mesure que l'utilisation des données non étiquetées s'étend.
Ces changements renforcent la nécessité de penser en systèmes, pas en silos.
Défis et limites
L'apprentissage supervisé et non supervisé jouent tous deux des rôles essentiels dans l'IA d'entreprise, mais chacun présente des compromis que les équipes doivent planifier tôt.
Défis de l'apprentissage supervisé
Les exigences en matière de données sont souvent la plus grande contrainte. La création d'ensembles de données étiquetés peut être longue et coûteuse, surtout lorsque l'étiquetage nécessite une expertise du domaine. Dans de nombreux cas, la précision du modèle est directement liée à la qualité des labels, ce qui fait des annotations incohérentes ou biaisées un risque sérieux.
Les modèles supervisés sont également confrontés à des risques de surapprentissage. Lorsque les modèles apprennent trop étroitement les données d'entraînement, ils peuvent bien performer lors de l'évaluation mais échouer à généraliser à de nouvelles données ou à des données inédites. Les atténuations courantes comprennent la validation croisée, les techniques de régularisation et l'expansion des ensembles de données d'entraînement pour mieux refléter la variabilité du monde réel.
Les préoccupations de scalabilité émergent à mesure que les volumes de données augmentent. L'étiquetage par boucle humaine ne s'adapte pas linéairement, et les processus manuels peuvent devenir des goulots d'étranglement pour les projets volumineux ou en évolution rapide. Sans une planification minutieuse, les flux de travail supervisés peuvent avoir du mal à suivre les demandes de l'entreprise.
Défis de l'apprentissage non supervisé
L'apprentissage non supervisé introduit un ensemble différent de problèmes, à commencer par la difficulté d'interprétation. Les clusters ou les modèles peuvent ne pas avoir de signification évidente sans contexte de domaine, et la structure découverte ne correspond pas toujours aux objectifs commerciaux. L'extraction de valeur nécessite souvent une collaboration étroite entre les data scientists et les experts du sujet.
La complexité de la validation est un autre défi. Sans labels de vérité terrain, il peut être difficile d'évaluer objectivement la qualité du modèle. Les équipes s'appuient souvent sur des métriques substituts, l'alignement métier ou une évaluation comparative entre plusieurs algorithmes pour renforcer la confiance dans les résultats.
Enfin, la sélection des algorithmes nécessite de l'expérimentation. Les résultats peuvent varier considérablement en fonction des choix de paramètres, des mesures de distance ou des étapes de prétraitement, rendant l'itération inévitable.
Meilleures pratiques en matière d'IA
Dans les deux approches, plusieurs pratiques améliorent systématiquement les résultats :
- Assurez des données d'entrée de haute qualité, y compris une gestion appropriée des valeurs manquantes et des valeurs aberrantes
- Commencez par une définition claire du problème avant de choisir une approche
- Mettez en œuvre des contrôles de qualité des données et des processus de validation dès le début
- Utilisez des métriques d'évaluation appropriées pour chaque paradigme
- Commencez par une analyse exploratoire des données avant de vous engager dans des flux de travail de production
Des solutions d'ingénierie des données fiables fournissent la base pour appliquer ces pratiques de manière cohérente, aidant les équipes à passer de l'expérimentation à la production avec plus de confiance.
Ce que vous devez savoir en 2026
Plusieurs changements remodèlent déjà la pratique de l'IA d'entreprise.
1. Le pré-entraînement auto-supervisé sous-tend désormais la plupart des modèles fondamentaux modernes
La plupart des modèles de pointe, y compris les grands modèles linguistiques, les systèmes de vision par ordinateur et les architectures multimodales, sont désormais entraînés principalement à l'aide de l'apprentissage auto-supervisé. Plutôt que de s'appuyer sur des ensembles de données étiquetés par des humains, ces modèles génèrent leurs propres signaux d'entraînement à partir de données brutes, comme prédire le prochain token dans une séquence ou reconstruire des parties masquées d'une entrée.
Ce changement reflète une réalité pratique : les entreprises possèdent de vastes quantités de données non étiquetées, mais l'étiquetage à grande échelle est coûteux et lent. L'apprentissage auto-supervisé permet aux organisations d'extraire de la valeur des actifs de données existants tout en construisant des représentations qui peuvent ensuite être adaptées à des tâches spécifiques.
2. Le réglage fin supervisé est devenu un rôle de raffinement
L'apprentissage supervisé n'a pas disparu, mais son rôle a changé. Au lieu de servir de mécanisme d'entraînement principal, le réglage fin supervisé est de plus en plus utilisé pour affiner, aligner et valider les modèles pour des objectifs commerciaux bien définis.
Cette approche permet aux équipes de concentrer les efforts d'étiquetage là où la précision est la plus importante, comme pour les exigences réglementaires, les contraintes de sécurité ou la précision spécifique au domaine, tout en évitant un étiquetage inutile plus tôt dans le pipeline.
3. Les embeddings sont désormais des capacités d'entreprise clés
Les embeddings sont devenus une infrastructure d'entreprise essentielle. Les modèles fondamentaux génèrent de plus en plus des embeddings vectoriels qui capturent la signification sémantique du texte, des images, de l'audio et des données structurées. Ces embeddings alimentent la recherche de similarité, la récupération, la personnalisation, la détection d'anomalies et les systèmes de recommandation à grande échelle.
Le clustering et d'autres méthodes basées sur la similarité sont importants, mais ce sont des applications en aval des embeddings plutôt que des paradigmes pairs. Le changement stratégique n'est pas vers le clustering lui-même, mais vers des architectures centrées sur les embeddings qui permettent la recherche, la récupération et le raisonnement unifiés sur les données de l'entreprise.
À mesure que les organisations opérationnalisent l'IA, les embeddings deviennent le tissu conjonctif entre le pré-entraînement auto-supervisé, le réglage fin supervisé et les applications en aval. Ils fournissent une couche de représentation commune qui prend en charge à la fois l'exploration et les flux de travail de précision au sein des plateformes de données unifiées modernes.
Construisez des systèmes, pas des côtés
L'apprentissage supervisé et non supervisé résolvent des problèmes différents — et les systèmes ML modernes ont besoin des deux. L'apprentissage automatique supervisé excelle lorsque vous disposez de données étiquetées et que vous avez besoin de prédictions ou de classifications précises et fiables. L'apprentissage automatique non supervisé prospère lorsque l'objectif est la découverte, aidant les équipes à découvrir des modèles et des informations dans des données brutes sans sorties prédéfinies. Lorsque les données étiquetées sont limitées, les approches d'apprentissage semi-supervisé comblent le fossé en combinant les deux paradigmes.
Le véritable défi n'est pas de choisir entre l'apprentissage supervisé et non supervisé, mais de construire des systèmes capables de combiner les approches, d'évoluer avec le temps et de fonctionner de manière fiable en production. Les équipes efficaces commencent par évaluer la disponibilité de leurs données, en clarifiant si leur objectif principal est la prédiction ou l'exploration, et en évaluant les ressources nécessaires pour soutenir chaque approche.
Les stratégies d'apprentissage automatique sont rarement statiques. L'exploration non supervisée informe souvent le développement ultérieur de modèles supervisés, tandis que le réglage fin supervisé apporte précision et validation aux systèmes construits sur des représentations plus larges. Au fil du temps, les informations doivent être intégrées à la business intelligence et à l'analytique où elles peuvent éclairer les décisions et générer des résultats.
Pour approfondir, explorez ces ressources :
- Un guide compact pour le réglage fin et le pré-entraînement des LLM — Apprenez les techniques pour régler fin et pré-entraîner votre LLM
Obtenez le guide - Le grand livre de l'IA générative — Bonnes pratiques pour construire des applications GenAI de qualité production
Télécharger - Le grand livre des cas d'utilisation de l'apprentissage automatique — Obtenez tout ce dont vous avez besoin pour mettre l'apprentissage automatique au travail
Lire maintenant
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.