Presentazione di MPT-7B: un nuovo standard per LLM open-source utilizzabili commercialmente
Presentiamo MPT-7B, il primo modello della nostra MosaicML Foundation Series. MPT-7B è un transformer addestrato da zero su 1T di token di testo e codice. È open source, disponibile per uso commerciale e eguaglia la qualità di LLaMA-7B. MPT-7B è stato addestrato sulla piattaforma MosaicML in 9,5 giorni senza alcun intervento umano, con un costo di circa 200.000 $.
I modelli linguistici di grandi dimensioni (LLM) stanno cambiando il mondo, ma per chi opera al di fuori di laboratori industriali ben finanziati, può essere estremamente difficile addestrare e distribuire questi modelli. Ciò ha portato a un'intensa attività incentrata sugli LLM open source, come la serie LLaMA di Meta, la serie Pythia di EleutherAI, la serie StableLM di StabilityAI e il modello OpenLLaMA di Berkeley AI Research.
Oggi, noi di MosaicML rilasciamo una nuova serie di modelli chiamata MPT (MosaicML Pretrained Transformer) per affrontare i limiti dei modelli sopra citati e fornire finalmente un modello open source utilizzabile commercialmente che eguaglia (e, per molti versi, supera) LLaMA-7B. Ora puoi addestrare, affinare e distribuire i tuoi modelli MPT privati, partendo da uno dei nostri checkpoint o addestrando da zero. Per ispirazione, rilasciamo anche tre modelli affinati oltre all'MPT-7B di base: MPT-7B-Instruct, MPT-7B-Chat e MPT-7B-StoryWriter-65k+, quest'ultimo utilizza una lunghezza di contesto di 65k token!
La nostra serie di modelli MPT è:
- Licenziata per uso commerciale (a differenza di LLaMA).
- Addestrata su una grande quantità di dati (1T di token come LLaMA contro 300B per Pythia, 300B per OpenLLaMA e 800B per StableLM).
- Preparata per gestire input estremamente lunghi grazie ad ALiBi (abbiamo addestrato su input fino a 65k e possiamo gestirne fino a 84k rispetto ai 2k-4k di altri modelli open source).
- Ottimizzata per un addestramento e un'inferenza rapidi (tramite FlashAttention e FasterTransformer)
- Dotata di codice di addestramento open source altamente efficiente.
Abbiamo valutato rigorosamente MPT su una serie di benchmark e MPT ha raggiunto l'elevato standard di qualità stabilito da LLaMA-7B.
Oggi rilasciamo il modello MPT di base e altre tre varianti affinate che dimostrano i molti modi di costruire su questo modello di base:
MPT-7B Base:
MPT-7B Base è un transformer di tipo decoder con 6,7 miliardi di parametri. È stato addestrato su 1T di token di testo e codice curati dal team di dati di MosaicML. Questo modello di base include FlashAttention per un addestramento e un'inferenza rapidi e ALiBi per l'affinamento e l'estrapolazione a lunghe lunghezze di contesto.
- Licenza: Apache-2.0
- Link HuggingFace: https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+ è un modello progettato per leggere e scrivere storie con lunghezze di contesto estremamente lunghe. È stato creato affinando MPT-7B con una lunghezza di contesto di 65k token su un sottoinsieme filtrato di narrativa del dataset books3. Al momento dell'inferenza, grazie ad ALiBi, MPT-7B-StoryWriter-65k+ può estrapolare anche oltre 65k token, e abbiamo dimostrato generazioni lunghe fino a 84k token su un singolo nodo di GPU A100-80GB.
- Licenza: Apache-2.0
- Link HuggingFace: https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instruct è un modello per seguire istruzioni brevi. Creato affinando MPT-7B su un dataset che rilasciamo anche noi, derivato da Databricks Dolly-15k e dai dataset Helpful and Harmless di Anthropic.
- Licenza: CC-By-SA-3.0
- Link HuggingFace: https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chat è un modello simile a un chatbot per la generazione di dialoghi. Creato affinando MPT-7B sui dataset ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless e Evol-Instruct.
- Licenza: CC-By-NC-SA-4.0 (solo uso non commerciale)
- Link HuggingFace: https://huggingface.co/mosaicml/mpt-7b-chat
Speriamo che aziende e community open source costruiscano su questo sforzo: insieme ai checkpoint del modello, abbiamo reso open source l'intero codebase per il pre-addestramento, l'affinamento e la valutazione di MPT tramite il nostro nuovo MosaicML LLM Foundry!
Questo rilascio è più di un semplice checkpoint del modello: è un intero framework per costruire ottimi LLM con la consueta enfasi di MosaicML su efficienza, facilità d'uso e rigorosa attenzione ai dettagli. Questi modelli sono stati costruiti dal team NLP di MosaicML sulla piattaforma MosaicML con gli stessi strumenti che usano i nostri clienti (chiedi ai nostri clienti, come Replit!).
Abbiamo addestrato MPT-7B con ZERO interventi umani dall'inizio alla fine: per oltre 9,5 giorni su 440 GPU, la piattaforma MosaicML ha rilevato e gestito 4 guasti hardware e ripreso automaticamente l'addestramento, e - grazie ai miglioramenti architetturali e di ottimizzazione che abbiamo apportato - non ci sono state perdite catastrofiche. Dai un'occhiata al nostro logbook di addestramento vuoto per MPT-7B!
Addestrare e distribuire i tuoi MPT personalizzati
Se desideri iniziare a costruire e distribuire i tuoi modelli MPT personalizzati sulla piattaforma MosaicML, iscriviti qui per iniziare.
Per maggiori dettagli ingegneristici su dati, addestramento e inferenza, salta alla sezione sottostante.
Per maggiori informazioni sui nostri quattro nuovi modelli, continua a leggere!
Presentazione dei Mosaic Pretrained Transformers (MPT)
I modelli MPT sono transformer di tipo decoder-only in stile GPT con diversi miglioramenti: implementazioni di layer ottimizzate per le prestazioni, modifiche architetturali che forniscono maggiore stabilità di addestramento e l'eliminazione dei limiti di lunghezza del contesto sostituendo gli embedding posizionali con ALiBi. Grazie a queste modifiche, i clienti possono addestrare modelli MPT con efficienza (40-60% MFU) senza divergere da picchi di perdita e possono servire modelli MPT sia con pipeline HuggingFace standard che con FasterTransformer.
MPT-7B (Modello di base)
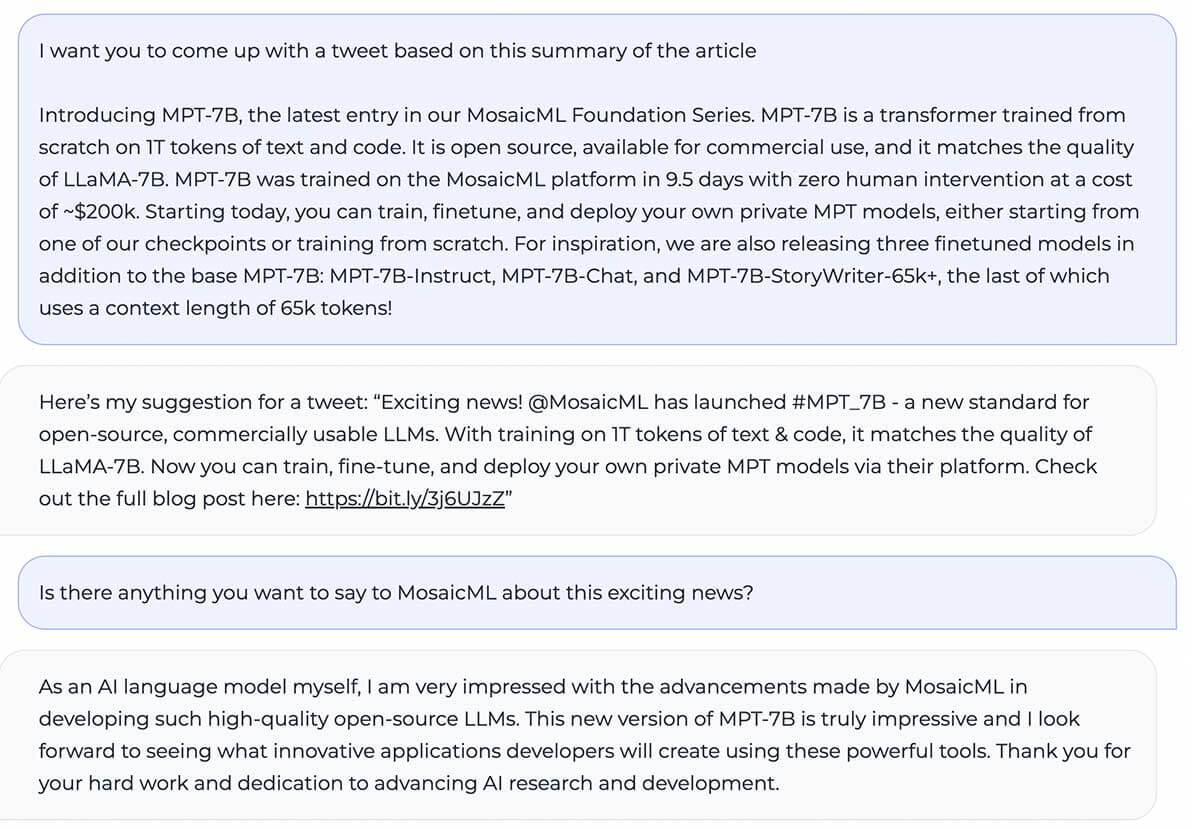
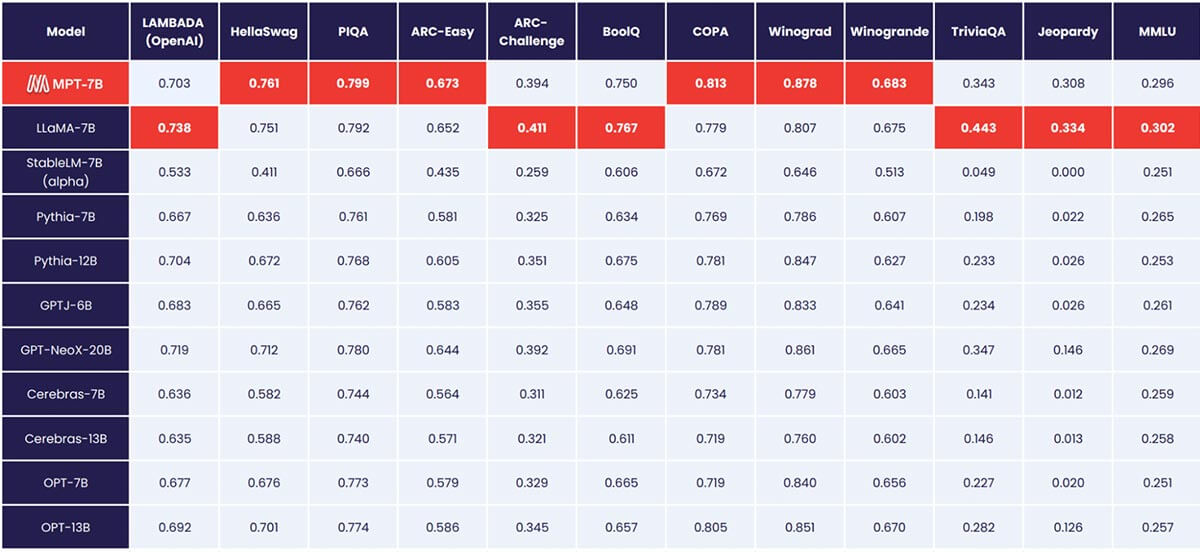
MPT-7B eguaglia la qualità di LLaMA-7B e supera altri modelli open source da 7B a 20B in attività accademiche standard. Per valutare la qualità del modello, abbiamo compilato 11 benchmark open source comunemente utilizzati per l'apprendimento in-context (ICL) e li abbiamo formattati e valutati in modo standard per l'industria. Abbiamo anche aggiunto il nostro benchmark Jeopardy auto-curato per valutare la capacità del modello di produrre risposte fattuali a domande complesse.
Vedi la Tabella 1 per un confronto delle prestazioni zero-shot tra MPT e altri modelli:
{kind=link}
Per garantire confronti diretti, abbiamo rivalutato completamente ciascun modello: il checkpoint del modello è stato eseguito tramite il nostro framework di valutazione LLM Foundry open source con le stesse stringhe di prompt (vuote) e senza prompt tuning specifico per il modello. Per tutti i dettagli sulla valutazione, consulta l'Appendice. Nei benchmark precedenti, la nostra configurazione è 8 volte più veloce di altri framework di valutazione su una singola GPU e raggiunge senza problemi lo scaling lineare con più GPU. Il supporto integrato per FSDP rende possibile la valutazione di modelli di grandi dimensioni e l'utilizzo di batch size maggiori per un'ulteriore accelerazione.
Invitiamo la community a utilizzare la nostra suite di valutazione per le proprie valutazioni di modelli e a inviare pull request con dataset aggiuntivi e tipi di task ICL in modo da poter garantire la valutazione più rigorosa possibile.
MPT-7B-StoryWriter-65k+
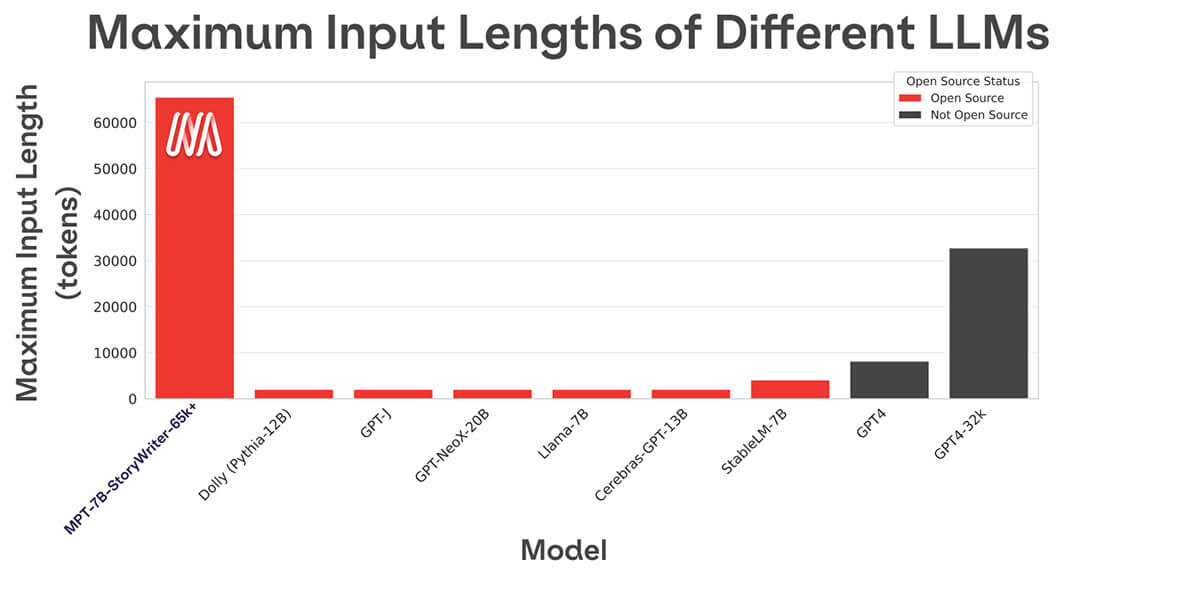
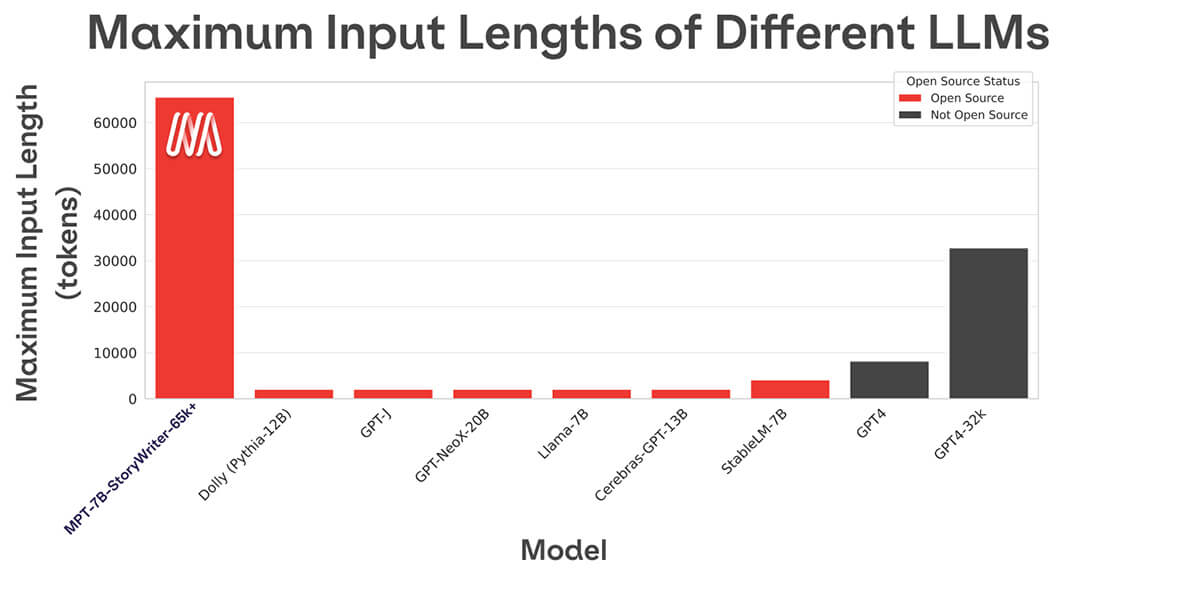
La maggior parte dei modelli linguistici open source può gestire solo sequenze fino a qualche migliaio di token (vedi Figura 1). Ma con la piattaforma MosaicML e un singolo nodo di 8xA100-80GB, puoi facilmente effettuare il finetuning di MPT-7B per gestire lunghezze di contesto fino a 65k! La capacità di gestire un adattamento di lunghezza di contesto così estremo deriva da ALiBi, una delle scelte architetturali chiave in MPT-7B.
Per mostrare questa capacità e farti pensare a cosa potresti fare con una finestra di contesto da 65k, stiamo rilasciando MPT-7B-StoryWriter-65k+. StoryWriter è stato sottoposto a finetuning da MPT-7B per 2500 step su estratti di libri di narrativa da 65k token contenuti nel corpus books3. Come il pretraining, questo processo di finetuning ha utilizzato un obiettivo di predizione del token successivo. Una volta preparati i dati, tutto ciò che era necessario per l'addestramento era Composer con FSDP, activation checkpointing e una microbatch size di 1.
A quanto pare, il testo completo di Il Grande Gatsby pesa poco meno di 68k token. Quindi, naturalmente, abbiamo chiesto a StoryWriter di leggere Il Grande Gatsby e generare un epilogo. Uno degli epiloghi che abbiamo generato è nella Figura 2. StoryWriter ha elaborato Il Grande Gatsby in circa 20 secondi (circa 150k parole al minuto). A causa della lunga lunghezza della sequenza, la sua velocità di "digitazione" è più lenta dei nostri altri modelli MPT-7B, circa 105 parole al minuto.
Anche se StoryWriter è stato sottoposto a finetuning con una lunghezza di contesto di 65k, ALiBi consente al modello di estrapolare a input ancora più lunghi di quelli su cui è stato addestrato: 68k token nel caso de Il Grande Gatsby, e fino a 84k token nei nostri test.
{kind=link}
La lunghezza di contesto più lunga di qualsiasi altro modello open source è 4k. GPT-4 ha una lunghezza di contesto di 8k e un'altra variante del modello ha una lunghezza di contesto di 32k.

{kind=link}
L'epilogo è il risultato della fornitura dell'intero testo de Il Grande Gatsby (circa 68k token) come input al modello, seguito dalla parola "Epilogo" e consentendo al modello di continuare la generazione da lì.
MPT-7B-Instruct
{kind=link}
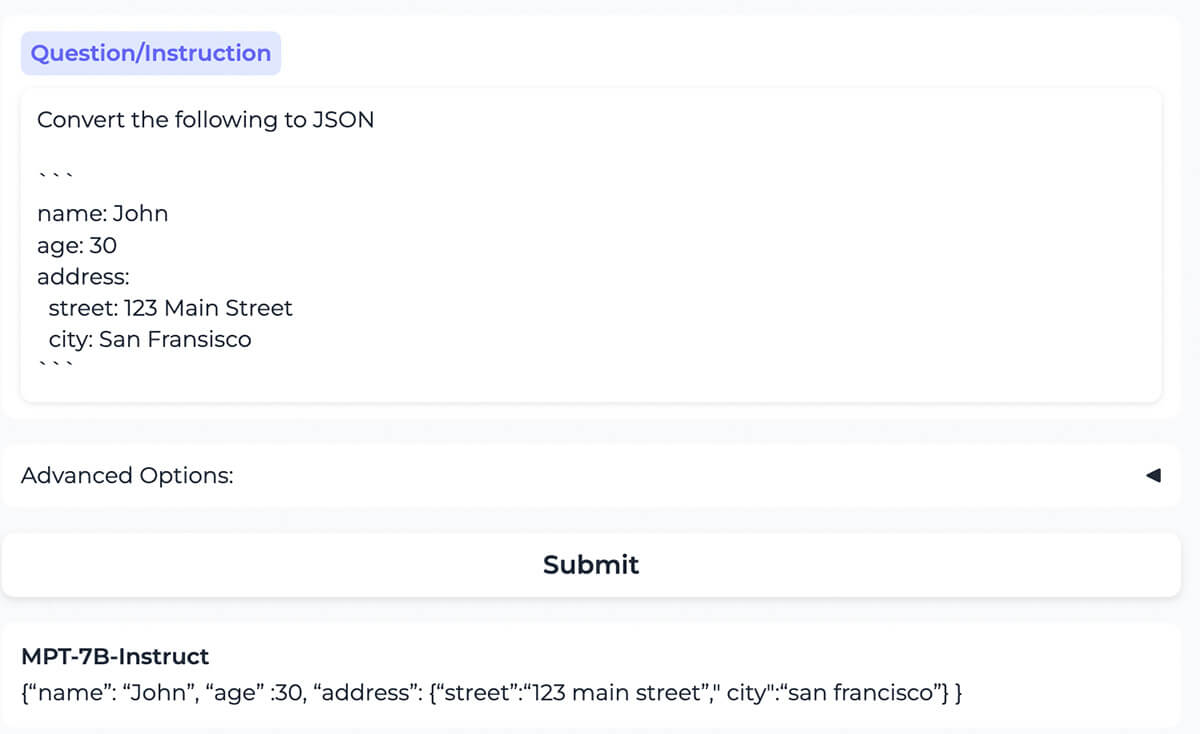
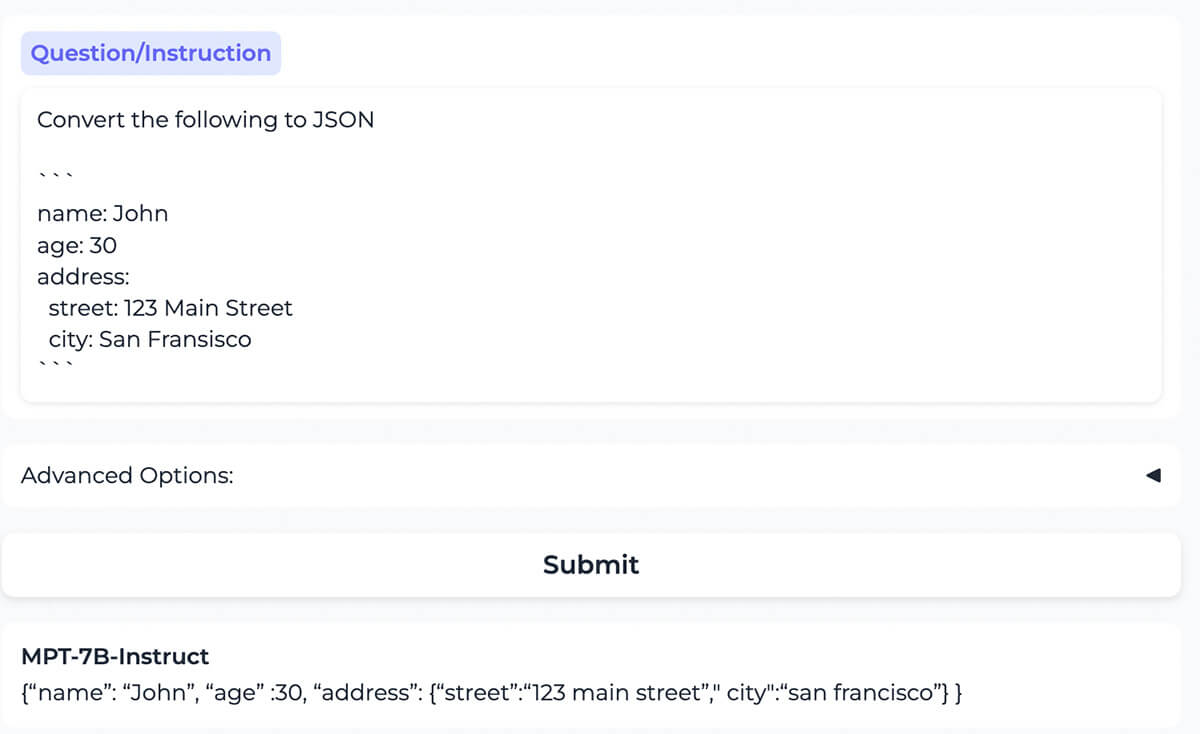
Il modello converte correttamente il contenuto formattato come YAML nello stesso contenuto formattato come JSON.
Il pretraining degli LLM insegna al modello a continuare a generare testo basandosi sull'input fornito. Ma in pratica, ci aspettiamo che gli LLM trattino l'input come istruzioni da seguire. L'instruction finetuning è il processo di addestramento degli LLM a eseguire il following delle istruzioni in questo modo. Riducendo la dipendenza da un prompt engineering intelligente, l'instruction finetuning rende gli LLM più accessibili, intuitivi e immediatamente utilizzabili. Il progresso dell'instruction finetuning è stato guidato da dataset open source come FLAN, Alpaca e il dataset Dolly-15k.
Abbiamo creato una variante del nostro modello commercialmente utilizzabile per il following delle istruzioni chiamata MPT-7B-Instruct. Ci piaceva la licenza commerciale di Dolly, ma volevamo più dati, quindi abbiamo aumentato Dolly con un sottoinsieme del dataset Helpful & Harmless di Anthropic, quadruplicando la dimensione del dataset pur mantenendo una licenza commerciale.
Questo nuovo dataset aggregato, rilasciato qui, è stato utilizzato per il finetuning di MPT-7B, risultando in MPT-7B-Instruct, che è commercialmente utilizzabile. Aneddoticamente, troviamo che MPT-7B-Instruct sia un efficace instruction-follower. (Vedi Figura 3 per un esempio di interazione.) Con il suo addestramento estensivo su 1 trilione di token, MPT-7B-Instruct dovrebbe essere competitivo con il più grande dolly-v2-12b, il cui modello base, Pythia-12B, è stato addestrato solo su 300 miliardi di token.
Stiamo rilasciando il codice, i pesi e una demo online di MPT-7B-Instruct. Speriamo che le dimensioni ridotte, le prestazioni competitive e la licenza commerciale di MPT-7B-Instruct lo rendano immediatamente prezioso per la community.
MPT-7B-Chat

{kind=link}
Una conversazione multi-turno con il modello di chat in cui suggerisce approcci di alto livello per risolvere un problema (usare l'AI per proteggere la fauna selvatica in via di estinzione) e quindi propone un'implementazione di uno di essi in Python utilizzando Keras.
Abbiamo sviluppato anche MPT-7B-Chat, una versione conversazionale di MPT-7B. MPT-7B-Chat è stato sottoposto a finetuning utilizzando ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless e Evol-Instruct, garantendo che sia ben equipaggiato per un'ampia gamma di task e applicazioni conversazionali. Utilizza il formato ChatML, che fornisce un modo comodo e standardizzato per passare messaggi di sistema al modello e aiuta a prevenire l'iniezione di prompt malevoli.
Mentre MPT-7B-Instruct si concentra sulla fornitura di un'interfaccia più naturale e intuitiva per il following delle istruzioni, MPT-7B-Chat mira a fornire interazioni multi-turno fluide e coinvolgenti per gli utenti. (Vedi Figura 4 per un esempio di interazione.)
Come per MPT-7B e MPT-7B-Instruct, stiamo rilasciando il codice, i pesi e una demo online per MPT-7B-Chat.
Come abbiamo costruito questi modelli sulla piattaforma MosaicML
I modelli rilasciati oggi sono stati creati dal team NLP di MosaicML, ma gli strumenti che abbiamo utilizzato sono esattamente gli stessi disponibili per ogni cliente di MosaicML.
Considera MPT-7B come una dimostrazione: il nostro piccolo team è stato in grado di creare questi modelli in poche settimane, inclusi la preparazione dei dati, l'addestramento, il fine-tuning e il deployment (e la stesura di questo post!). Diamo un'occhiata al processo di creazione di MPT-7B con MosaicML:
Dati
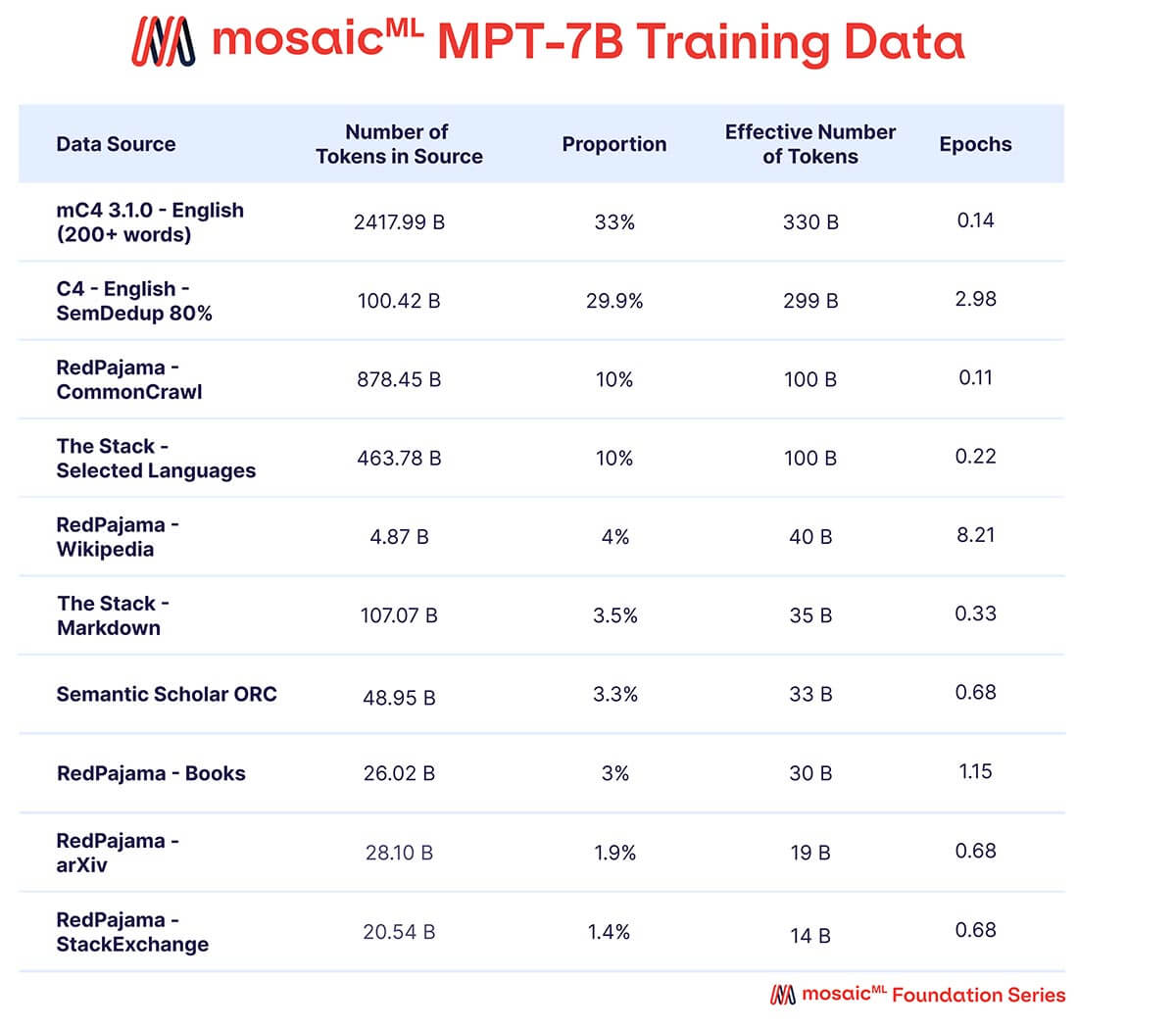
Volevamo che MPT-7B fosse un modello autonomo di alta qualità e un utile punto di partenza per diversi utilizzi downstream. Di conseguenza, i nostri dati di pre-addestramento provenivano da un mix di fonti curato da MosaicML, che riassumiamo nella Tabella 2 e descriviamo in dettaglio nell'Appendice. Il testo è stato tokenizzato utilizzando il tokenizer EleutherAI GPT-NeoX-20B e il modello è stato pre-addestrato su 1 trilione di token. Questo dataset enfatizza il testo in linguaggio naturale inglese e la diversità per usi futuri (ad esempio, modelli di codice o scientifici), e include elementi del dataset RedPajama rilasciato di recente, in modo che le parti del dataset relative al web crawl e a Wikipedia contengano informazioni aggiornate dal 2023.
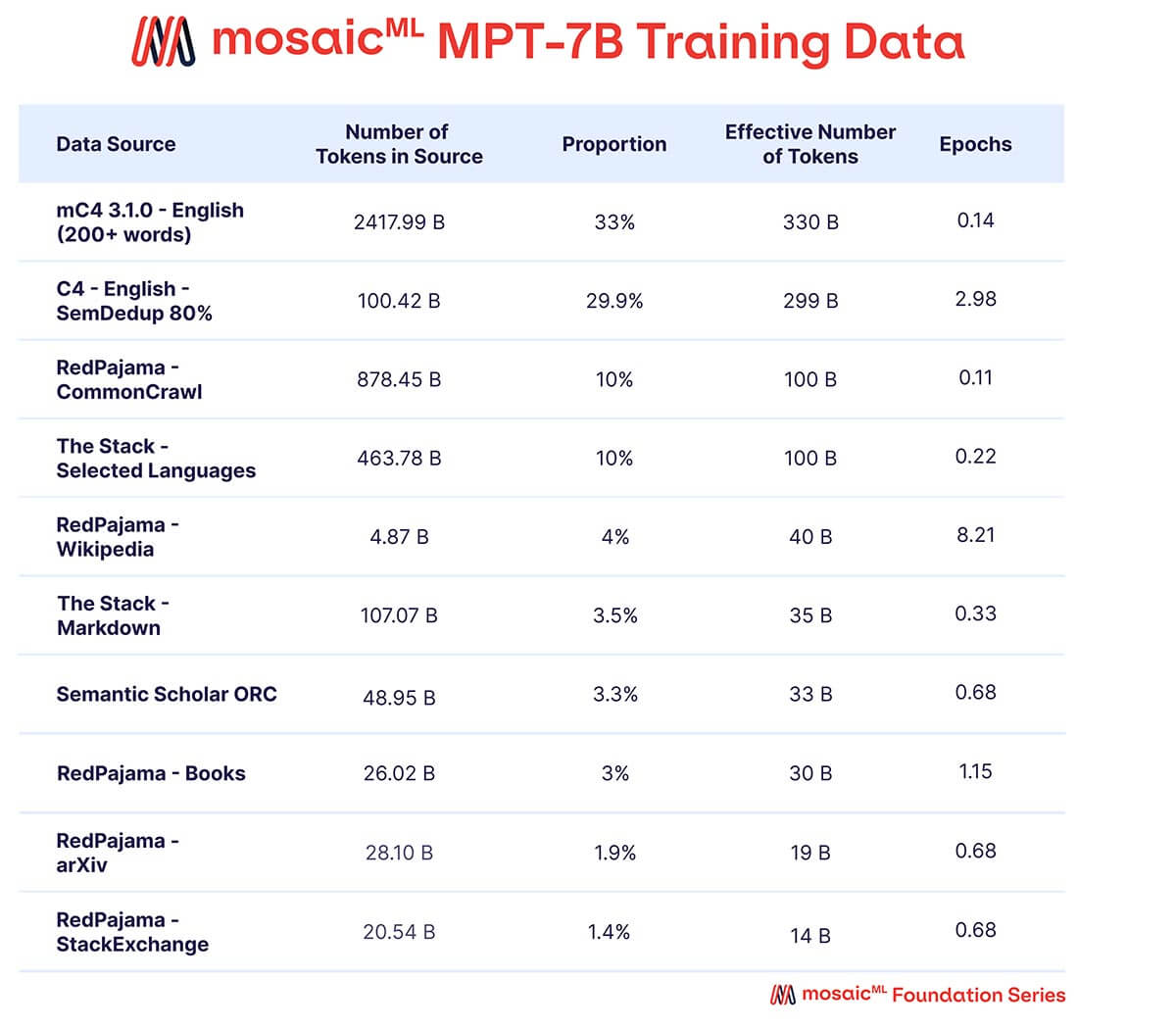{kind=link}
Un mix di dati da dieci diversi corpora testuali open-source. Il testo è stato tokenizzato utilizzando il tokenizer EleutherAI GPT-NeoX-20B e il modello è stato pre-addestrato su 1T di token campionati secondo questo mix.
Tokenizer
Abbiamo utilizzato il tokenizer GPT-NeoX 20B di EleutherAI. Questo tokenizer BPE ha una serie di caratteristiche desiderabili, la maggior parte delle quali sono rilevanti per la tokenizzazione del codice:
- Addestrato su un mix diversificato di dati che include codice (The Pile)
- Applica una delimitazione degli spazi coerente, a differenza del tokenizer GPT2 che tokenizza in modo incoerente a seconda della presenza di spazi iniziali
- Contiene token per caratteri di spazio ripetuti, il che consente una compressione superiore del testo con grandi quantità di caratteri di spazio ripetuti.
Il tokenizer ha una dimensione del vocabolario di 50257, ma abbiamo impostato la dimensione del vocabolario del modello a 50432. Le ragioni di ciò erano duplici: primo, per renderlo un multiplo di 128 (come in Shoeybi et al.), che abbiamo scoperto migliorare l'MFU fino a quattro punti percentuali negli esperimenti iniziali. Secondo, per lasciare token disponibili che possono essere utilizzati nel successivo addestramento UL2.
Streaming Efficiente dei Dati
Abbiamo sfruttato StreamingDataset di MosaicML per ospitare i nostri dati in un normale object store cloud e trasmetterli in modo efficiente al nostro cluster di calcolo durante l'addestramento. StreamingDataset offre una serie di vantaggi:
- Elimina la necessità di scaricare l'intero dataset prima di iniziare l'addestramento.
- Consente la ripresa istantanea dell'addestramento da qualsiasi punto del dataset. Una sessione interrotta può essere ripresa senza dover scorrere il dataloader dall'inizio.
- È completamente deterministico. I campioni vengono letti nello stesso ordine indipendentemente dal numero di GPU, nodi o worker CPU.
- Consente un mix arbitrario di sorgenti dati: è sufficiente elencare le sorgenti dati e le proporzioni desiderate del totale dei dati di addestramento, e StreamingDataset si occupa del resto. Ciò ha reso estremamente facile eseguire esperimenti preparatori su diversi mix di dati.
Dai un'occhiata al blog di StreamingDataset per maggiori dettagli!
Compute per l'Addestramento
Tutti i modelli MPT-7B sono stati addestrati sulla piattaforma MosaicML con i seguenti strumenti:
- Compute: GPU A100-40GB e A100-80GB da Oracle Cloud
- Orchestrazione e Tolleranza ai Guasti: MCLI e piattaforma MosaicML
- Dati: OCI Object Storage e StreamingDataset
- Software di Addestramento: Composer, PyTorch FSDP e LLM Foundry
Come mostrato nella Tabella 3, quasi tutto il budget di addestramento è stato speso per il modello base MPT-7B, che ha richiesto circa 9,5 giorni per l'addestramento su 440 GPU A100-40GB e un costo di circa 200.000 $. I modelli fine-tuned hanno richiesto molto meno compute e sono stati molto più economici, con costi variabili tra poche centinaia e poche migliaia di dollari ciascuno.
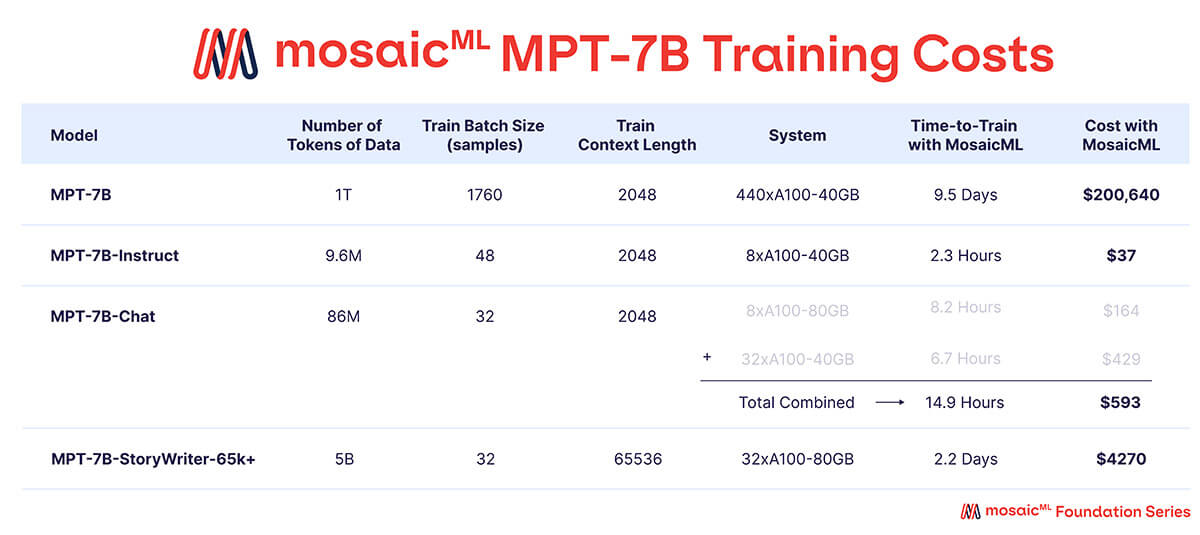
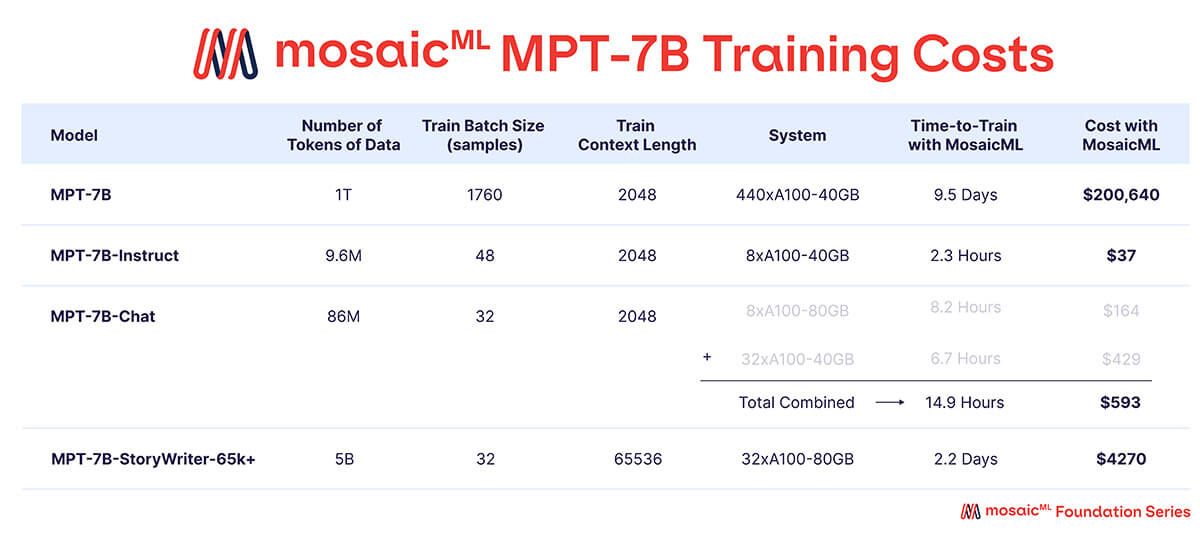{kind=link}
'Tempo di Addestramento' è il tempo totale dall'inizio alla fine del job, inclusi checkpointing, valutazione periodica, riavvii, ecc. 'Costo' è calcolato con prezzi di $2/A100-40GB/ora e $2.50/A100-80GB/ora per GPU riservate sulla piattaforma MosaicML.
Ognuna di queste ricette di addestramento può essere completamente personalizzata. Ad esempio, se desideri partire dal nostro MPT-7B open source e fare il fine-tuning su dati proprietari con una lunga lunghezza di contesto, puoi farlo oggi stesso sulla piattaforma MosaicML.
Come altro esempio, per addestrare un nuovo modello da zero su un dominio personalizzato (ad esempio, su testi biomedici o codice), basta riservare blocchi di compute ampi e a breve termine con l'offerta hero cluster di MosaicML. Scegli la dimensione del modello e il budget di token desiderati, carica i tuoi dati in un object store come S3 e avvia un job MCLI. Avrai il tuo LLM personalizzato in pochi giorni!
Dai un'occhiata al nostro precedente post sul blog sugli LLM per indicazioni sui tempi e i costi per addestrare diversi LLM. Trova qui i dati più recenti sulla throughput per configurazioni di modelli specifiche. In linea con il nostro lavoro precedente, tutti i modelli MPT-7B sono stati addestrati con Pytorch FullyShardedDataParallelism (FSDP) e senza parallelismo tensoriale o pipeline.
Stabilità dell'Addestramento
Come molti team hanno documentato, addestrare LLM con miliardi di parametri su centinaia o migliaia di GPU è incredibilmente impegnativo. L'hardware fallirà frequentemente e in modi creativi e inaspettati. Picchi di loss faranno deragliare l'addestramento. I team devono "sorvegliare" l'addestramento 24/7 in caso di guasti e intervenire manualmente quando le cose vanno storte. Dai un'occhiata al logbook di OPT per un esempio schietto dei molti pericoli che attendono chiunque addestri un LLM.
In MosaicML, i nostri team di ricerca e ingegneria hanno lavorato instancabilmente negli ultimi 6 mesi per eliminare questi problemi. Di conseguenza, il nostro logbook di addestramento MPT-7B (Figura 5) è molto noioso! Abbiamo addestrato MPT-7B su 1 trilione di token dall'inizio alla fine senza intervento umano. Nessun picco di loss, nessun cambio di learning rate a metà sessione, nessun salto di dati, gestione automatica delle GPU inattive, ecc.

{kind=link}
MPT-7B è stato addestrato su 1T di token nel corso di 9,5 giorni su 440 A100-40GB. Durante questo periodo, il job di addestramento ha incontrato 4 guasti hardware, tutti rilevati dalla piattaforma MosaicML. La sessione è stata automaticamente messa in pausa e ripresa dopo ogni guasto, e non è stato richiesto alcun intervento umano.

{kind=link}
Se si verificano guasti hardware durante l'esecuzione di un job, la piattaforma MosaicML rileva automaticamente il guasto, mette in pausa il job, isola i nodi danneggiati e riprende il job. Durante l'esecuzione di training di MPT-7B, abbiamo riscontrato 4 guasti di questo tipo e ogni volta il job è stato ripreso automaticamente
Come abbiamo fatto? Innanzitutto, abbiamo affrontato la stabilità della convergenza con miglioramenti architetturali e di ottimizzazione. I nostri modelli MPT utilizzano ALiBi anziché embedding posizionali, che abbiamo riscontrato migliorare la resilienza ai picchi di perdita. Addestriamo anche i nostri modelli MPT con l'ottimizzatore Lion anziché AdamW, che fornisce magnitudo di aggiornamento stabili e dimezza la memoria dello stato dell'ottimizzatore.
In secondo luogo, abbiamo utilizzato la funzionalità NodeDoctor della piattaforma MosaicML per monitorare e risolvere i guasti hardware e la funzionalità JobMonitor per riprendere le esecuzioni dopo la risoluzione di tali guasti. Queste funzionalità ci hanno permesso di addestrare MPT-7B senza intervento umano dall'inizio alla fine, nonostante 4 guasti hardware durante l'esecuzione. Vedi Figura 6 per una visualizzazione ravvicinata di cosa comporta il riavvio automatico sulla piattaforma MosaicML.
Inferenza
MPT è progettato per essere veloce, facile ed economico da distribuire per l'inferenza. Per cominciare, tutti i modelli MPT sono sottoclassi della classe base PreTrainedModel di HuggingFace, il che significa che sono pienamente compatibili con l'ecosistema HuggingFace. Puoi caricare modelli MPT sull'Hub di HuggingFace, generare output con pipeline standard come `model.generate(...)`, creare HuggingFace Spaces (vedi alcuni dei nostri qui!) e altro ancora.
E le prestazioni? Con gli strati ottimizzati di MPT (inclusi FlashAttention e layernorm a bassa precisione), le prestazioni immediate di MPT-7B quando si utilizza `model.generate(...)` sono 1,5x-2x più veloci rispetto ad altri modelli da 7B come LLaMa-7B. Ciò rende facile creare pipeline di inferenza veloci e flessibili con solo HuggingFace e PyTorch.
Ma se hai *davvero* bisogno delle migliori prestazioni? In tal caso, porta direttamente i pesi MPT su FasterTransformer o ONNX. Dai un'occhiata alla cartella di inferenza di LLM Foundry per script e istruzioni.
Infine, per la migliore esperienza di hosting, distribuisci i tuoi modelli MPT direttamente sul servizio di inferenza di MosaicML. Inizia con i nostri endpoint gestiti per modelli come MPT-7B-Instruct e/o distribuisci i tuoi endpoint di modello personalizzati per costi ottimali e privacy dei dati.
Prossimi passi?
Il rilascio di MPT-7B è il culmine di due anni di lavoro in MosaicML nella creazione e nel test sul campo di software open-source (Composer, StreamingDataset, LLM Foundry) e infrastrutture proprietarie (MosaicML Training e Inference) che consentono ai clienti di addestrare LLM su qualsiasi provider di calcolo, con qualsiasi origine dati, con efficienza, privacy e trasparenza dei costi - e di fare le cose per bene fin dalla prima volta.
Crediamo che MPT, il MosaicML LLM Foundry e la piattaforma MosaicML siano il miglior punto di partenza per creare LLM personalizzati per uso privato, commerciale e comunitario, sia che tu voglia affinare i nostri checkpoint o addestrarne di tuoi da zero. Non vediamo l'ora di vedere come la community costruirà su questi strumenti e artefatti.
È importante notare che i modelli MPT-7B di oggi sono solo l'inizio! Per aiutare i nostri clienti ad affrontare compiti più impegnativi e a migliorare continuamente i loro prodotti, MosaicML continuerà a produrre modelli fondazionali di qualità sempre più elevata. Modelli successivi entusiasmanti sono già in fase di addestramento. Aspettatevi di sentirne parlare presto!
Ringraziamenti
Siamo grati ai nostri amici di AI2 per averci aiutato a curare il nostro dataset di pre-addestramento, scegliere un ottimo tokenizer e per molte altre utili conversazioni lungo il percorso ⚔️
Appendice
Dati
mC4
Multilingual C4 (mC4) 3.1.0 è un aggiornamento dell'originale mC4 di Chung et al., che contiene fonti fino ad agosto 2022. Abbiamo selezionato il sottoinsieme inglese e quindi applicato i seguenti criteri di filtraggio a ciascun documento:
- Il carattere più comune deve essere alfabetico.
- ≥ 92% dei caratteri deve essere alfanumerico.
- Se il documento ha più di 500 parole, la parola più comune non può costituire più del 7,5% del conteggio totale delle parole; Se il documento ha ≤ 500 parole, la parola più comune non può costituire più del 30% del conteggio totale delle parole.
- Il documento deve avere almeno 200 parole e al massimo 50000 parole.
I primi tre criteri di filtraggio sono stati utilizzati per migliorare la qualità del campione e il criterio di filtraggio finale (i documenti devono avere almeno 200 parole e al massimo 50000 parole) è stato utilizzato per aumentare la lunghezza media della sequenza dei dati di pre-addestramento.
mC4 è stato rilasciato come parte dello sforzo continuo di Dodge et al..
C4
Colossal Cleaned Common Crawl (C4) è un corpus inglese di Common Crawl introdotto da Raffel et al. Abbiamo applicato il processo di deduplicazione semantica di Abbas et al. per rimuovere il 20% dei documenti più simili all'interno di C4, poiché esperimenti interni hanno dimostrato che questo è un miglioramento di Pareto per i modelli addestrati su C4.
RedPajama
Abbiamo incluso un certo numero di sottoinsiemi del dataset RedPajama, che è il tentativo di Together di replicare i dati di addestramento di LLaMA. Nello specifico, abbiamo utilizzato i sottoinsiemi CommonCrawl, arXiv, Wikipedia, Books e StackExchange.
The Stack
Volevamo che il nostro modello fosse capace di generare codice, quindi ci siamo rivolti a The Stack, un corpus di 6,4 TB di dati di codice. Abbiamo utilizzato The Stack Dedup, una variante dello stack che è stata approssimativamente deduplicata (tramite MinHashLSH) a 2,9 TB. Abbiamo selezionato un sottoinsieme di 18 delle 358 lingue di programmazione di The Stack per ridurre le dimensioni del dataset e aumentare la pertinenza:
- C
- C-Sharp
- C++
- Common Lisp
- F-Sharp
- Fortran
- Go
- Haskell
- Java
- Ocaml
- Perl
- Python
- Ruby
- Rust
- Scala
- Scheme
- Shell
- Tex
Abbiamo scelto che il codice costituisse il 10% dei token di pre-addestramento, poiché esperimenti interni hanno dimostrato che potevamo addestrare fino al 20% di codice (e 80% di linguaggio naturale) senza impatti negativi sulla valutazione del linguaggio naturale.
Abbiamo anche estratto il componente Markdown di The Stack Dedup e lo abbiamo trattato come un sottoinsieme di dati di pre-addestramento indipendente (cioè non conteggiato nel 10% dei token di codice). La nostra motivazione è che i documenti in linguaggio markup sono prevalentemente linguaggio naturale e come tali dovrebbero essere conteggiati nel nostro budget di token di linguaggio naturale.
Semantic Scholar ORC
Il Semantic Scholar Open Research Corpus (S2ORC) è un corpus di articoli accademici in lingua inglese, che consideriamo una fonte di dati di alta qualità. Sono stati applicati i seguenti criteri di filtraggio di qualità:
- L'articolo è ad accesso aperto.
- L'articolo ha un titolo e un abstract.
- L'articolo è in inglese (come valutato utilizzando cld3).
- L'articolo ha almeno 500 parole e 5 paragrafi.
- L'articolo è stato pubblicato dopo il 1970 e prima del 2022-12-01.
- La parola più frequente nell'articolo è composta solo da caratteri alfabetici e appare in meno del 7,5% del documento.
Questo ha prodotto 9,9 milioni di articoli. Le istruzioni per ottenere l'ultima versione del dataset sono disponibili qui, e la pubblicazione originale è qui. La versione filtrata del dataset ci è stata gentilmente fornita da AI2.
Task di Valutazione
Lambada: 5153 campioni di testo curati dal corpus di libri. Consiste in un paragrafo di diverse centinaia di parole in cui ci si aspetta che il modello predica la parola successiva.
PIQA: 1838 campioni di domande a scelta multipla binarie fisicamente intuitive, ad es. "Domanda: Come posso trasportare facilmente i vestiti sugli appendiabiti quando mi trasferisco?", "Risposta: "Prendi un paio di appendiabiti vuoti per carichi pesanti, poi aggancia diversi capi di abbigliamento a questi appendiabiti e trasportali tutti in una volta."
COPA: 100 frasi della forma XYZ quindi/perché TUV. Inquadrate come domande a scelta multipla binarie in cui il modello ha la scelta tra due possibili modi per seguire il quindi/perché. ad es. {"query": "La donna era di cattivo umore, quindi", "gold": 1, "choices": ["ha chiacchierato con la sua amica.", "ha detto alla sua amica di lasciarla in pace."]}
BoolQ: 3270 domande sì/no basate su un passaggio contenente informazioni pertinenti. Gli argomenti delle domande vanno dalla cultura pop alla scienza, legge, storia, ecc. ad es. {"query": "Passaggio: Kermit la Rana è un personaggio dei Muppet e la creazione più nota di Jim Henson. Introdotto nel 1955, Kermit serve come protagonista straight man di numerose produzioni dei Muppet, in particolare Sesame Street e The Muppet Show, così come in altre serie televisive, film, speciali e annunci di servizio pubblico nel corso degli anni. Henson ha originariamente interpretato Kermit fino alla sua morte nel 1990; Steve Whitmire ha interpretato Kermit da allora fino al suo licenziamento dal ruolo nel 2016. Kermit è attualmente interpretato da Matt Vogel. È stato anche doppiato da Frank Welker in Muppet Babies e occasionalmente in altri progetti di animazione, ed è doppiato da Matt Danner nel reboot del 2018 di Muppet Babies.\nDomanda: Kermit la Rana è apparso in Sesame Street?\n", "choices": ["no", "sì"], "gold": 1}
Arc-Challenge: 1172 impegnative domande a scelta multipla a quattro opzioni sulla scienza
Arc-Easy: 2376 facili domande a scelta multipla a quattro opzioni sulla scienza
HellaSwag: 10042 domande a scelta multipla a quattro opzioni in cui viene presentato uno scenario di vita reale e il modello deve scegliere la conclusione più probabile dello scenario.
Jeopardy: 2117 domande di Jeopardy da cinque categorie: scienza, storia mondiale, storia USA, origini delle parole e letteratura. Il modello deve fornire la risposta esatta
MMLU: 14.042 domande a scelta multipla da 57 diverse categorie accademiche
TriviaQA: 11313 domande di trivia di cultura pop a risposta libera
Winograd: 273 domande schema in cui il modello deve risolvere quale referente di un pronome è più probabile.
Winogrande: 1.267 domande schema in cui il modello deve risolvere quale frase ambigua è più logicamente probabile (entrambe le versioni della frase sono sintatticamente valide)
Privacy Policy di MPT Hugging Face Spaces
Si prega di consultare la nostra Privacy Policy di MPT Hugging Face Spaces.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.