Architecture de Référence pour l'Ingestion de Données
Cette architecture de référence pour l'ingestion de données fournit une base simplifiée, unifiée et efficace pour charger des données provenant de diverses sources d'entreprise dans la Plateforme d'Intelligence de Données Databricks.
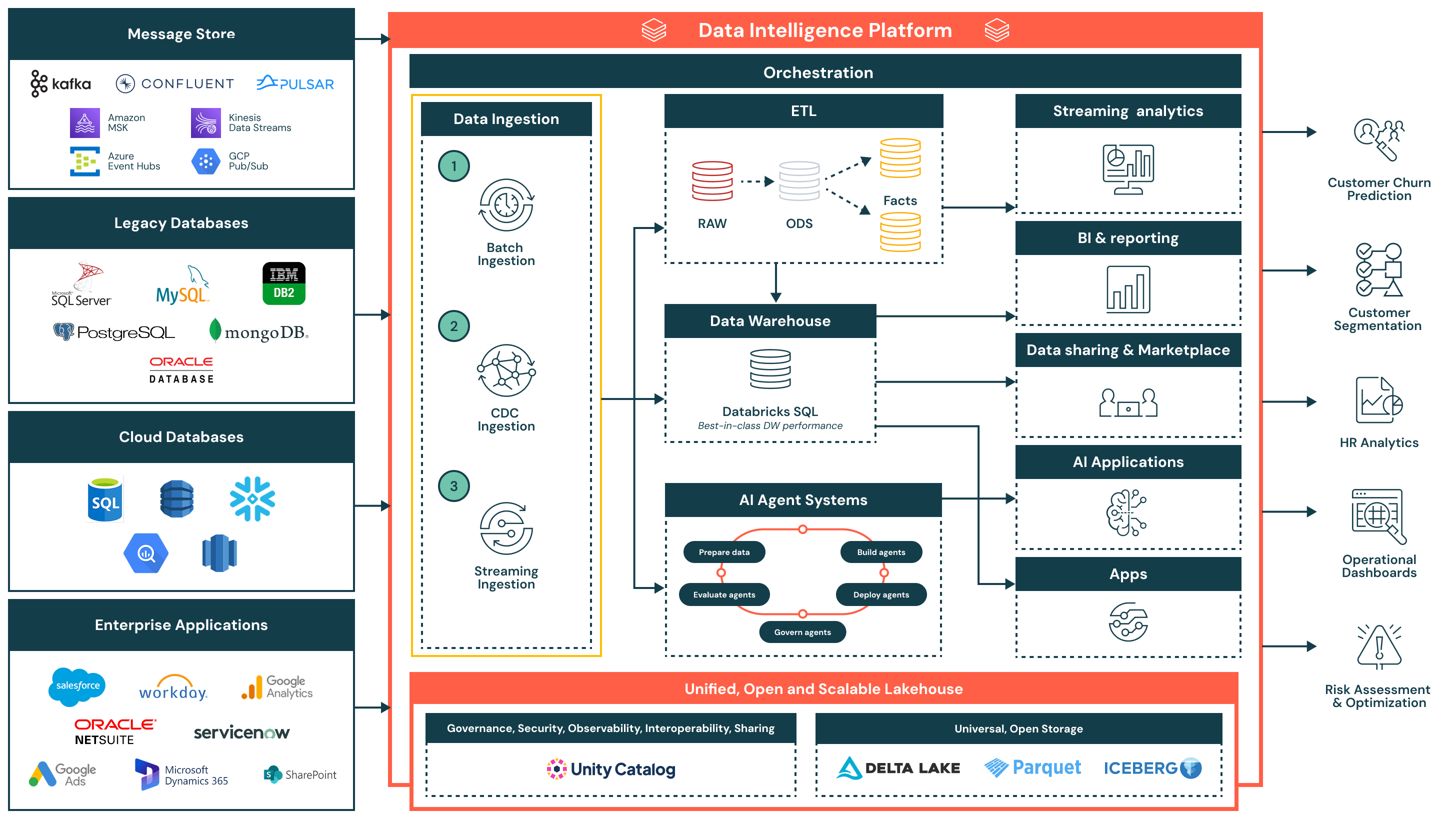
Résumé de l'architecture
L'architecture de référence pour l'ingestion de données prend en charge une large gamme de modèles d'ingestion - y compris par lots, la capture de données modifiées (CDC) et le streaming - tout en garantissant la gouvernance, la performance et l'interopérabilité. Une fois ingérées, les données sont affinées et mises à disposition pour l'analytique, l'IA et le partage sécurisé des données à travers l'organisation.
Cette architecture est idéale pour les organisations cherchant à moderniser et opérationnaliser les pipelines de données tout en réduisant la complexité et la surcharge d'intégration. Elle est construite autour de trois principes clés :
- Simple et nécessitant peu d'entretien : Les pipelines d'ingestion sont faciles à construire et à gérer, permettant un temps de valeur plus rapide, moins de goulots d'étranglement opérationnels et un accès plus large aux données à travers les équipes
- Unifié avec l'architecture du lac de données : Les données sont directement acheminées vers le lac de données en utilisant des formats ouverts et sont régies par le Catalogue Unity - garantissant la cohérence à travers les cas d'utilisation de la BI, de l'IA et des opérations
- Flux efficace de bout en bout : De l'ingestion à la transformation et à la livraison, la plateforme prend en charge un traitement efficace et incrémental qui minimise la duplication, la latence et l'utilisation des ressources
Cas d’utilisation
Cas d’utilisation technique
- Ingestion périodique par lots à partir de fichiers plats, d'exports ou d'APIs vers des zones de préparation
- Capture de données modifiées (CDC) ingestion pour synchroniser de manière incrémentielle les mises à jour provenant de systèmes transactionnels tels qu'Oracle ou PostgreSQL
- Ingestion en streaming des événements en temps réel à partir de Kafka ou des files d'attente de messages pour une utilisation dans des tableaux de bord en direct ou des systèmes d'alerte
- Harmonisation de l'ingestion à travers les systèmes hérités, les bases de données natives du cloud et les applications SaaS d'entreprise
- Alimentation des données organisées et transformées dans les entrepôts de données, les applications d'IA et les API externes
Cas d'utilisation commerciaux
- Prédiction de la résiliation des clients en ingérant des données comportementales, transactionnelles et de support
- Alimentation des tableaux de bord exécutifs avec des métriques opérationnelles fraîches provenant des systèmes ERP et CRM
- Segmenter les clients en combinant les données de campagne, de ventes et d'utilisation du produit
- Réalisation d'analyses RH en intégrant des données provenant de Workday et de plateformes de productivité
- Réalisation d'une évaluation des risques en analysant les transactions et les flux d'alertes en temps quasi réel
Flux d'ingestion de données et capacités clés
- Ingestion par lots
- Charge les données à des intervalles programmés ou à la demande à partir de sources telles que des fichiers plats, des API ou des exports de bases de données
- Convient pour les rapports quotidiens, les chargements de données historiques et les instantanés de système d'enregistrement
- Supporte à la fois les charges complètes et incrémentielles, avec une planification native, une logique de réessai et une transformation utilisant SQL ou Python
- Ingestion de la capture de données modifiées (CDC)
- Capture les modifications incrémentielles provenant de systèmes transactionnels tels qu'Oracle, PostgreSQL et MySQL
- Maintient les tables du lakehouse à jour sans rechargements complets, améliorant l'efficacité et la fraîcheur des données
- Permet une synchronisation des données en temps quasi réel pour les tables de faits, les pistes d'audit et les couches de reporting
- Ingestion en continu
- Traite en continu les données provenant de sources d'événements comme Kafka, Kinesis, Pub/Sub ou Event Hubs
- Idéal pour les tableaux de bord en temps réel, les systèmes d'alerte et la détection d'anomalies
- Le Streaming Structuré gère l'état, la tolérance aux pannes et le débit, réduisant la charge opérationnelle
Capacités supplémentaires de la plateforme
- Gouvernance unifiée
- Catalogue Unity fournit une gouvernance unifiée, incluant le contrôle d'accès, la lignée et le suivi d'audit
- Les données sont stockées dans des formats ouverts et interopérables en utilisant Delta Lake et Apache Iceberg™, garantissant la flexibilité et l'interopérabilité à travers les outils et les environnements
- Une couche d'orchestration centralisée gère la planification des pipelines, les dépendances, la surveillance et la récupération
- Architecture du lac de données : Les données ingérées sont transformées et modélisées dans l'architecture de médailles (Bronze, Argent et Or), permettant des requêtes à haute performance dans Databricks SQL
- Orchestration : L'orchestration intégrée gère les pipelines de données, les flux de travail d'IA et les tâches planifiées à travers les charges de travail par lots et en streaming, avec un support natif pour la gestion des dépendances et la gestion des erreurs
- IA et systèmes d'agents : Les données alimentent les systèmes d'agents pour la préparation des caractéristiques, l'évaluation des modèles et le déploiement d'applications alimentées par l'IA
- Consommation en aval :
- Analytique en streaming : Visualisation en temps réel des indicateurs clés et des signaux opérationnels
- BI/analytique : Ensembles de données organisées servis à des outils tels que Power BI, Lakeview et les clients SQL
- Applications IA : Ensembles de données réglementés consommés par les pipelines d'entraînement et les moteurs d'inférence
- Partage de données et marketplace : Partage de données interne et externe sécurisé via Delta Sharing
- Applications opérationnelles : Intelligence intégrée et insights contextuels dans les outils d'entreprise
Recommandations

Architecture de référence

Architecture de référence

Architecture sectorielle

Architecture sectorielle
Architecture de référence