Rilevamento del bias dei dati con SHAP e machine learning
Cosa il Machine Learning e SHAP possono dirci sulla relazione tra gli stipendi degli sviluppatori e il divario retributivo di genere
di Sean Owen
Prova il notebook Detecting Data Bias Using SHAP per riprodurre i passaggi descritti di seguito e guarda il nostro webinar on-demand per saperne di più.
Il sondaggio annuale per sviluppatori di StackOverflow si è concluso all'inizio di quest'anno e i risultati (anonimizzati) del 2019 sono stati gentilmente pubblicati per l'analisi. Offrono una visione dettagliata dell'esperienza degli sviluppatori di software in tutto il mondo: qual è il loro editor preferito? quanti anni di esperienza? tabulazioni o spazi? e, soprattutto, lo stipendio. Gli stipendi degli ingegneri del software sono buoni e a volte sia esorbitanti che degni di nota.
Anche il settore tecnologico è dolorosamente consapevole di non essere sempre all'altezza dei suoi presunti ideali meritocratici. La retribuzione non è una pura funzione del merito e innumerevoli storie ci dicono che fattori come una scuola di prestigio, l'età, l'etnia e il genere influenzano i risultati come lo stipendio.
Il machine learning può fare di più che semplici previsioni? Può spiegare gli stipendi e quindi evidenziare i casi in cui questi fattori potrebbero causare in modo indesiderato differenze retributive? Questo esempio illustrerà come i modelli standard possono essere integrati con SHAP (SHapley Additive exPlanations) per rilevare singole istanze le cui previsioni possono destare preoccupazione, per poi analizzare più a fondo le ragioni specifiche per cui i dati portano a tali previsioni.
Bias del modello o bias dei dati?
Sebbene questo argomento sia spesso definito come il rilevamento del "bias del modello", un modello è semplicemente uno specchio dei dati su cui è stato addestrato. Se il modello è "distorto", significa che ha appreso tale distorsione dai fatti storici presenti nei dati. I modelli non sono il problema in sé; sono un'opportunità per analizzare i dati alla ricerca di prove di bias.
Spiegare i modelli non è una novità e la maggior parte delle librerie può valutare l'importanza relativa degli input per un modello. Si tratta di viste aggregate degli effetti degli input. Tuttavia, l'output di alcuni modelli di machine learning ha effetti molto individuali: il tuo prestito è stato approvato? Riceverai un aiuto finanziario? Sei un viaggiatore sospetto?
Infatti, StackOverflow offre un pratico calcolatore per stimare la retribuzione prevista, sulla base del suo sondaggio. Possiamo solo fare supposizioni su quanto siano accurate le previsioni nel complesso, ma tutto ciò che interessa in particolare a uno sviluppatore sono le proprie prospettive.
La domanda giusta potrebbe non essere: i dati suggeriscono un bias complessivo? bensì: i dati mostrano singoli casi di bias?
Valutazione dei dati del sondaggio di StackOverflow
I dati del 2019 sono, per fortuna, puliti e privi di problemi. Contiene le risposte a 85 domande di circa 88.000 sviluppatori.
Questo esempio si concentra solo sugli sviluppatori a tempo pieno. Il set di dati contiene molte informazioni pertinenti, come anni di esperienza, istruzione, ruolo e informazioni demografiche. In particolare, questo set di dati non contiene informazioni su bonus e azioni, ma solo sullo stipendio.
Contiene anche risposte a domande ad ampio raggio sulle opinioni relative alla blockchain, al fizz buzz e al sondaggio stesso. Questi vengono qui esclusi poiché è improbabile che riflettano l'esperienza e le competenze che presumibilmente dovrebbero determinare la retribuzione. Allo stesso modo, per semplicità, ci si concentrerà solo sugli sviluppatori con sede negli Stati Uniti.
I dati richiedono un'ulteriore trasformazione prima della modellazione. Diverse domande consentono risposte multiple, come "Quali sono le maggiori sfide per la tua produttività come sviluppatore?" Queste singole domande generano più risposte sì/no e devono essere suddivise in più feature sì/no.
Alcune domande a scelta multipla come "Approssimativamente quante persone sono impiegate dall'azienda o dall'organizzazione per cui lavori?" consentire risposte come "2-9 dipendenti". Questi sono a tutti gli effetti valori continui suddivisi in bin e potrebbe essere utile rimapparli a valori continui inferiti come "2", in modo che il modello possa considerarne l'ordine e la grandezza relativa. Purtroppo, questa traduzione è manuale e comporta alcune valutazioni discrezionali.
Il codice Apache Spark che consente di eseguire questa operazione si trova nel notebook allegato, per gli interessati.
Selezione del modello con Apache Spark
Con i dati in un formato più adatto al machine learning, il passo successivo è addestrare un modello di regressione che preveda lo stipendio a partire da queste feature. Il set di dati stesso, dopo il filtraggio e la trasformazione con Spark, è di soli 4 MB, contiene 206 feature di circa 12.600 sviluppatori e potrebbe essere facilmente caricato in memoria come DataFrame su uno smartwatch, per non parlare di un server.
xgboost, un popolare pacchetto di alberi con boosting del gradiente, può adattare un modello a questi dati in pochi minuti su una singola macchina, senza Spark. xgboost offre molti "iperparametri" regolabili che influiscono sulla qualità del modello: profondità massima, tasso di apprendimento, regolarizzazione e così via. Invece di tirare a indovinare, la semplice prassi standard consiste nel provare molte impostazioni di questi valori e scegliere la combinazione che si traduce nel modello più accurato.
Fortunatamente, è qui che Spark rientra in gioco. Può creare centinaia di questi modelli in parallelo e raccogliere i risultati di ciascuno. Poiché il set di dati è di piccole dimensioni, è semplice trasmetterlo ai worker, creare una serie di combinazioni di tali iperparametri da provare e usare Spark per applicare ai dati, con ogni combinazione, lo stesso semplice codice xgboost non distribuito che potrebbe creare un modello localmente.
Questo creerà molti modelli. Per tracciare e valutare i risultati, mlflow può loggare ciascuno di essi con le relative metriche e iperparametri e visualizzarli nell'Experiment del Notebook. Qui, un iperparametro su più esecuzioni viene confrontato con l'accuratezza risultante (errore assoluto medio):
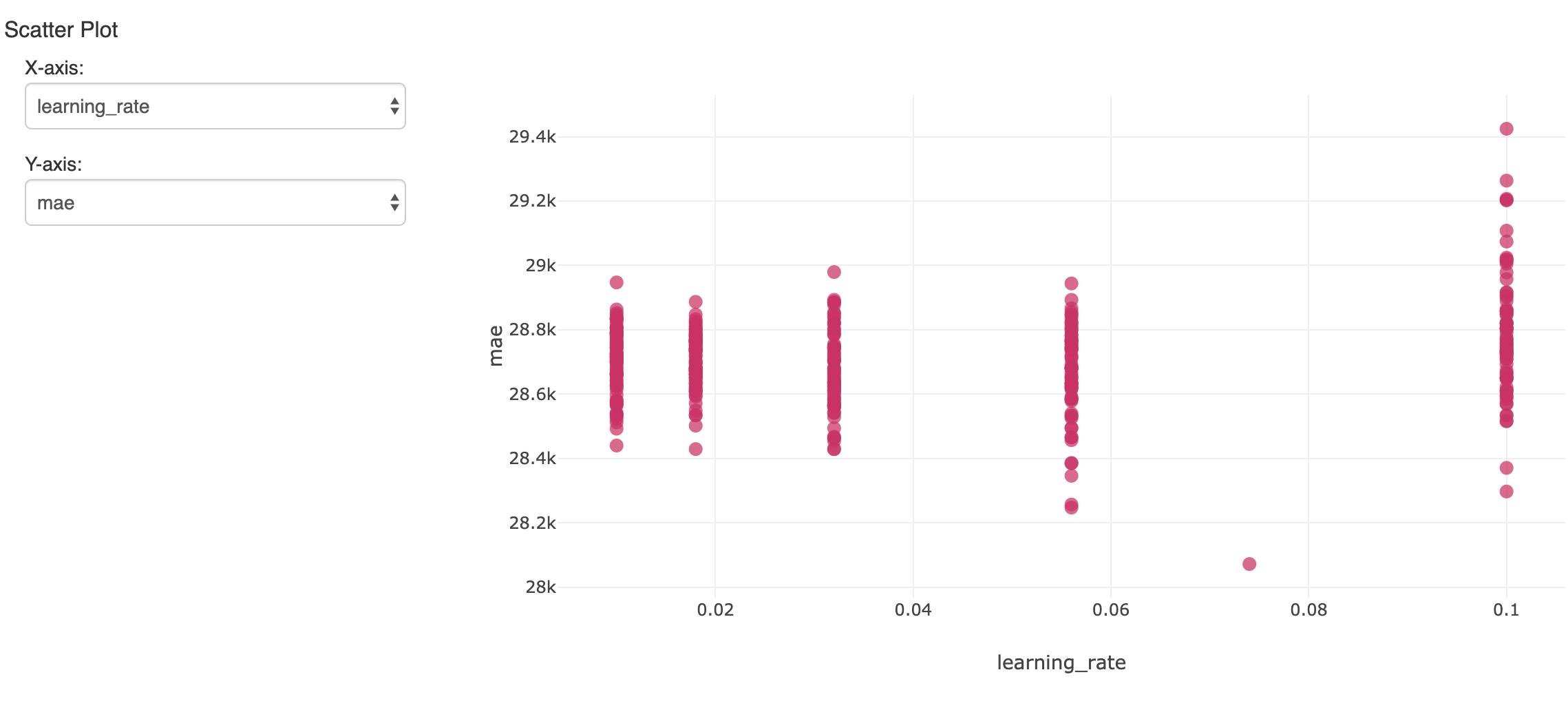
Il singolo modello che ha mostrato l'errore più basso sul set di dati di convalida tenuto da parte è di interesse. Ha prodotto un errore medio assoluto di circa 28.000 $ su stipendi medi di circa 119.000 $. Non male, anche se dobbiamo renderci conto che il modello può spiegare solo la maggior parte della variazione salariale.
Interpretazione del modello xgboost
Anche se il modello può essere utilizzato per prevedere gli stipendi futuri, la domanda è invece cosa il modello dice sui dati. Quali feature sembrano essere più importanti per prevedere lo stipendio con precisione? Il modello xgboost stesso calcola una misura dell'importanza delle feature:
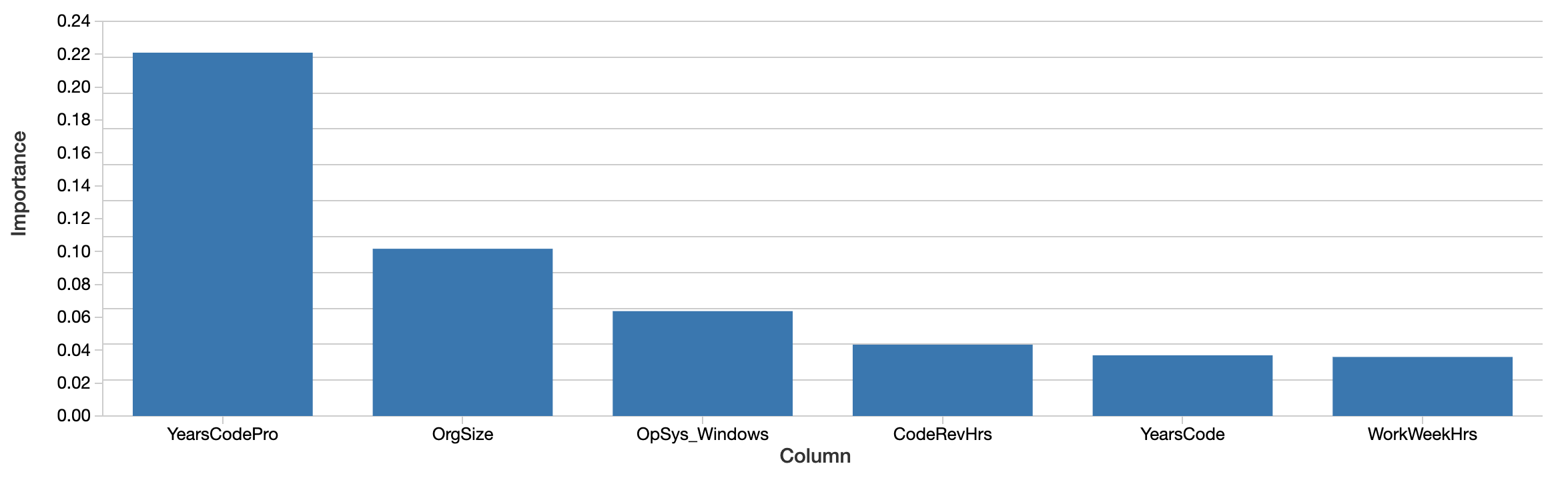
Fattori come gli anni di programmazione professionale, le dimensioni dell'organizzazione e l'uso di Windows sono i più "importanti". Questo è interessante, ma difficile da interpretare. I valori riflettono un'importanza relativa e non assoluta. Cioè, l'effetto non è misurato in dollari. Anche la definizione di importanza in questo caso (total gain) è specifica del modo in cui vengono costruiti gli alberi decisionali ed è difficile da mappare a un'interpretazione intuitiva. Inoltre, le feature importanti non sono nemmeno necessariamente correlate in modo positivo allo stipendio.
Cosa più importante, questa è una visione "globale" di quanto contino le feature in aggregato. Fattori come genere ed etnia non compaiono in questo elenco se non più avanti. Questo non significa che questi fattori non siano comunque significativi. In primo luogo, le feature possono essere correlate o interagire. È possibile che fattori come il genere siano correlati con altre feature che gli alberi hanno selezionato al loro posto e questo, in una certa misura, ne maschera l'effetto.
La domanda più interessante non è tanto se questi fattori siano importanti nel complesso (è possibile che il loro effetto medio sia relativamente piccolo), ma se abbiano un effetto significativo in alcuni singoli casi. Questi sono i casi in cui il modello ci sta dicendo qualcosa di importante sull'esperienza dei singoli e, per tali individui, è quell'esperienza che conta.
Applicazione del pacchetto SHAP per spiegazioni a livello di sviluppatore
Fortunatamente, negli ultimi cinque anni circa è emersa una serie di tecniche per un'interpretazione dei modelli teoricamente più solida a livello della singola previsione. Sono note collettivamente come "Shapley Additive Explanations" e, opportunamente, sono implementate nel pacchetto Python shap.
Dato un qualsiasi modello, questa libreria calcola i "valori SHAP" dal modello. Questi valori sono facilmente interpretabili, poiché ogni valore rappresenta l'effetto di una feature sulla previsione, nelle sue unità. Un valore SHAP di 1000 qui significa "spiegato +$1.000 di stipendio previsto". I valori SHAP vengono calcolati anche in modo da tentare di isolare la correlazione e l'interazione.
I valori SHAP vengono calcolati anche per ogni input, non per il modello nel suo complesso, quindi queste spiegazioni sono disponibili singolarmente per ogni input. Può anche stimare l'effetto delle interazioni tra le feature separatamente dall'effetto principale di ogni feature, per ogni previsione.
AI spiegabile: svelare gli effetti complessivi delle feature
Le spiegazioni a livello di sviluppatore possono essere aggregate in spiegazioni degli effetti delle feature sullo stipendio sull'intero data set, semplicemente calcolando la media dei loro valori assoluti. La valutazione di SHAP delle funzionalità complessivamente più importanti è simile:
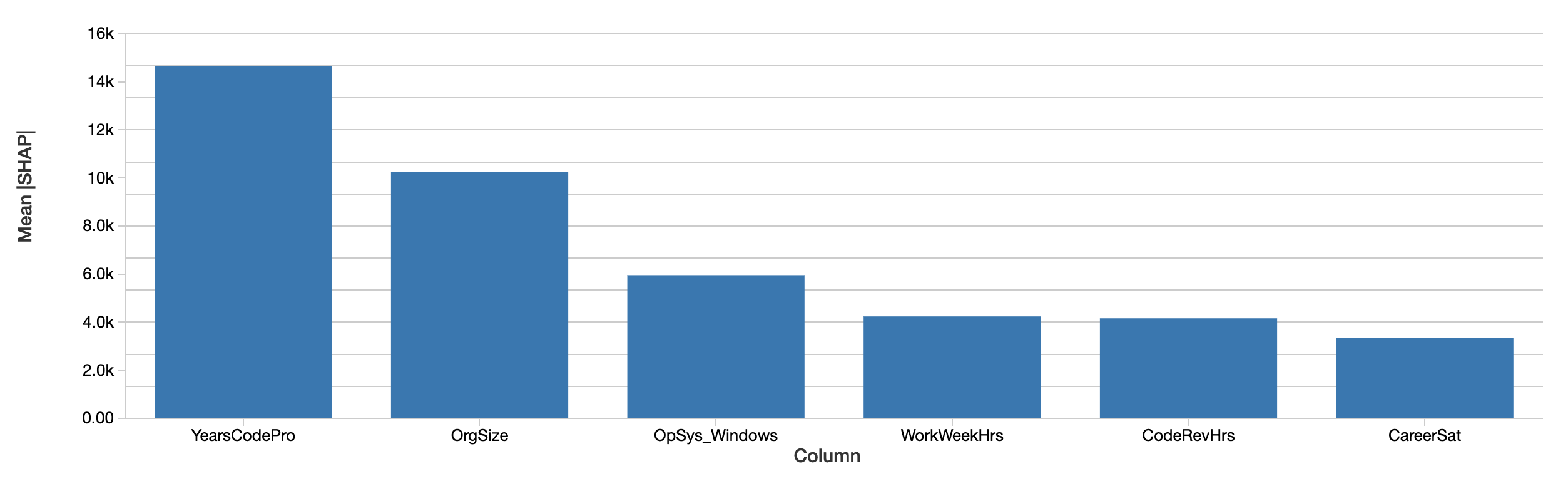
I valori SHAP raccontano una storia simile. Innanzitutto, SHAP è in grado di quantificare l'effetto sullo stipendio in dollari, il che migliora notevolmente l'interpretazione dei risultati. Sopra è riportato un grafico dell'effetto assoluto di ogni feature sullo stipendio previsto, mediato tra gli sviluppatori. Gli anni di esperienza professionale nella programmazione sono ancora il fattore dominante, spiegando in media un effetto di quasi 15.000 $ sullo stipendio.
Analisi degli effetti del genere con i valori SHAP
Abbiamo analizzato in modo specifico gli effetti di genere, etnia e altri fattori che presumibilmente non dovrebbero essere di per sé predittivi dello stipendio. Questo esempio esaminerà l'effetto del genere, anche se ciò non suggerisce affatto che sia l'unico, o il più importante, tipo di bias da cercare.
Il genere non è binario e il sondaggio riconosce separatamente le risposte "Uomo", "Donna", "Non-binario, genderqueer o di genere non conforme" nonché "Trans". (Si noti che, sebbene il sondaggio registri separatamente anche le risposte relative alla sessualità, queste non vengono prese in considerazione in questa sede.) SHAP calcola l'effetto sullo stipendio previsto per ognuna di queste categorie. Per uno sviluppatore di sesso maschile (che si identifica solo come uomo), l'effetto del genere non è solo l'effetto dell'essere uomo, ma anche del non identificarsi come donna, transgender e così via.
I valori SHAP ci consentono di leggere la somma di questi effetti per gli sviluppatori che si identificano in ciascuna delle quattro categorie:

Mentre il genere degli sviluppatori uomini spiega un modesto intervallo da circa -230 $ a +890 $ con una media di circa 225 $, per le donne l'intervallo è più ampio, da circa -4.260 $ a -690 $ con una media di -1.320 $. I risultati per gli sviluppatori transgender e non-binary sono simili, anche se leggermente meno negativi.
Nel valutare il significato di quanto segue, è importante ricordare i limiti dei dati e del modello in questo caso:
- Correlazione non è causalità; 'spiegare' lo stipendio previsto è suggestivo, ma non dimostra che una feature abbia causato direttamente un aumento o una diminuzione dello stipendio.
- Il modello non è perfettamente accurato
- Si tratta di dati di un solo anno e solo di sviluppatori statunitensi
- Questo riflette solo lo stipendio di base, non i bonus o le azioni, che possono variare più ampiamente.
Utilizzo di SHAP per visualizzare le feature che interagiscono con il genere
La libreria SHAP offre visualizzazioni interessanti che sfruttano la sua capacità di isolare l'effetto delle interazioni tra le feature. Ad esempio, i valori sopra riportati suggeriscono che per gli sviluppatori che si identificano come maschi si prevede uno stipendio leggermente più alto rispetto ad altri, ma c'è dell'altro? Un grafico di dipendenza come questo può essere d'aiuto:
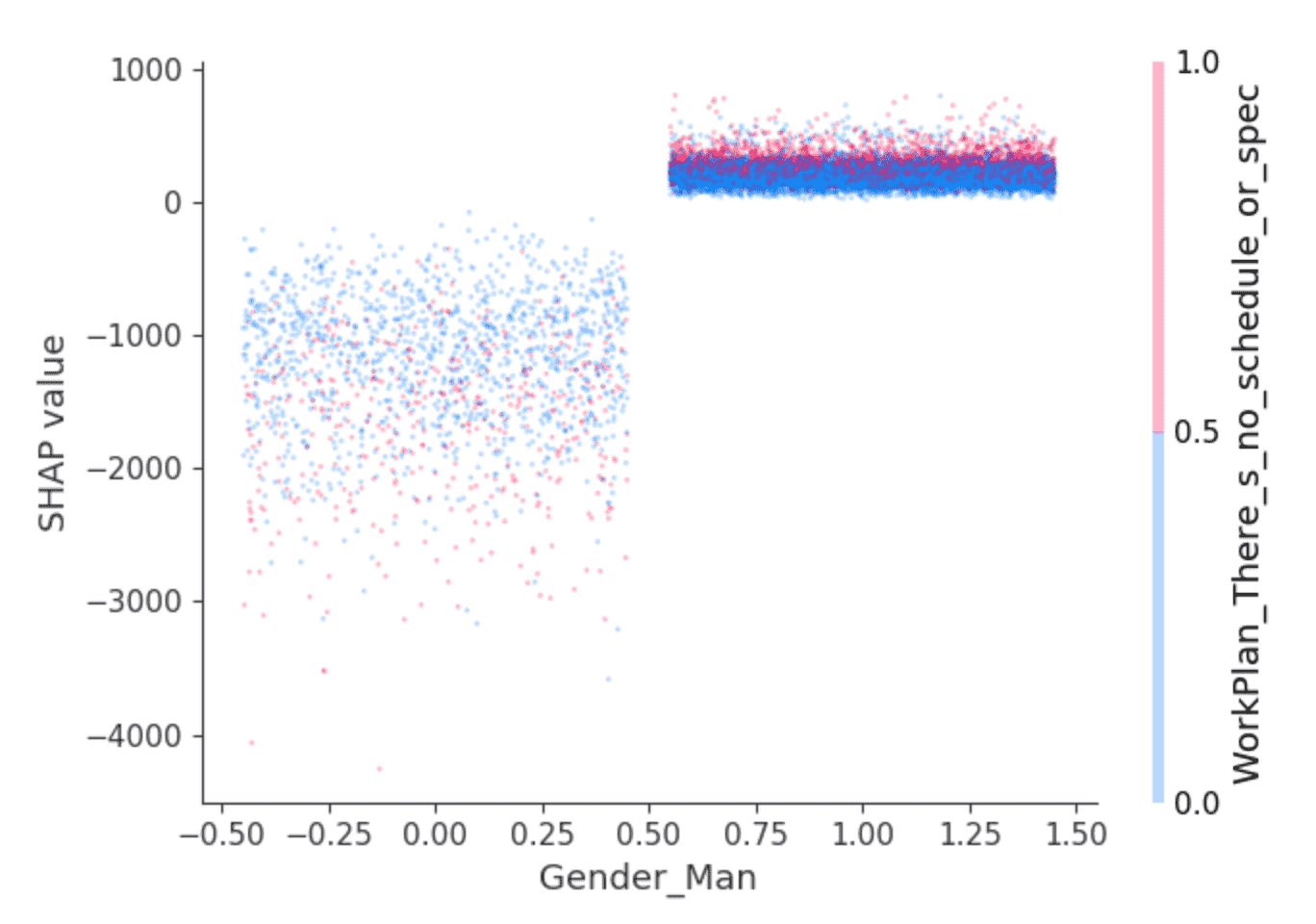
I punti sono sviluppatori. Gli sviluppatori a sinistra sono quelli che non si identificano come maschi e a destra quelli che lo fanno, che sono prevalentemente coloro che si identificano solo come maschi. (I punti sono distribuiti orizzontalmente in modo casuale per maggiore chiarezza.) L'asse y è il valore SHAP, ovvero ciò che l'identificazione come maschio o meno spiega riguardo allo stipendio previsto per ogni sviluppatore. Come sopra, coloro che non si identificano come maschi mostrano valori SHAP complessivamente negativi e uno che varia ampiamente, mentre gli altri mostrano costantemente un valore SHAP leggermente positivo.
Cosa c'è dietro quella varianza? SHAP può selezionare una seconda feature il cui effetto varia maggiormente in base al valore, in questo caso, dell'identificarsi come maschio o meno. Seleziona la risposta "Lavoro su ciò che sembra più importante o urgente" alla domanda "Quanto è strutturato o pianificato il tuo lavoro?" Tra gli sviluppatori che si identificano come uomini, coloro che hanno risposto in questo modo (punti rossi) sembrano avere valori SHAP leggermente più alti. Tra gli altri, l'effetto è più eterogeneo ma sembra avere valori SHAP generalmente più bassi.
L'interpretazione è lasciata al lettore, ma forse: gli sviluppatori uomini che si sentono realizzati in questo senso godono anche di stipendi leggermente più alti, mentre altri sviluppatori ne beneficiano laddove ciò va di pari passo con ruoli meno retribuiti?
Esplorazione delle istanze con effetti di genere sproporzionati
E se analizzassimo lo sviluppatore il cui stipendio è influenzato più negativamente? Così come è possibile esaminare l'effetto complessivo delle feature legate al genere, è possibile cercare lo sviluppatore le cui feature legate al genere hanno avuto l'impatto maggiore sullo stipendio previsto. Questa persona è di sesso femminile e l'effetto è negativo. Secondo il modello, si prevede che guadagnerà circa 4.260 $ in meno all'anno a causa del suo genere:

Lo stipendio previsto, poco più di 157.000 $, è accurato in questo caso, poiché il suo stipendio effettivo dichiarato è di 150.000 $.
Le tre caratteristiche più positive e negative che influenzano lo stipendio previsto sono che lei:
- Ha una laurea (solo) (+$18.200)
- Ha 10 anni di esperienza professionale (+$9.400)
- Si identifica come asiatico orientale (+$9.100)
- ...
- Lavora 40 ore a settimana (-4.000 $)
- Non si identifica come maschio (-$4.250)
- Lavora in un'organizzazione di medie dimensioni con 100-499 dipendenti (-9.700 $)
Data l'entità dell'effetto sullo stipendio previsto del non identificarsi come maschio, potremmo fermarci qui e analizzare i dettagli di questo caso offline per comprendere meglio il contesto relativo a questa sviluppatrice e se la sua esperienza, o il suo stipendio, o entrambi, necessitino di una modifica.
Spiegare le interazioni usando i valori SHAP
Sono disponibili maggiori dettagli all'interno di quei -$4.260. SHAP può scomporre gli effetti di queste feature in interazioni. L'effetto totale dell'identificarsi come donna sulla previsione può essere scomposto nell'effetto dell'identificarsi come donna e essere un manager di ingegneria, e lavorare con Windows, ecc.
L'effetto sullo stipendio previsto, spiegato dai fattori di genere, di per sé ammonta solo a circa -630. Piuttosto, SHAP assegna la maggior parte degli effetti del genere alle interazioni con altre feature:
Identificarsi come donna e lavorare con PostgreSQL influisce leggermente in positivo sullo stipendio previsto, mentre identificarsi anche come persona dell'Asia orientale influisce più negativamente sullo stipendio previsto. Interpretare questi valori a questo livello di granularità è difficile in questo contesto, ma questo livello di spiegazione aggiuntivo è disponibile.
Applicazione di SHAP con Apache Spark
I valori SHAP vengono computati in modo indipendente per ogni riga, dato il modello, e quindi questo avrebbe potuto essere fatto anche in parallelo con Spark. L'esempio seguente calcola i valori SHAP in parallelo e individua in modo simile gli sviluppatori con valori SHAP sproporzionati legati al genere:
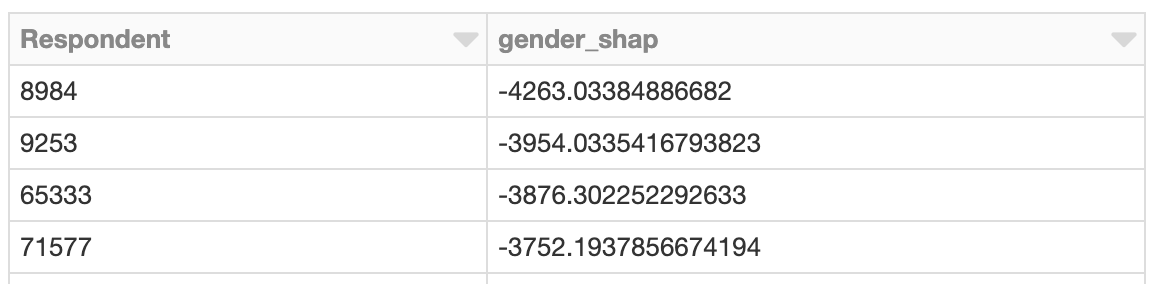
Clustering dei valori SHAP
L'utilizzo di Spark è vantaggioso quando si deve valutare un gran numero di previsioni con SHAP. Dato tale output, è anche possibile utilizzare Spark per clusterizzare i risultati, ad esempio, con il k-means bisecante:
Il cluster i cui effetti SHAP totali legati al genere sono più negativi potrebbe meritare un'ulteriore indagine. Quali sono i valori SHAP degli intervistati nel cluster? Quali sono le caratteristiche dei membri del cluster rispetto alla popolazione complessiva di sviluppatori?
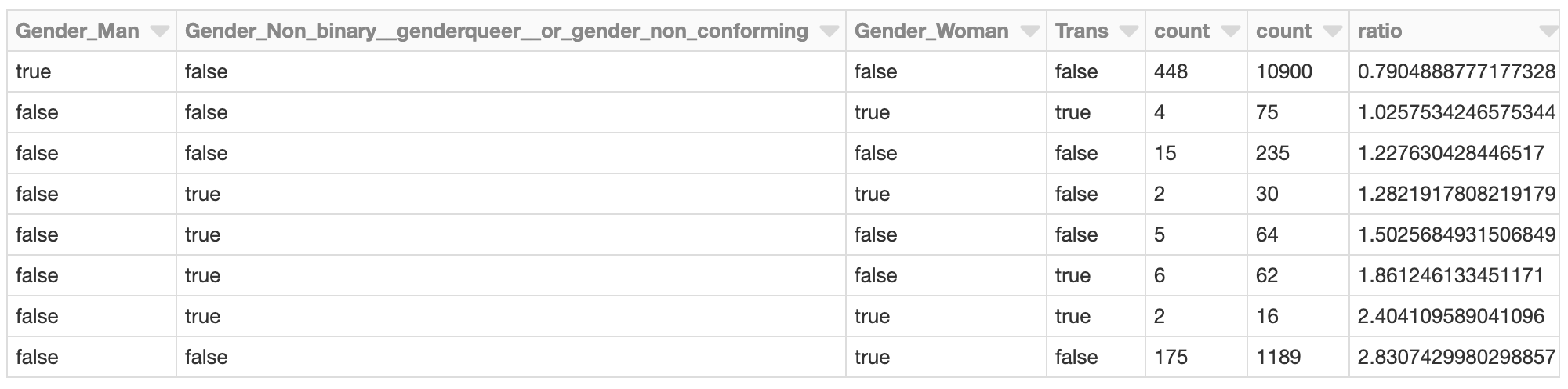
Ad esempio, le sviluppatrici (solo donne) sono rappresentate in questo cluster a un tasso quasi 2,8 volte superiore rispetto alla popolazione complessiva di sviluppatori. Questo non sorprende, data l'analisi precedente. Questo cluster potrebbe essere ulteriormente analizzato per valutare altri fattori specifici di questo gruppo che contribuiscono a uno stipendio previsto complessivamente più basso.
Conclusione
Questo tipo di analisi con SHAP può essere eseguita per qualsiasi modello e anche su larga scala. Come strumento analitico, trasforma i modelli in investigatori dei dati per far emergere le singole istanze le cui previsioni suggeriscono che meritano un esame più approfondito. L'output di SHAP è facilmente interpretabile e produce grafici intuitivi che possono essere valutati caso per caso dagli utenti business.
Naturalmente, questa analisi non si limita a esaminare questioni di bias di genere, età o razza. Più prosaicamente, potrebbe essere applicata ai modelli di churn dei clienti. In questo caso, la domanda non è solo "questo cliente farà churn?" ma "perché il cliente sta facendo churn?" A un cliente che annulla l'abbonamento a causa del prezzo si può offrire uno sconto, mentre a uno che lo annulla a causa dell'utilizzo limitato potrebbe essere proposto un upsell.
Infine, questa analisi può essere eseguita come parte di un processo di convalida, apportando una maggiore trasparenza al modello di machine learning in generale. La validazione di un modello si concentra spesso sulla sua accuratezza complessiva. Dovrebbe concentrarsi anche sul 'ragionamento' del modello, ovvero su quali feature hanno contribuito maggiormente alle previsioni. Con SHAP, può anche aiutare a rilevare quando le spiegazioni di troppe previsioni individuali sono in conflitto con l'importanza complessiva delle feature.
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.