Grands modèles de langage
Accélérez l'innovation avec les grands modèles de langage de Databricks

Qu'est-ce qu'un grand modèle linguistique ?
Les grands modèles de langage (LLM) sont des modèles de machine learning extrêmement efficaces lorsqu'il s'agit d'effectuer des tâches liées au langage : traduire, répondre à des questions, discuter et résumer des textes, mais aussi générer du contenu et du code. Les LLM extraient la valeur de vastes corpus de données et rendent cet « apprentissage » directement accessible. Databricks met ces LLM à votre disposition afin que vous puissiez les intégrer à vos workflows. Grâce aux capacités de la plateforme, vous pourrez affiner les LLM à l'aide de vos propres données afin d'optimiser leurs performances.

Traitement du langage naturel avec les LLM (grands modèles de langage)
S&P Global utilise de grands modèles de langage sur Databricks pour mieux comprendre les différences et les points communs entre les dossiers des sociétés. Cela aide les gestionnaires d'actifs à constituer un portefeuille plus diversifié.
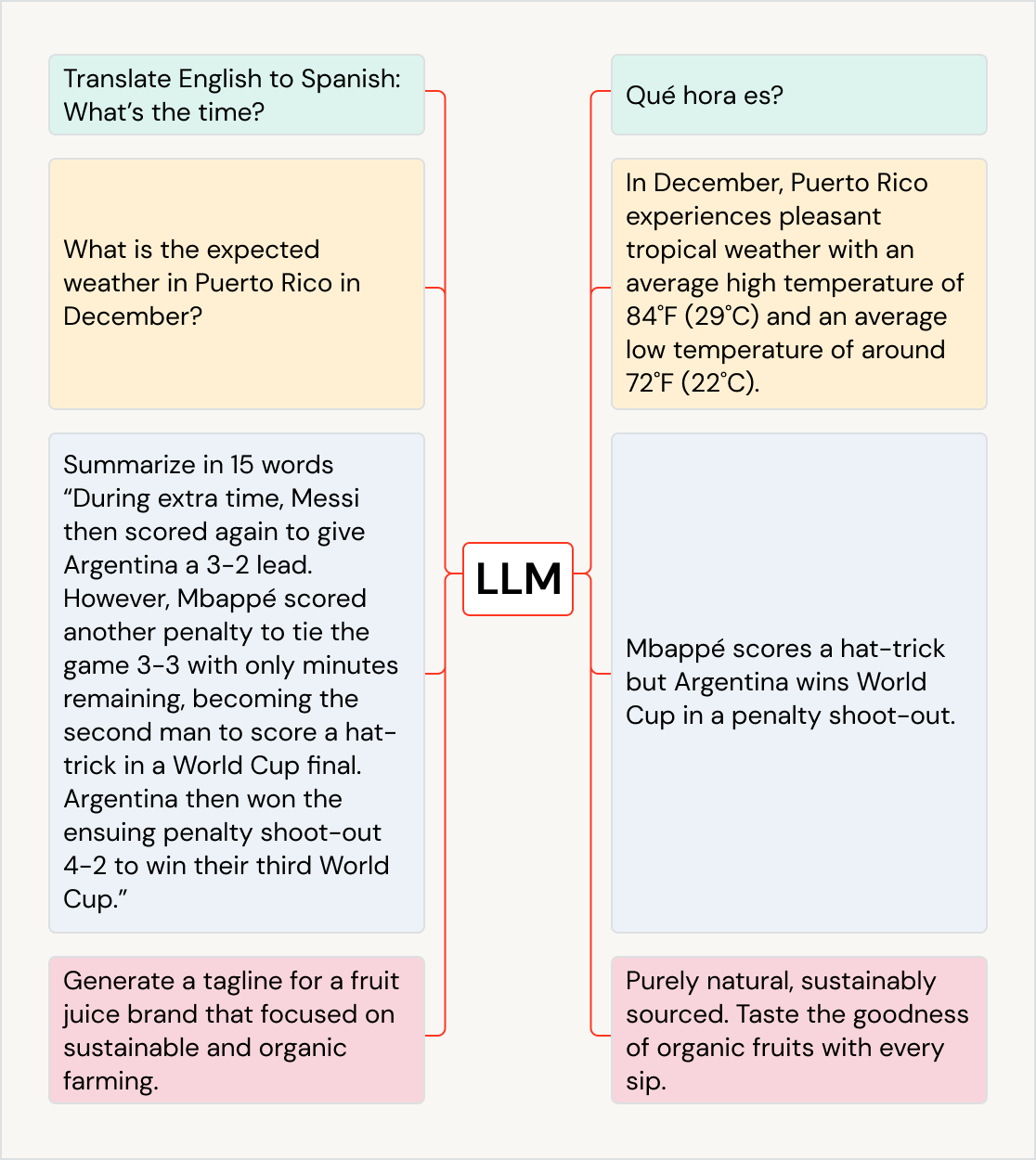
Les nombreux cas d'usage des LLM
Les LLM (grands modèles de langage) peuvent avoir un impact sur de nombreux cas d'usage dans un grand nombre de secteurs. Ils aident ainsi à traduire du texte dans d'autres langues, à améliorer l'expérience des clients avec des robots conversationnels et des assistants IA, et à organiser et classer les avis des clients pour les orienter vers le bon service. Ils permettent aussi de résumer de longs documents comme les conférences sur les revenus et les dossiers juridiques, de créer du contenu marketing et de générer du code logiciel à partir du langage naturel. Ils peuvent même alimenter d'autres modèles, comme ceux qui produisent des images. Parmi les LLM les plus populaires, citons la famille GPT (dont ChatGPT), BERT, T5 et BLOOM.
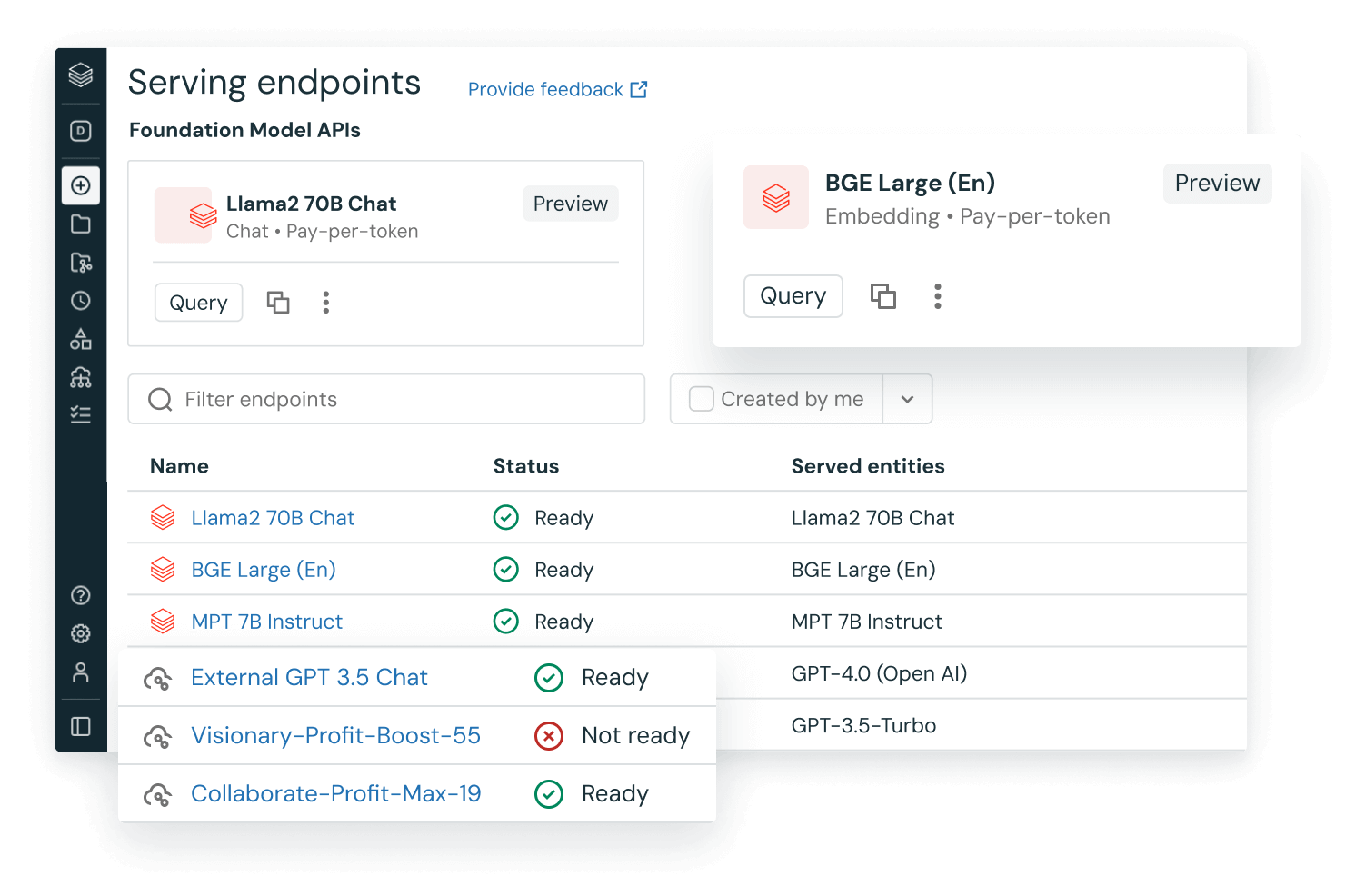
Des LLM pré-entraînés dans vos applications
Intégrez à vos workflows des modèles pré-entraînés, comme ceux de la bibliothèque Transformers de Hugging Face ou d'autres bibliothèques open source. Les pipelines de transformation facilitent l'utilisation des GPU et le regroupement des éléments à traiter pour optimiser le débit.
Avec la version de MLflow pour les transformateurs HuggingFace, vous profitez d'une intégration native des pipelines, des modèles et des composants de traitement du transformateur au sein du service de suivi MLflow. Vous pouvez également intégrer des modèles OpenAI et des solutions de partenaires comme John Snow Labs à vos workflows Databricks.
Grâce aux fonctions d'IA, les data analysts SQL accèdent sans problème aux modèles LLM, OpenAI inclus, directement depuis leurs pipelines de données et leurs workflows.
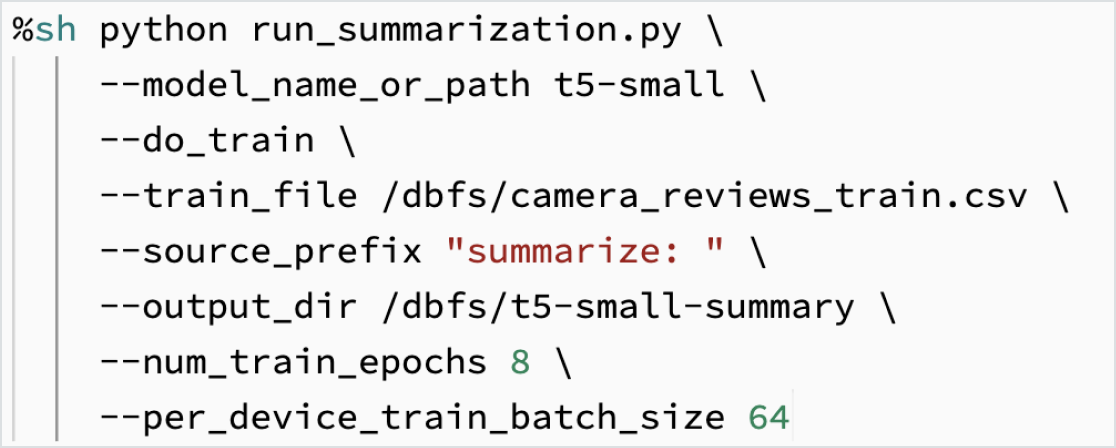
Affiner les LLM avec vos données
Utilisez vos données pour personnaliser un modèle et l'adapter à votre tâche. Grâce aux outils open source comme Hugging Face et DeepSpeed, vous pouvez rapidement exploiter un LLM et l'entraîner avec vos propres données pour améliorer la précision des résultats dans vos applications. Cette approche vous donne également un contrôle accru sur les données d'entraînement, ce qui est un atout pour l'utilisation responsable de l'IA.

Dolly 2.0 est un grand modèle de langage qui a été entraîné par Databricks pour démontrer comment vous pouvez entraîner rapidement et à peu de frais votre propre LLM. L'ensemble de données de haute qualité générées par l'homme (databricks-dolly-15k) utilisé pour entraîner le modèle a également été mis à la disposition de tous. Avec Dolly 2.0, les clients peuvent désormais posséder, exploiter et personnaliser leur propre LLM. Les entreprises peuvent créer et former un LLM sur leurs propres données, sans avoir besoin d'envoyer des données à des LLM propriétaires. Pour obtenir le code Dolly 2.0, les poids des modèles ou le jeu de données databricks-dolly-15k, visitez le site HuggingFace.
Intégration des LLMOps (MLOps pour les LLM)
Les MLOps intégrées sont utilisables en production. Utilisez-les avec le MLflow managé pour effectuer le suivi, la gestion et le déploiement des modèles. Une fois le modèle déployé, vous pouvez notamment surveiller la latence et la dérive des données pour déclencher des pipelines de réentraînement en cas de besoin. Et tout cela sur la même plateforme lakehouse Databricks unifiée pour des LLMOps de bout en bout.
Les données et les modèles sur une même plateforme unifiée
La plupart des modèles doivent être entraînés plus d'une fois. C'est pourquoi il est essentiel que les données d'entraînement se trouvent sur la même plateforme ML, pour des questions de coût mais aussi de performance. En entraînant des LLM sur le lakehouse, vous avez accès à des outils et à une puissance de calcul de pointe, aux tarifs extrêmement compétitifs du data lakehouse. Vous pouvez par ailleurs réentraîner vos modèles au fil de l'évolution de vos corpus.