Création avec Databricks Document Intelligence et Lakeflow
Transformez les connaissances d'entreprise verrouillées en intelligence interrogeable et fiable
par Giselle Goicochea et Joanna Zouhour
- La plupart des connaissances de l'entreprise sont inaccessibles dans des documents non structurés, tandis que le traitement intelligent des documents (IDP) actuel est souvent fragile et peu fiable
- Databricks Document Intelligence et Lakeflow permettent aux ingénieurs de données de construire et d'automatiser facilement un flux de travail IDP de bout en bout : ingestion de données non structurées, analyse avec une intelligence artificielle ancrée dans le contexte de l'entreprise, puis orchestration à grande échelle, le tout au sein d'une plateforme gouvernée
- Les équipes de données peuvent faire remonter des documents auparavant cachés dans des jeux de données fiables et interrogeables qui aident à découvrir de nouvelles perspectives, des flux de travail d'agents et de la valeur pour leur entreprise
Malgré des décennies de perfectionnement des pipelines de données structurées, 80 % des connaissances de l'entreprise restent pratiquement invisibles, piégées dans des PDF, des images et des documents de bureau.
Traditionnellement, le traitement intelligent des documents (IDP) a été un cauchemar fragmenté. Avant l'ère de l'IA générative, les organisations étaient obligées de s'appuyer sur des API NLP et de vision par ordinateur déconnectées qui se trouvaient en dehors de leurs plateformes de données principales. Ces fournisseurs d'OCR (reconnaissance optique de caractères) isolés offraient une précision limitée et manquaient de protocoles de gouvernance formels, créant ainsi des frictions importantes. Pour tenir la promesse de l'IA d'entreprise, nous avons besoin d'une approche unifiée qui intègre l'intelligence des données directement dans le cycle de vie des données.
Aujourd'hui, nous montrons comment les ingénieurs de données peuvent exploiter Lakeflow, la solution unifiée d'ingénierie de données de Databricks, et Databricks Document Intelligence pour débloquer ces données et les transformer en intelligence ayant un impact sur les affaires en créant des IDP autonomes de qualité production sur leur plateforme Databricks.

Étape 1 : Ingestion sécurisée avec Lakeflow Connect
Les documents d'entreprise résident dans des silos, accessibles uniquement via des intégrations d'API personnalisées et fragiles qui se cassent dès qu'un dossier est renommé. Lakeflow Connect, la solution de Databricks pour ingérer des données dans le lakehouse, change la donne avec des connecteurs intégrés pour de nombreuses applications d'entreprise, bases de données et sources de fichiers populaires, y compris SharePoint et Google Drive.
Cette solution offre une ingestion sans maintenance en éliminant le besoin de gérer des flux OAuth complexes ou des scripts Python personnalisés. Les documents atterrissent directement dans les volumes Unity Catalog et les tables, de sorte que le contrôle d'accès, la lignée et l'audit s'appliquent dès que le fichier est dans le lakehouse, et vous pouvez réutiliser les mêmes politiques granulaires basées sur les attributs sur lesquelles vous comptez déjà pour les données structurées.
Vous bénéficiez également d'une ingestion rapide et efficace à grande échelle grâce aux capacités robustes de Lakeflow Connect, y compris les lectures et écritures incrémentielles qui évitent les re-téléchargements complets de grandes bibliothèques pour les remplissages rétroactifs par lots et les flux de documents quasi en temps réel lorsqu'ils sont combinés avec le streaming en aval.
Étape 2 : Démarrer avec Databricks Document Intelligence
Ces documents d'entreprise contiennent certains des informations les plus précieuses de votre organisation, mais ils sont intrinsèquement désordonnés, variables et incohérents. Les pages numérisées, les notes manuscrites et les tables imbriquées piègent vos informations les plus précieuses. Pour résoudre ce problème, vous n'avez pas seulement besoin d'un autre outil d'extraction de documents ; comme le note Forrester, vous avez besoin d'une « évolution architecturale axée sur le raisonnement ». Avec cette approche, Gartner prédit que GenAI réduira de 70 % le besoin de modèles de documents personnalisés.
Aujourd'hui, avec Databricks Document Intelligence, vous pouvez apporter une compréhension de documents de pointe directement à vos données. Vos équipes d'ingénierie de données peuvent exploiter des fonctions IA spécialement conçues qui peuvent de manière fiable analyser, structurer et enrichir des documents complexes aux côtés de vos pipelines de données existants, le tout géré de manière transparente par Unity Catalog.
- ai_parse_document (nouveau - GA) : Cette fonction convertit les fichiers non structurés en représentations structurées à l'aide du type de données Variant. Elle gère nativement la complexité des entrées qui pose généralement problème aux analyseurs traditionnels, tels que les images numérisées, l'écriture manuscrite et les mises en page variables, tout en préservant la structure critique du document (par exemple, les tables imbriquées, les sections et les en-têtes) que l'extraction de texte plat perdrait. Cela vous permet d' faire évoluer les schémas au fil du temps sans casser vos pipelines. En aval, vous traitez la sortie VARIANT comme une représentation bronze/argent flexible, en la projetant dans des colonnes Delta dans vos couches argent/or à l'aide de SQL ou PySpark dans Lakeflow Spark Declarative Pipelines.
En plus de la structure analysée, vous pouvez enchaîner d'autres fonctions IA optimisées pour la recherche :
- ai_extract (PuPr) pour extraire des informations structurées telles que les dates d'entrée en vigueur et d'expiration des contrats, les contreparties, les totaux des factures, les taxes, la devise et les numéros de commande.
- ai_classify (PuPr) pour acheminer les documents par type (facture, commande, SOW, NDA), urgence/risque ou unité commerciale propriétaire.
- ai_prep_search (nouveau - Beta) pour diviser intelligemment les documents en morceaux pour une intégration en aval de haute qualité, les préparant pour des cas d'utilisation de récupération ou de recherche
Ci-dessous un exemple simple d'enchaînement de ai_parse_document et ai_extract.
Remarque : cet exemple montre PySpark, mais vous pouvez également utiliser SQL (voir la documentation).
Étant donné qu'il s'agit de fonctions IA gérées intégrées à la plateforme Databricks, Document Intelligence peut les combiner avec votre contexte d'entreprise (métadonnées du catalogue, sémantique métier, tables existantes) pour alimenter des flux de travail d'agents qui raisonnent sur vos données avec une grande précision, ancrés dans votre contexte de domaine d'entreprise.
Étape 3 : Productionnalisation des charges de travail IDP à grande échelle
Une fois que vous avez l'ingestion et l'analyse qui fonctionnent dans les notebooks, vous devez productionnaliser votre IDP : orchestrer l'ingestion, l'analyse, l'enrichissement et la diffusion. Mais vous voulez également surveiller les SLA, les échecs et les nouvelles tentatives dans CI/CD pour garantir la santé des pipelines.
Avec Lakeflow Jobs, l'orchestrateur natif de Databricks, vous pouvez transformer les charges de travail IDP en pipelines robustes et automatisés avec le même système d'orchestration que vous utilisez pour ETL, l'analyse et le ML. Il fournit une orchestration unifiée pour chaque tâche du DAG IDP, vous permettant d'enchaîner des notebooks, des scripts Python, des requêtes SQL, des pipelines, des LLM ou des appels d'agents dans un seul travail et de modéliser le flux complet depuis l'ingestion des documents.
Lakeflow Jobs est également livré avec un contrôle de flux avancé intégré (y compris les conditions si/sinon, pour chaque, les nouvelles tentatives, etc.) et des déclencheurs (mise à jour de table, arrivée de fichier, continu, etc.). Cela permet de 1) retraiter uniquement les partitions échouées ou les lots de documents spécifiques et 2) gérer les travaux pour s'adapter à des calendriers spécifiques, des déclencheurs basés sur des événements ou un mode continu pour les flux de documents en temps réel.
Avec le calcul serverless de Lakeflow Jobs avec une observabilité native, vous bénéficiez également d'une mise à l'échelle automatique avec les pics de volume de documents tout en affichant une surveillance en temps réel, des métriques et des alertes afin que vous puissiez identifier les goulots d'étranglement et réparer les échecs sans avoir à réexécuter les tâches réussies.
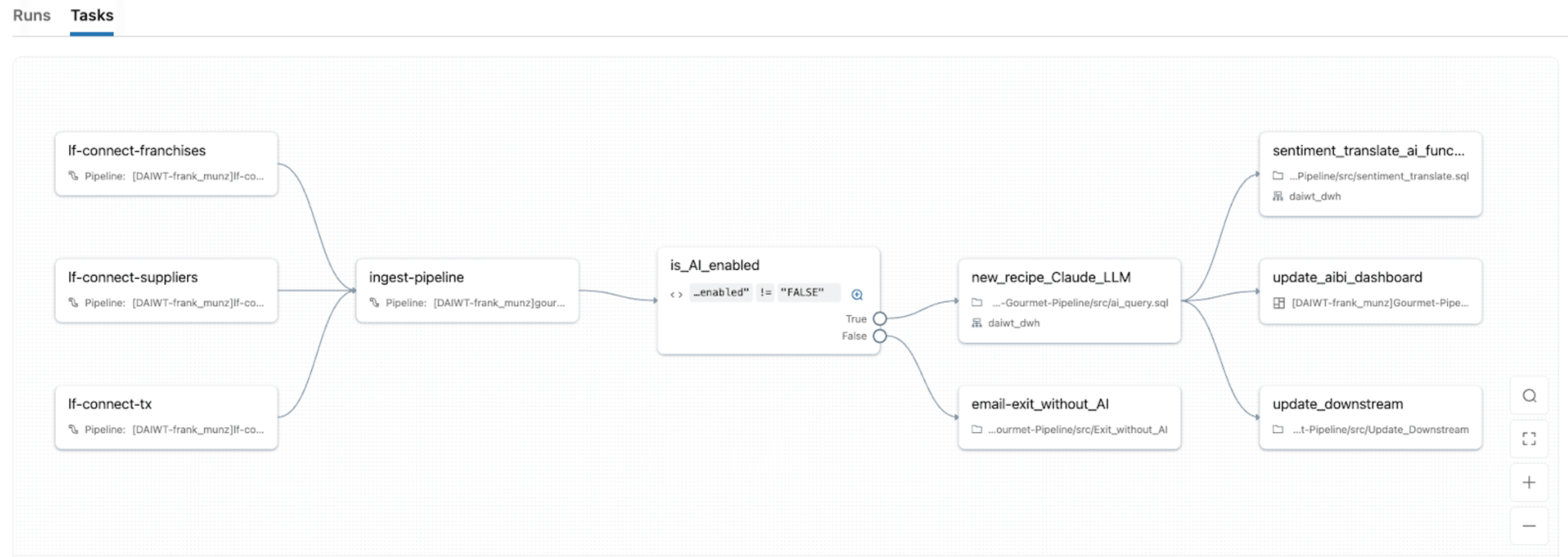
Ancrer l'IA dans le contexte de l'entreprise
L'IDP est le plus précieux lorsqu'il est soutenu par le contexte de l'entreprise : vos schémas uniques, vos définitions métier et votre sémantique personnalisée.
Unity Catalog
Unity Catalog fournit une gouvernance et une découverte unifiées sur les données structurées, les fichiers non structurés, les modèles ML et les métriques métier sur n'importe quel cloud. Pour l'IDP, cela signifie :
- Un emplacement unique pour définir les politiques d'accès, la lignée et l'audit pour les documents bruts et les tables structurées dérivées
- Prise en charge des formats ouverts (Delta, Apache Iceberg, Hudi, Parquet) pour que vous ne soyez pas enfermé dans une représentation propriétaire de documents
- Sémantique métier et métadonnées au niveau du catalogue que les agents peuvent utiliser pour nommer et interpréter de manière cohérente des entités telles que « Fournisseur », « Client » ou « Valeur du contrat ».
Intelligence Documentaire
Intelligence Documentaire utilise ce contexte pour construire des agents IA de production qui savent quelles tables, outils et modèles utiliser pour une tâche IDP donnée, sont gouvernés de bout en bout afin qu'ils n'accèdent jamais plus qu'ils ne le devraient, et s'améliorent continuellement grâce à l'évaluation de la qualité basée sur les LLM, des benchmarks spécifiques aux tâches et des boucles d'apprentissage. Pour les développeurs, Databricks fournit des API et des SDK afin que vous puissiez définir ces agents en tant que code et les intégrer dans vos pipelines CI/CD existants, tout comme tout autre actif de données ou ML.
Meilleures pratiques pour la pile IDP moderne
Pour passer du pilote à la plateforme, gardez ces meilleures pratiques à l'esprit :
- Enrichissement des données : Ne vous contentez pas d'extraire un "Nom du fournisseur". Joignez-le avec vos données maîtres internes ou des sources tierces (comme Dun & Bradstreet) pour fournir un contexte métier complet.
- Excellence opérationnelle : Utilisez des principaux de service pour les travaux Lakeflow afin d'assurer la stabilité du pipeline.
- Surveillance : Utilisez la surveillance Lakehouse pour suivre la dérive des modèles et la précision de l'extraction au fil du temps.
La voie vers l'intelligence de données moderne
Avec Databricks, vous pouvez maîtriser le cycle de vie complet du traitement intelligent des documents sur une plateforme de données moderne. La combinaison de Lakeflow et des fonctions IA vous permet de transformer des données non structurées et cachées en jeux de données fiables et interrogeables et d'exécuter de manière transparente des pipelines de documents observables aux côtés de votre ETL et ML principaux.
Maintenant que nous avons couvert la valeur stratégique de l'intelligence documentaire autonome, il est temps de la construire. Consultez notre article complémentaire, De PDF à Insights, pour une présentation technique étape par étape du déploiement de cette architecture exacte à l'aide de Databricks.
Vous pouvez également explorer la documentation sur l'Intelligence Documentaire et Lakeflow pour commencer à construire votre premier pipeline IDP dès aujourd'hui !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.