Presentazione di DBRX: un nuovo LLM open source all'avanguardia
Oggi siamo entusiasti di presentare DBRX, un LLM open source general-purpose creato da Databricks. Su una serie di benchmark standard, DBRX stabilisce un nuovo stato dell'arte per gli LLM open source consolidati. Inoltre, fornisce alla community open source e alle aziende che creano i propri LLM capacità precedentemente limitate alle API dei modelli chiusi; secondo le nostre misurazioni, supera GPT-3.5 ed è competitivo con Gemini 1.0 Pro. È un modello di codice particolarmente capace, che supera modelli specializzati come CodeLLaMA-70B nella programmazione, oltre alla sua forza come LLM general-purpose.
Questa qualità all'avanguardia si accompagna a miglioramenti significativi nelle prestazioni di training e inferenza. DBRX fa progredire lo stato dell'arte nell'efficienza tra i modelli open grazie alla sua architettura fine-grained mixture-of-experts (MoE). L'inferenza è fino a 2 volte più veloce di LLaMA2-70B, e DBRX è circa il 40% delle dimensioni di Grok-1 in termini di conteggio totale e attivo dei parametri. Se ospitato su Databricks Model Serving, DBRX può generare testo fino a 150 tok/s/utente. I nostri clienti scopriranno che anche il training di MoE è circa 2 volte più efficiente in termini di FLOP rispetto al training di modelli densi per la stessa qualità finale del modello. Complessivamente, la nostra ricetta per DBRX (inclusi i dati di pretraining, l'architettura del modello e la strategia di ottimizzazione) può eguagliare la qualità dei nostri modelli MPT di generazione precedente con quasi 4 volte meno compute.
I pesi del modello base (DBRX Base) e del modello finetuned (DBRX Instruct) sono disponibili su Hugging Face con una licenza open. A partire da oggi, DBRX è disponibile per i clienti Databricks tramite API, e i clienti Databricks possono pre-addestrare i propri modelli di classe DBRX da zero o continuare l'addestramento partendo da uno dei nostri checkpoint utilizzando gli stessi strumenti e la stessa scienza che abbiamo usato per costruirlo. DBRX è già integrato nei nostri prodotti basati su GenAI, dove - in applicazioni come SQL - i primi rollout hanno superato GPT-3.5 Turbo e stanno sfidando GPT-4 Turbo. È anche un modello leader tra i modelli open e GPT-3.5 Turbo sui task RAG.
Addestrare modelli mixture-of-experts è difficile. Abbiamo dovuto superare una serie di sfide scientifiche e di performance per costruire una pipeline abbastanza robusta da addestrare ripetutamente modelli di classe DBRX in modo efficiente. Ora che ci siamo riusciti, abbiamo uno stack di training unico che consente a qualsiasi azienda di addestrare modelli foundation MoE di livello mondiale da zero. Non vediamo l'ora di condividere questa capacità con i nostri clienti e le nostre lezioni apprese con la community.
Scarica DBRX oggi stesso da Hugging Face (DBRX Base, DBRX Instruct), oppure prova DBRX Instruct nel nostro HF Space, o consulta il nostro repository di modelli su github: databricks/dbrx.
Cos'è DBRX?
DBRX è un modello linguistico di grandi dimensioni (LLM) decoder-only basato su transformer, addestrato utilizzando la predizione del token successivo. Utilizza un'architettura fine-grained mixture-of-experts (MoE) con 132 miliardi di parametri totali di cui 36 miliardi di parametri attivi su qualsiasi input. È stato pre-addestrato su 12 trilioni di token di dati testuali e di codice. Rispetto ad altri modelli MoE open source come Mixtral e Grok-1, DBRX è fine-grained, il che significa che utilizza un numero maggiore di esperti più piccoli. DBRX ha 16 esperti e ne sceglie 4, mentre Mixtral e Grok-1 hanno 8 esperti e ne scelgono 2. Ciò fornisce 65 volte più combinazioni possibili di esperti e abbiamo riscontrato che ciò migliora la qualità del modello. DBRX utilizza rotary position encodings (RoPE), gated linear units (GLU) e grouped query attention (GQA). Utilizza il tokenizer GPT-4 come fornito nel repository tiktoken. Abbiamo fatto queste scelte sulla base di valutazioni esaustive ed esperimenti di scaling.
DBRX è stato pre-addestrato su 12 trilioni di token di dati accuratamente curati e con una lunghezza di contesto massima di 32k token. Stimiamo che questi dati siano almeno 2 volte migliori token per token rispetto ai dati che abbiamo utilizzato per pre-addestrare la famiglia di modelli MPT. Questo nuovo dataset è stato sviluppato utilizzando l'intera suite di strumenti Databricks, tra cui Apache Spark™ e i notebook Databricks per l'elaborazione dei dati, Unity Catalog per la gestione e la governance dei dati, e MLflow per il tracciamento degli esperimenti. Abbiamo utilizzato il curriculum learning per il pre-addestramento, modificando il mix di dati durante l'addestramento in modi che hanno migliorato sostanzialmente la qualità del modello.
Qualità sui Benchmark rispetto ai Modelli Open Leader
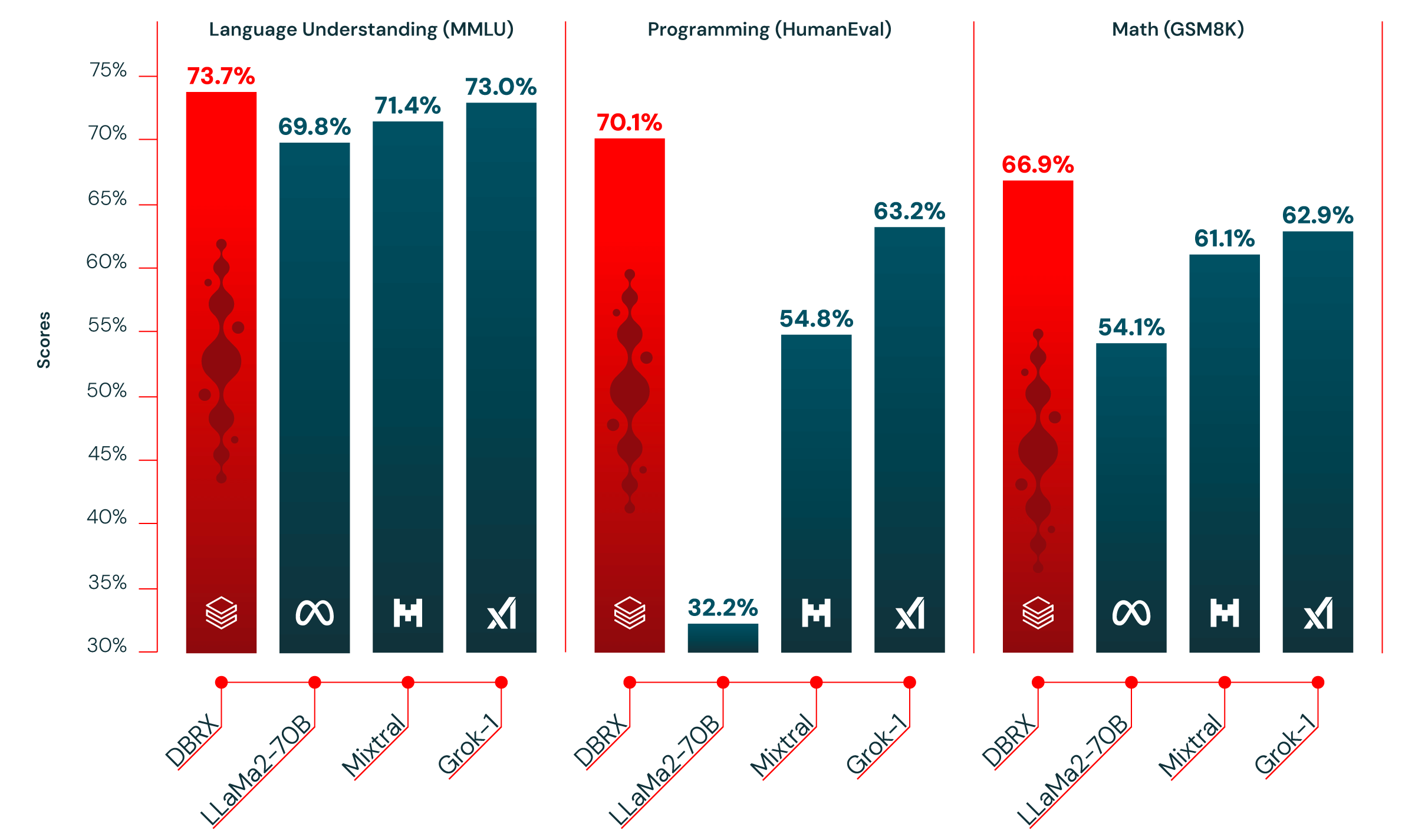
La Tabella 1 mostra la qualità di DBRX Instruct e dei principali modelli open consolidati. DBRX Instruct è il modello leader sui benchmark compositi, sui benchmark di programmazione e matematica, e su MMLU. Supera tutti i modelli chat o instruction finetuned sui benchmark standard.
Benchmark compositi. Abbiamo valutato DBRX Instruct e i suoi pari su due benchmark compositi: l'Hugging Face Open LLM Leaderboard (la media di ARC-Challenge, HellaSwag, MMLU, TruthfulQA, WinoGrande e GSM8k) e il Databricks Model Gauntlet (una suite di oltre 30 task che coprono sei categorie: conoscenza del mondo, ragionamento di senso comune, comprensione del linguaggio, comprensione della lettura, risoluzione di problemi simbolici e programmazione).
Tra i modelli che abbiamo valutato, DBRX Instruct ottiene il punteggio più alto su due benchmark compositi: l'Hugging Face Open LLM Leaderboard (74,5% contro il 72,7% del modello successivo più performante, Mixtral Instruct) e il Databricks Gauntlet (66,8% contro il 60,7% del modello successivo più performante, Mixtral Instruct).
Programmazione e matematica. DBRX Instruct è particolarmente forte nella programmazione e nella matematica. Ottiene punteggi più alti rispetto agli altri modelli open che abbiamo valutato su HumanEval (70,1% contro il 63,2% di Grok-1, il 54,8% di Mixtral Instruct e il 32,2% della variante LLaMA2-70B con le migliori prestazioni) e GSM8k (66,9% contro il 62,9% di Grok-1, il 61,1% di Mixtral Instruct e il 54,1% della variante LLaMA2-70B con le migliori prestazioni). DBRX supera Grok-1, il modello successivo migliore su questi benchmark, nonostante Grok-1 abbia 2,4 volte più parametri. Su HumanEval, DBRX Instruct supera persino CodeLLaMA-70B Instruct, un modello creato specificamente per la programmazione, nonostante DBRX Instruct sia progettato per uso general-purpose (70,1% contro il 67,8% su HumanEval come riportato da Meta nel blog CodeLLaMA).
MMLU. DBRX Instruct ottiene un punteggio più alto di tutti gli altri modelli che consideriamo su MMLU, raggiungendo il 73,7%.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabella 1. Qualità di DBRX Instruct e dei principali modelli open. Vedere le note a piè di pagina per i dettagli su come sono stati raccolti i numeri. In grassetto e sottolineato il punteggio più alto.
Qualità sui Benchmark rispetto ai Modelli Closed Leader
La Tabella 2 mostra la qualità di DBRX Instruct e dei principali modelli closed. Secondo i punteggi riportati da ciascun creatore di modelli, DBRX Instruct supera GPT-3.5 (come descritto nel paper di GPT-4), ed è competitivo con Gemini 1.0 Pro e Mistral Medium.
Su quasi tutti i benchmark considerati, DBRX Instruct supera o, nel peggiore dei casi, eguaglia GPT-3.5. DBRX Instruct supera GPT-3.5 nella conoscenza generale misurata da MMLU (73,7% vs 70,0%) e nel ragionamento di senso comune misurato da HellaSwag (89,0% vs 85,5%) e WinoGrande (81,8% vs 81,6%). DBRX Instruct eccelle in particolare nella programmazione e nel ragionamento matematico misurati da HumanEval (70,1% vs 48,1%) e GSM8k (72,8% vs 57,1%).
DBRX Instruct è competitivo con Gemini 1.0 Pro e Mistral Medium. I punteggi di DBRX Instruct sono superiori a quelli di Gemini 1.0 Pro su Inflection Corrected MTBench, MMLU, HellaSwag e HumanEval, mentre Gemini 1.0 Pro è più forte su GSM8k. I punteggi di DBRX Instruct e Mistral Medium sono simili su HellaSwag, mentre Mistral Medium è più forte su Winogrande e MMLU e DBRX Instruct è più forte su HumanEval, GSM8k e Inflection Corrected MTBench.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabella 2. Qualità di DBRX Instruct e dei principali modelli chiusi. Ad eccezione di Inflection Corrected MTBench (che abbiamo misurato noi stessi sugli endpoint del modello), i numeri sono stati riportati dai creatori di questi modelli nei loro rispettivi whitepaper. Vedere le note a piè di pagina per dettagli aggiuntivi.
Qualità su Task a Contesto Lungo e RAG
DBRX Instruct è stato addestrato con una finestra di contesto fino a 32K token. La Tabella 3 confronta le sue prestazioni con quelle di Mixtral Instruct e delle ultime versioni delle API GPT-3.5 Turbo e GPT-4 Turbo su una suite di benchmark a contesto lungo (KV-Pairs dal paper Lost in the Middle e HotpotQAXL, una versione modificata di HotPotQA che estende il task a sequenze più lunghe). GPT-4 Turbo è generalmente il modello migliore per questi task. Tuttavia, con una sola eccezione, DBRX Instruct ottiene prestazioni migliori di GPT-3.5 Turbo a tutte le lunghezze di contesto e in tutte le parti della sequenza. Le prestazioni complessive di DBRX Instruct e Mixtral Instruct sono simili.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabella 3. Prestazioni medie dei modelli sui benchmark KV-Pairs e HotpotQAXL. Il grassetto indica il punteggio più alto. Il sottolineato indica il punteggio più alto diverso da GPT-4 Turbo. GPT-3.5 Turbo supporta una lunghezza di contesto massima di 16K, quindi non è stato possibile valutarlo a 32K. *Le medie per l'inizio, il centro e la fine della sequenza per GPT-3.5 Turbo includono solo contesti fino a 16K.
Uno dei modi più diffusi per sfruttare il contesto di un modello è la generazione aumentata da recupero (RAG). In RAG, il contenuto pertinente a un prompt viene recuperato da un database e presentato insieme al prompt per fornire al modello maggiori informazioni di quelle che avrebbe altrimenti. La Tabella 4 mostra la qualità di DBRX su due benchmark RAG - Natural Questions e HotPotQA - quando al modello vengono forniti anche i primi 10 passaggi recuperati da un corpus di articoli di Wikipedia utilizzando il modello di embedding bge-large-en-v1.5. DBRX Instruct è competitivo con modelli open come Mixtral Instruct e LLaMA2-70B Chat e con la versione attuale di GPT-3.5 Turbo.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabella 4. Le prestazioni dei modelli misurate quando a ciascun modello vengono forniti i primi 10 passaggi recuperati da un corpus di Wikipedia utilizzando bge-large-en-v1.5. L'accuratezza viene misurata confrontando la risposta del modello. Il grassetto indica il punteggio più alto. Il sottolineato indica il punteggio più alto diverso da GPT-4 Turbo.
Efficienza di addestramento
La qualità del modello deve essere valutata nel contesto di quanto sia efficiente addestrare e utilizzare il modello. Questo è particolarmente vero in Databricks, dove creiamo modelli come DBRX per stabilire un processo per i nostri clienti per addestrare i propri modelli di base.
Abbiamo riscontrato che l'addestramento di modelli mixture-of-experts offre notevoli miglioramenti nell'efficienza computazionale per l'addestramento (Tabella 5). Ad esempio, l'addestramento di un membro più piccolo della famiglia DBRX chiamato DBRX MoE-B (23,5 miliardi di parametri totali, 6,6 miliardi di parametri attivi) ha richiesto 1,7 volte meno FLOP per raggiungere un punteggio del 45,5% sul Databricks LLM Gauntlet rispetto a quanto richiesto da LLaMA2-13B per raggiungere il 43,8%. DBRX MoE-B contiene anche la metà dei parametri attivi rispetto a LLaMA2-13B.
Considerando l'intero processo, la nostra pipeline di pre-addestramento LLM end-to-end è diventata quasi 4 volte più efficiente dal punto di vista computazionale negli ultimi dieci mesi. Il 5 maggio 2023, abbiamo rilasciato MPT-7B, un modello da 7 miliardi di parametri addestrato su 1 trilione di token che ha raggiunto un punteggio Databricks LLM Gauntlet di 30,9%. Un membro della famiglia DBRX chiamato DBRX MoE-A (7,7 miliardi di parametri totali, 2,2 miliardi di parametri attivi) ha raggiunto un punteggio Databricks Gauntlet di 30,5% con 3,7 volte meno FLOP. Questa efficienza è il risultato di una serie di miglioramenti, tra cui l'uso di un'architettura MoE, altre modifiche architetturali alla rete, migliori strategie di ottimizzazione, migliore tokenizzazione e, cosa molto importante, migliori dati di pre-addestramento.
Da soli, dati di pre-addestramento migliori hanno avuto un impatto sostanziale sulla qualità del modello. Abbiamo addestrato un modello da 7B su 1T di token (chiamato DBRX Dense-A) utilizzando i dati di pre-addestramento DBRX. Ha raggiunto il 39,0% sul Databricks Gauntlet rispetto al 30,9% di MPT-7B. Stimiamo che i nostri nuovi dati di pre-addestramento siano almeno 2 volte migliori token per token rispetto ai dati utilizzati per addestrare MPT-7B. In altre parole, stimiamo che siano necessari la metà dei token per raggiungere la stessa qualità del modello. Lo abbiamo determinato addestrando DBRX Dense-A su 500B di token; ha superato MPT-7B sul Databricks Gauntlet, raggiungendo il 32,1%. Oltre alla migliore qualità dei dati, un altro importante contributore a questa efficienza dei token potrebbe essere il tokenizer GPT-4, che ha un vocabolario ampio ed è ritenuto particolarmente efficiente in termini di token. Queste lezioni sul miglioramento della qualità dei dati si traducono direttamente in pratiche e strumenti che i nostri clienti utilizzano per addestrare modelli di base sui propri dati.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabella 5. Dettagli di diversi articoli di test utilizzati per validare l'efficienza di training dell'architettura DBRX MoE e della pipeline di training end-to-end
Efficienza di Inferenza
La Figura 2 mostra l'efficienza di inferenza end-to-end per il serving di DBRX e modelli simili utilizzando NVIDIA TensorRT-LLM con la nostra infrastruttura di serving ottimizzata e precisione a 16 bit. Il nostro obiettivo è che questo benchmark rifletta l'utilizzo reale il più fedelmente possibile, includendo più utenti che accedono contemporaneamente allo stesso server di inferenza. Avviamo un nuovo utente al secondo, ogni richiesta utente contiene un prompt di circa 2000 token e ogni risposta è composta da 256 token.
In generale, i modelli MoE sono più veloci nell'inferenza di quanto suggerirebbe il loro conteggio totale di parametri. Ciò è dovuto al fatto che utilizzano un numero relativamente ridotto di parametri per ogni input. Constatiamo che DBRX non fa eccezione a questo riguardo. Il throughput di inferenza di DBRX è 2-3 volte superiore a quello di un modello non-MoE da 132B.
L'efficienza di inferenza e la qualità del modello sono tipicamente in tensione: modelli più grandi raggiungono generalmente una qualità superiore, ma modelli più piccoli sono più efficienti per l'inferenza. L'utilizzo di un'architettura MoE rende possibile ottenere migliori compromessi tra qualità del modello ed efficienza di inferenza rispetto a quanto i modelli densi tipicamente raggiungono. Ad esempio, DBRX è sia di qualità superiore a LLaMA2-70B, sia - grazie ad avere circa la metà dei parametri attivi - il throughput di inferenza di DBRX è fino a 2 volte più veloce (Figura 2). Mixtral è un altro punto sulla frontiera di Pareto migliorata raggiunta dai modelli MoE: è più piccolo di DBRX, ed è corrispondentemente inferiore in termini di qualità, ma raggiunge un throughput di inferenza più elevato. Gli utenti delle API Databricks Foundation Model possono aspettarsi fino a 150 token al secondo per DBRX sulla nostra piattaforma di serving ottimizzata con quantizzazione a 8 bit.

Come Abbiamo Costruito DBRX
DBRX è stato addestrato su 3072 NVIDIA H100 collegati da 3.2Tbps Infiniband. Il processo principale di costruzione di DBRX - inclusi pre-training, post-training, valutazione, red-teaming e raffinamento - si è svolto nel corso di tre mesi. È stata la continuazione di mesi di ricerca scientifica, ricerca sui dataset ed esperimenti di scaling, per non parlare di anni di sviluppo LLM in Databricks che include i progetti MPT e Dolly e le migliaia di modelli che abbiamo costruito e portato in produzione con i nostri clienti.
Per costruire DBRX, abbiamo sfruttato la stessa suite di strumenti Databricks disponibile per i nostri clienti. Abbiamo gestito e governato i nostri dati di training utilizzando Unity Catalog. Abbiamo esplorato questi dati utilizzando il recentemente acquisito Lilac AI. Abbiamo elaborato e pulito questi dati utilizzando Apache Spark™ e notebook Databricks. Abbiamo addestrato DBRX utilizzando versioni ottimizzate delle nostre librerie di training open-source: MegaBlocks, LLM Foundry, Composer e Streaming. Abbiamo gestito il training e il fine-tuning di modelli su larga scala su migliaia di GPU utilizzando il nostro servizio Databricks Training. Abbiamo registrato i nostri risultati utilizzando MLflow. Abbiamo raccolto feedback umano per miglioramenti di qualità e sicurezza tramite Databricks Model Serving e Inference Tables. Abbiamo sperimentato manualmente con il modello utilizzando il Databricks Playground. Abbiamo trovato gli strumenti Databricks essere best-in-class per ciascuno dei loro scopi, e abbiamo beneficiato del fatto che fossero tutti parte di un'esperienza di prodotto unificata.
Inizia con DBRX su Databricks
Se desideri iniziare subito a lavorare con DBRX, è facile farlo con le API Databricks Foundation Model APIs. Puoi iniziare rapidamente con il nostro prezzo pay-as-you-go e interrogare il modello dalla nostra interfaccia chat AI Playground. Per applicazioni di produzione, offriamo un'opzione di throughput provisionato per fornire garanzie di performance, supporto per modelli finetuned, e sicurezza e conformità aggiuntive. Per ospitare DBRX in privato, puoi scaricare il modello dal Databricks Marketplace e distribuire il modello su Model Serving.
Conclusioni
In Databricks, crediamo che ogni azienda debba avere la capacità di controllare i propri dati e il proprio destino nel mondo emergente della GenAI. DBRX è un pilastro centrale della nostra prossima generazione di prodotti GenAI, e attendiamo con impazienza l'entusiasmante viaggio che attende i nostri clienti mentre sfruttano le capacità di DBRX e gli strumenti che abbiamo utilizzato per costruirlo. Nell'ultimo anno, abbiamo addestrato migliaia di LLM con i nostri clienti. DBRX è solo un esempio dei modelli potenti ed efficienti che vengono costruiti in Databricks per una vasta gamma di applicazioni, dalle funzionalità interne ai casi d'uso ambiziosi per i nostri clienti.
Come per ogni nuovo modello, il viaggio con DBRX è solo l'inizio, e il miglior lavoro sarà fatto da coloro che ci costruiranno sopra: le aziende e la comunità open-source. Questo è anche solo l'inizio del nostro lavoro su DBRX, e dovreste aspettarvi molto di più in futuro.
Contributi
Lo sviluppo di DBRX è stato guidato dal team Mosaic che in precedenza ha costruito la famiglia di modelli MPT, in collaborazione con decine di ingegneri, avvocati, specialisti di procurement e finanza, program manager, marketer, designer e altri collaboratori di Databricks. Siamo grati ai nostri colleghi, amici, familiari e alla comunità per la loro pazienza e il loro supporto negli ultimi mesi.
Nel creare DBRX, ci basiamo sui giganti della community open source e accademica. Rendendo DBRX disponibile apertamente, intendiamo reinvestire nella community con la speranza di costruire insieme tecnologie ancora più grandi in futuro. Tenendo conto di ciò, riconosciamo con gratitudine il lavoro e la collaborazione di Trevor Gale e del suo MegaBlocks project (il relatore del dottorato di Trevor è il CTO di Databricks Matei Zaharia), il team PyTorch e il progetto FSDP, NVIDIA e il progetto TensorRT-LLM, il team e il progetto vLLM, EleutherAI e il loro progetto di valutazione LLM, Daniel Smilkov e Nikhil Thorat presso Lilac AI, e i nostri amici dell'Allen Institute for Artificial Intelligence (AI2).
Informazioni su Databricks
Databricks è l'azienda di Dati e AI. Oltre 10.000 organizzazioni in tutto il mondo — tra cui Comcast, Condé Nast, Grammarly e oltre il 50% delle Fortune 500 — si affidano alla Piattaforma di Intelligenza dei Dati Databricks per unificare e democratizzare dati, analytics e AI. Databricks ha sede a San Francisco, con uffici in tutto il mondo ed è stata fondata dai creatori originali di Lakehouse, Apache Spark™, Delta Lake e MLflow. Per saperne di più, segui Databricks su LinkedIn, X e Facebook.
1 Numeri come riportato da xAI. A causa della mancanza di un checkpoint compatibile con Hugging Face al momento del rilascio, non siamo stati in grado di valutare Grok-1 autonomamente sulla nostra suite completa di benchmark.
2 DBRX è stato misurato da noi utilizzando EleutherAI Harness. Tutti gli altri numeri sono come riportato sulla Hugging Face Open LLM Leaderboard.
3 DBRX è stato misurato da noi utilizzando EleutherAI Harness con lo stesso commit più vecchio utilizzato dalla Hugging Face Open LLM Leaderboard. Tutti gli altri numeri sono come riportato sulla Hugging Face Open LLM Leaderboard. Si noti che utilizzando il commit più recente di EleutherAI Harness, che include diverse correzioni di parsing, il punteggio 5-shot di DBRX su GSM8k sale a 72,8% come riportato nella Tabella 2. Anche LLaMA2-70B Chat sale a 48,4%.
4 Misurato da Databricks utilizzando Gauntlet v0.3.0 in LLM Foundry.
5 Salvo diversa indicazione, misurato da Databricks.
6 Questo numero proviene dal paper Arxiv di Mixtral. Riportiamo questo numero perché è più alto di quello che abbiamo misurato valutando noi stessi il modello (36,7%)
7 Tutti i punteggi come riportato nel paper GPT-4. Non siamo stati in grado di raccogliere Inflection Corrected MTBench perché questa versione di GPT-3.5 non è disponibile. Abbiamo riscontrato che la versione attuale di GPT-3.5 Turbo ha ottenuto un punteggio di 8,58 ± 0,04 su Inflection Corrected MTBench rispetto a 8,39 ± 0,08 per DBRX Instruct.
8 Tutti i punteggi come riportato nel paper GPT-4. Non siamo stati in grado di raccogliere Inflection Corrected MTBench perché questa versione di GPT-4 non è disponibile. Abbiamo riscontrato che la versione attuale di GPT-4 Turbo ha ottenuto un punteggio di 9,27 ± 0,10 su Inflection Corrected MTBench rispetto a 8,39 ± 0,08 per DBRX Instruct.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.