Crea e distribuisci sistemi di agenti AI di qualità
Connetti in modo sicuro i tuoi dati a qualsiasi modello di AI per creare applicazioni accurate e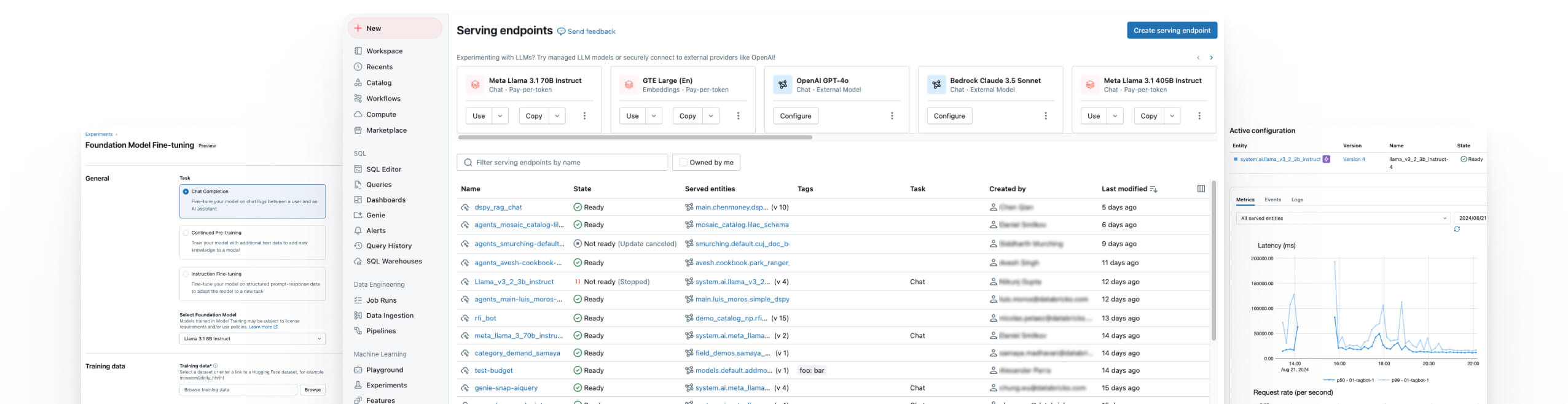
I MIGLIORI TEAM HANNO SUCCESSO CON DATABRICKS

L'unica piattaforma unificata per i sistemi di agenti
Non affidarti più a modelli di AI generici. Databricks ha gli strumenti per creare sistemi di agenti che forniscono risultati accurati e basati su dati.Agenti basati sui tuoi dati
Sviluppa rapidamente agenti ottimizzati sui dati aziendali provenienti da più sistemi. Utilizza qualsiasi modello, da modelli di ML classici a modelli di GenAl, per applicare la migliore soluzione alle esigenze della tua applicazione.
Valutazione personalizzata
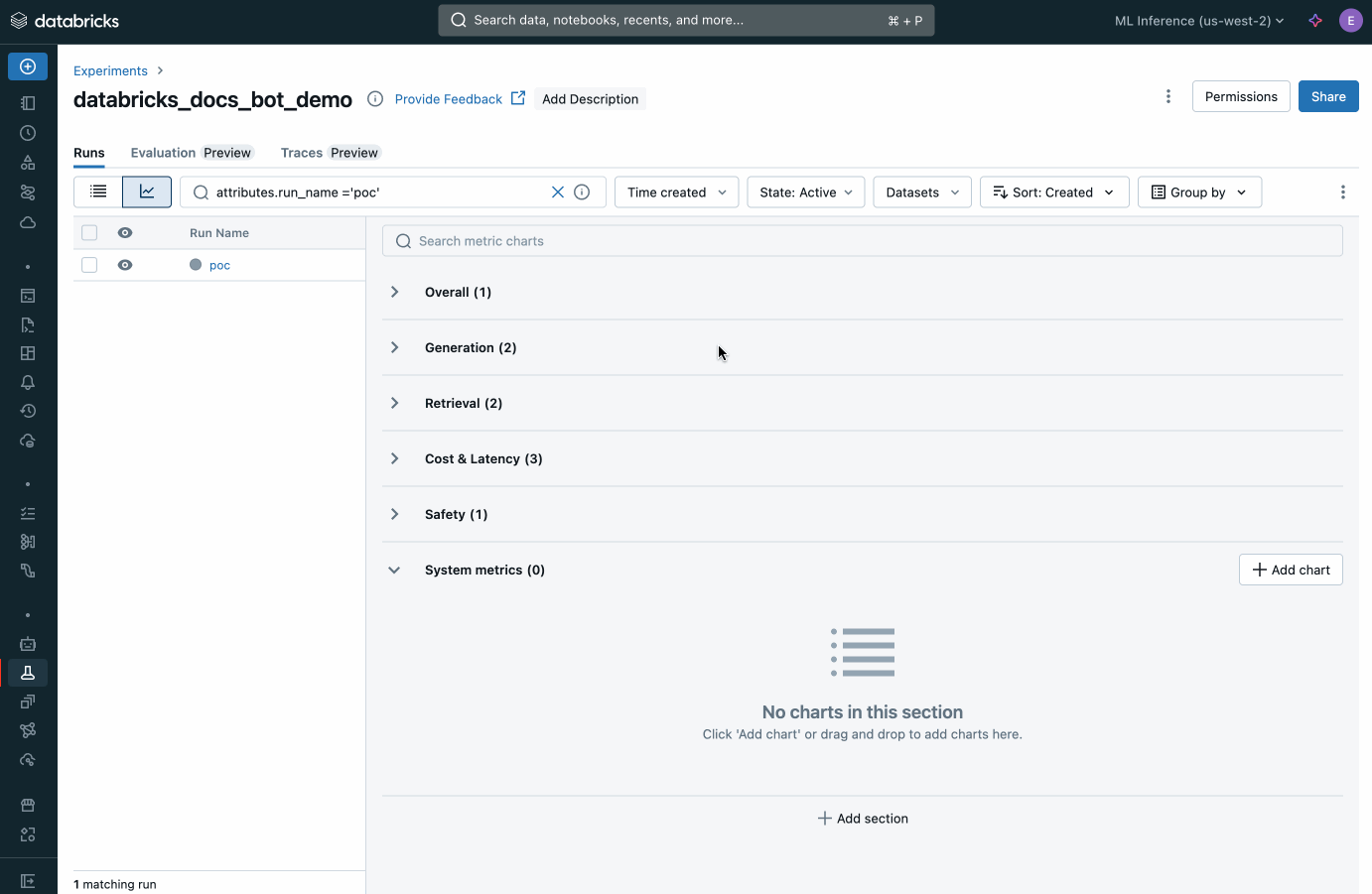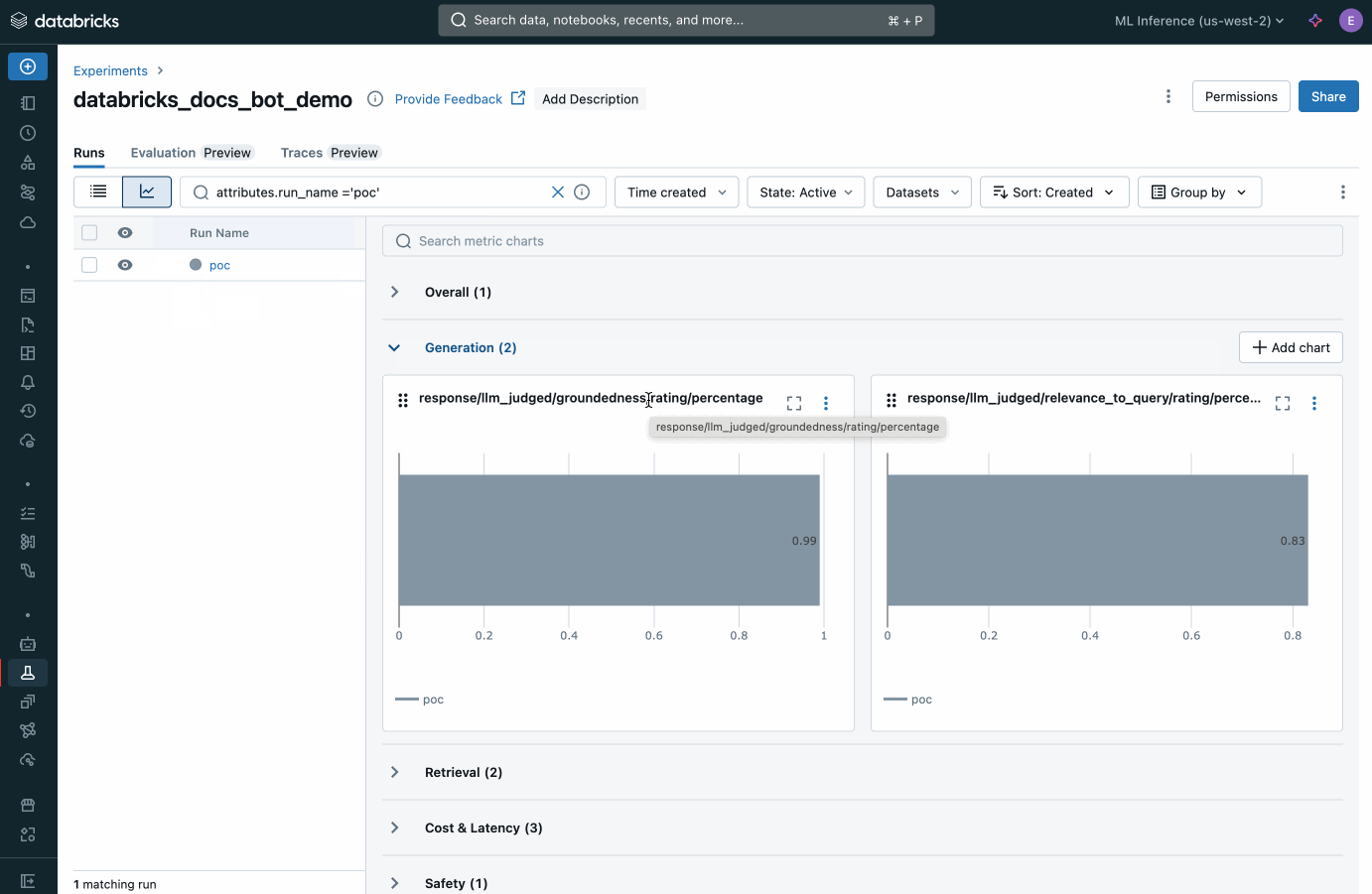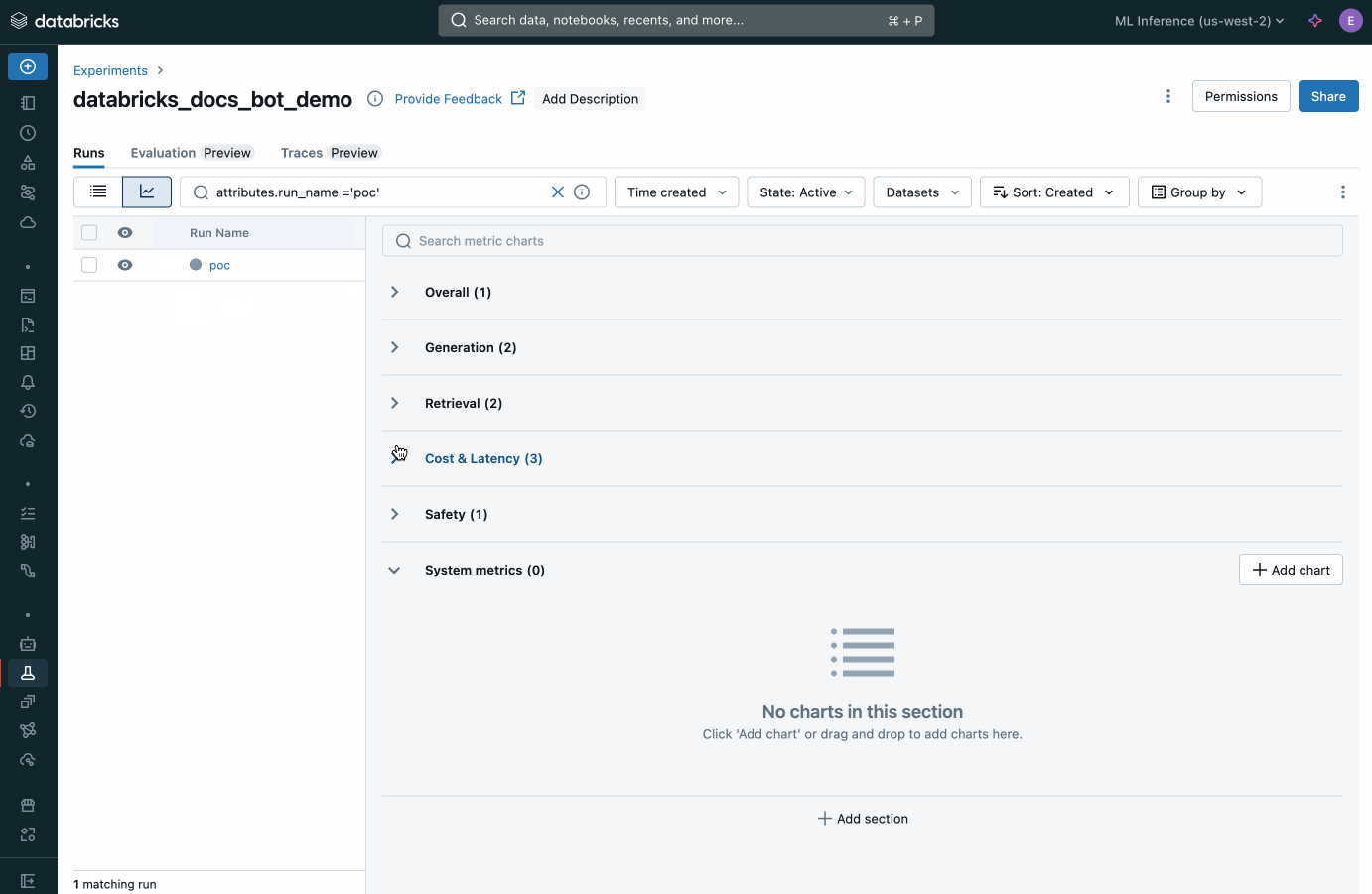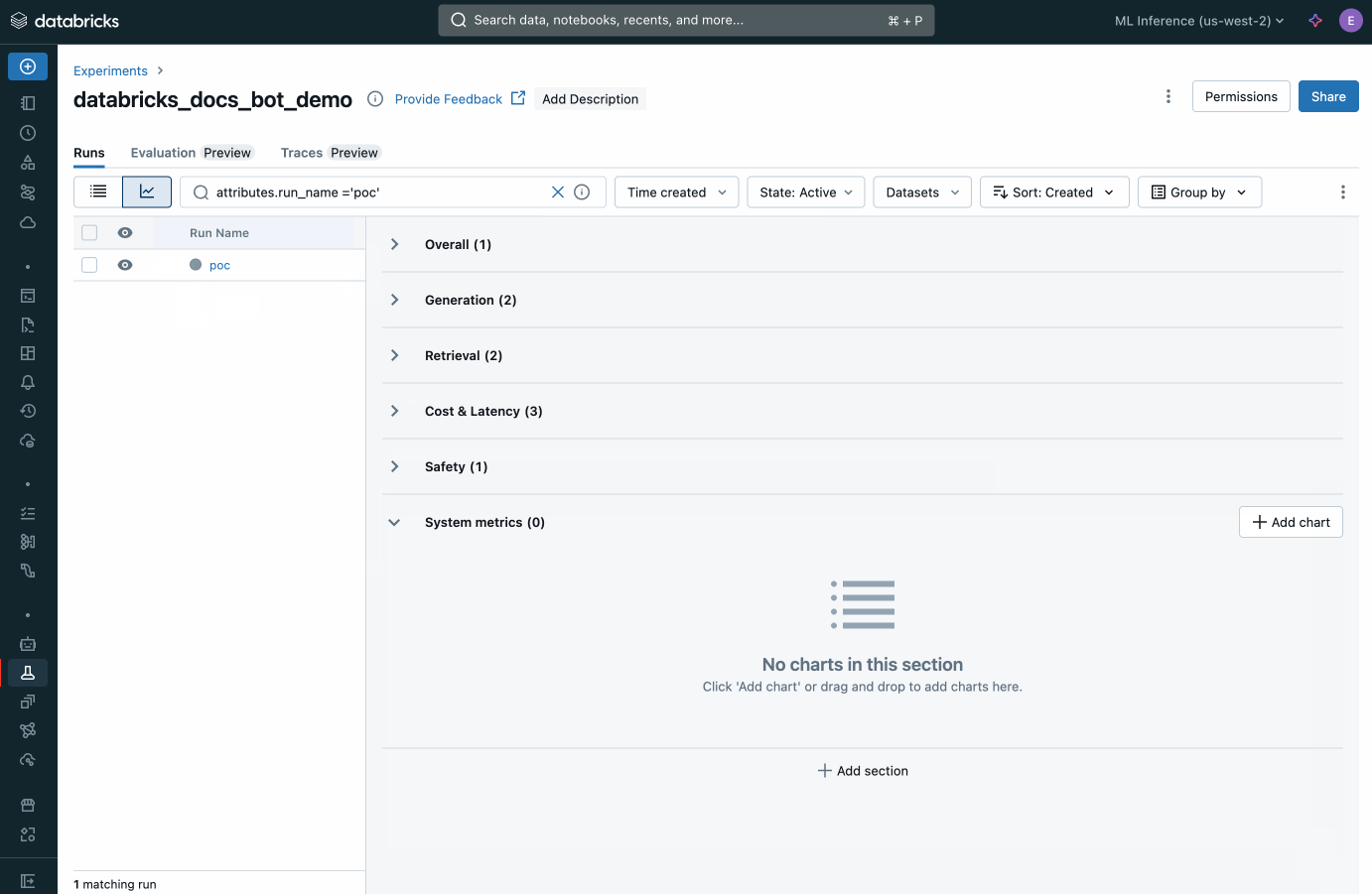
Databricks offre un sistema integrato per valutare gli agenti che supporta qualsiasi modello di AI. Misura la qualità degli output degli agenti tramite giudici AI, valuta le correzioni e distribuisci rapidamente le modifiche. Identifica i problemi di produzione, analizzane le cause principali e intraprendi azioni correttive in tutte le app di ML e GenAI.
Governance
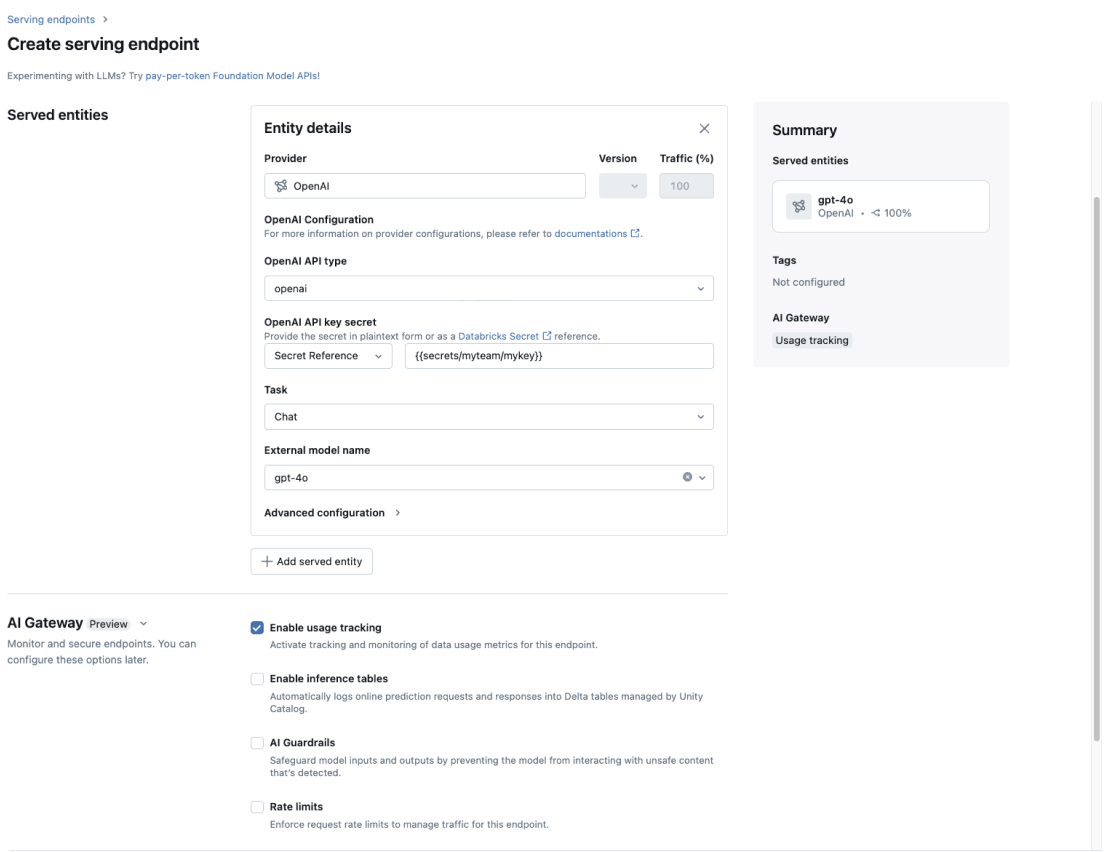
Mantieni la sicurezza dei dati con la governance end-to-end per gli agenti. Applica guardrail per tutti i tuoi modelli, automatizza i controlli di accesso, imposta i limiti di velocità e monitora la provenienza dei dati nell'intero flusso di lavoro.
Miglioramento del 44% nell'accuratezza
Aumenti della produttività per 10 milioni di dollari
Accuratezza del 96% nelle risposte



Strumenti per sistemi di agenti AI end-to-end

Agent Bricks
Crea agenti AI basati sui tuoi dati aziendali. Databricks Agent Bricks ti permette di ottimizzare qualità e costi con dati sintetici, valutazioni personalizzate e ottimizzazione automatica.
Unity AI Gateway
Un unico posto per applicare la governance dei dati a ogni LLM e MCP della tua azienda.
Ricerca vettoriale
Un database vettoriale altamente performante con sincronizzazione in tempo reale dei dati di origine.
Agent Framework e Agent Evaluation
Crea agenti AI di qualità di produzione con Agent Framework. Agent Evaluation, una funzionalità integrata nel framework, garantisce la qualità dell'output degli agenti con valutazioni assistite dall'AI e offre un'interfaccia utente intuitiva per il feedback degli stakeholder umani.
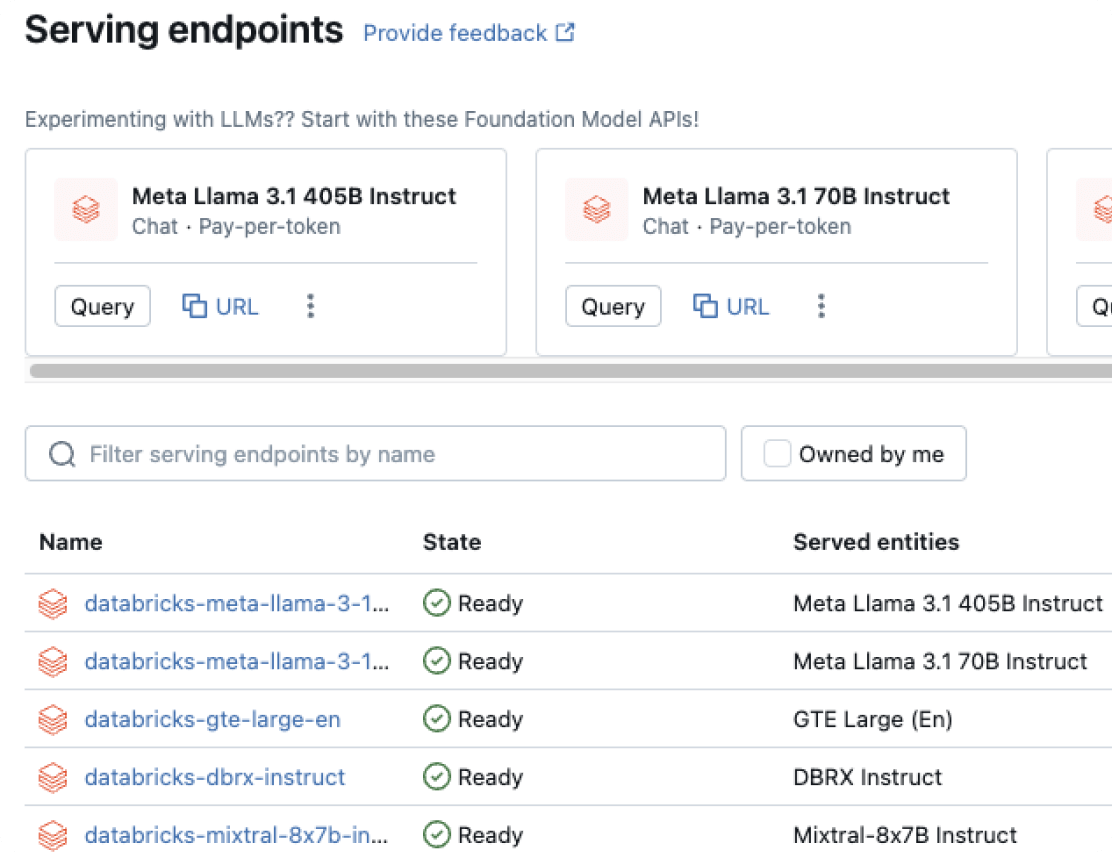
Model Serving
Distribuzione unificata per agenti, modelli di GenAI e modelli di ML classici.
Model Training
Ottimizza LLM open source, pre-addestra LLM personalizzati o crea modelli di ML classici.
Databricks Notebook
Aumenta la produttività dei team con i Databricks Collaborative Notebook, che consentono la collaborazione in tempo reale e semplificano i flussi di lavoro per la data science.
Managed MLFlow
Estendi MLflow open source, una piattaforma MLOps unificata per la creazione di modelli e app di AI generativa migliori, con affidabilità, sicurezza e scalabilità di livello aziendale.
Monitoraggio della qualità dei dati
Offre un monitoraggio semplice e scalabile che rileva le anomalie, tiene traccia dell'aggiornamento dei dati e fornisce segnali di qualità coerenti su tutti gli asset di dati e AI.
La piattaforma di intelligenza dei dati di Databricks
Esplora l'intera gamma di strumenti disponibili sulla Databricks Data Intelligence Platform per integrare perfettamente dati e AI in tutta l'organizzazione.
Costruisci sistemi di agenti di alta qualità

Trasforma i tuoi dati senza sforzo
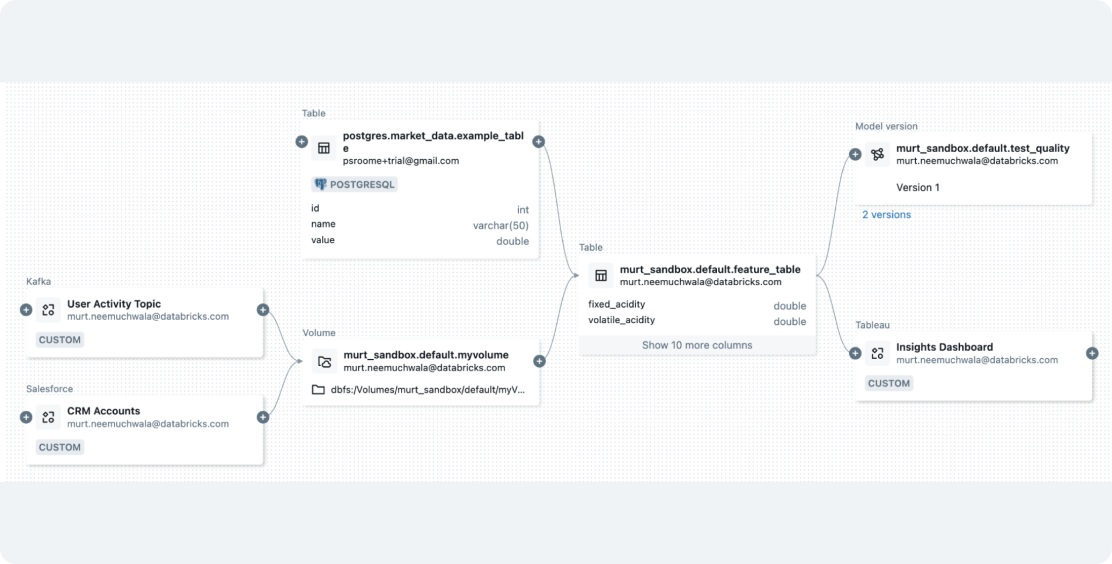
Prepara i dati con un'integrazione perfetta per flussi di lavoro di GenAI e ML
Databricks consente di acquisire qualsiasi tipo di dati e di orchestrare i processi per prepararli per le applicazioni di GenAI o ML. Con la governance integrata, semplifica la funzionalizzazione dei dati e crea indici vettoriali per la RAG utilizzando Databricks AI Search, unificando le pipeline di dati e modelli per semplificare i flussi di lavoro e ridurre i costi.

Fai il passo successivo
Formazione gratuita sulla GenAI
Sviluppa le tue competenze sulla GenAI con questo corso autogestito e ottieni un certificato di completamento Databricks riconosciuto nel settore.
Guida introduttiva
Questo tutorial sugli agenti AI mostra come si passa da un proof-of-concept (POC) a un'applicazione di alta qualità pronta per la produzione utilizzando Databricks.




FAQ su Databricks
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il percorso di trasformazione