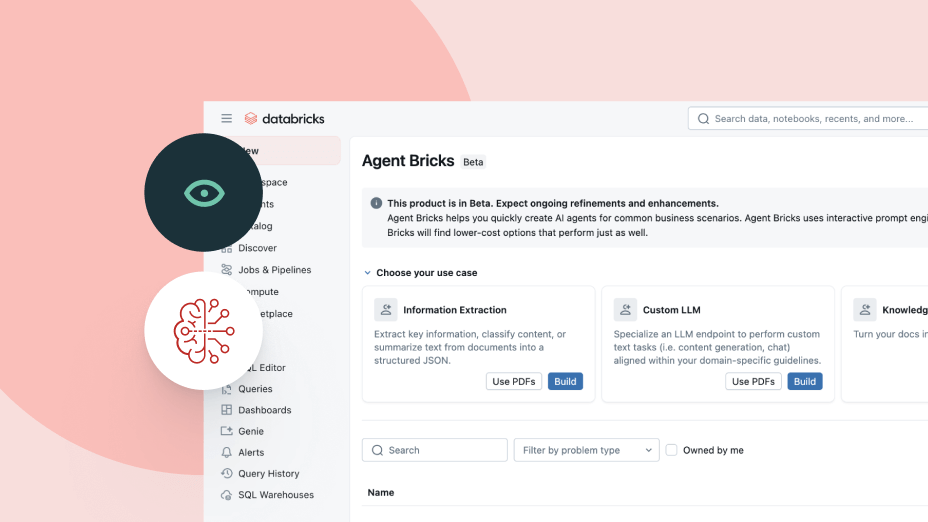
Agenti AI per la produzione
Piattaforma unificata per sviluppare e governare agenti AI che migliorano continuamente
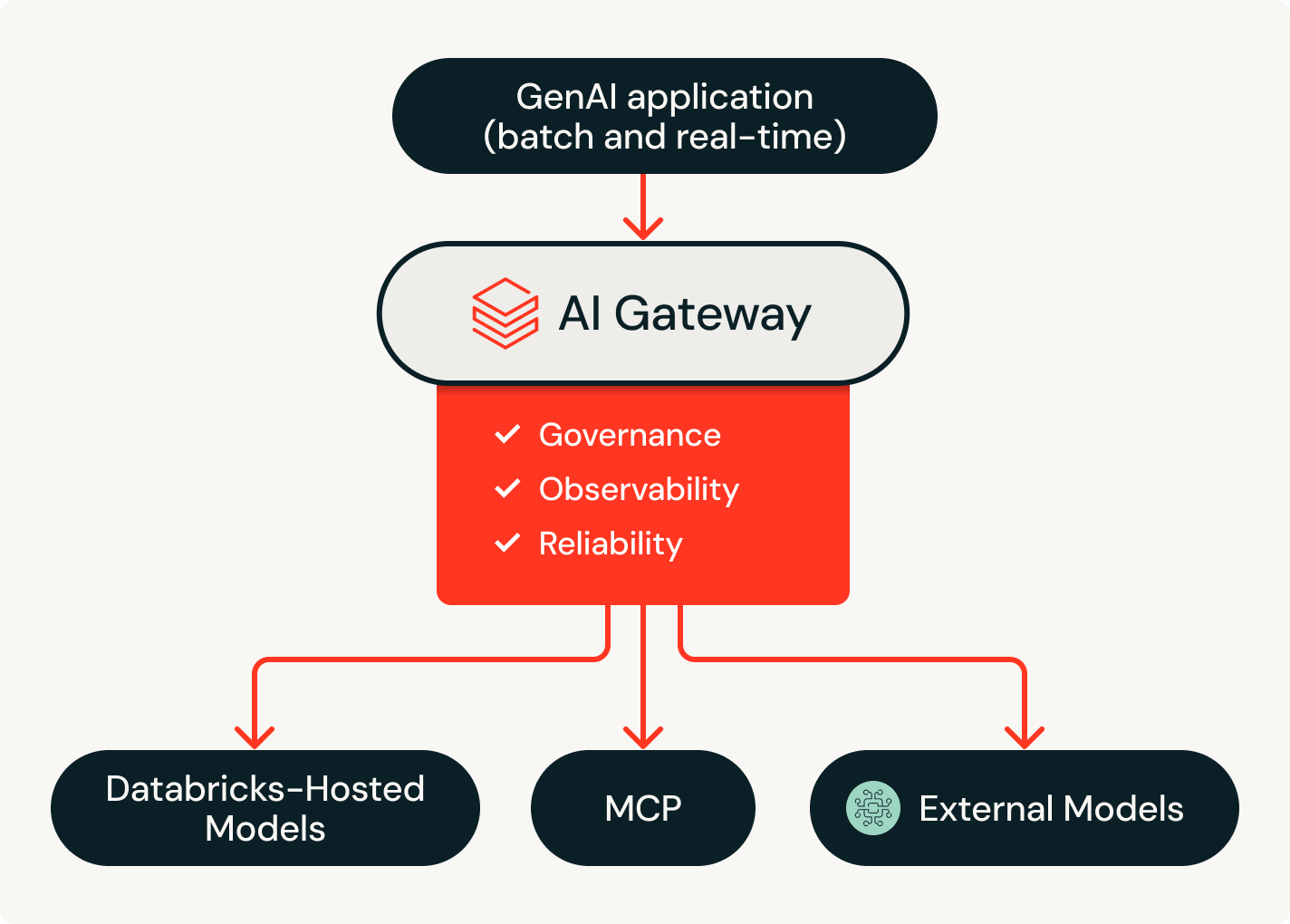
Gestisci la proliferazione degli agenti. Sviluppa con la massima affidabilità.
Unifica sviluppo, gestione e governance degli agenti AI aziendali.Agenti che conoscono i tuoi dati
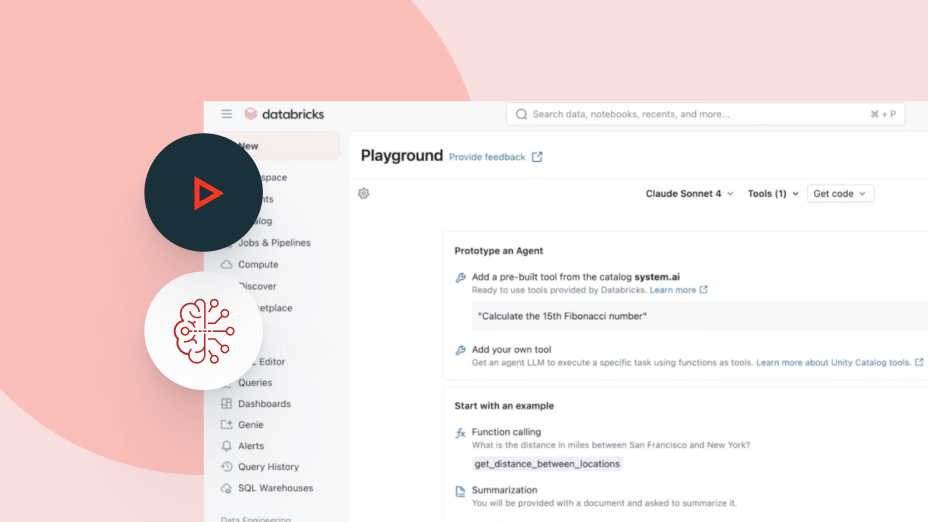
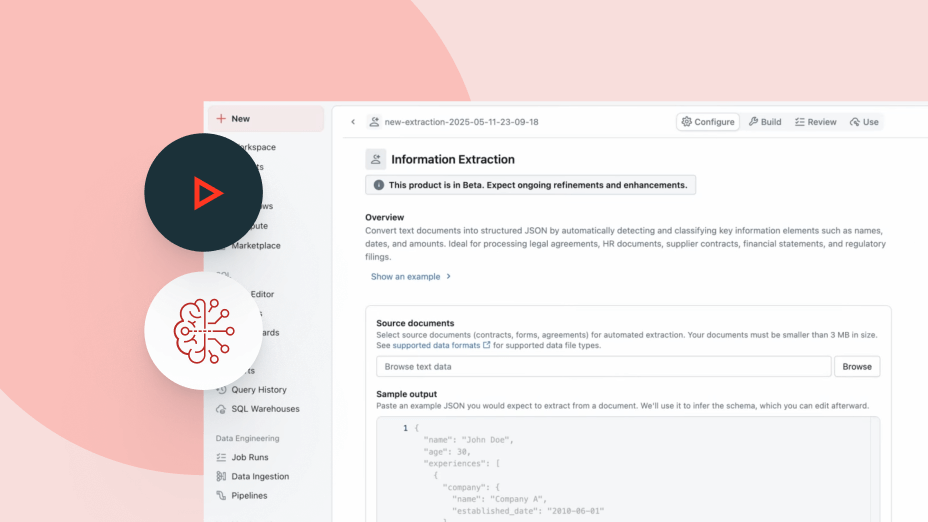
Agent Bricks utilizza il contesto aziendale (schemi, definizioni di business e semantiche personalizzate) per prendere decisioni più intelligenti su quali strumenti e tabelle utilizzare, come eseguire correttamente le join sui dati e come produrre risposte accurate e coerenti.
Aperto e multi-AI
Accedi a tutti i principali modelli AI, da OpenAI, Anthropic e Google fino a quelli open-source, tramite un'unica piattaforma. Agent Bricks ti permette di cambiare modello istantaneamente per ottimizzare costi, qualità e prestazioni senza dover riprogettare il tuo stack.
Governance unificata
Solo Databricks governa l'intero stack, dai dati ai modelli AI, in un unico sistema di riferimento. Monitora ogni agente, server MCP, modello e strumento con una chiara assegnazione delle responsabilità e controlli end-to-end che garantiscono che gli agenti non accedano mai a più risorse di quanto consentito.

I MIGLIORI TEAM HANNO SUCCESSO CON AGENT BRICKS
Tutto ciò di cui hai bisogno per creare, governare e scalare agenti
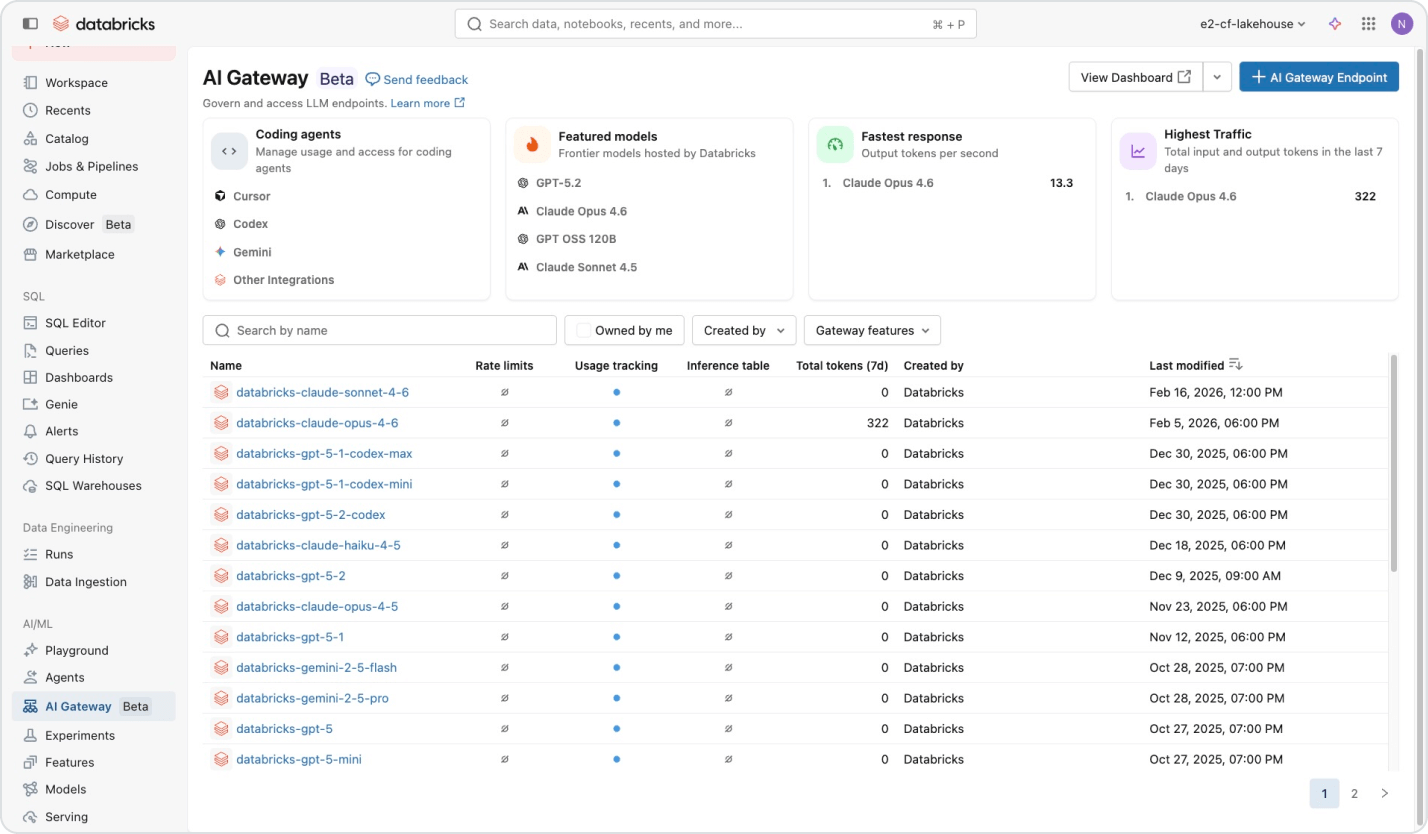
Accedi a qualsiasi modello tramite un unico contratto, senza vincoli di fornitore
Accedi ai modelli AI di OpenAI, Anthropic, Google, Meta e altri tramite un'unica piattaforma. Il routing intelligente e i fallback automatici mantengono operativi gli agenti anche quando un provider non è disponibile. Unity Catalog applica autorizzazioni granulari e limiti di frequenza per utente o team, permettendoti di scalare l'accesso ai modelli senza perdere il controllo.
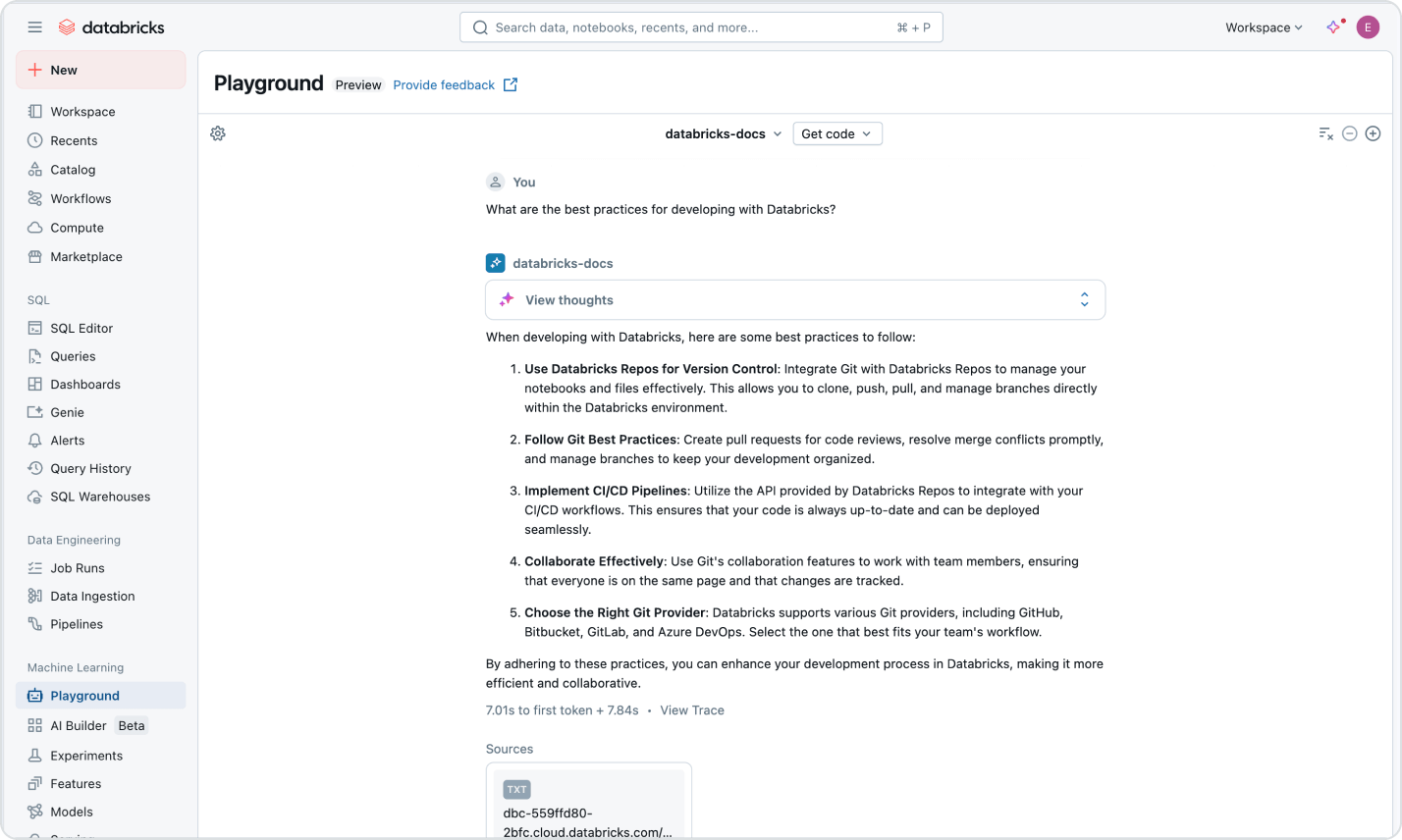
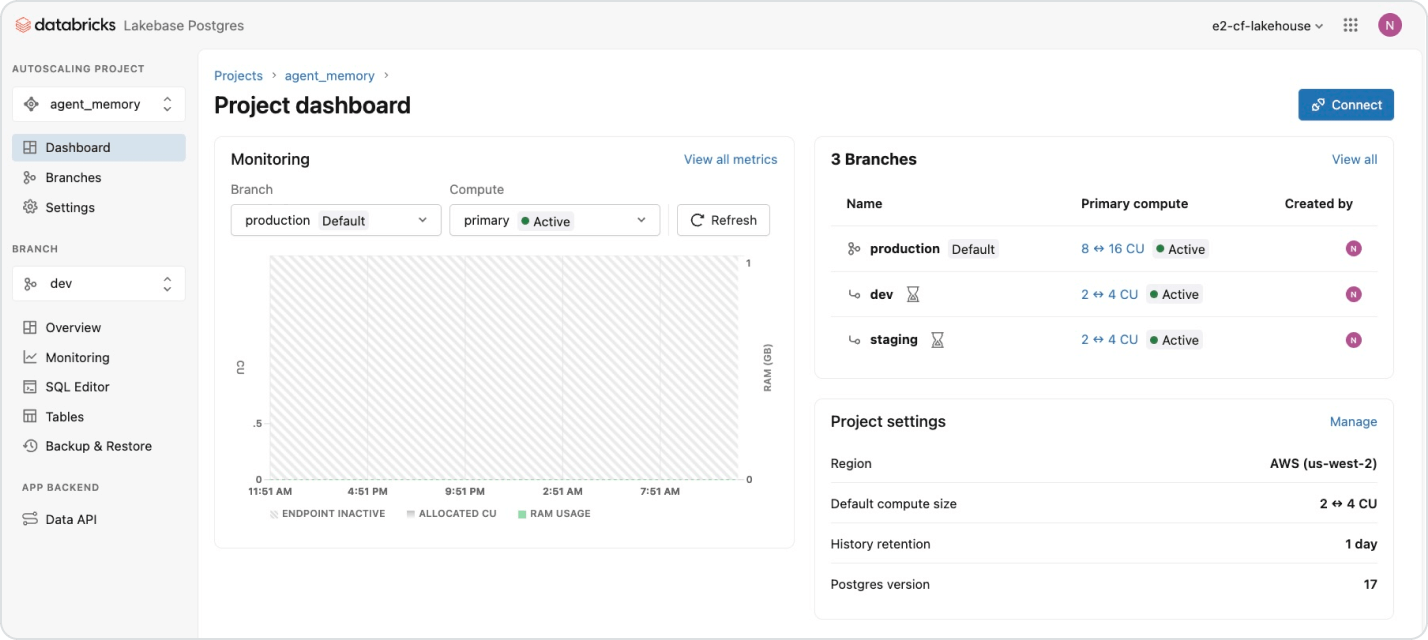
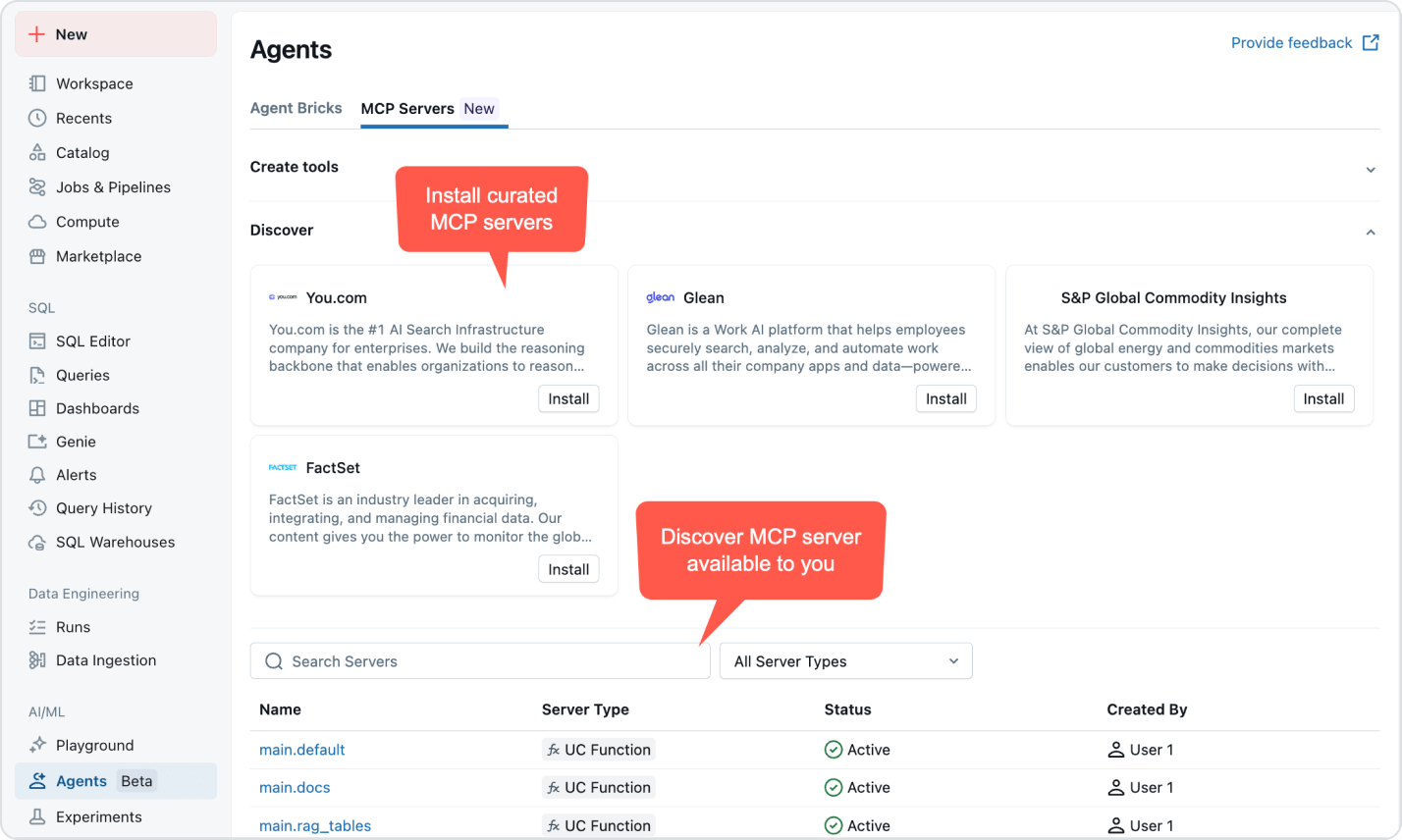



I prezzi basati sull'utilizzo tengono sotto controllo la spesa
Paga solo per i prodotti che utilizzi con una granularità al secondo.Scopri di più
Scopri come la Databricks Data Intelligence Platform supporta i tuoi team di dati in tutti i carichi di lavoro di dati e AI.
Genie
Ottieni informazioni dettagliate dai tuoi dati semplicemente ponendo domande in linguaggio naturale.

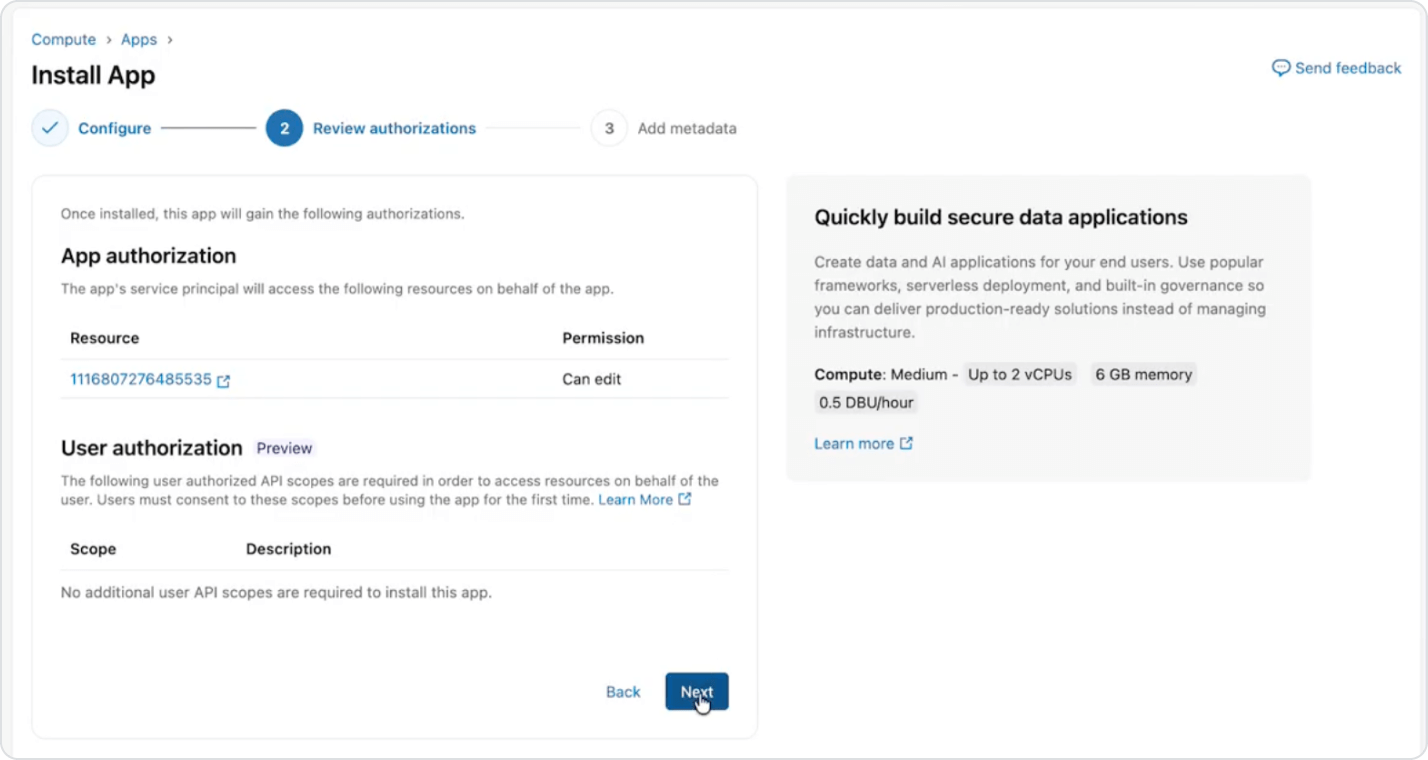
Databricks Apps
Trasforma agenti personalizzati in applicazioni AI sicure e rivolte agli utenti su Databricks. Crea esperienze complete basate su dati e modelli governati, con infrastruttura serverless e scalabilità integrata.

Model Serving
Distribuisci e governa qualsiasi modello o agente AI in produzione con osservabilità, scalabilità e controlli enterprise integrati.

Ricerca vettoriale
Alimenta applicazioni AI in tempo reale con un database vettoriale ad alte prestazioni che sincronizza continuamente i tuoi dati sorgente.

Unity Catalog
Governa in modo fluido dati strutturati e non strutturati, modelli di machine learning, notebook, dashboard e file su qualsiasi cloud o piattaforma.

Intelligenza artificiale
Esplora l'intera suite di strumenti AI di Databricks per sistemi di agenti AI end-to-end.

La piattaforma di intelligenza dei dati di Databricks
Esplora la gamma completa di strumenti disponibili su Databricks per integrare perfettamente dati e AI in tutta l'organizzazione.
Fai il passo successivo




FAQ di Agent Bricks
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il tuo percorso di trasformazione dei dati