Managed MLFlow
Gestisci nativamente modelli di IA, agenti e app con MLflow in Databricks


Che cos'è Managed MLflow?
Managed MLflow su Databricks offre tracciamento degli esperimenti all'avanguardia, osservabilità, valutazione delle prestazioni e gestione dei modelli per l'intero spettro del machine learning e dell'IA, dai modelli classici e deep learning alle applicazioni e agenti di IA generativa, il tutto nativamente all'interno della Databricks Data Intelligence Platform. Managed MLflow si basa sulle fondamenta flessibili di MLflow open source ed è potenziato con affidabilità, sicurezza e scalabilità di livello enterprise. Questo consente alle aziende di costruire con sicurezza modelli e agenti di alta qualità utilizzando i loro strumenti preferiti in tutto l'ecosistema di AI & ML, garantendo al contempo che i loro asset di IA e dati siano governati e protetti.
Vantaggi
Ciclo di vita unificato di ML e Gen AI
Managed MLflow unifica ML classico, deep learning e sviluppo GenAI in un unico flusso di lavoro semplificato. Dal tracciamento degli esperimenti al deployment, offre versioning coerente, gestione dei prompt e confezionamento tra modelli e agenti—eliminando la necessità di unire strumenti separati.
Flessibile e open-source
Evita il vendor lock-in e mantieni la massima flessibilità in tutto il tuo stack. Basato su MLflow open-source, con oltre 800 collaboratori della community, più di 25 milioni di download mensili del pacchetto e scelto da oltre 5.000 organizzazioni in tutto il mondo, Managed MLflow supporta senza problemi la tua scelta di framework, linguaggi e strumenti. Ottieni tutta la libertà e l'affidabilità dell'open source, oltre alla semplicità di un'esperienza completamente gestita.
Osservabilità e governance di livello enterprise
Profondamente integrato nella piattaforma Databricks, Managed MLflow offre piena tracciabilità, monitoraggio in tempo reale e governance unificata attraverso i tuoi flussi di lavoro di IA. Con Unity Catalog, puoi far rispettare automaticamente i controlli di accesso, tracciare la linea di discendenza e garantire la conformità tra i tuoi modelli, dati e agenti.
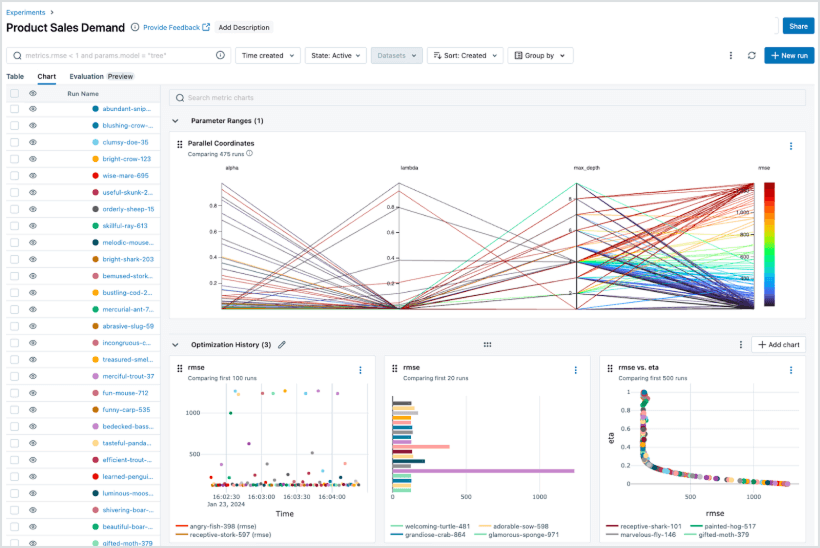
Potenti analitiche delle prestazioni
Analizza, confronta e visualizza le prestazioni tra sviluppo, staging e produzione—tutto da un unico posto. Con il modello dati unificato di MLflow e l'integrazione con Databricks AI/BI e SQL, i data scientists possono scoprire tendenze, identificare regressioni e aumentare l'impatto sul business utilizzando la stessa piattaforma che utilizzano per costruire e distribuire.
Nuove funzionalità GenAI
Tracciamento
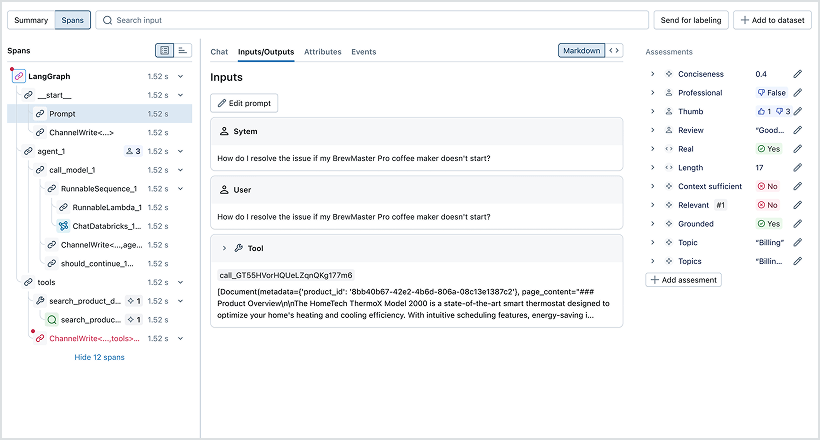
Cattura input, output ed esecuzione passo dopo passo—inclusi prompt, recuperi e chiamate agli strumenti—con il tracciamento open-source e compatibile con OpenTelemetry. Strumenta automaticamente le librerie GenAI popolari o assorbi direttamente le tracce. Debug e itera più velocemente con visualizzazioni interattive della timeline, confronti affiancati e zero lock-in del fornitore.
Valutazione dell'IA generativa
Valuta gli agenti GenAI utilizzando la valutazione LLM-as-a-judge e il feedback umano, direttamente nell'interfaccia utente di MLflow. Crea set di dati da tracce di produzione, confronta gli output tra le diverse versioni e valuta la qualità con metriche predefinite o personalizzate come l'allucinazione o la pertinenza. Integra il feedback degli esperti tramite interfacce utente web o APIs di app per allinearti al giudizio umano e migliorare continuamente i risultati.
Registro dei prompt e controllo delle versioni dell'agente
Gestisci le versioni dei prompt, degli agenti e del codice dell'applicazione in un unico posto con MLflow. Link tracce, valutazioni e dati sulle prestazioni a versioni specifiche per una derivazione completa del ciclo di vita. Riusa e confronta i prompt tra i flussi di lavoro, gestisci le versioni degli agenti con metriche e parametri associati e integra con Git e CI/CD per accelerare l'iterazione governata.
Monitoraggio e avvisi per l'IA generativa
Monitora la qualità della GenAI in tempo reale con le dashboard di MLflow, gli esploratori di tracce e gli avvisi automatici. Traccia problemi come la fuga di PII, i picchi di latenza o le risposte non utili utilizzando le valutazioni LLM-judge e le metriche personalizzate. Configura le valutazioni online e agisci rapidamente, prima che gli utenti ne risentano.
Caratteristiche principali
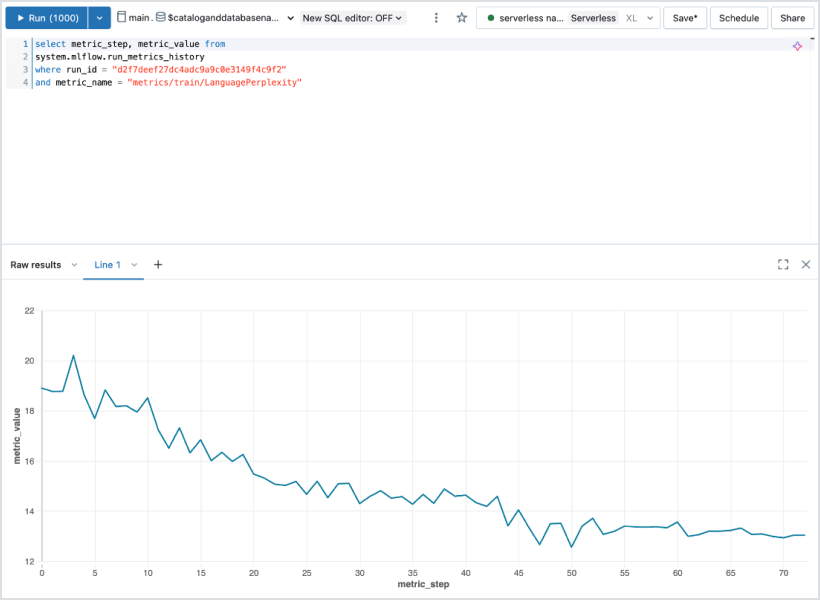
Monitoraggio di esperimenti
Ottieni il tracciamento automatico di parametri, metriche, artefatti e modelli da qualsiasi framework di ML o deep learning. MLflow ti offre un audit trail completo e supporta confronti approfonditi tra architetture, checkpoint e flussi di lavoro di addestramento, su vasta scala.
Valutazione dei modelli per ML e DL
Registra automaticamente metriche integrate e personalizzate per compiti come classificazione o regressione. Confronta i risultati con le linee di base, registra artefatti come le curve ROC e valida i modelli su nuovi set di dati—prima che raggiungano la produzione.
Gestione dei modelli e governance semplificate
Scopri, condividi e gestisci i modelli in modo centralizzato con MLflow Model Registry, integrato con Unity Catalog per una governance end-to-end. Monitora lo stato del deployment e collabora tra team con piena visibilità sulle prestazioni del modello in diversi ambienti
Deployment su larga scala
Esegui il deployment dei modelli con un formato di pacchettizzazione riproducibile che include tutto il codice, le dipendenze e i pesi. Servili come API REST o esegui l'inferenza batch ad alto throughput con ai_query, ottimizzato sia per CPU che per GPU tramite Databricks Model Serving.
Leggi la sezione dedicata alle novità di prodotto di Azure Databricks e AWS per scoprire le nostre funzionalità più recenti.
Offerte MLflow a confronto
MLflow Open Source | Managed MLflow su Databricks | |
|---|---|---|
Tracing & AI Observability | ||
APIs di tracciamento | ||
Integrazione del debug dei notebook | ||
Tracciamento per applicazioni di produzione | ||
Dashboard di osservabilità personalizzabili | ||
Consulta i dati di tracciamento con SQL e strumenti AI/BI | ||
Monitoraggio della produzione | ||
Valutazione dell'IA Generativa | ||
APIs di valutazione | ||
UI e APIs di feedback umano | ||
Giudici LLM di alta qualità | ||
Set di dati di valutazione con versioni | ||
Gestione dei prompt | ||
Registro dei prompt MLflow | ||
UI dell'editor di prompt | ||
Monitoraggio di esperimenti | ||
API di tracciamento di MLflow | ||
Dashboard di prestazioni ricche e comparazione | ||
Query dei dati degli esperimenti con SQL e strumenti AI/BI | ||
Server di tracciamento di MLflow | Hosting interno | Completamente gestito |
Integrazione con notebook | ||
Integrazione con flussi di lavoro | ||
Gestione dei modelli | ||
Registro dei modelli MLflow | ||
Gestione delle versioni dei modelli | ||
Flussi di lavoro di approvazione basati sui ruoli | ||
Integrazione con flussi di lavoro CI/CD | ||
Implementazione flessibile | ||
Packaging del modello | ||
Inferenza batch su larga scala | ||
Distribuzione in tempo reale a bassa latenza | ||
Analisi in streaming integrata | ||
Sicurezza e gestione | ||
Governance aziendale | ||
Alta disponibilità | ||
Aggiornamenti automatici |
Risorse
Documentazione
Tutorial
Blog
Video
eBook
Webinar
Domande frequenti
Pronto per cominciare?