Qu'est-ce que le réglage Spark ?
L'optimisation systématique des configurations, de l'utilisation de la mémoire et des stratégies d'exécution d'Apache Spark afin de maximiser les performances tout en évitant les goulots d'étranglement des ressources.
- L'optimisation de Spark ajuste l'allocation de mémoire entre le stockage et l'exécution, gère la sérialisation des données pour optimiser les performances réseau et optimise les partitions de brassage afin d'éviter les gaspillages de mémoire disque.
- L'exécution adaptative des requêtes (AQE) trouve automatiquement les partitions de brassage optimales et corrige les asymétries de données, tandis que l'optimiseur basé sur les coûts (CBO) utilise les statistiques des tables pour sélectionner des stratégies de jointure efficaces.
- Les techniques avancées incluent les jointures diffusées pour les petites tables, le pushdown des prédicats pour réduire les transferts de données et une gestion rigoureuse du cache et du stockage disque pour les accès répétés aux données.
Qu'est-ce que l'ajustement des performances Spark ?
L'ajustement des performances Spark consiste à modifier les paramètres de mémoire, de cœurs et d'instances utilisés par le système. Ce processus permet à Spark d'offrir des performances irréprochables et prévient la formation de goulets d'étranglement dans les ressources de Spark. 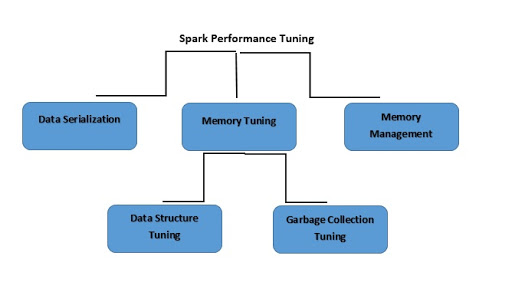
Qu'est-ce que la sérialisation des données ?
Pour réduire la consommation de mémoire, vous aurez peut-être à stocker les RDD Spark sous forme sérialisée. La sérialisation des données est également gage de bonnes performances réseau. Pour obtenir de bons résultats dans Spark :
- Mettez fin aux jobs qui n'aboutissent pas.
- Veillez à ce que les jobs soient réalisés sur un moteur d'exécution précis.
- Utilisez toutes les ressources efficacement.
- Améliorez les temps de performance du système
Spark prend en charge deux bibliothèques de sérialisation :
- Sérialisation Java
- Sérialisation Kryo
Qu'est-ce que l'ajustement de la mémoire ?
Trois aspects dominent l'ajustement de la consommation de la mémoire :
- L'intégralité du dataset doit pouvoir être contenue dans la mémoire ; il est donc indispensable de tenir compte de la mémoire utilisée par vos objets.
- En augmentant la rotation des objets, il devient indispensable de tenir compte de la collecte des déchets.
- Et vous devez évaluer le coût de l'accès à ces objets.
Le guide pratique de l'IA agentique pour l'entreprise

Qu'est-ce que l'ajustement de la structure des données ?
Une option pour réduire la consommation de mémoire consiste à éviter les fonctionnalités Java les plus coûteuses. Il y a plusieurs manières de procéder :
- Si la taille de la RAM est inférieure à 32 Go, le marqueur JVM doit être défini comme –xx:+ UseCompressedOops. Cette opération permet de créer un pointeur de quatre octets au lieu de huit.
- Il est possible d'éviter les structures imbriquées en utilisant plusieurs petits objets en plus des pointeurs.
- Au lieu d'employer des chaînes pour les clés, utilisez des identifiants numériques et des objets énumérés
Qu'est-ce que l'ajustement de la collecte des déchets ?
Pour éviter l'attrition importante associée aux RDD précédemment stockés par le programme, Java élimine les anciens objets pour faire de la place aux nouveaux. Il est toutefois possible d'utiliser des structures de données comprenant un nombre inférieur d'objets pour réduire considérablement les coûts. Pour prendre un exemple, pensez à un tableau d'entiers à la place d'une liste liée. Vous pouvez également utiliser des objets sous forme sérialisée, de façon à n'avoir qu'un seul objet pour chaque partition RDD.
Qu'est-ce que la gestion de la mémoire ?
De bonnes performances reposent avant tout sur une utilisation efficace de la mémoire. Spark utilise principalement la mémoire à des fins de stockage et d'exécution. La mémoire de stockage permet de mettre en cache des données qui seront réemployées par la suite. D'autre part, la mémoire d'exécution sert à effectuer des calculs pour les shuffles, les tris, les jointures et les agrégations. La contention de mémoire pose trois difficultés à Apache Spark :
- Comment arbitrer la mémoire entre l'exécution et le stockage ?
- Comment arbitrer la mémoire entre des tâches exécutées simultanément ?
- Comment arbitrer la mémoire entre des opérateurs exécutés au sein de la même tâche ?
Au lieu d'éviter de réserver statiquement la mémoire à l'avance, vous pouvez gérer la contention de la mémoire lorsqu'elle se produit en forçant un déversement.
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.