Construire une ETL de production avec les pipelines déclaratifs Lakeflow
Conçue pour l’analytique moderne et l’IA, cette architecture fournit une base évolutive pour créer et automatiser des pipelines ETL sur des données en lots et en flux.
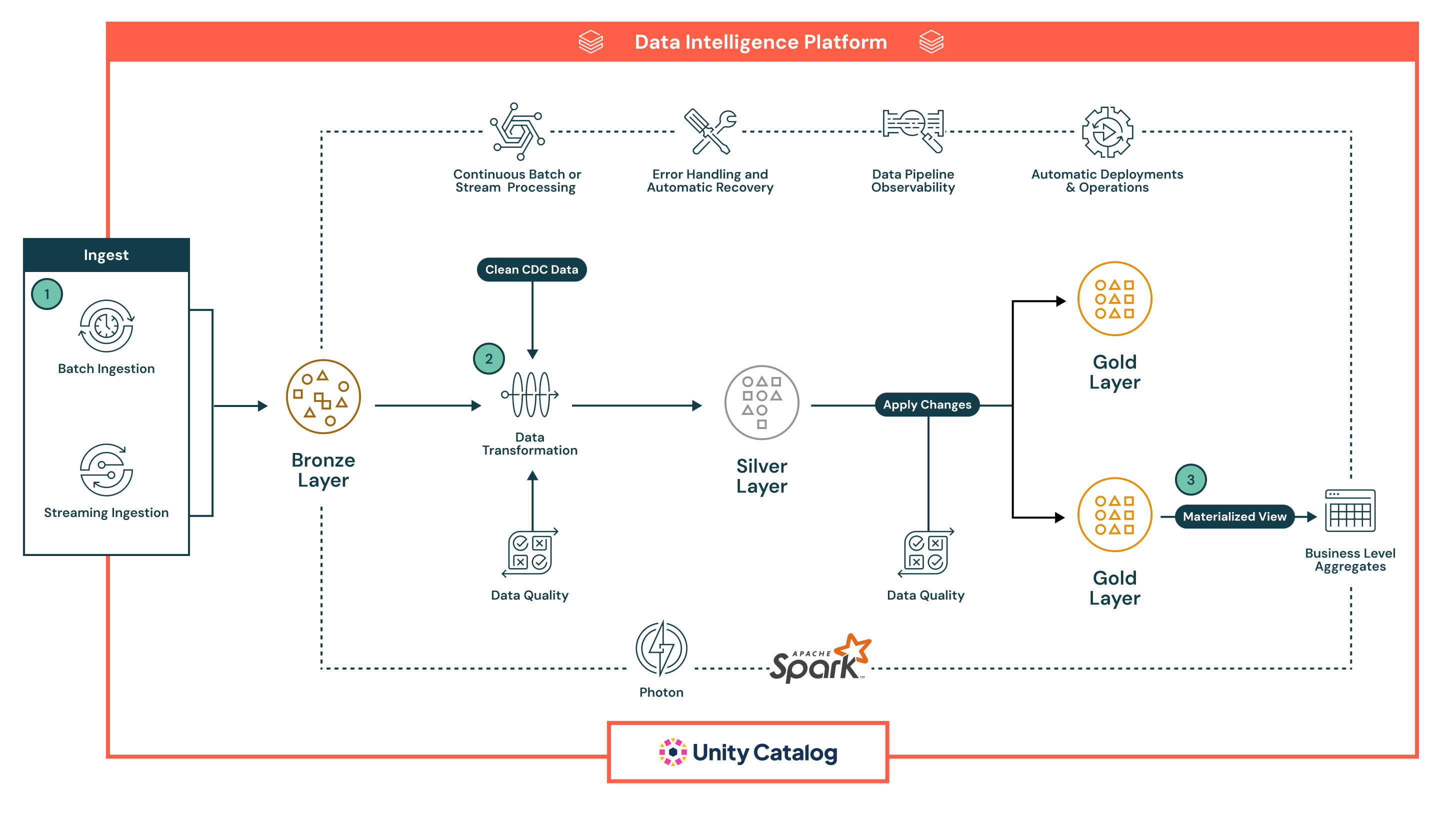
Résumé de l'architecture
Cette architecture de référence convient parfaitement aux organisations cherchant à unifier les pipelines de lots et de streaming sous un seul cadre déclaratif, tout en garantissant la fiabilité, la qualité et la gouvernance des données à chaque étape. Elle exploite la plateforme d'intelligence de données Databricks pour simplifier la gestion des pipelines, imposer des attentes de données et fournir des insights en temps réel avec une observabilité et une automatisation intégrées.
Elle prend en charge un large éventail de scénarios d'ingénierie et d'analyse de données, de l'ingestion et de la transformation des données à des flux de travail complexes avec des contrôles de qualité en temps réel, une logique métier et une récupération automatique. Les organisations qui adoptent cette architecture cherchent souvent à moderniser les ETL hérités, à réduire les frais d'exploitation et à accélérer la livraison de données organisées et de haute qualité pour l'intelligence d'affaires, l'apprentissage automatique et les applications opérationnelles.
Cas d’utilisation technique
- Cette architecture permet la création de pipelines de capture de modifications de données (CDC) qui appliquent de manière incrémentielle les mises à jour provenant des systèmes sources dans le lakehouse
- Les ingénieurs de données peuvent construire des modèles de dimensions à changement lent (SCD) pour gérer les modèles dimensionnels dans les couches d'analyse
- Des pipelines de streaming peuvent être construits de manière résiliente pour gérer les événements hors ordre et les données arrivant tardivement avec des filigranes et des points de contrôle
- Les ingénieurs de données peuvent imposer l'évolution du schéma et les règles de qualité automatisées en utilisant des contraintes déclaratives
- Les ingénieurs de données peuvent automatiser le suivi de la lignée des données et la journalisation des audits sur l'ensemble du pipeline sans instrumentation manuelle
Cas d'utilisation commerciaux
- Les entreprises de vente au détail et de biens de consommation emballés (CPG) peuvent utiliser cette architecture pour construire des tableaux de bord en temps réel qui suivent les ventes, les stocks et le comportement des clients à travers plusieurs canaux
- En intégrant les données provenant des transactions, des interactions numériques et des systèmes CRM, les institutions financières peuvent soutenir la détection de fraude et la segmentation des clients
- Les organisations de santé peuvent traiter et normaliser les données des dispositifs médicaux et les dossiers des patients pour des informations cliniques et des rapports de conformité
- Les fabricants peuvent combiner les données des capteurs IoT avec les journaux historiques pour conduire la maintenance prédictive et l'optimisation de la chaîne d'approvisionnement
- Les fournisseurs de télécommunications peuvent unifier les données de CRM et de télémétrie réseau pour modéliser le taux d'attrition des clients et les modèles d'utilisation en temps réel proche
Capacités clés
- Développement de pipelines déclaratifs : Définissez des pipelines en utilisant SQL ou Python, en abstrayant la logique d'orchestration
- Support de lots et de streaming : Gérer à la fois les charges de travail en temps réel et planifiées dans un cadre unifié
- Contrôle de la qualité des données : Appliquez des attentes directement dans le pipeline pour détecter, bloquer ou mettre en quarantaine les mauvaises données
- Observabilité et lignage : La surveillance intégrée, les alertes et le suivi visuel du lignage améliorent la transparence et le dépannage
- Gestion et récupération des erreurs : Détecter et récupérer automatiquement des échecs à n'importe quelle étape du pipeline
- Gouvernance avec le Catalogue Unity : Appliquez des contrôles d'accès à granularité fine, auditez l'utilisation des données et maintenez la classification des données à travers la pile
- Exécution optimisée : Exploitez Spark et Photon sous le capot pour un traitement à haute performance et évolutif
- Opérations automatisées : Les pipelines peuvent être versionnés, déployés et gérés à travers CI/CD, avec un support pour la planification et la paramétrisation
Flux de données
L'architecture suit une robuste architecture de médaille à plusieurs couches, améliorée par les capacités intégrées des pipelines déclaratifs de Lakeflow pour l'automatisation, la gouvernance et la fiabilité. Chaque phase du pipeline est déclarative, observable et optimisée pour les cas d'utilisation en lots et en flux continu :
- Les pipelines déclaratifs de Lakeflow supportent à la fois l'ingestion en lots et en flux continu, fournissant une manière unifiée et automatisée d'amener les données dans la lakehouse.
- L'ingestion par lots charge les données selon un calendrier ou un déclencheur, idéal pour les workflows ETL périodiques. Il prend en charge les charges complètes et incrémentielles à partir du stockage en nuage et des bases de données. Contrairement aux outils traditionnels, le déclaratif gère nativement l'orchestration, les nouvelles tentatives et l'évolution du schéma, réduisant ainsi le besoin de planificateurs externes ou de scripts.
- L'ingestion en flux continu traite continuellement les données provenant de sources comme Kafka et Event Hubs en utilisant Structured Streaming. Les pipelines déclaratifs gèrent le point de contrôle, la gestion de l'état et l'auto-échelle de manière automatique, éliminant la configuration manuelle généralement requise dans les pipelines de streaming.
Toutes les données atterrissent d'abord dans la couche Bronze sous forme brute, permettant une traçabilité complète, une traçabilité et une retraitement sûr. L'approche déclarative des pipelines, les contrôles de qualité intégrés et la gestion automatique de l'infrastructure réduisent considérablement la complexité opérationnelle et facilitent la construction de pipelines résilients et de qualité de production — quelque chose que la plupart des outils ETL hérités ont du mal à fournir nativement.
- Après l'ingestion, les données peuvent être traitées dans la couche Silver, où elles sont nettoyées, jointes et enrichies pour préparer la consommation en aval.
- Les pipelines sont définis en utilisant SQL déclaratif ou Python, rendant les transformations faciles à lire, à maintenir et à versionner. Les transformations sont exécutées en utilisant Apache Spark™ avec Photon, offrant un traitement évolutif et haute performance.
- Les contrôles de qualité des données sont appliqués en ligne en utilisant les attentes, une fonctionnalité native des pipelines déclaratifs qui permet aux équipes d'appliquer des règles de validation (par exemple, vérifications de null, types de données, limites de plage). Les données invalides peuvent être configurées pour soit supprimer les mauvais enregistrements, les mettre en quarantaine ou échouer le pipeline - garantissant que les systèmes en aval ne reçoivent que des données fiables.
- Le pipeline gère automatiquement le suivi des dépendances de travail, les tentatives de tâches et l'isolement des erreurs, réduisant la charge opérationnelle. Cela garantit que les données traitées dans la couche Silver sont précises, cohérentes et prêtes pour la production - tout en maintenant la simplicité opérationnelle.
- Dans la couche Gold, le pipeline génère des agrégats au niveau de l'entreprise et des ensembles de données organisés prêts à être consommés.
- Ces sorties sont optimisées pour être utilisées dans les tableaux de bord BI, les fonctionnalités d'apprentissage automatique et les systèmes opérationnels.
- Les pipelines déclaratifs prennent en charge les tables temporelles et la logique SCD, permettant des cas d'utilisation avancés tels que le suivi historique et les rapports d'audit.
- Tout au long de toutes les couches, les Pipelines Déclaratifs fournissent une observabilité riche et une lignée de pipeline.
- L'interface utilisateur affiche des graphiques de flux de données, des métriques opérationnelles et des tableaux de bord de qualité pour soutenir un dépannage rapide et un reporting de conformité
- Avec l'intégration du catalogue Unity, chaque table, colonne et transformation est gouvernée par un contrôle d'accès centralisé, un journal d'audit et une classification des données
- Les pipelines sont prêts pour la production par conception.
- Les équipes peuvent déployer des pipelines déclaratifs en utilisant des définitions contrôlées par version, les planifier via Lakeflow Jobs et les gérer à travers des outils CI/CD comme GitHub Actions ou Azure DevOps
- Cette automatisation remplace les scripts fragiles et les configurations d'orchestration complexes, aidant les équipes de données à se concentrer sur la logique métier plutôt que sur l'infrastructure
Recommandations

Vidéo à la demande

Vidéo à la demande
Visite guidée

Architecture par Secteur d'activité
