Model Serving
Implementazione e governance unificate per tutti i modelli e agenti di AI


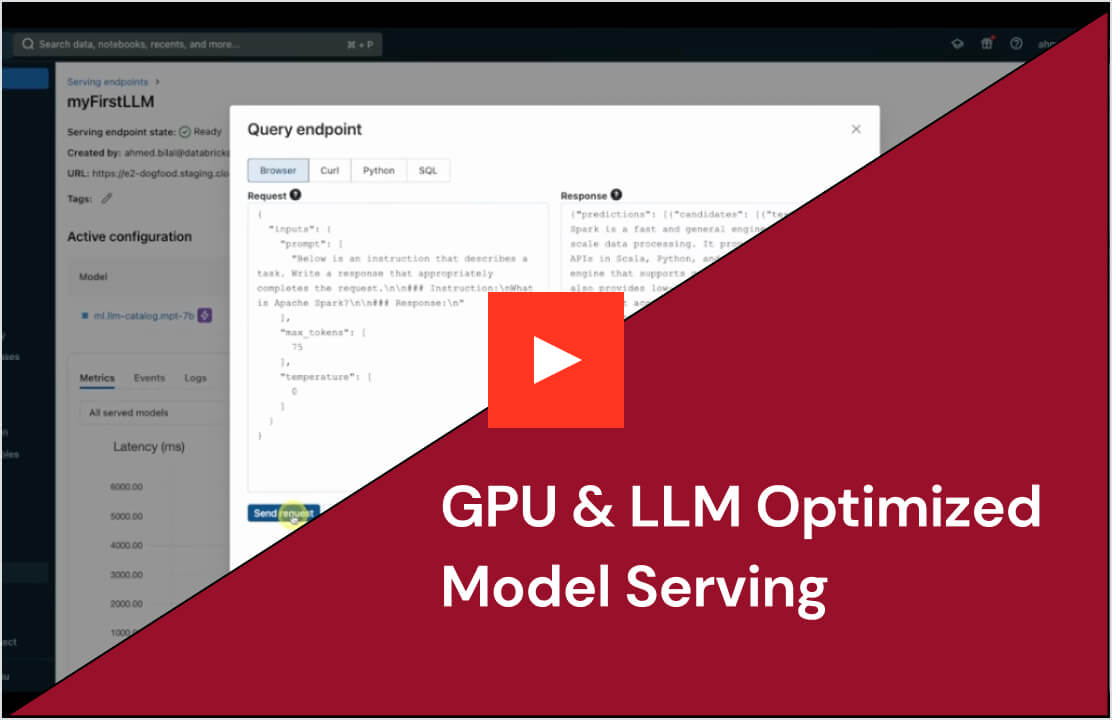
Introduzione
Databricks Model Serving offre alle aziende una soluzione robusta per l'implementazione di modelli di ML classici, modelli di AI generativa e agenti di AI. Supporta modelli proprietari come Azure OpenAI, AWS Bedrock e Anthropic, e modelli open source come Llama e Mistral. I clienti possono anche distribuire modelli open source ottimizzati o modelli di ML classici addestrati sui propri dati. Possono inoltre utilizzare facilmente i modelli serviti come endpoint nei propri flussi di lavoro, sia per inferenze batch su larga scala che per applicazioni in tempo reale. Model Serving include anche funzionalità integrate di governance, tracciabilità e monitoraggio per garantire risultati di alta qualità.
Citazioni dei clienti
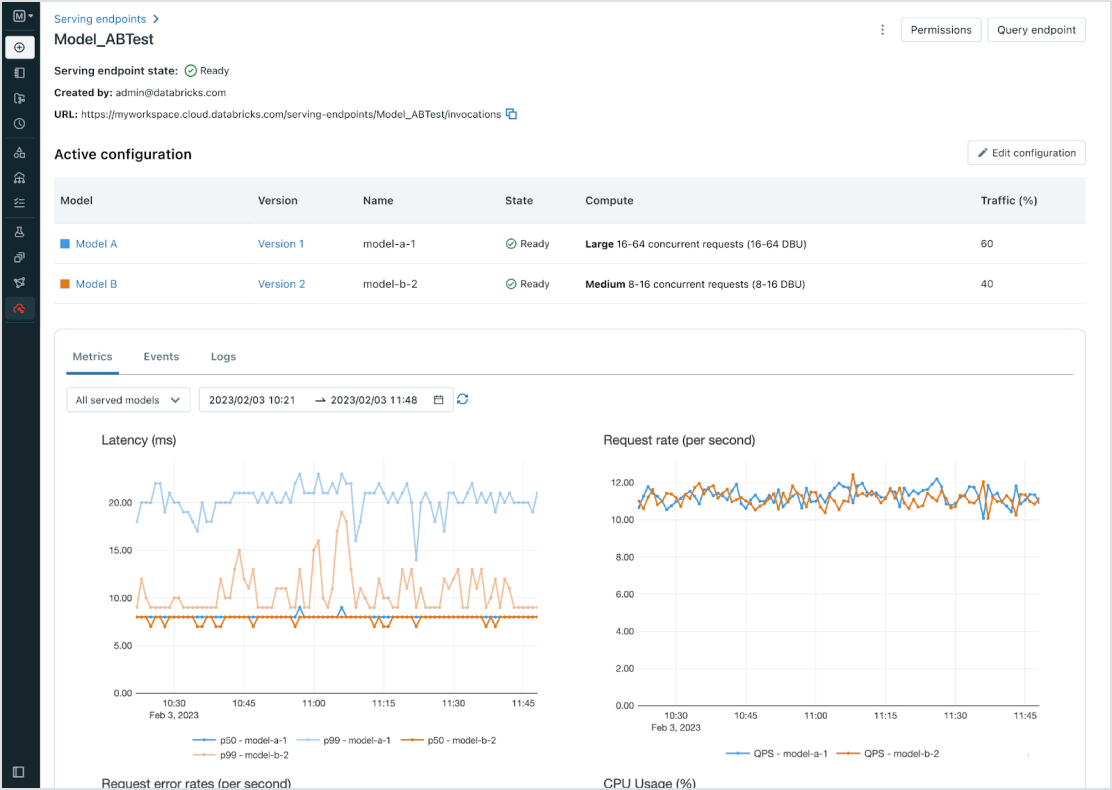
Distribuzione semplificata per tutti i modelli e agenti di AI
Distribuisci qualsiasi tipo di modello, dai modelli open-source preaddestrati a modelli personalizzati costruiti con i tuoi dati, su CPU e GPU. La creazione di container e la gestione dell'infrastruttura automatizzate riducono i costi di manutenzione e velocizzano la distribuzione, consentendo di concentrarsi sulla costruzione di sistemi di agenti di AI e sulla creazione di valore aggiunto per l'attività in tempi più rapidi.
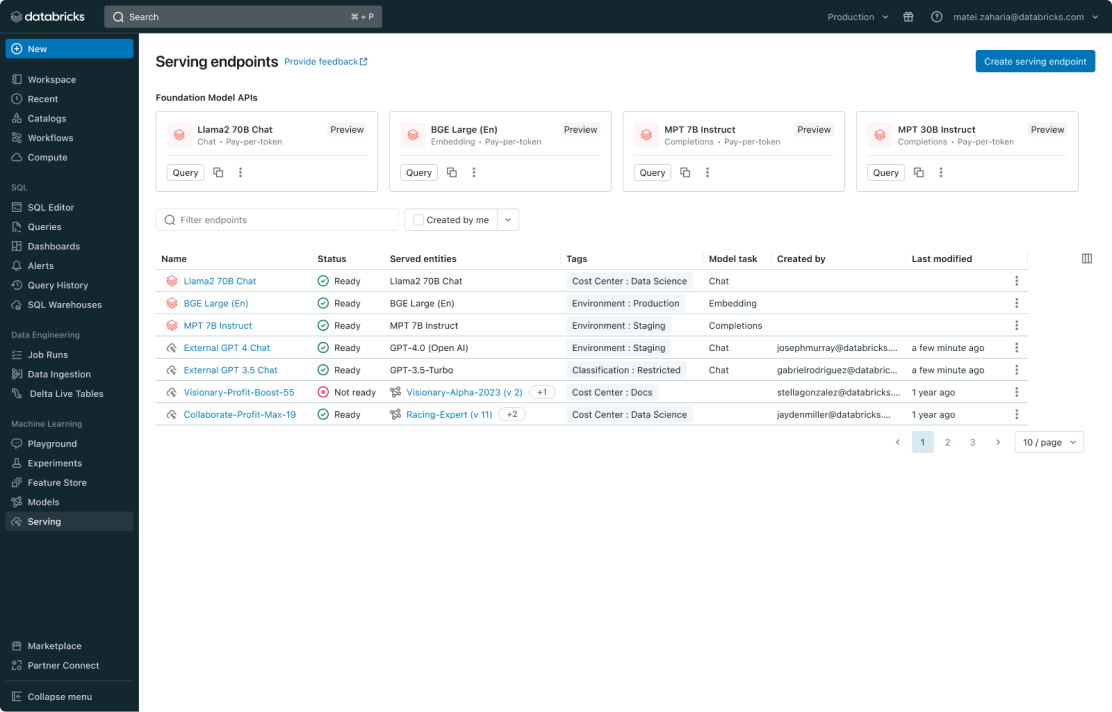
Gestione unificata per tutti i modelli
Gestisci tutti i modelli, inclusi modelli ML personalizzati come PyFunc, scikit-learn e LangChain, modelli di base (Foundation Model) su Databricks come Llama 3, MPT e BGE, e modelli di base ospitati altrove come ChatGPT, Claude 3, Cohere e Stable Diffusion. Model Serving rende accessibili tramite un'interfaccia utente e un'API unificata tutti i modelli, inclusi quelli ospitati da Databricks o da altri fornitori su Azure o AWS.
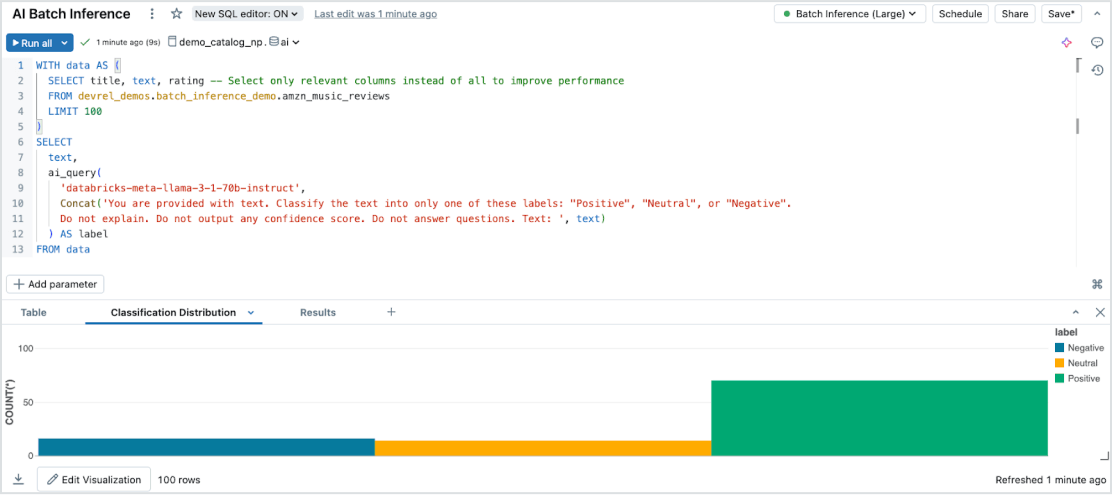
Inferenza batch senza sforzo
Model Serving consente un'efficiente inferenza AI serverless su grandi set di dati, indipendentemente dal tipo di dato o modello. Si integra perfettamente con Databricks SQL, Notebooks e Workflows per applicare l'AI su larga scala. Grazie alle AI Functions, permette di eseguire inferenze batch su vasta scala in modo immediato, senza gestione dell'infrastruttura, garantendo velocità, scalabilità e governance.
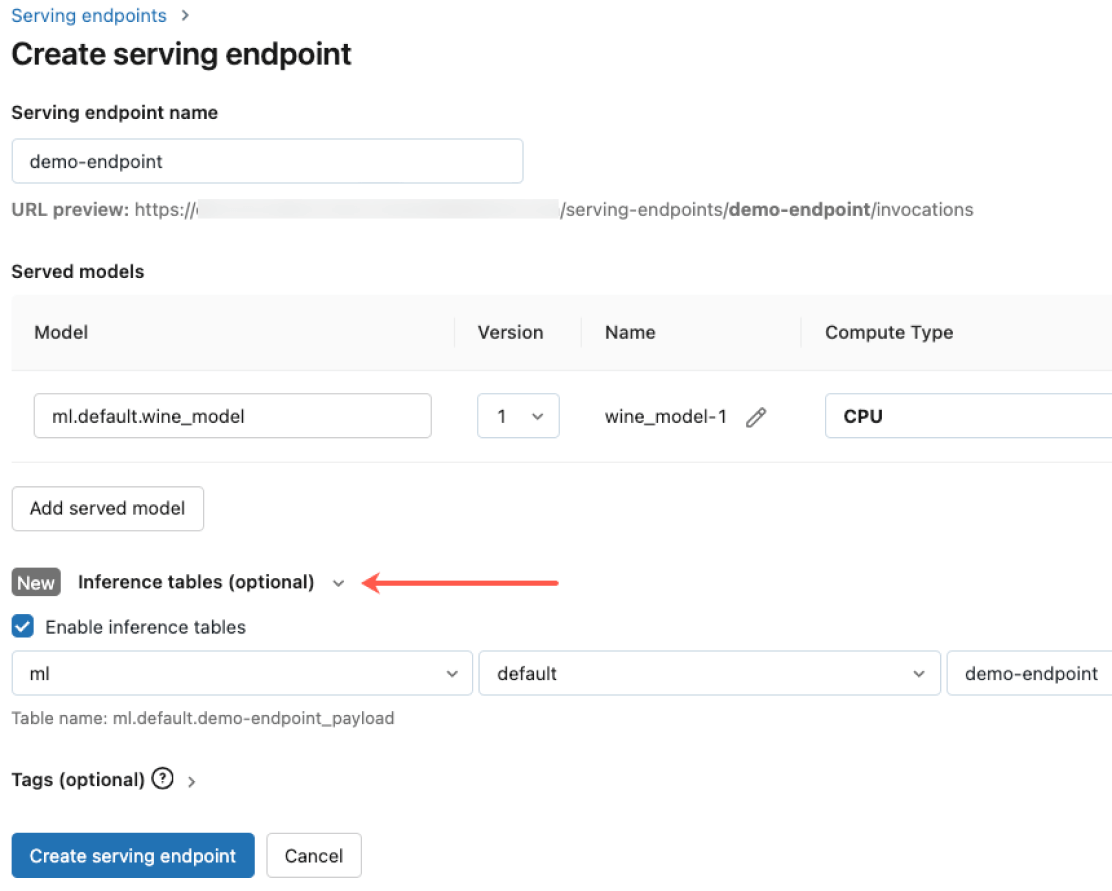
Governance integrata
Si integra con Agent Bricks AI Gateway per soddisfare rigorosi requisiti di sicurezza e avanzate esigenze di governance. Puoi applicare permessi specifici, monitorare la qualità dei modelli, impostare limiti di utilizzo e tracciare la derivazione su tutti i modelli, indipendentemente dal fatto che siano ospitati da Databricks o da altri provider.
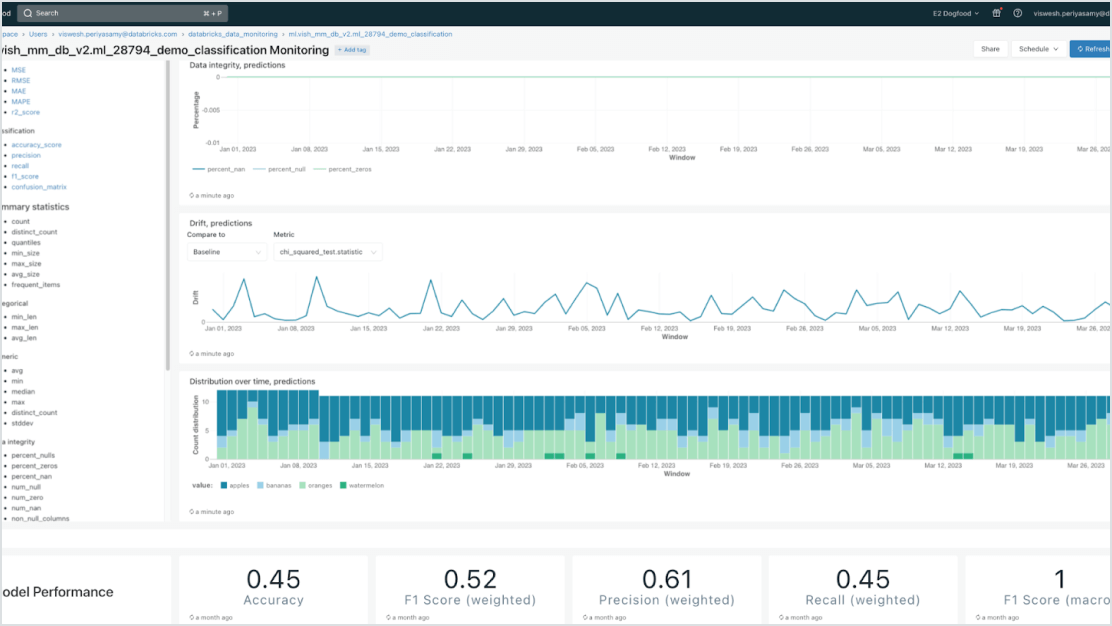
Modelli incentrati sui dati
Accelera le implementazioni e riduci gli errori grazie alla stretta integrazione con la Data Intelligence Platform. Puoi ospitare facilmente vari modelli di ML e AI generativa classici, modelli di generazione aumentata (RAG) o modelli ottimizzati con i dati aziendali. Model Serving offre funzionalità automatizzate di ricerca, monitoraggio e governance lungo tutto il ciclo di vita dell'AI.
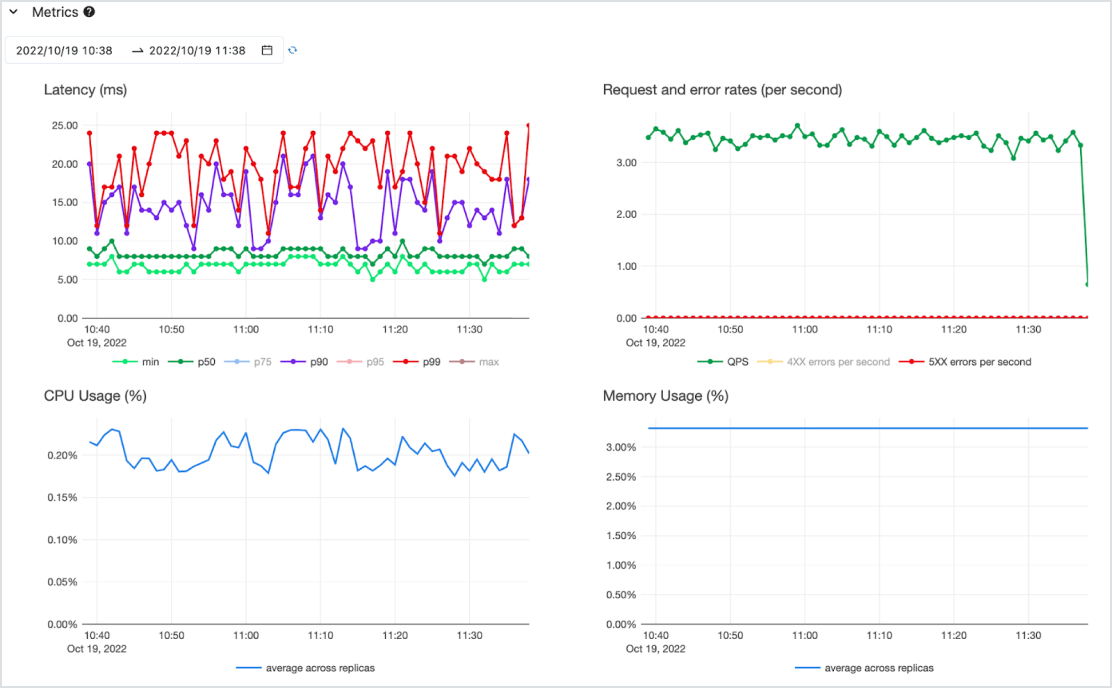
Economicamente vantaggioso
Il model serving può essere eseguito come API a bassa latenza su un servizio serverless ad alta disponibilità con supporto di CPU e GPU. Puoi espandere la soluzione senza fatica partendo da zero per soddisfare le esigenze più critiche (ed eventualmente ridimensionarla). Puoi iniziare a lavorare velocemente con uno o più modelli preinstallati e carichi di lavoro a pagamento (pay-per-token secondo fabbisogno senza impegno o pay-for-provisioned in base alla capacità richiesta) per avere una produttività garantita. Databricks si farà carico della gestione dell'infrastruttura e dei costi di manutenzione, così la tua azienda potrà concentrarsi sulla generazione di valore.