Lakehouse Monitoring : une solution unifiée pour la qualité des données et l'IA
Introduction
Databricks Data Quality Monitoring vous permet de surveiller tous vos pipelines de données, des données aux caractéristiques et aux modèles de ML, sans outils ni complexité supplémentaires. Intégré à Unity Catalog, il vous permet de suivre la qualité en parallèle de la gouvernance et d'obtenir des informations approfondies sur les performances de vos données et AI assets. Lakehouse Monitoring est entièrement serverless, vous n'avez donc jamais à vous soucier de l'infrastructure ou du réglage de la configuration de compute.
Notre approche de surveillance unique et unifiée simplifie le suivi de la qualité, le diagnostic des erreurs et la recherche de solutions directement dans la Databricks Data Intelligence Platform. Continuez votre lecture pour découvrir comment vous et votre équipe pouvez tirer le meilleur parti de Lakehouse Monitoring.
Pourquoi Lakehouse Monitoring ?
Voici un scénario : votre pipeline de données semble fonctionner sans problème, mais vous découvrez que la qualité des données s'est dégradée silencieusement au fil du temps. C'est un problème courant chez les data engineers : tout semble aller bien jusqu'à ce que quelqu'un se plaigne que les données sont inutilisables.
Pour ceux d'entre vous qui entraînent des modèles de ML, le suivi des performances des modèles en production et la comparaison des différentes versions représentent un défi constant. Par conséquent, les équipes sont confrontées à des modèles qui deviennent obsolètes en production et doivent revenir à une version antérieure.
L'illusion de pipelines fonctionnels qui masquent une qualité de données en déclin rend difficile pour les équipes de données et d'IA le respect des SLA de livraison et de qualité. Lakehouse Monitoring peut vous aider à découvrir de manière proactive les problèmes de qualité avant que les processus en aval ne soient affectés. Vous pouvez anticiper les problèmes potentiels, en veillant à ce que les pipelines fonctionnent sans problème et que les modèles de machine learning restent efficaces au fil du temps. Fini les semaines passées à debugging et à annuler les changements !
Comment ça marche

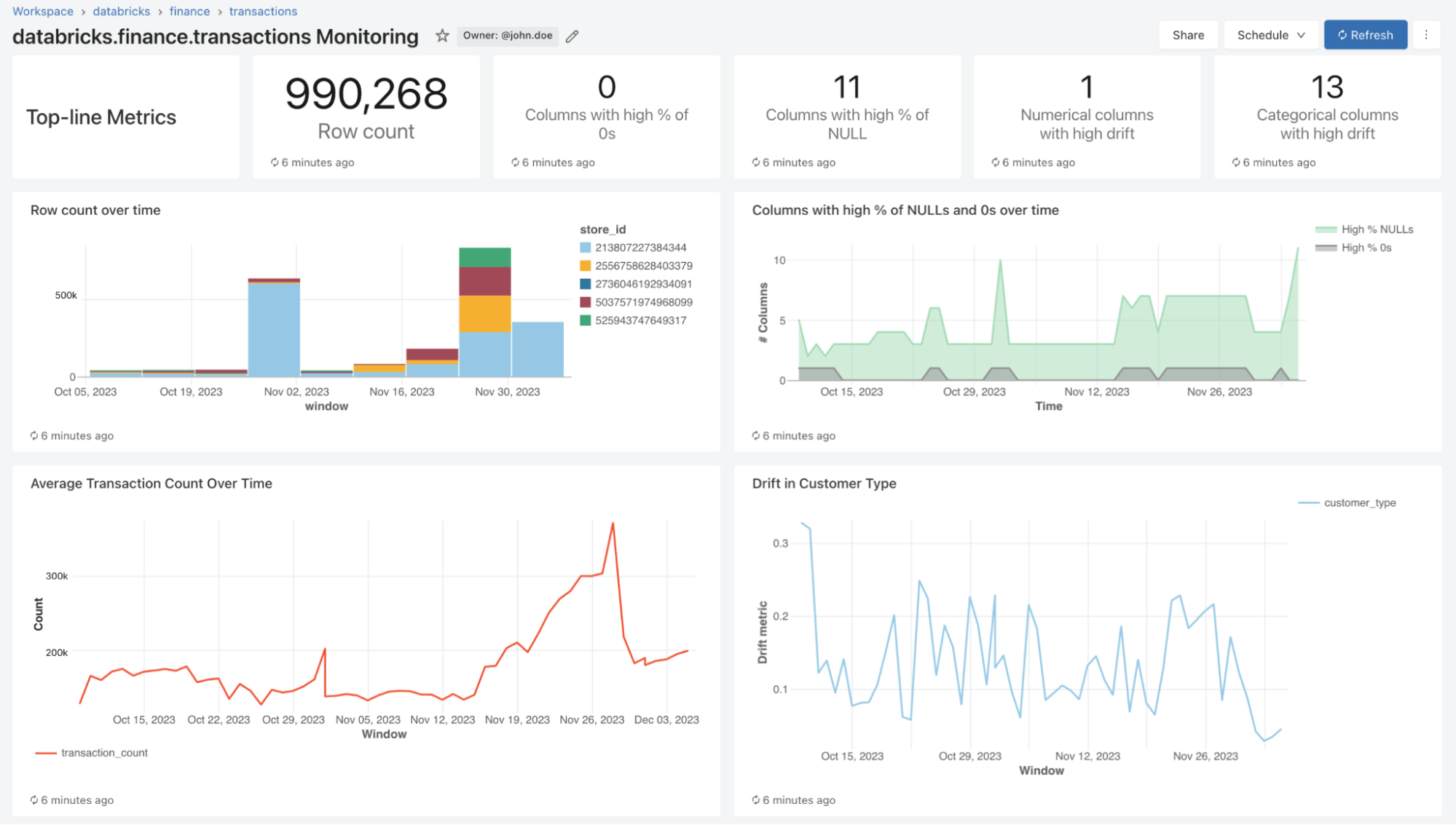
Avec Lakehouse Monitoring, vous pouvez surveiller les propriétés statistiques et la qualité de toutes vos tables en un seul clic. Nous générons automatiquement un tableau de bord qui visualise la qualité des données pour n'importe quelle table Delta dans Unity Catalog. Notre produit compute un riche ensemble de métriques prêtes à l'emploi. Par exemple, si vous faites du monitoring d'une table d'inférence, nous fournissons des métriques de performance du modèle, telles que le R-carré, la précision, etc. Alternativement, pour ceux qui font du monitoring des tables de Data Engineering, nous fournissons des métriques de distribution, notamment la moyenne, le min/max, etc. En plus des métriques intégrées, vous pouvez également configurer des métriques personnalisées (spécifiques à votre activité) que vous souhaitez que nous calculions. Lakehouse Monitoring actualise les métriques et maintient le tableau de bord à jour selon la planification que vous avez spécifiée. Toutes les métriques sont stockées dans des tables Delta pour permettre des analyses ad hoc, des visualisations personnalisées et des alertes.
Configurer la surveillance
Vous pouvez configurer le monitoring sur n'importe quelle table que vous possédez à l'aide de l'interface utilisateur de Databricks (AWS | Azure) ou de l'API (AWS | Azure). Sélectionnez le type de profil de monitoring que vous souhaitez pour vos pipelines de données ou vos modèles :
- Profil d'instantané : si vous souhaitez surveiller la table complète au fil du temps ou comparer les données actuelles à des versions précédentes ou à une ligne de base connue, un profil d'instantané sera le plus adapté. Nous calculerons ensuite des métriques sur toutes les données de la table et les mettrons à jour chaque fois que le moniteur sera actualisé.
- Profil de série temporelle : Si votre table contient des horodatages d'événements et que vous souhaitez comparer les distributions de données sur des fenêtres de temps (horaires, quotidiennes, hebdomadaires, ...), alors un profil de série temporelle sera le plus adapté. Nous vous recommandons d'activer le Change Data Feed (AWS | Azure) afin d'obtenir un traitement incrémentiel à chaque actualisation du moniteur. Remarque : vous aurez besoin d'une colonne d'horodatage pour configurer ce profil.
- Profil du journal d'inférence : si vous souhaitez comparer les performances des modèles au fil du temps ou suivre l'évolution des entrées et des prédictions du modèle, un profil d'inférence sera le plus adapté. Vous aurez besoin d'une table d'inférence (AWS | Azure) contenant les entrées et les sorties d'un modèle de classification ou de régression ML. Vous pouvez également inclure des étiquettes de vérité terrain pour calculer la dérive et d'autres métadonnées, telles que des informations démographiques, afin d'obtenir des métriques d'équité et de biais.
Vous pouvez choisir la fréquence d'exécution de notre service de monitoring. De nombreux clients choisissent une planification quotidienne ou horaire pour garantir la fraîcheur et la pertinence de leurs données. Si vous souhaitez que le monitoring s'exécute automatiquement à la fin de l'exécution du pipeline de données, vous pouvez également appeler l'API pour refresh le monitoring directement dans votre Workflow.
Pour personnaliser davantage le monitoring, vous pouvez définir des expressions de découpage afin de surveiller les sous-ensembles de caractéristiques de la table, en plus de la table dans son ensemble. Vous pouvez découper n'importe quelle colonne spécifique, par exemple l'ethnicité ou le sexe, pour générer des métriques d'équité et de biais. Vous pouvez également définir des métriques personnalisées basées sur les colonnes de votre table principale ou en plus des métriques prêtes à l'emploi. Pour en savoir plus sur l'utilisation des métriques personnalisées, consultez la documentation (AWS | Azure).
Visualiser la qualité
Dans le cadre d'un refresh, nous analyserons vos tables et modèles pour générer des métriques qui suivent la qualité au fil du temps. Nous calculons deux types de métriques que nous stockons pour vous dans des tables Delta :
- Métriques de profil: elles fournissent des statistiques récapitulatives de vos données. Par exemple, vous pouvez suivre le nombre de valeurs nulles et de zéros dans votre table ou les métriques de précision de votre modèle. Consultez le schéma de la table des métriques de profil (AWS | Azure) pour plus d'informations.
- Métriques de dérive: Elles fournissent des métriques de dérive statistique qui vous permettent d'effectuer une comparaison avec vos tables de référence. Pour plus d'informations, consultez le schéma de la table des métriques de dérive (AWS | Azure).
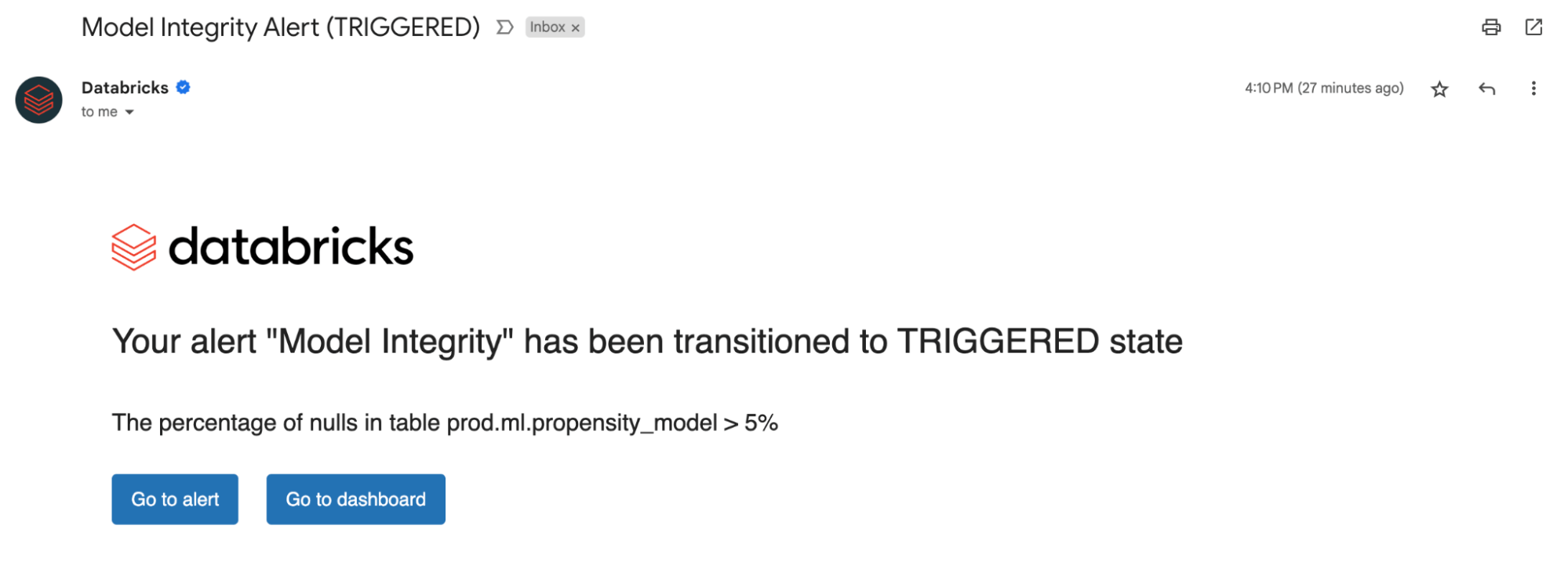
Pour visualiser toutes ces métriques, Lakehouse Monitoring fournit un tableau de bord prêt à l'emploi entièrement personnalisable. Vous pouvez également créer des alertes Databricks SQL (AWS | Azure) pour être averti des dépassements de seuil, des changements dans la distribution des données et du drift par rapport à votre table de référence.
Configuration des alertes
Que vous surveilliez des tables de données ou des modèles, la configuration d'alertes sur nos métriques calculées vous informe des erreurs potentielles et aide à prévenir les risques en aval.
Vous pouvez être alerté si le pourcentage de valeurs nulles et de zéros dépasse un certain seuil ou subit des changements au fil du temps. Si vous effectuez le monitoring de modèles, vous pouvez être alerté si les métriques de performance du modèle, telles que la toxicité ou la dérive, tombent en dessous de certains seuils de qualité.
Désormais, grâce aux insights issues de nos alertes, vous pouvez déterminer si un modèle doit être réentraîné ou s'il existe des problèmes potentiels avec vos données sources. Après avoir résolu les problèmes, vous pouvez appeler manuellement l'API de rafraîchissement pour obtenir les dernières métriques de votre pipeline mis à jour. Lakehouse Monitoring vous aide à prendre des mesures de manière proactive pour maintenir la santé et la fiabilité globales de vos données et de vos modèles.
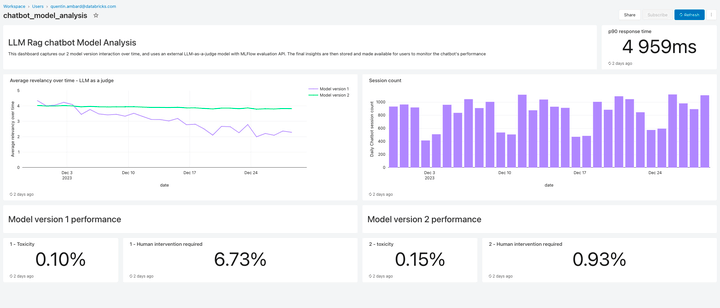
Surveiller la qualité des LLM
Lakehouse Monitoring offre une solution de qualité entièrement managé pour les applications de génération augmentée par récupération (RAG). Il analyse les sorties de votre application pour y déceler tout contenu toxique ou dangereux. Vous pouvez rapidement diagnostiquer les erreurs liées par ex. à des pipelines de données obsolètes ou à un comportement inattendu du modèle. Lakehouse Monitoring gère entièrement les pipelines de monitoring, ce qui permet aux développeurs de se concentrer sur leurs applications.
Et ensuite ?
Nous sommes enthousiasmés par l'avenir de Lakehouse Monitoring et nous sommes impatients de prendre en charge :
- Classification des données/Détection des PII – Inscrivez-vous à notre préversion privée ici!
- Attentes pour appliquer automatiquement les règles de qualité des données et orchestrer vos pipelines
- Une vue d'ensemble de vos moniteurs pour résumer la qualité et la santé de vos tables.
Pour en savoir plus sur Lakehouse monitoring et pour commencer dès aujourd'hui, consultez notre documentation produit (AWS | Azure). De plus, découvrez les récentes annonces concernant la création d'applications RAG de haute qualité, et rejoignez-nous pour notre webinaire GenAI.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.