Que sont les applications Spark ?
Découvrez comment les processus de pilote et d'exécution fonctionnent ensemble pour exécuter des calculs distribués sur un cluster.
- Comprendre l'architecture des applications Spark, notamment la manière dont les processus pilotes gèrent la logique applicative et coordonnent le travail au sein du cluster.
- Découvrir comment les processus d'exécution exécutent les tâches qui leur sont assignées et communiquent l'état des calculs au pilote.
- Explorer comment les gestionnaires de clusters tels que YARN, Mesos et Spark Standalone allouent les ressources pour plusieurs applications simultanées.
Les applications Spark se composent d’un processus driver et d’un ensemble de processus exécuteurs. Le processus driver exécute votre fonction main(), tourne sur un nœud du cluster et prend en charge trois tâches : gérer les informations sur l’application Spark ; répondre au programme ou à l’entrée d’un utilisateur ; et analyser, distribuer et planifier le travail à travers les exécuteurs (définis momentanément). Le processus driver est absolument essentiel, il constitue le cœur d’une application Spark. Il maintient toutes les informations pertinentes pendant la durée de vie de l’application. Les exécuteurs sont chargés d’exécuter le travail que le driver leur confie. Cela signifie que chaque exécuteur est responsable de deux tâches uniquement : l’exécution du code qui lui est assigné par le driver et la communication de l’état du calcul, sur cet exécuteur, au nœud du driver.
Le guide pratique de l'IA agentique pour l'entreprise

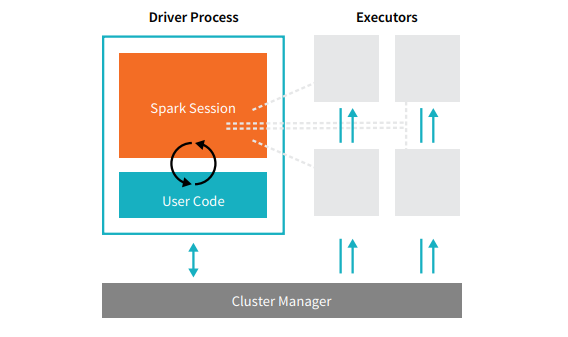
Le gestionnaire de clusters contrôle les machines physiques et alloue des ressources à l'application Spark. Il peut s’agir de l’un des principaux gestionnaires de clusters : Spark, YARN ou Mesos. Cela signifie que plusieurs applications Spark peuvent fonctionner en même temps sur un cluster. Nous parlerons plus en détail des gestionnaires de clusters dans la partie IV de ce livre intitulée « Applications de production ». Dans l’illustration ci-dessus, nous voyons à gauche notre driver et à droite les quatre exécuteurs. Nous n’y avons pas schématisé le concept de nœuds de clusters. L’utilisateur peut effectuer des configurations pour spécifier le nombre d’exécuteurs devant se trouver sur chaque nœud. [glossary-cta]
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.