Qu'est-ce qu'un ensemble de données distribuées résilientes (RDD) ?
Comprendre la structure de données fondamentale de Spark pour le traitement parallèle distribué et tolérant aux pannes
- Comprendre ce que sont les RDD et comment elles servent de collections de données immuables et partitionnées pour le traitement parallèle dans Apache Spark.
- Découvrir les cinq principaux cas d'utilisation des RDD, notamment pour les données non structurées et le contrôle des transformations de bas niveau.
- Explorer les liens entre les RDD, les DataFrames et les Datasets, et savoir quand utiliser chaque API.
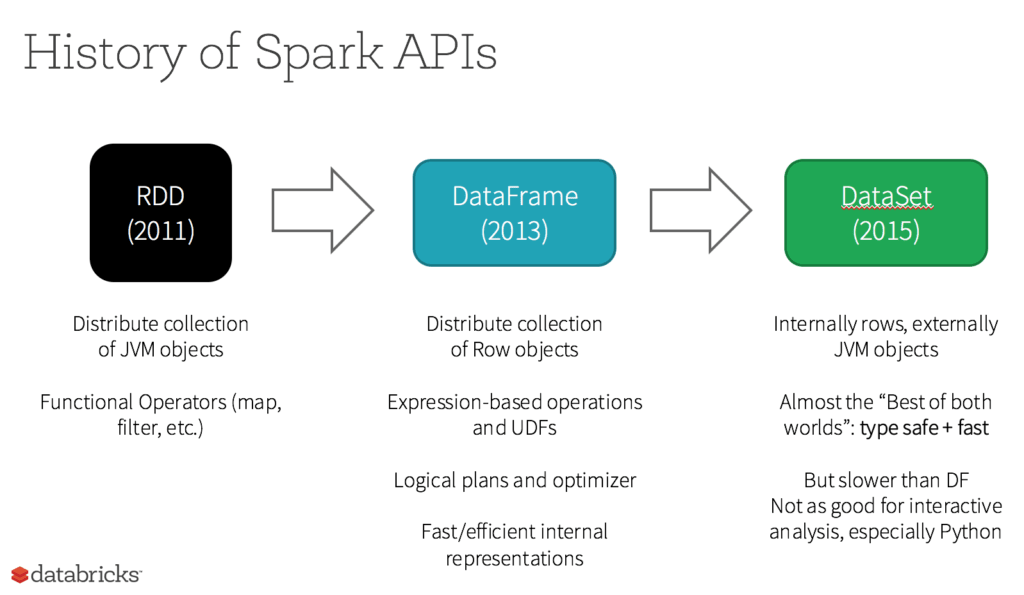
Le RDD était à l'origine la principale API côté utilisateur dans Spark.Fondamentalement, un RDD est une collection distribuée immuables d'éléments de données, répartis sur les nœuds de votre cluster, et que vous pouvez exploiter en parallèle à l'aide d'une API de bas niveau qui fournit des transformations et des actions.
5 raisons d'utiliser les RDD
- Vous voulez des outils de transformation et d'action de bas niveau ainsi que du contrôle sur votre dataset ;
- Vos données sont structurées (flux de médias ou de texte, par exemple) ;
- Vous voulez manipuler vos données à l'aide de modules programmatiques fonctionnels plutôt qu'avec des expressions spécifiques à un domaine ;
- Vous n'avez pas besoin d'imposer un schéma tel qu'un format colonnaire, lors du traitement ou de l'accès aux attributs de données par nom ou par colonne ; et
- Vous pouvez renoncer à certains avantages d'optimisation et de performance, disponibles avec les DataFrames et les Datasets pour les données structurées et semi-structurées.
Le guide pratique de l'IA agentique pour l'entreprise

Que deviennent les RDD dans Apache Spark 2.0 ?
Est-ce que les RDD (Resilient Distributed Datasets) sont devenus des composants de seconde classe ? Est-ce qu'ils sont obsolètes ? La réponse est claire : NON ! De plus, vous pouvez désormais naviguer en toute liberté entre DataFrames, Datasets et RDD à l'aide de simples appels de méthodes d'API. Par ailleurs, les DataFrames et Datasets sont bâtis à partir des RDD.
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.