Ouvrir les archives : transformer des documents non structurés en une base de données interrogeable pour la découverte des eaux souterraines
Comment Databricks for Good a aidé MapAid à tirer parti de l'AI pour transformer des archives statiques en un moteur de recherche opérationnel pour répondre à la crise de l'eau au Soudan
- MapAid s'est associé à Databricks for Good pour classifier et cataloguer près de 700 documents hydrogéologiques numérisés, transformant une collection non structurée en une base de données interrogeable.
- En utilisant l'AI multimodale, l'équipe a mis en place un pipeline serverless qui classifie les documents et extrait les informations relatives à l'eau directement à partir des images de pages numérisées.
- Les chercheurs peuvent désormais localiser des études historiques pertinentes en quelques secondes et accéder à des registres de puits qui alimentent directement les modèles de prédiction des eaux souterraines de MapAid, favorisant ainsi de meilleurs résultats de forage.
Introduction
À travers le Soudan, les communautés dépendent des eaux souterraines pour l'eau potable, l'irrigation et leur survie, mais le forage d'un puits productif est loin d'être garanti. La géologie est complexe, les aquifères varient considérablement et un forage infructueux peut coûter des milliers de dollars. Des décennies d'études géologiques et de rapports de terrain contiennent les données nécessaires pour améliorer les résultats, mais ces informations ont été dispersées dans des archives et n'ont jamais été organisées de manière systématique, ce qui les rend invisibles pour les personnes qui en ont le plus besoin.
MapAid est une organisation à but non lucratif fondée à l'Université de Stanford, dont la mission est de donner aux acteurs humanitaires et du développement, principalement en Afrique, les moyens de prendre des décisions basées sur les données grâce à une cartographie améliorée par l'AI. Leur outil phare, l'application WellMapr (gratuite), utilise l'AI et des données géospatiales pour identifier les zones d'eaux souterraines peu profondes, guidant ainsi les forages à faible coût pour l'eau potable et l'irrigation des petits exploitants agricoles. Les données historiques sur les puits, les forages et la géologie des aquifères constituent une entrée essentielle pour ces modèles.
La Sudan Association for Archiving Knowledge (SUDAAK) conserve l'une des plus riches collections de ces données : près de 700 PDF, TIFF et JPG numérisés, totalisant plus de 5 000 pages d'études géologiques, de rapports de forage de puits et d'études de terrain, disponibles publiquement sur wossac.com. Cependant, disponibilité ne rime pas avec accessibilité. Un chercheur à la recherche de données de forage dans une région spécifique du Soudan devrait passer manuellement au crible des centaines de documents. Les données ont été numérisées, mais sans système de recherche, elles restaient inexploitées.
Classification de documents numérisés avec l'AI multimodale
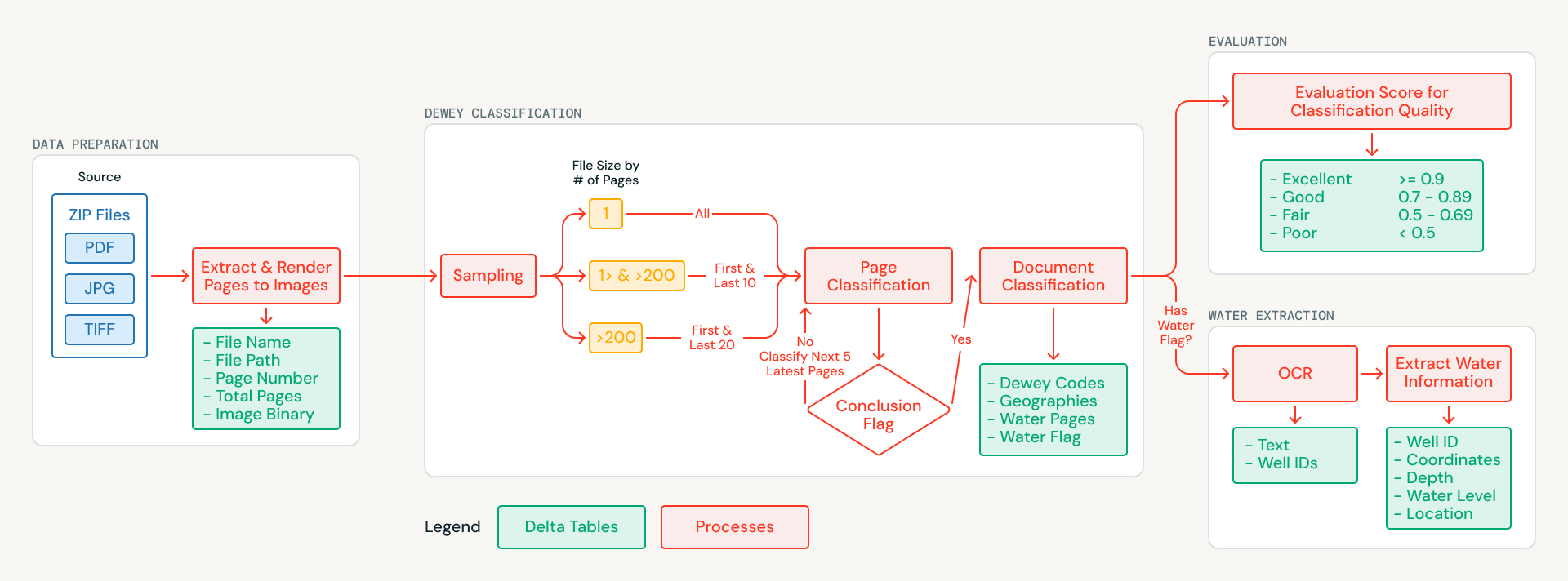
Databricks s'est associé à MapAid pour concevoir un pipeline basé sur l'AI qui classifie chaque document de l'archive, le tague avec des métadonnées géographiques et thématiques, et extrait des enregistrements structurés de puits et de forages à partir de documents liés à l'eau. Le système fonctionne entièrement sur Databricks et est packagé pour un déploiement en une seule commande. Cet article présente l'approche technique et la manière dont elle se généralise à toute organisation cherchant à extraire des connaissances structurées à partir de vastes collections de documents numérisés non structurés.
L'archive présentait des défis qui excluaient l'extraction de texte traditionnelle. Les documents sont des scans de rapports physiques, vieux de plusieurs décennies, sans couche de texte intégrée. Certaines pages sont de travers, d'autres combinent l'anglais et l'arabe, et beaucoup comprennent des notes de terrain manuscrites. Plutôt que de tenter une OCR dans un premier temps, l'équipe a reformulé le problème comme un problème de compréhension visuelle : envoyer les images des pages numérisées directement à des modèles d'AI multimodaux capables d'interpréter visuellement le contenu.
Les pages de chaque document sont converties en images et stockées dans des volumes Unity Catalog Volumes, créant ainsi un ensemble de données de base propre et versionné. À partir de là, une stratégie d'échantillonnage intelligente réduit les coûts de traitement : les documents plus courts sont analysés dans leur intégralité, tandis que les documents plus longs sont échantillonnés à partir de leurs sections les plus informatives (pages de titre, introductions et conclusions). Cela a permis de réduire le volume de traitement de l'AI de plus de 70 % tout en préservant la qualité de la classification.
Chaque page échantillonnée est analysée à l'aide des Databricks AI Functions (ai_query), qui prennent en charge de manière native les entrées multimodales et les sorties JSON structurées. Le modèle examine l'image de chaque page et renvoie :
- Les codes de classification décimale de Dewey, le système universel de classification des bibliothèques
- Les zones géographiques soudanaises référencées dans le contenu
- Un indicateur de pertinence pour l'eau signalant si la page contient des données sur les puits, les forages ou les aquifères
Comme les AI Functions s'exécutent directement dans SQL, l'équipe a pu itérer sur les prompts et les schémas de sortie sans avoir à créer d'infrastructure distincte pour le service de modèles. Les résultats au niveau de la page sont agrégés en classifications au niveau du document, produisant un catalogue structuré et interrogeable où chaque document est étiqueté avec son sujet et son champ d'application.
{kind=link}
Extraction d'enregistrements structurés de puits et de forages
De nombreux documents signalés comme liés à l'eau contiennent exactement le type d'informations structurées dont dépendent les modèles WellMapr de MapAid : l'emplacement des puits, les profondeurs de forage, les mesures de la nappe phréatique et les débits. Ces informations sont souvent réparties dans l'ensemble d'un document, les coordonnées apparaissant dans une section, les mesures de profondeur dans une autre et les données de débit dans un tableau récapitulatif plusieurs pages plus loin. L'extraction et la liaison de ces données constituaient un objectif central du partenariat.
Pour chaque document lié à l'eau, le pipeline traite chaque page plutôt que le seul sous-ensemble échantillonné utilisé pour la classification. L'OCR est effectuée page par page à l'aide d'un modèle multimodal fourni via l'Foundation Model API, qui gère l'anglais, l'arabe et les mises en page complexes, y compris les notes de terrain manuscrites, les données tabulaires et les pages aux formats mixtes. Pendant l'OCR, le système applique également une approche de reconnaissance d'entités, identifiant les identifiants de puits et de forages comme des entités d'ancrage afin que les enregistrements s'étendant sur plusieurs pages puissent être reliés à un site unique.
Le texte extrait de toutes les pages est fusionné en une représentation de document unifiée, qui est ensuite traitée dans un second passage pour extraire des enregistrements structurés au format JSON capturant les noms des sites, les coordonnées GPS, les profondeurs de forage, les niveaux d'eau statiques et les débits des essais de pompage. Les Databricks AI Functions imposent des réponses contraintes par un schéma, garantissant que ces attributs sont capturés de manière cohérente même s'ils apparaissent dans des formats ou des sections différents du document. Le résultat est un ensemble d'enregistrements structurés de puits et de forages prêts à être directement intégrés dans les modèles de prédiction WellMapr de MapAid.
Évaluation automatisée de la qualité à l'échelle
La validation manuelle de centaines de classifications hydrogéologiques spécialisées nécessiterait des ressources importantes et une expertise approfondie du domaine. Plutôt que de traiter l'évaluation comme une étape distincte à réaliser après coup, l'équipe a intégré l'évaluation automatisée de la qualité directement dans le pipeline en tant qu'étape de premier plan. Un modèle d'AI distinct, également appelé via les AI Functions, fait office de juge : il évalue chaque classification selon une grille structurée couvrant la précision, l'exhaustivité et la cohérence. Pour chaque document, l'évaluateur compare les codes décimaux de Dewey et les étiquettes géographiques attribués au contenu de la page échantillonnée, afin de vérifier si les classifications sont étayées par ce que le modèle a réellement observé.
Chaque évaluation produit à la fois une note catégorielle (excellent, bon, passable ou médiocre) et une justification écrite expliquant le score, créant ainsi une piste d'audit pour chaque décision prise par le pipeline. Les documents dont le score est inférieur à un seuil de confiance sont signalés pour examen manuel, ce qui permet de concentrer les efforts humains limités sur les cas les plus importants. Lors de la première exécution complète, seule une petite fraction des classifications a nécessité une intervention humaine.
Déploiement d'une solution autonome sur Databricks
Un projet comme celui-ci touche toutes les couches de la pile de données et d'AI : stockage des fichiers, ingénierie des données, inférence de l'AI, analyse des sorties structurées, évaluation de la qualité et gouvernance. Databricks a fourni l'ensemble de ces éléments au sein d'un espace de travail unique. Les fichiers d'archives bruts sont stockés dans des volumes Unity Catalog, et toutes les sorties du pipeline sont écrites dans des tables Delta Lake avec une fiabilité ACID, une évolution des schémas et un lignage complet des données. Le pipeline est orchestré sous la forme d'un Lakeflow Job sur un calcul serverless, de sorte que MapAid ne paie que ce que chaque exécution consomme.
L'ensemble du système est packagé sous la forme d'un Databricks Asset Bundle, ce qui signifie qu'il peut être déployé, mis à jour et exécuté à l'aide d'une seule commande. MapAid a reçu une solution autonome qui peut être maintenue sans expertise sur plusieurs services cloud. Comme la logique du pipeline est découplée de l'archive spécifique qu'il traite, le même système pourrait être adapté à d'autres archives sur l'eau, à d'autres régions ou à d'autres domaines où de vastes collections de documents numérisés doivent être classifiées et rendues interrogeables.
Ce que cela signifie sur le terrain
Lors de sa première exécution complète, le pipeline a permis de :
- classifier 654 documents et 5 570 pages
- Terminé en moins de trois heures
- 95 % des classifications évaluées comme « excellentes » ou « bonnes » par l'évaluateur automatisé
- ~50 % de l'archive identifiée comme contenant des données relatives à l'eau
- 299 enregistrements structurés de puits et de forages extraits avec les noms de lieux, les profondeurs et les mesures de débit
Le pipeline a réduit ce qui aurait pris des semaines ou des mois à des experts du domaine en un processus qui se termine en quelques heures. L'archive peut désormais être consultée par classification, par zone géographique ou par présence de données sur l'eau. Chaque enregistrement extrait contenant des coordonnées et des données de profondeur alimente directement les prédictions d'eau souterraine de MapAid, favorisant ainsi des taux de réussite de forage plus élevés et un approvisionnement plus rapide en eau pour les communautés dans le besoin.
Alors que SUDAAK continue de numériser de nouveaux documents, le pipeline peut traiter chaque nouveau lot avec une seule commande, garantissant ainsi que le catalogue reste à jour à mesure que l'archive s'agrandit. Le travail de MapAid s'étend à l'Afrique de l'Est, notamment à l'Éthiopie et au Malawi, et des archives non classifiées similaires existent sur tout le continent. La méthodologie et l'infrastructure sont prêtes à passer à l'échelle.
Rupert Douglas-Bate, Chief Executive Officer (CEO) de MapAid, a partagé son point de vue sur ce partenariat : "Notre système d'AI en évolution, WellMapr, est destiné à révolutionner la recherche et la localisation à faible coût de sources d'eau souterraine durables, mais il a besoin de données sur l'eau des puits. Notre mission pour atteindre cet objectif a été grandement accélérée par notre collaboration avec Databricks for Good, qui nous a contactés par l'intermédiaire du Rotary International. Le projet Databricks for Good a été fondamental dans le développement de notre Online Water Library (OWL) avec le soutien de la Sudan Association for Archiving Knowledge (SUDAAK). L'équipe Databricks a aidé à transformer une vaste archive désorganisée de données historiques sur l'eau et les sols soudanais en un système structuré utilisant la classification décimale de Dewey. Cela nous permet d'identifier rapidement et à faible coût des données sur les puits d'eau souterraine durables, qui peuvent désormais être utilisées pour aider à développer notre algorithme WellMapr. MapAid est ravi d'utiliser OWL comme un outil de développement essentiel pour atténuer la sécheresse, prouvant que lorsque les bons partenaires s'alignent, nous pouvons accomplir l'« impossible » pour ceux qui en ont le plus besoin."
Découvrez d'autres de nos projets pro bono ci-dessous :
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.