Previsioni di serie temporali a grana fine su larga scala con Facebook Prophet e Apache Spark
Prova questo notebook di previsione delle serie temporali nel nostro Solution Accelerator per la Previsione della Domanda.
I progressi nella previsione delle serie temporali consentono ai rivenditori di generare previsioni della domanda più affidabili. La sfida ora è produrre queste previsioni in modo tempestivo e a un livello di granularità che consenta all'azienda di apportare aggiustamenti precisi alle scorte di prodotti. Sfruttando Apache Spark™ e Facebook Prophet, sempre più aziende che affrontano queste sfide scoprono di poter superare i limiti di scalabilità e accuratezza delle soluzioni passate.
In questo post, discuteremo l'importanza della previsione delle serie temporali, visualizzeremo alcuni dati di esempio di serie temporali, quindi costruiremo un modello semplice per mostrare l'uso di Facebook Prophet. Una volta che ti sentirai a tuo agio nel costruire un singolo modello, combineremo Prophet con la potenza di Apache Spark™ per mostrarti come addestrare centinaia di modelli contemporaneamente, permettendoci di creare previsioni precise per ogni singola combinazione prodotto-negozio a un livello di granularità raramente raggiunto fino ad ora.
Previsioni accurate e tempestive sono ora più importanti che mai
Migliorare la velocità e l'accuratezza delle analisi delle serie temporali al fine di prevedere meglio la domanda di prodotti e servizi è fondamentale per il successo dei rivenditori. Se troppo prodotto viene immesso in un negozio, lo spazio sugli scaffali e nei magazzini può essere limitato, i prodotti possono scadere e i rivenditori potrebbero ritrovarsi con le risorse finanziarie bloccate nell'inventario, impedendo loro di sfruttare nuove opportunità generate dai produttori o dai cambiamenti nei modelli di consumo. Se viene immesso troppo poco prodotto in un negozio, i clienti potrebbero non essere in grado di acquistare i prodotti di cui hanno bisogno. Questi errori di previsione non solo comportano una perdita immediata di entrate per il rivenditore, ma nel tempo la frustrazione dei consumatori può spingere i clienti verso i concorrenti.
Le nuove aspettative richiedono metodi e modelli di previsione delle serie temporali più precisi
Per qualche tempo, i sistemi di pianificazione delle risorse d'impresa (ERP) e le soluzioni di terze parti hanno fornito ai rivenditori funzionalità di previsione della domanda basate su semplici modelli di serie temporali. Ma con i progressi tecnologici e la crescente pressione nel settore, molti rivenditori stanno cercando di andare oltre i modelli lineari e gli algoritmi più tradizionali storicamente disponibili per loro.
Nuove funzionalità, come quelle fornite da Facebook Prophet, stanno emergendo dalla comunità di data science e le aziende cercano la flessibilità di applicare questi modelli di machine learning alle loro esigenze di previsione delle serie temporali.
![]()
Questo allontanamento dalle soluzioni di previsione tradizionali richiede ai rivenditori e simili di sviluppare competenze interne non solo nelle complessità della previsione della domanda, ma anche nella distribuzione efficiente del lavoro necessario per generare centinaia di migliaia o addirittura milioni di modelli di machine learning in modo tempestivo. Fortunatamente, possiamo usare Spark per distribuire l'addestramento di questi modelli, rendendo possibile prevedere non solo la domanda complessiva di prodotti e servizi, ma la domanda unica per ogni prodotto in ogni località.
Visualizzazione della stagionalità della domanda nei dati delle serie temporali
Per dimostrare l'uso di Prophet per generare previsioni della domanda a grana fine per singoli negozi e prodotti, utilizzeremo un set di dati pubblicamente disponibile da Kaggle. Consiste in 5 anni di dati di vendita giornalieri per 50 articoli individuali in 10 negozi diversi.
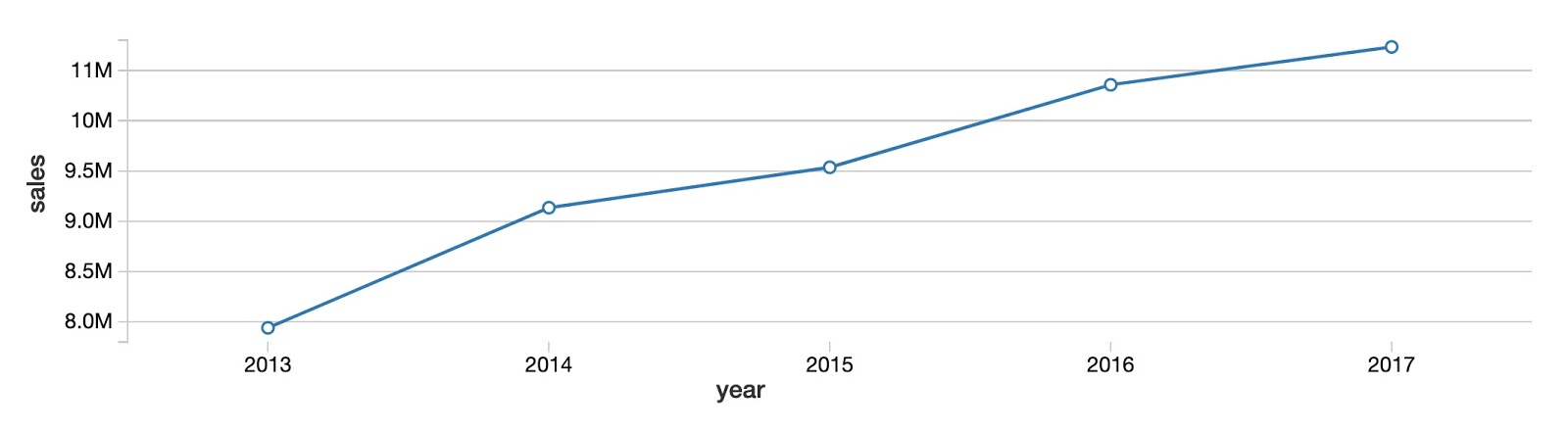
Per iniziare, diamo un'occhiata all'andamento generale delle vendite annuali per tutti i prodotti e negozi. Come puoi vedere, le vendite totali di prodotti stanno aumentando di anno in anno senza chiari segni di convergenza attorno a un plateau.
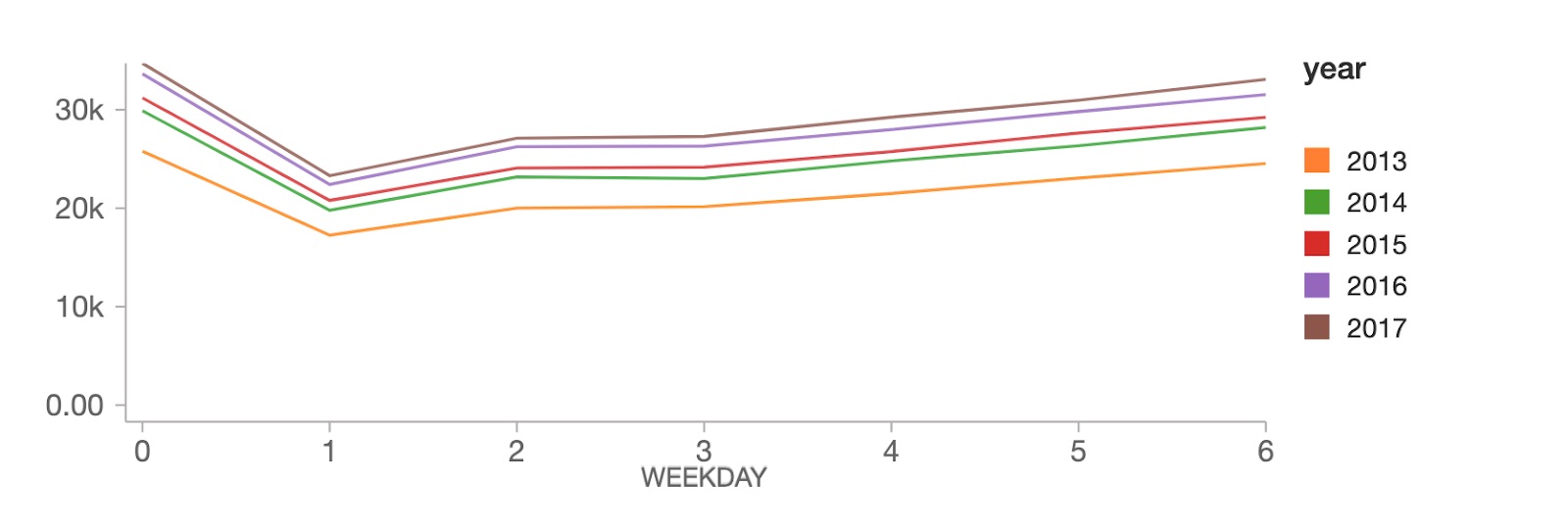
A livello di giorni della settimana, le vendite raggiungono il picco la domenica (giorno della settimana 0), seguite da un forte calo il lunedì (giorno della settimana 1), per poi recuperare costantemente durante il resto della settimana.
Iniziare con un semplice modello di previsione delle serie temporali su Facebook Prophet
Come illustrato nei grafici precedenti, i nostri dati mostrano un chiaro andamento ascendente anno su anno delle vendite, insieme a modelli stagionali sia annuali che settimanali. Sono questi schemi sovrapposti nei dati che Prophet è progettato per affrontare.
Facebook Prophet segue l'API di scikit-learn, quindi dovrebbe essere facile da apprendere per chiunque abbia esperienza con sklearn. Dobbiamo passare un pandas DataFrame a 2 colonne come input: la prima colonna è la data e la seconda è il valore da prevedere (nel nostro caso, le vendite). Una volta che i nostri dati sono nel formato corretto, costruire un modello è facile:
Ora che abbiamo adattato il nostro modello ai dati, usiamolo per costruire una previsione a 90 giorni. Nel codice seguente, definiamo un set di dati che include sia le date storiche che 90 giorni successivi, utilizzando il metodo make_future_dataframe di Prophet:
Questo è tutto! Ora possiamo visualizzare come i nostri dati effettivi e previsti si allineano, nonché una previsione per il futuro utilizzando il metodo .plot integrato di Prophet. Come puoi vedere, i modelli di domanda settimanali e stagionali che abbiamo illustrato in precedenza si riflettono effettivamente nei risultati previsti.
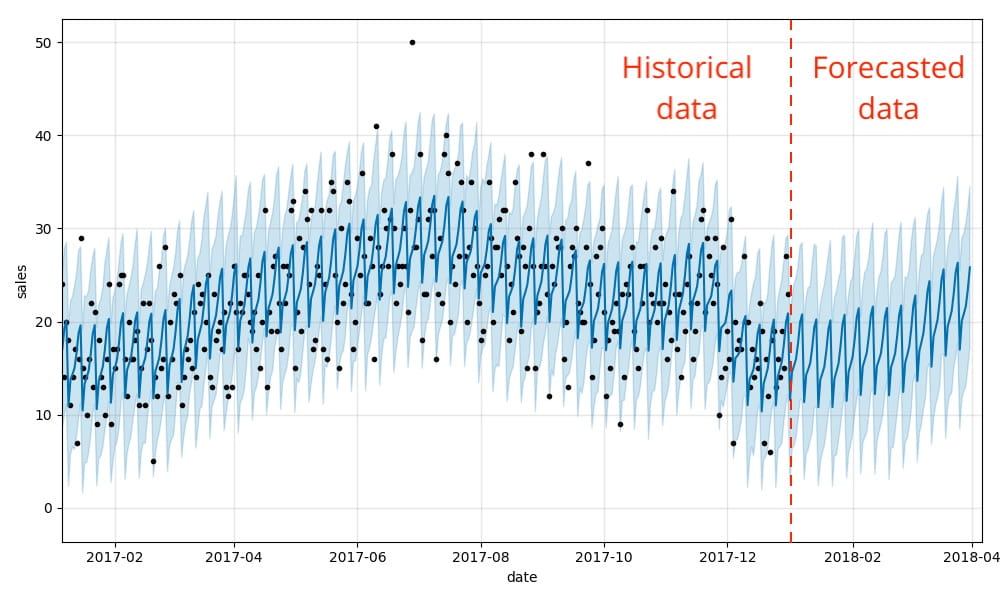
Questa visualizzazione è un po' affollata. Bartosz Mikulski fornisce un'eccellente spiegazione che vale la pena consultare. In poche parole, i punti neri rappresentano i nostri dati effettivi, la linea blu più scura rappresenta le nostre previsioni e la banda blu più chiara rappresenta il nostro intervallo di incertezza (95%).
Addestramento di centinaia di modelli di previsione delle serie temporali in parallelo con Prophet e Spark
Ora che abbiamo dimostrato come costruire un singolo modello di previsione delle serie temporali, possiamo utilizzare la potenza di Apache Spark per moltiplicare i nostri sforzi. Il nostro obiettivo è generare non una previsione per l'intero set di dati, ma centinaia di modelli e previsioni per ogni combinazione prodotto-negozio, qualcosa che richiederebbe un tempo incredibilmente lungo per essere eseguito come operazione sequenziale.
La costruzione di modelli in questo modo potrebbe consentire a una catena di supermercati, ad esempio, di creare una previsione precisa per la quantità di latte da ordinare per il loro negozio di Sandusky che differisce dalla quantità necessaria nel loro negozio di Cleveland, in base alla domanda diversa in quelle località.
Come utilizzare Spark DataFrames per distribuire l'elaborazione dei dati delle serie temporali
Gli scienziati dei dati affrontano frequentemente la sfida di addestrare un gran numero di modelli utilizzando un motore di elaborazione dati distribuito come Apache Spark. Sfruttando un cluster Spark, i singoli nodi worker nel cluster possono addestrare un sottoinsieme di modelli in parallelo con altri nodi worker, riducendo notevolmente il tempo complessivo necessario per addestrare l'intera raccolta di modelli di serie temporali.
Naturalmente, l'addestramento di modelli su un cluster di nodi worker (computer) richiede più infrastruttura cloud, e questo ha un costo. Ma con la facile disponibilità di risorse cloud on-demand, le aziende possono rapidamente fornire le risorse di cui hanno bisogno, addestrare i loro modelli e rilasciare tali risorse altrettanto rapidamente, consentendo loro di ottenere una scalabilità massiccia senza impegni a lungo termine verso asset fisici.
Il meccanismo chiave per ottenere l'elaborazione dati distribuita in Spark è il DataFrame. Caricando i dati in uno Spark DataFrame, i dati vengono distribuiti tra i worker nel cluster. Ciò consente a questi worker di elaborare sottoinsiemi dei dati in modo parallelo, riducendo la quantità complessiva di tempo necessaria per svolgere il nostro lavoro.
Naturalmente, ogni worker deve avere accesso al sottoinsieme di dati di cui ha bisogno per svolgere il proprio lavoro. Raggruppando i dati in base a valori chiave, in questo caso su combinazioni di negozio e articolo, riuniamo tutti i dati delle serie temporali per tali valori chiave su un nodo worker specifico.
Condividiamo il codice groupBy qui per sottolineare come ci consente di addestrare molti modelli in parallelo in modo efficiente, anche se non entrerà in gioco fino a quando non imposteremo e applicheremo una UDF ai nostri dati nella sezione successiva.
Sfruttare la potenza delle funzioni definite dall'utente pandas (UDF)
Con i nostri dati di serie temporali correttamente raggruppati per negozio e articolo, ora dobbiamo addestrare un singolo modello per ciascun gruppo. Per raggiungere questo obiettivo, possiamo utilizzare una funzione definita dall'utente pandas (UDF), che ci consente di applicare una funzione personalizzata a ciascun gruppo di dati nel nostro DataFrame.
Questa UDF non solo addestrerà un modello per ciascun gruppo, ma genererà anche un set di risultati che rappresenta le previsioni di quel modello. Ma mentre la funzione addestrerà e prevederà su ciascun gruppo nel DataFrame indipendentemente dagli altri, i risultati restituiti da ciascun gruppo verranno comodamente raccolti in un unico DataFrame risultante. Ciò ci consentirà di generare previsioni a livello di negozio-articolo ma di presentare i nostri risultati ad analisti e manager come un unico set di dati di output.
Come puoi vedere nel codice Python abbreviato di seguito, la creazione della nostra UDF è relativamente semplice. La UDF viene istanziata con il metodo pandas_udf che identifica lo schema dei dati che restituirà e il tipo di dati che si aspetta di ricevere. Subito dopo, definiamo la funzione che eseguirà il lavoro della UDF.
All'interno della definizione della funzione, istanziamo il nostro modello, lo configuriamo e lo adattiamo ai dati che ha ricevuto. Il modello effettua una previsione e tali dati vengono restituiti come output della funzione.
Ora, per mettere tutto insieme, utilizziamo il comando groupBy di cui abbiamo discusso in precedenza per garantire che il nostro set di dati sia correttamente partizionato in gruppi che rappresentano combinazioni specifiche di negozio e articolo. Quindi applichiamo semplicemente la UDF al nostro DataFrame, consentendo alla UDF di adattare un modello ed effettuare previsioni su ciascun raggruppamento di dati.
Il set di dati restituito dall'applicazione della funzione a ciascun gruppo viene aggiornato per riflettere la data in cui abbiamo generato le nostre previsioni. Ciò ci aiuterà a tenere traccia dei dati generati durante diverse esecuzioni del modello man mano che alla fine porteremo la nostra funzionalità in produzione.
Prossimi passi
Abbiamo ora costruito un modello di previsione delle serie temporali per ogni combinazione negozio-articolo. Utilizzando una query SQL, gli analisti possono visualizzare le previsioni personalizzate per ciascun prodotto. Nel grafico seguente, abbiamo rappresentato la domanda prevista per il prodotto n. 1 in 10 negozi. Come puoi vedere, le previsioni della domanda variano da negozio a negozio, ma il modello generale è coerente in tutti i negozi, come ci aspetteremmo.
Man mano che arrivano nuovi dati di vendita, possiamo generare in modo efficiente nuove previsioni e aggiungerle alle nostre strutture di tabella esistenti, consentendo agli analisti di aggiornare le aspettative dell'azienda man mano che le condizioni evolvono.
Per saperne di più, guarda il webinar on-demand intitolato Come Starbucks prevede la domanda su larga scala con Facebook Prophet e Azure Databricks e dai un'occhiata al nostro Solution Accelerator per la Previsione della Domanda.

(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.