Applicazione della tua Rete Neurale Convoluzionale: webinar on-demand e FAQ ora disponibili!
Prova questo notebook in Databricks
Il 25 ottobre abbiamo ospitato un webinar dal vivo —Applicazione della tua rete neurale convoluzionale— con Denny Lee, Technical Product Marketing Manager presso Databricks. Questo è il terzo webinar di una serie gratuita sui fondamenti del deep learning di Databricks.

In questo webinar, abbiamo approfondito le Reti Neurali Convoluzionali (CNN), un particolare tipo di reti neurali che presuppongono che gli input siano immagini e che si sono dimostrate molto efficaci per la classificazione delle immagini e il riconoscimento di oggetti.
In particolare, abbiamo parlato di:
- Architettura CNN, con nodi disposti in 3D (larghezza, altezza e profondità) che consente di applicare filtri convoluzionali per estrarre le feature.
- Come funzionano i kernel convoluzionali (filtri), compresa la scelta delle dimensioni dei filtri, dello stride e del padding per estrarre le feature da regioni di pixel nelle immagini di input.
- Tecniche di pooling, o sottocampionamento, per ridurre le dimensioni dell'immagine in modo da ridurre il numero di parametri e quindi il rischio di overfitting.
Abbiamo illustrato alcuni di questi concetti utilizzando Keras (backend TensorFlow) su Databricks, ed ecco il link al nostro Notebook per iniziare oggi:
Puoi ancora guardare la Parte 1 e la Parte 2 qui sotto:


Se desideri l'accesso gratuito alla Databricks Piattaforma di analisi unificata e provare i nostri Notebooks, puoi accedere a una prova gratuita qui.
Verso la fine, si è tenuta una sessione di Q&A, e di seguito sono riportate le domande e le relative risposte, raggruppate per argomenti.
Fondamenti
D: Devo davvero capire la matematica alla base delle reti neurali per poterle usare?
Sebbene non sia assolutamente necessario comprendere la matematica alla base delle reti neurali per utilizzarle, è importante capire questi fondamenti per scegliere gli algoritmi giusti e per sapere come ottimizzare, migliorare e progettare i propri modelli di deep learning (e machine learning). Un buon articolo su questo argomento è The Mathematics of Machine Learning di Wale Akinfaderin.
Rete neurale convoluzionale
D: Perché usare le CNN invece delle reti neurali tradizionali? E come si usano le CNN nel mondo reale? Puoi condividere qualche esempio di applicazione?
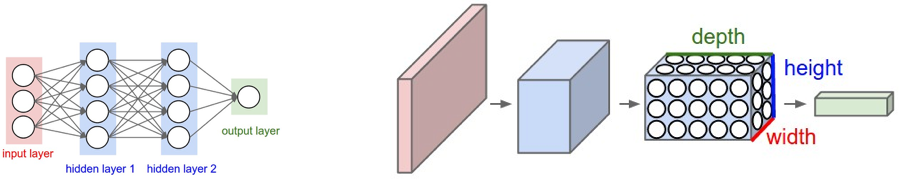
Fonte: https://cs231n.github.io/convolutional-networks/
Come discusso più approfonditamente in Addestramento delle reti neurali, le reti neurali convoluzionali (CNN) sono simili alle normali reti neurali artificiali, ma le prime assumono esplicitamente che l'input sia costituito da immagini. Il problema è che le reti neurali artificiali completamente connesse (come visualizzato nel grafico a sinistra) non scalano bene con le immagini. Ad esempio, 200 pixel x 200 pixel x 3 canali di colore (ad es. RGB) comporterebbe 120.000 pesi. Più l'immagine è grande o complessa (in termini di canali), più pesi saranno richiesti. Nel caso delle CNN, i nodi sono connessi solo a una piccola regione del livello precedente organizzata in 3D (larghezza, altezza, profondità). Dato che i nodi non sono completamente connessi, questo riduce il numero di pesi (cioè cardinalità) consentendo così alla rete di completare i suoi passaggi più rapidamente.
D: Una CNN è una rete di layer, dimensioni e tipo. Come li scelgo? In base a cosa? In altre parole, come progetto la mia architettura?
Come indicato in Introduzione alle reti neurali: webinar on-demand e domande frequenti ora disponibili, sebbene esistano delle regole empiriche generali sul tuo punto di partenza (ad es. start con un layer nascosto ed espandere di conseguenza, il numero di nodi di input è uguale alla dimensione delle feature, ecc.), la cosa fondamentale è che dovrai testare. Cioè, addestra il tuo modello e poi esegui i test e/o le convalide su quel modello per comprenderne l'accuratezza (più è alta, meglio è) e la perdita (più è bassa, meglio è). Per quanto riguarda la progettazione della tua architettura, è meglio iniziare con le architetture meglio comprese e studiate (ad es. AlexNet, LeNet-5, Inception, VGG, ResNet, ecc.). Da qui, puoi regolare il numero, la dimensione e il tipo di layer mentre esegui i tuoi esperimenti.
D: Perché usare la funzione softmax per il livello completamente connesso?
Quando si lavora con la regressione logistica, questa presume una distribuzione di Bernoulli per la classificazione binaria. Quando è necessario applicare a più di due classificatori (come nel nostro problema di classificazione MNIST), serve la generalizzazione della distribuzione di Bernoulli, ovvero la distribuzione multinomiale. Il tipo di regressione che si applica a una distribuzione multinomiale (multi-classificatore) è noto come regressione softmax. Per MNIST, classifichiamo cifre scritte a mano per un valore compreso tra 0, ..., 9 nel livello completamente connesso, da cui l'uso della softmax.
D: La dimensione del filtro è sempre un numero dispari?
Un approccio comune per la dimensione del filtro è f x f dove f è un numero dispari. Anche se non viene esplicitamente indicato, nella diapositiva 39 di Applying Rete neurale, f è un numero dispari perché l'obiettivo è eseguire la convoluzione del pixel di origine e dei pixel circostanti. Il minimo indispensabile sarebbe una dimensione del filtro di 3 x 3, poiché corrisponderebbe al pixel di origine + 1 pixel verso l'esterno nello spazio 2D.

Avere una dimensione f pari comporterebbe la convoluzione di meno della metà dei pixel attorno al pixel di origine. Per approfondire, un'ottima risposta su SO a questa domanda è disponibile all'indirizzo https://datascience.stackexchange.com/questions/23183/why-convolutions-always-use-odd-numbers-as-filter-size/23186.
D: Come posso implementare una CNN con una lunghezza di input variabile? Cioè, qualche suggerimento per i dati di addestramento che hanno immagini di dimensioni variabili?
In generale, è necessario ridimensionare le immagini o eseguire lo zero-padding in modo che tutte le immagini di input per la CNN abbiano la stessa dimensione. Esistono alcuni approcci che coinvolgono LSTM, RNN o reti neurali ricorsive (specialmente per i dati di testo) in grado di gestire input di dimensioni variabili, anche se si tratta spesso di un compito non banale.
Ambiente e Risorse ML
D: Sono un utente Databricks a pagamento. So come eseguire Keras sul mio PC, ma non ancora in Databricks.
Quando si utilizza Databricks, avviare un cluster Databricks Runtime for Machine Learning che include, tra gli altri, Keras, TensorFlow, XGBoost, Horovod e scikit-learn. Per maggiori informazioni, consulta Announcing Databricks Runtime for Machine Learning.
D: Abbiamo avuto una sessione simile per il ML?
Sono disponibili numerosi ottimi webinar di Databricks; quelli incentrati sul machine learning includono (ma non si limitano a):
- Presentazione di MLflow: infrastruttura per un ciclo di vita completo del machine learning
- Parallelizzare il codice R utilizzando Apache® Spark
- Produzionizzazione dei modelli MLlib di Apache Spark™ per l'erogazione di predizioni in tempo reale
- In che modo Databricks e il machine learning guidano il futuro della genomica
- GraphFrames: grafi basati su DataFrame per Apache® Spark™
- Apache® Spark™ MLlib: da Quick Start a Scikit-Learn
Risorse
- Machine Learning 101
- Demo ConvNetJS MNIST di Andrej Karparthy
- Cos'è la retropropagazione nelle reti neurali?
- CS231n: Reti Neurali Convoluzionali per il Riconoscimento Visivo
- Con particolare attenzione a CS231n: Lezione 7 - Reti neurali convoluzionali
- Reti neurali e deep learning
- tensorflow
- Deep Visualization Toolbox
- Retropropagazione con TensorFlow
- TensorFrames: Google TensorFlow con Apache Spark
- Integrazione delle librerie di deep learning con Apache Spark
- Crea, scala e distribuisci pipeline di deep learning con facilità
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.