Qu'est-ce que Catalyst Optimizer ?
Comment l'optimiseur Catalyst utilise des techniques basées sur des règles et sur les coûts appliquées aux plans de requêtes arborescents pour rendre les requêtes Spark SQL plus rapides, plus efficaces et plus faciles à étendre
- Découvrez comment Catalyst s'intègre au cœur de Spark SQL en tant qu'optimiseur extensible, s'appuyant sur des fonctionnalités Scala telles que la correspondance de motifs et les quasi-citations pour prendre en charge de nouvelles règles et de nouveaux types de données.
- Comprenez comment Catalyst représente les requêtes sous forme d'arbres et applique des règles tout au long des phases d'analyse, d'optimisation logique, de planification physique et de génération de code afin de créer des plans d'exécution efficaces.
- Découvrez comment Catalyst prend en charge l'optimisation basée sur des règles et l'optimisation basée sur les coûts, et expose des points d'extension pour les sources de données externes et les types définis par l'utilisateur.
Le cœur de Spark SQL repose sur Catalyst optimizer, qui utilise de manière innovante des capacités avancées de codage (telles que le pattern matching et les quasiquotes de Scala) pour créer un optimiseur de requêtes extensible. Catalyst est basé sur des structures de programmation fonctionnelle en Scala et conçu avec deux objectifs clés :
- permettre une intégration aisée de nouvelles techniques et fonctionnalités d'optimisation à Spark SQL ; et
- offrir aux développeurs externes la possibilité d'étendre l'optimiseur en ajoutant des règles adaptées à leur source de données ou en prenant en charge de nouveaux types de données, entre autres.
Le guide pratique de l'IA agentique pour l'entreprise

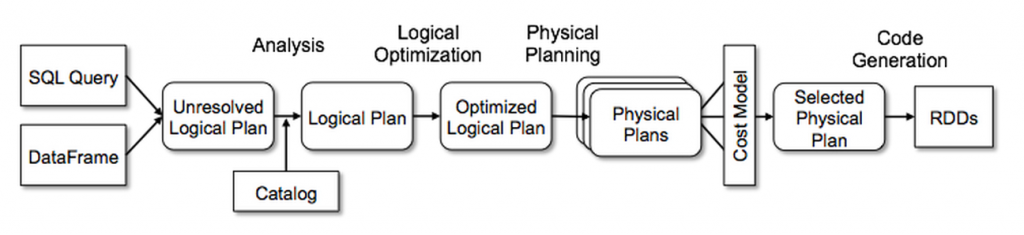
Catalyst dispose d'une bibliothèque générale pour représenter les arbres et appliquer des règles pour les manipuler. Au-dessus de ce cadre, Catalyst a des bibliothèques spécifiques au traitement des requêtes relationnelles (expressions, plans de requêtes logiques, etc.), et plusieurs ensembles de règles qui gèrent différentes phases de l'exécution des requêtes : analyse, optimisation logique, planification physique, et génération de code pour compiler des parties de requêtes en bytecode Java. Pour ce dernier, il utilise une autre fonctionnalité Scala, les quasiquotes, qui facilite la génération de code à l'exécution à partir d'expressions composables. Catalyst offre également plusieurs points d'extension publics, y compris des sources de données externes et des types définis par l'utilisateur. De plus, Catalyst prend en charge à la fois l'optimisation basée sur les règles et l'optimisation basée sur les coûts.
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.