Pourquoi vos agents ne peuvent pas lire les documents d’entreprise — et comment y remédier
Présentation de Document Intelligence sur Databricks
par Archika Dogra, Sergei Tsarev et Erich Elsen
- Les agents de pointe obtiennent toujours moins de 50 % de réussite dans les tâches réelles de documents d’entreprise. Le goulot d’étranglement n’est pas le raisonnement, mais la lecture.
- Le traitement des documents est le plafond de précision pour chaque flux de travail d’agent.
- Nous annonçons Document Intelligence pour combler cette lacune : offrant une précision basée sur la recherche, une échelle d’entreprise et une simplicité de bout en bout.
Les informations commerciales les plus importantes ne sont pas seulement stockées dans des entrepôts — elles résident dans les millions de documents qui alimentent les flux de travail essentiels de l'entreprise chaque jour : contrats, réclamations, factures, etc. Pendant une décennie, le traitement intelligent des documents (IDP) a été considéré comme un problème d'automatisation étroit, axé sur le back-office. À l'ère des agents, les enjeux sont fondamentalement différents : l'IDP est la base essentielle qui détermine si vos agents prennent des décisions auxquelles vous ferez réellement confiance.
Prenons le traitement des réclamations d'assurance. Sur le papier, c'est un flux de travail agentique idéal : ingérer une réclamation, extraire les détails, signaler les anomalies et la router. Les agents de pointe d'aujourd'hui gèrent facilement le raisonnement. Là où ils échouent, c'est dans la lecture des documents : PDF numérisés avec des mises en page incohérentes, tableaux imbriqués, notes manuscrites et variations de format entre chaque fournisseur. Un "10 000 $" est halluciné en "3 000 $", l'agent prend une décision erronée et le mauvais montant est payé silencieusement.
Nous constatons ce schéma généralisé : les agents raisonnent bien sur du texte propre mais échouent lorsqu'ils sont confrontés à de vrais documents d'entreprise. Il y a quelques mois, la recherche en IA de Databricks a publié OfficeQA, une référence basée sur des flux de travail de documents d'entreprise réels. Nous avons constaté que même les agents de pointe très performants obtenaient moins de 50 % de précision dans les tâches de raisonnement sur documents. Le goulot d'étranglement n'était pas le raisonnement — c'était la lecture.
C'est pourquoi nous sommes ravis d'annoncer Document Intelligence, construit sur trois piliers fondamentaux : précision basée sur la recherche, échelle d'entreprise et simplicité de bout en bout.
Chez Intercontinental Exchange, nous traitons des millions de documents financiers complexes et très variables chaque mois. Document Intelligence nous aide à transformer cette complexité en intelligence de marché structurée, nous permettant d'agir plus rapidement, d'offrir une plus grande valeur à nos clients et de débloquer des flux de travail agentiques qui accélèrent l'analyse et la prise de décision à grande échelle." —Anand Pradhan, CTO et Head of AI, Mortgage Data chez Intercontinental Exchange (NYSE)
Améliorer la qualité des agents sur des documents d'entreprise réels
Le traitement des documents est le plafond de précision pour chaque agent. Pour bien faire, l'équipe de recherche en IA de Databricks s'est donné pour mission de construire des systèmes spécialisés conçus pour la réalité complexe de ce que les entreprises traitent réellement : mises en page incohérentes, tableaux imbriqués, images et écriture manuscrite.
Cette recherche alimente un ensemble de fonctions IA chaînables qui décomposent le traitement des documents en étapes composables : ai_parse_document (maintenant disponible en général) convertit les scans bruts en texte structuré enrichi de la mise en page, tandis qu'en aval, ai_classify route correctement les documents, et ai_extract extrait les informations structurées clés qui comptent le plus. Ensemble, ils forment un pipeline d'intelligence documentaire que vous pouvez assembler facilement : analyser une fois, puis classifier, extraire et ré-extraire sans retraiter le document d'origine.
Alors, un meilleur traitement des documents rend-il les agents plus précis ? Lorsque nous avons comparé des documents d'obligations du Trésor réels via OfficeQA, le prétraitement avec ai_parse_document a permis un gain de performance moyen de 16 % sur tous les frameworks d'agents que nous avons testés. Le système de raisonnement de l'agent n'a pas changé du tout, mais la couche de données documentaires sous-jacente, si.
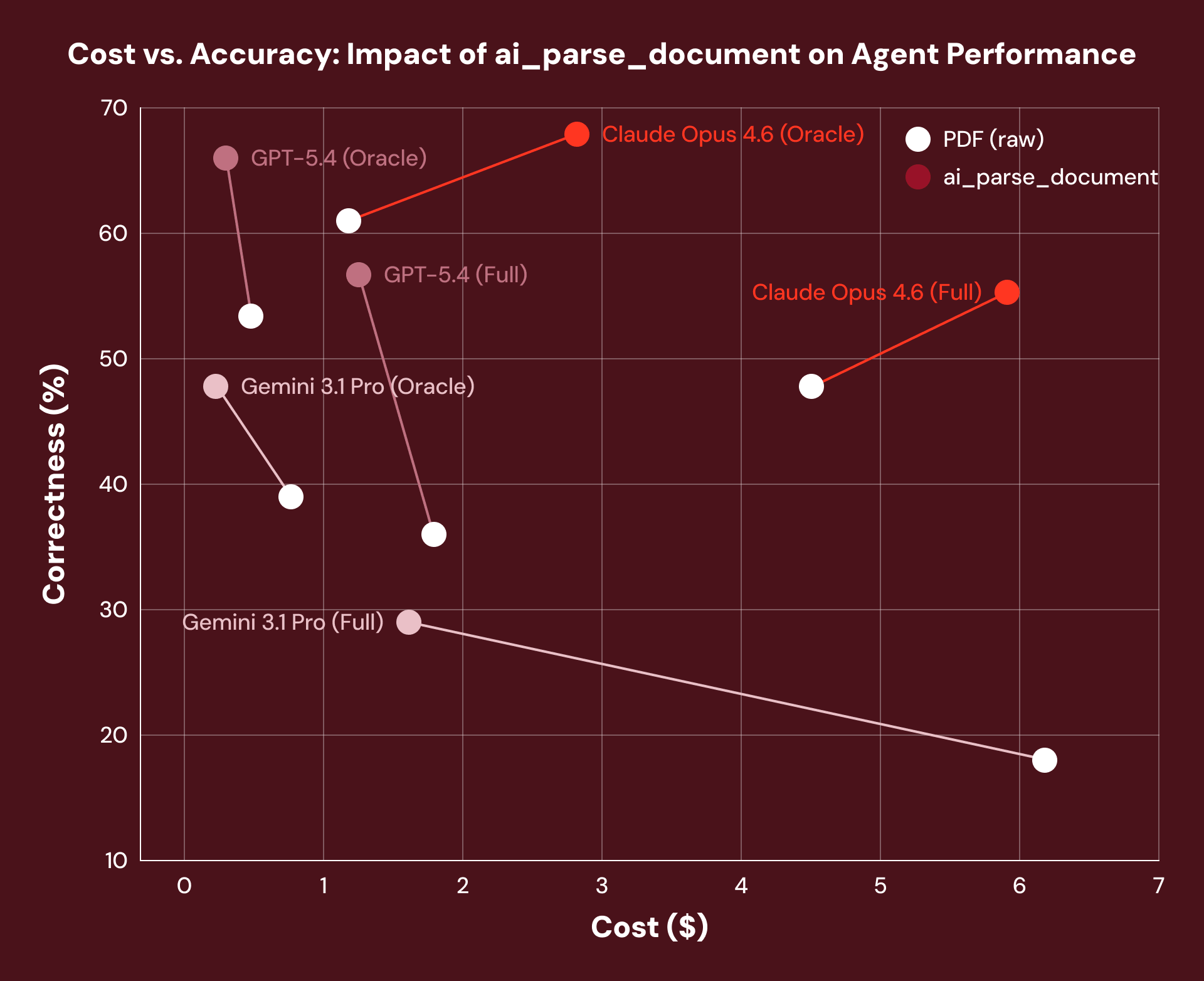
Note : Nous avons observé une augmentation des coûts de Claude Opus 4.6 en raison de la tendance du modèle à récupérer plus de jetons lorsqu'il reçoit le texte de mise en page structuré d'un document.
C'est exactement pourquoi nous avons construit Document Intelligence comme base de vos flux de travail agentiques : les gains de qualité et de coût du traitement des documents se composent à travers tout ce qui est construit dessus.
Avec Document Intelligence, nous posons les bases d'un pipeline de traitement intelligent des documents qui extrait des informations structurées clés de millions de PDF techniques non structurés chaque année, provenant de milliers d'organisations et couvrant des formats très incohérents. —Graham Lammers, Executive Director of Data Intelligence, Accuris
Débloquer l'intelligence documentaire à l'échelle de l'entreprise
Même lorsque la qualité est résolue, le cimetière des projets IDP d'entreprise est rempli de projets qui ont réussi le pilote mais n'ont pas pu survivre à l'économie de la production. Cela est dû à des coûts qui montent en flèche à six chiffres et à des travaux par lots qui prennent des jours au lieu d'heures.
Nous avons conçu Document Intelligence pour une économie à l'échelle de la production dès le départ, pas comme une réflexion après coup. Comme les fonctions IA comme ai_parse_document sont spécialisées par la recherche, elles atteignent une précision de pointe sans la surcharge de calcul des modèles à usage général.
Dans diverses solutions, nous avons comparé la précision et le coût des tâches d'extraction de documents structurés identifiant les entités clés des factures d'entreprise, des contrats, des notes médicales et des documents financiers. Document Intelligence a constamment atteint la plus haute précision à un coût 5 à 7 fois inférieur à celui des pipelines comparables.

Note : Les offres marquées (analyse + extraction) utilisent une architecture de pipeline en deux étapes — analyser une fois dans une couche argent réutilisable, puis extraire et ré-extraire sans ré-analyser. Les offres basées sur VLM retraient le document complet à chaque appel d'extraction.
Surtout, pour prendre en charge cette échelle, chaque fonction IA s'exécute sur une infrastructure de traitement par lots serverless conçue pour les charges de travail à haut volume : le même appel SQL en une ligne qui traite 100 factures traite 100 000 sans réarchitecturer votre pipeline.
Avec Document Intelligence, nous avons obtenu la même extraction d'entités de haute qualité à un coût près de 90 % inférieur en quelques semaines. Cette percée en termes de prix-performance alimente désormais nos pipelines de production, nous permettant de nous étendre plus rapidement dans de nouvelles zones de maladies, de traiter efficacement des centaines de millions de notes cliniques et de fournir des informations à nos clients à grande échelle. —Jerry Dennany, CTO Loopback Analytics
Surtout, pour le traitement à grande échelle, chaque fonction IA s'exécute sur une infrastructure de traitement par lots serverless conçue pour les charges de travail à haut volume : le même appel SQL en une ligne qui traite 100 factures traite 100 000 sans réarchitecturer votre pipeline.
Des pipelines fragmentés à un flux de travail unifié
Pour la plupart des entreprises aujourd'hui, l'intelligence documentaire n'est pas une capacité de plateforme. C'est une collection de pipelines ponctuels. Pour un seul cas d'utilisation, une équipe assemble un service OCR, ajoute une API d'extraction distincte et intègre un modèle de classification d'un autre fournisseur. Bientôt, ils gèrent trois à cinq API déconnectées maintenues par un code de liaison personnalisé fragile — un pipeline fragile, coûteux à maintenir et presque impossible à déboguer lorsqu'il tombe en panne à 3 heures du matin. Et lorsqu'une autre équipe a besoin de traiter un type de document différent, il n'y a rien de réutilisable sur quoi construire. Ils recommencent à zéro.
C'est le cycle qui maintient l'intelligence documentaire piégée dans une série de projets ponctuels au lieu d'une capacité à l'échelle de l'entreprise. Document Intelligence brise ce cycle. Au lieu d'assembler des services déconnectés, chaque étape s'exécute nativement dans votre couche d'orchestration et de gouvernance Databricks existante :
- Ingérez des documents (par exemple, depuis SharePoint) en utilisant Lakeflow Connect.
- Orchestrez le pipeline complet à l'aide de Lakeflow Jobs ou de Spark Declarative Pipelines, avec gestion intégrée des erreurs, observabilité et gestion automatique des nouveaux documents.
- Gouvernez la lignée de bout en bout, la sécurité et les contrôles d'accès de vos pipelines et de vos données — du document brut à la sortie de table structurée — avec Unity Catalog.
- Construisez des agents sur la nouvelle couche de données documentaires enrichie en utilisant la plateforme Agent Bricks.
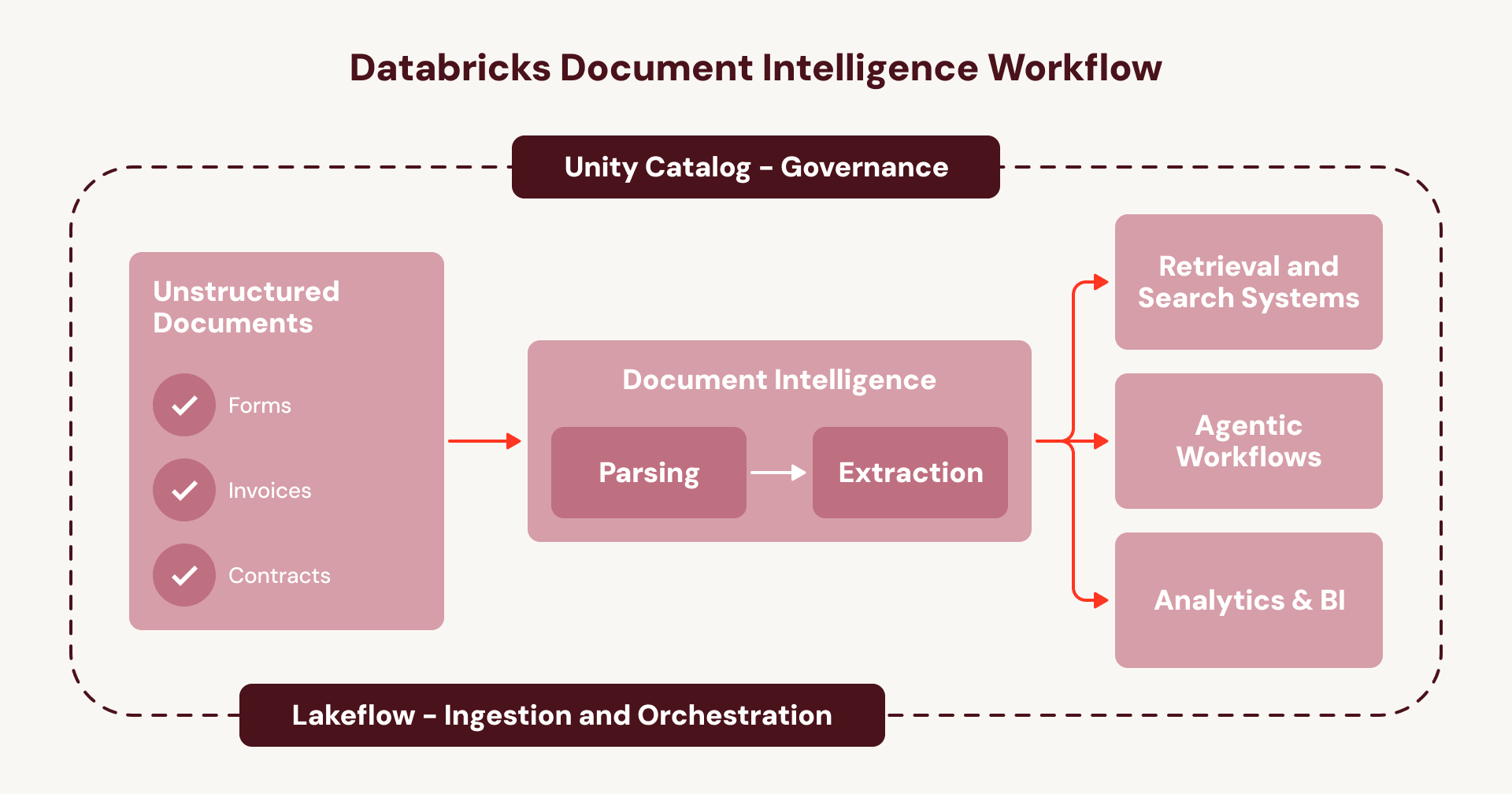
Pour les entreprises, cela signifie que l'intelligence documentaire s'exécute sur un flux de travail unifié et gouverné au lieu d'un réseau de services opaques et fragmentés — un playbook répétable pour mettre à l'échelle les cas d'utilisation agentiques sur tous vos documents.
Avec Databricks, nous sommes passés de processus manuels et fragmentés à une intelligence automatisée et évolutive. Ce qui prenait des semaines, nous le faisons maintenant en quelques jours — débloquant des informations que nos clients ne peuvent obtenir nulle part ailleurs. —Tony Qui, EY-Parthenon Global Innovation Leader, Strategy and Transactions
Vos agents ne sont bons qu'à la hauteur de votre couche de traitement de documents
La promesse des agents d'entreprise repose sur une question à laquelle la plupart des organisations n'ont pas encore répondu : vos agents peuvent-ils réellement comprendre les millions de documents de votre entreprise ?
C'est pourquoi nous sommes ravis d'annoncer Document Intelligence pour combler cet écart : suffisamment précis pour les flux de travail critiques pour l'entreprise, géré de bout en bout afin que votre équipe de conformité ne chasse pas les données entre les fournisseurs, et conçu pour passer de votre premier pilote à la production sans changer une ligne de code.
Vos documents sont la source d'intelligence la plus riche de votre entreprise. Il est temps que vos agents puissent les lire.
- Lisez notre blogue explicatif sur la création avec Document Intelligence et Lakeflow.
- Inscrivez-vous à l'essai Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.