Databricks Notebook
Esperienza dello sviluppatore unificata per realizzare progetti di dati e AI


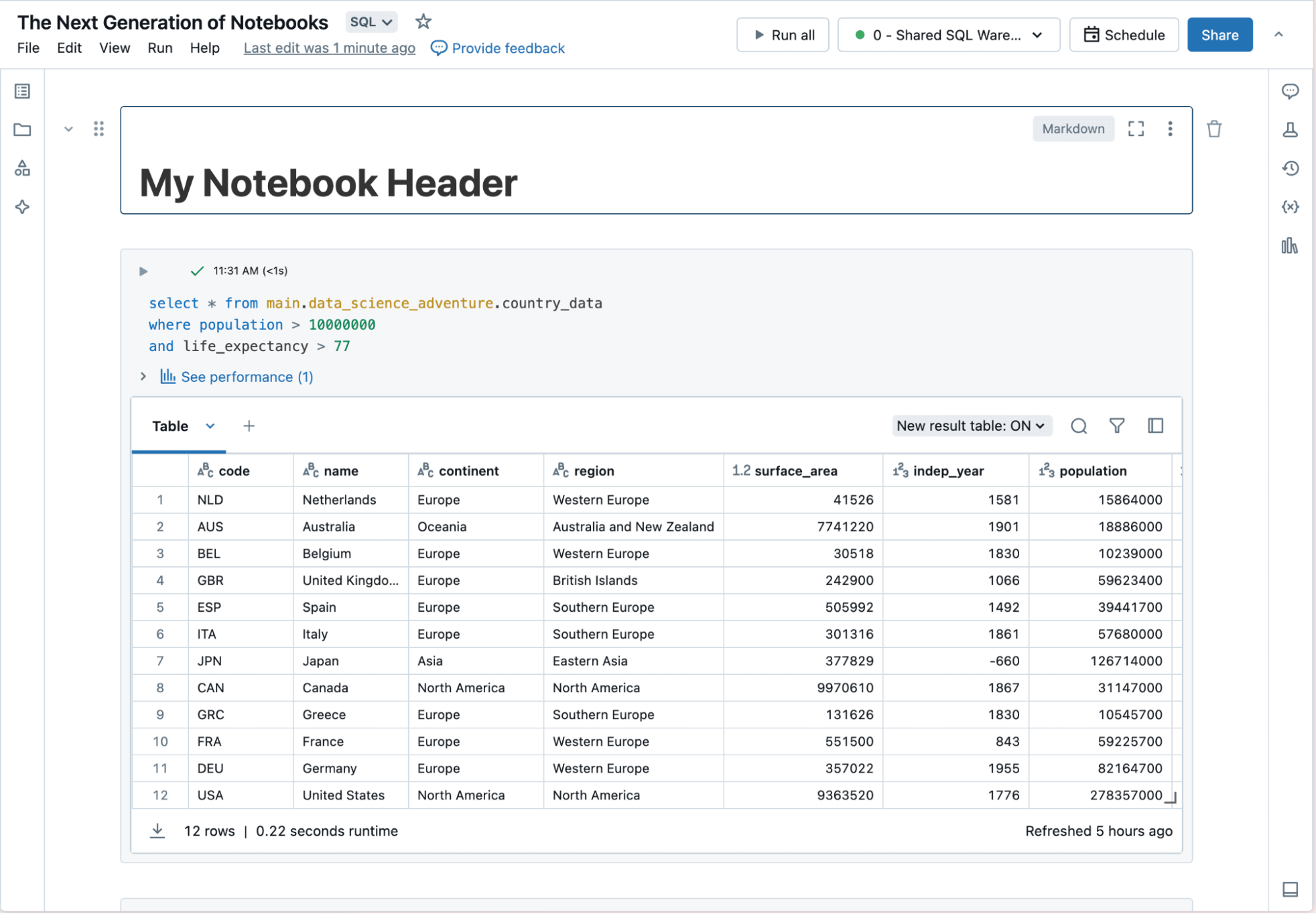
I notebook di Databricks semplificano la costruzione di progetti di dati e AI grazie a un'esperienza per lo sviluppatore pienamente gestita e altamente automatizzata. I notebook funzionano in modo nativo sulla Databricks Data Intelligence Platform, aiutando i professionisti dei dati a cominciare a lavorare in tempi rapidi, sviluppare con strumenti contestuali e condividere facilmente i risultati.
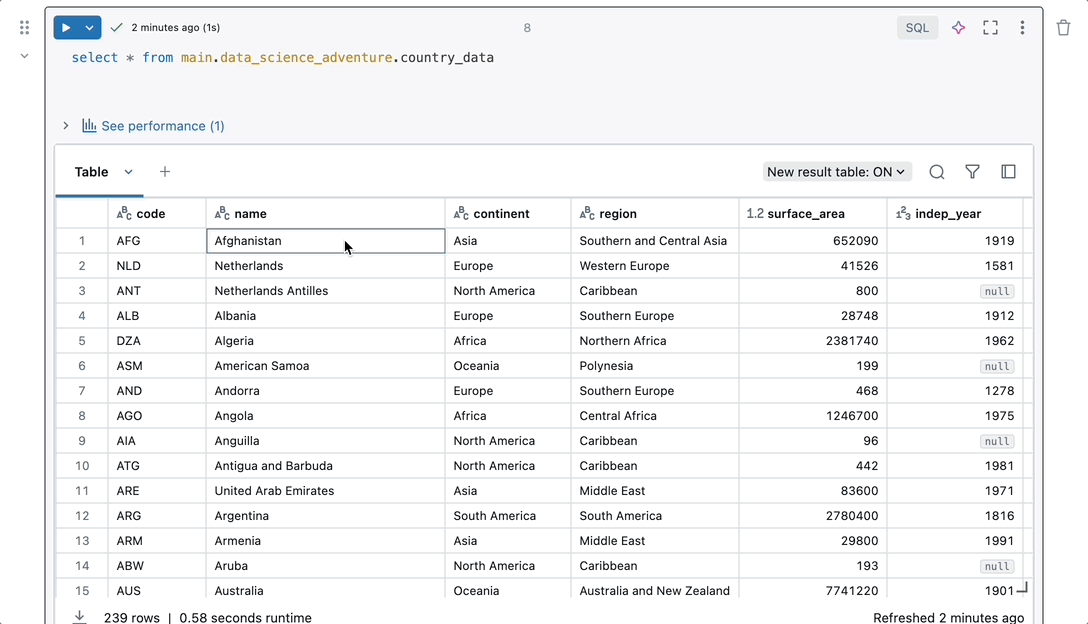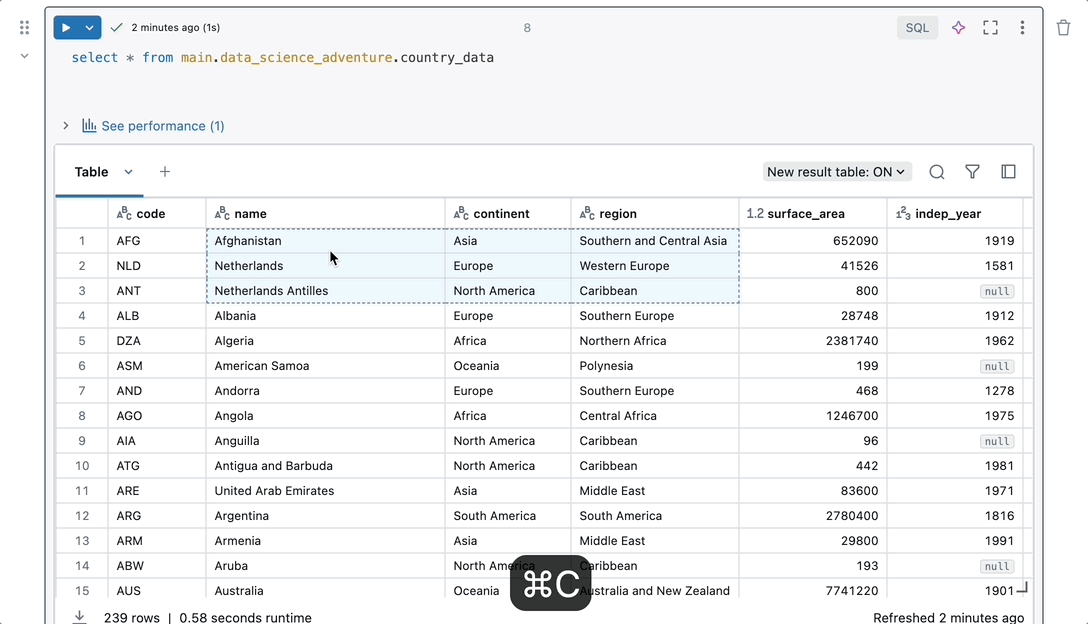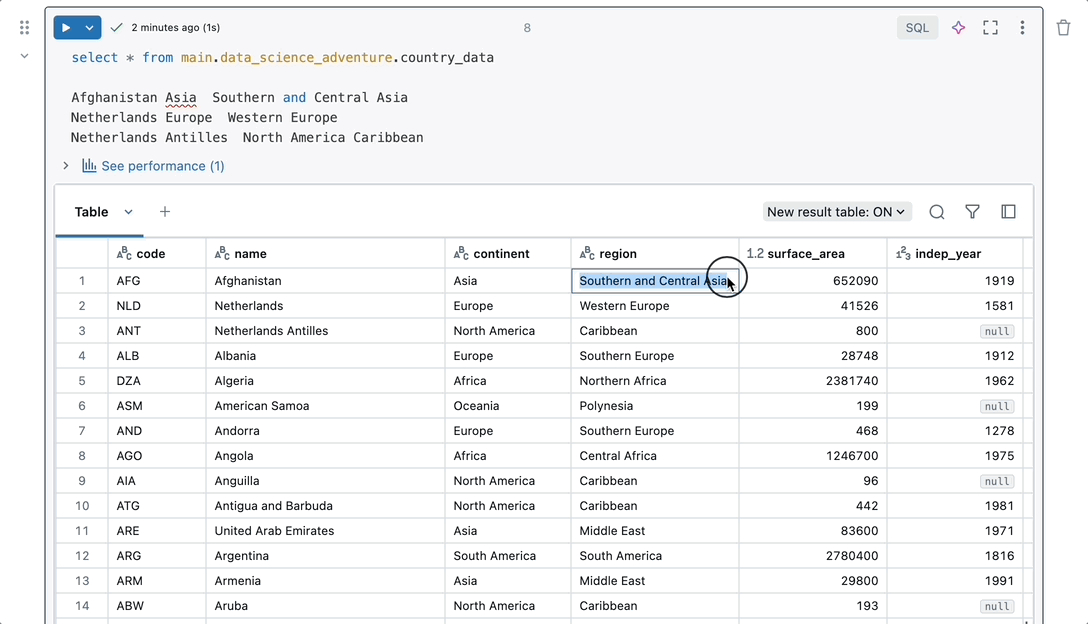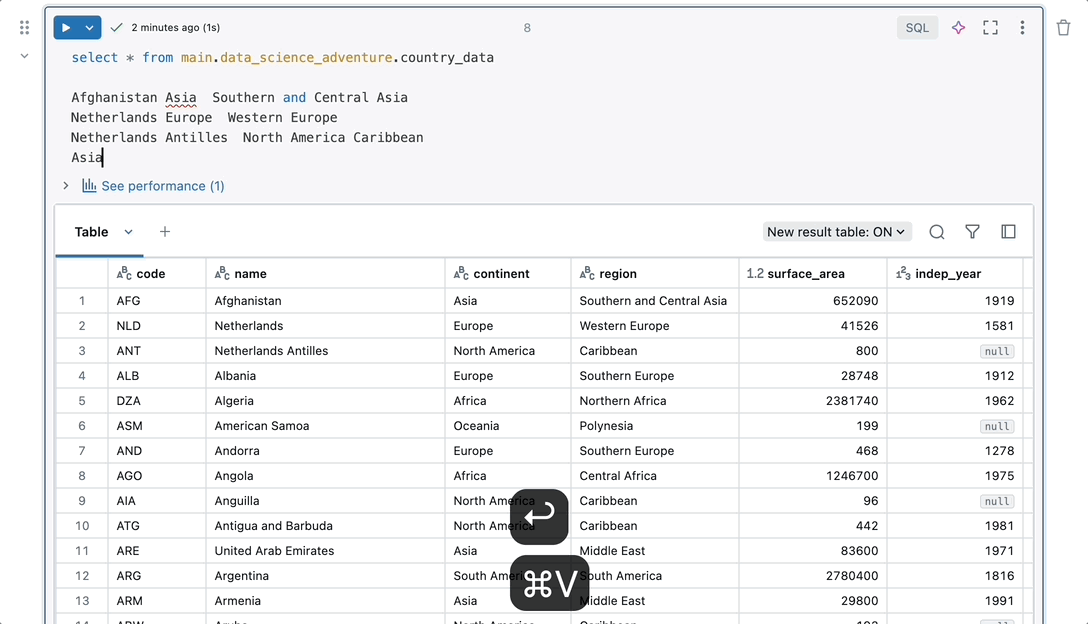
Integrazione diretta
Comincia a lavorare senza bisogno di impostare e configurare lo spazio di lavoro. I notebook offrono funzionalità native per gestire l'intero percorso dei dati da un unico luogo. L'utente può accedere a dati, elaborazione e strumenti di visualizzazione senza impostazioni aggiuntive, potendosi così concentrare sull'analisi dei dati.
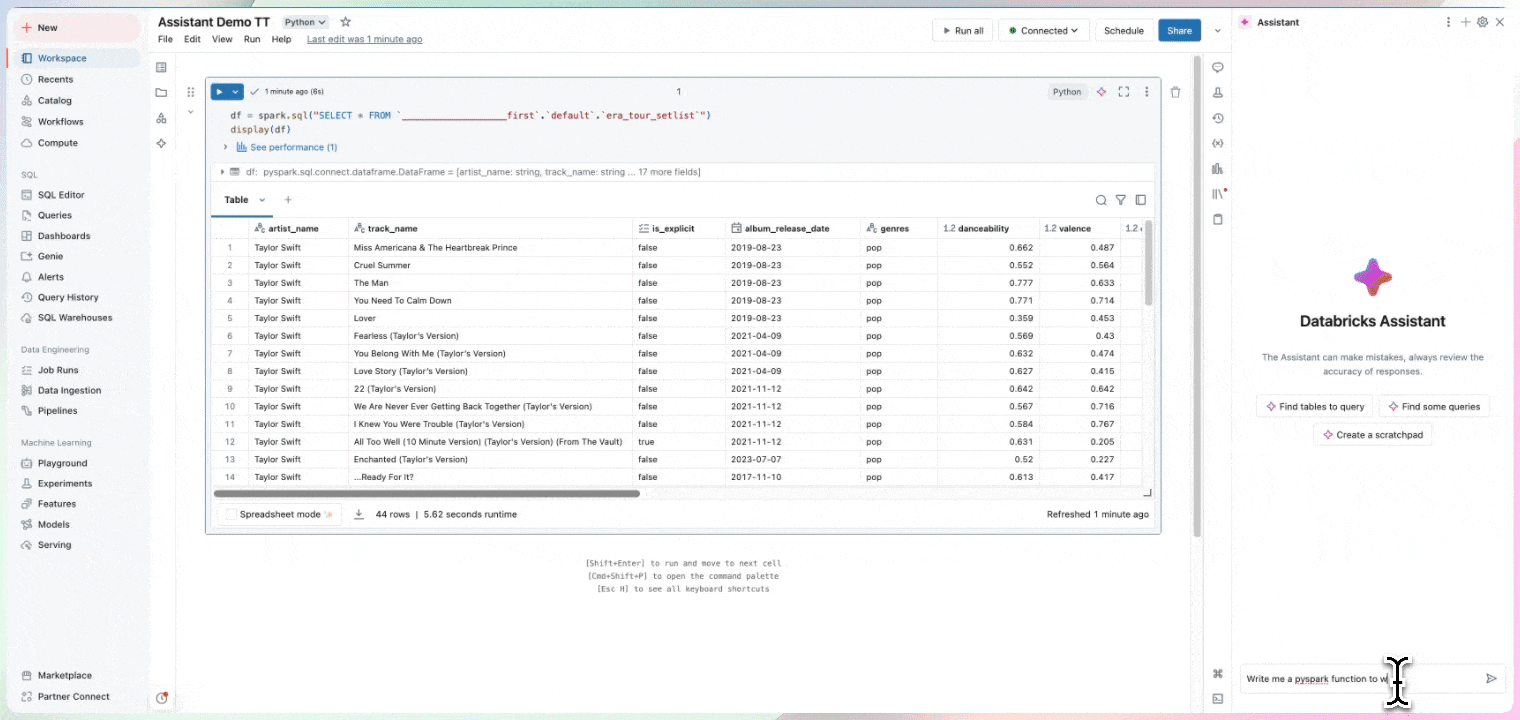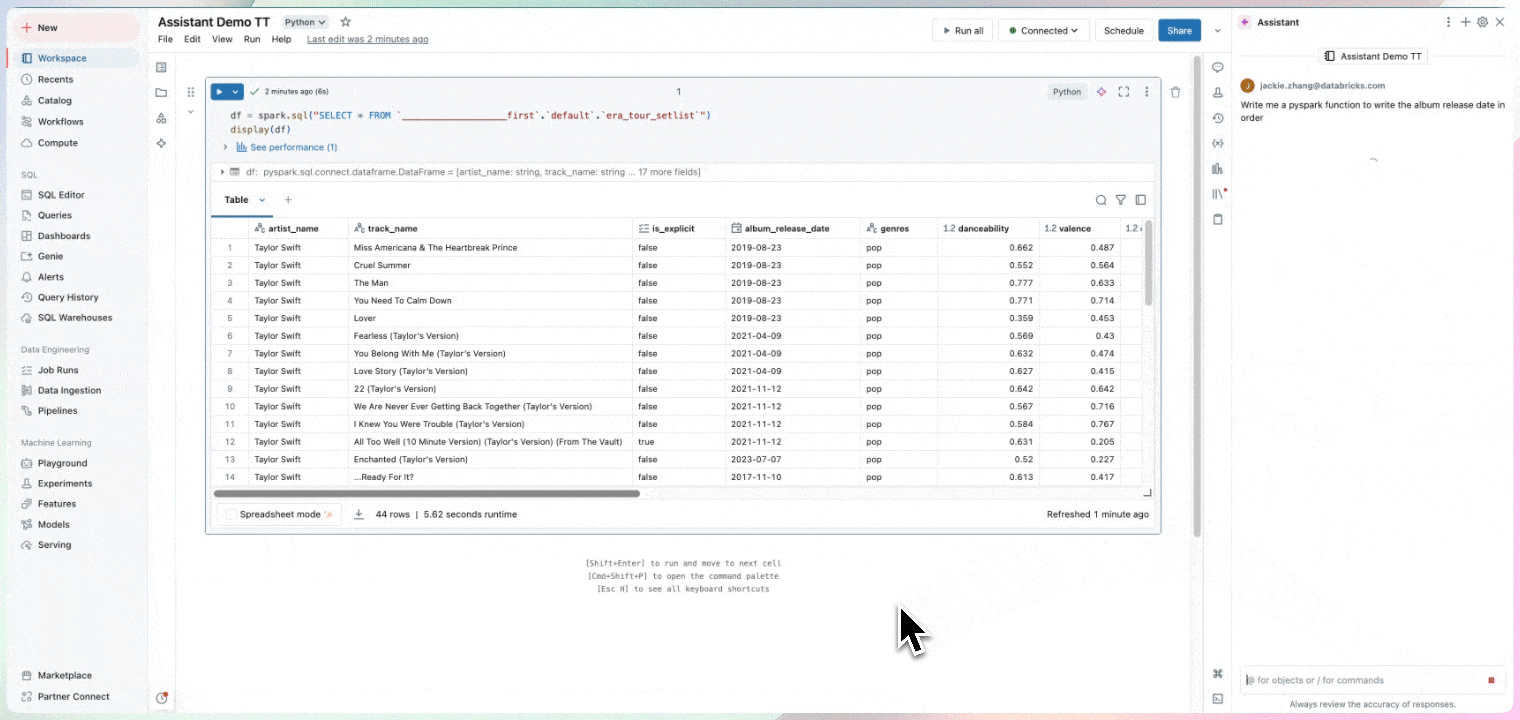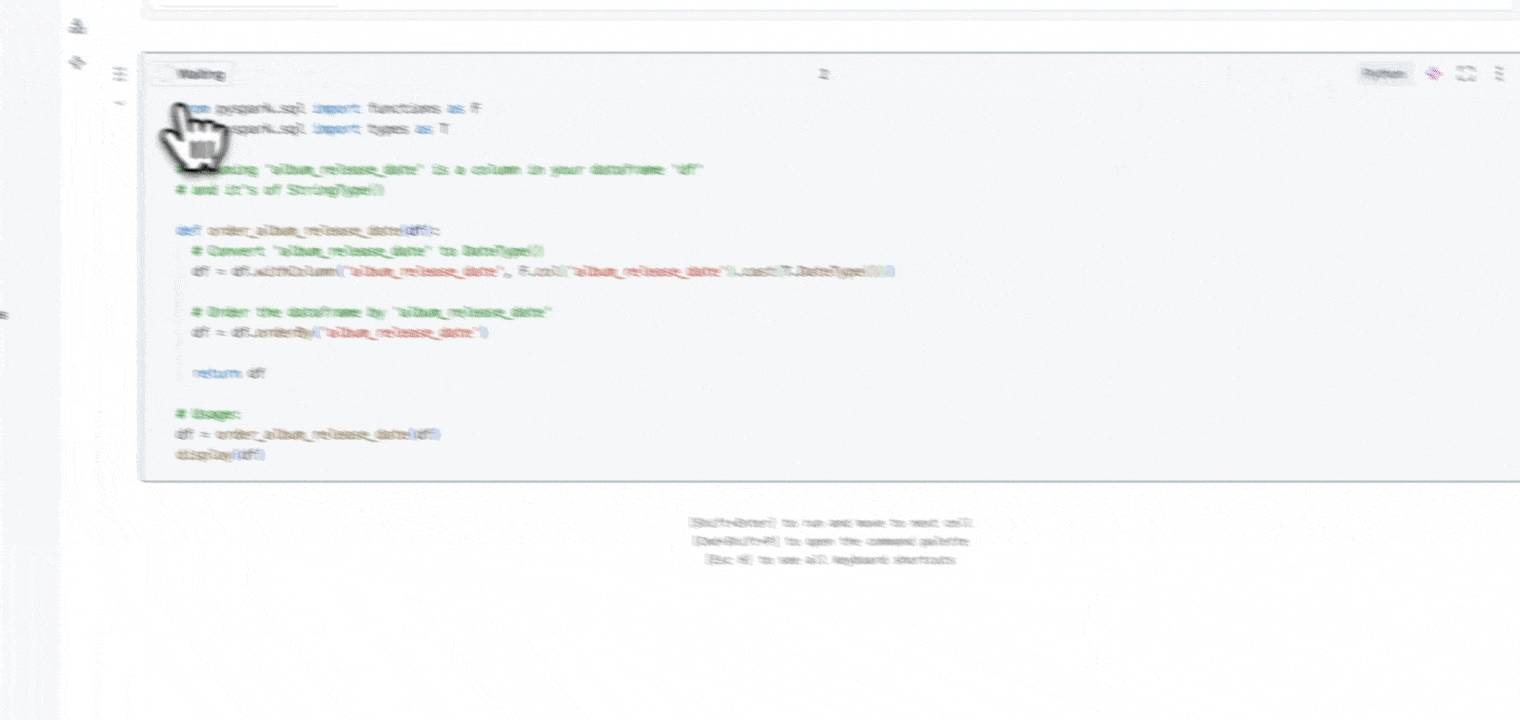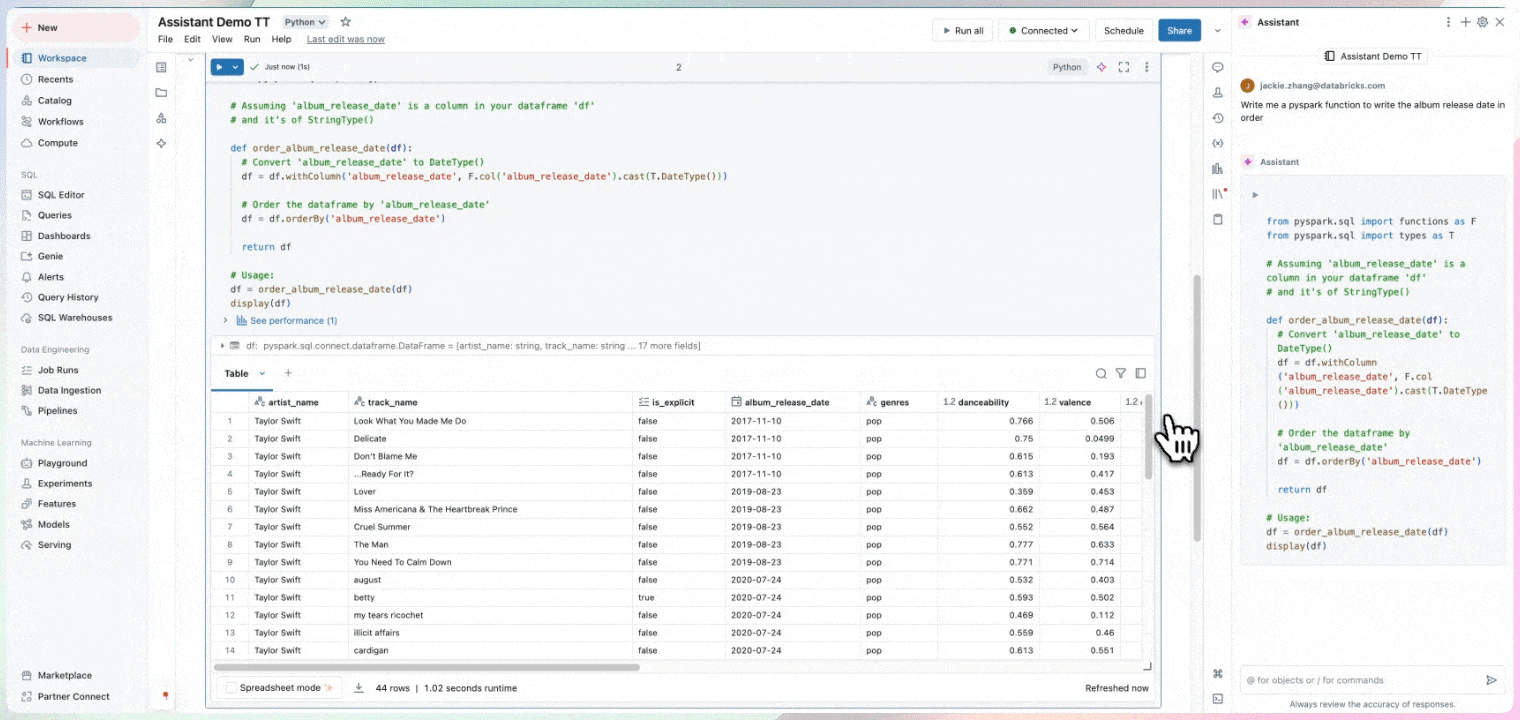
Strumenti di data intelligence
Dedica il tuo tempo a ricavare informazioni approfondite, non alla scrittura del codice. I notebook attingono alle informazioni sui dati, fra cui provenienza, tabelle collegate e popolarità, per estrapolare suggerimenti rilevanti per il tuo lavoro. I notebook comprendono Databricks Assistant, un assistente AI contestuale che consente di interrogare i dati attraverso un'interfaccia conversazionale, aumentando la produttività.
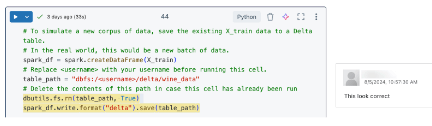
Spazio di lavoro collaborativo
Collabora con altri per creare e condividere progetti in un unico luogo con tutto il team di gestione dei dati. Memorizza commenti e codice in diversi linguaggi nei notebook per condividere un contesto importante con altri utenti. Consulta i registri di utilizzo e i fork dei report per capire come viene consumata l'analisi.