Adaptive Query Execution: Accelerare Spark SQL in fase di esecuzione
Leggi Rise of the Data Lakehouse per scoprire perché i lakehouse sono l'architettura dati del futuro con il padre del data warehouse, Bill Inmon.
Questo è uno sforzo ingegneristico congiunto tra il team di ingegneria Databricks Apache Spark — Wenchen Fan, Herman van Hovell e MaryAnn Xue — e il team di ingegneria Intel —Ke Jia, Haifeng Chen e Carson Wang.
Vedi il notebook AQE per provare la soluzione trattata di seguito o approfondisci il funzionamento interno della Databricks Lakehouse Platform
Nel corso degli anni, c'è stato uno sforzo esteso e continuo per migliorare l'ottimizzatore di query e il planner di Spark SQL al fine di generare piani di esecuzione di query di alta qualità. Uno dei maggiori miglioramenti è il framework di ottimizzazione basato sui costi che raccoglie e sfrutta una varietà di statistiche sui dati (ad esempio, conteggio delle righe, numero di valori distinti, valori NULL, valori max/min, ecc.) per aiutare Spark a scegliere piani migliori. Esempi di queste tecniche di ottimizzazione basata sui costi includono la scelta del giusto tipo di join (broadcast hash join vs. sort merge join), la selezione del lato di build corretto in un hash-join o la regolazione dell'ordine di join in un join multi-way. Tuttavia, statistiche obsolete e stime di cardinalità imperfette possono portare a piani di query subottimali. Adaptive Query Execution, nuovo nella prossima release di Apache SparkTM 3.0 e disponibile in Databricks Runtime 7.0, ora mira a risolvere tali problemi riottimizzando e regolando i piani di query in base alle statistiche di runtime raccolte nel processo di esecuzione della query.
Il framework Adaptive Query Execution (AQE)
Una delle domande più importanti per Adaptive Query Execution è quando riottimizzare. Gli operatori Spark sono spesso in pipeline ed eseguiti in processi paralleli. Tuttavia, uno shuffle o un broadcast exchange interrompono questa pipeline. Li chiamiamo punti di materializzazione e usiamo il termine "query stages" per indicare le sottosezioni delimitate da questi punti di materializzazione in una query. Ogni query stage materializza il suo risultato intermedio e lo stage successivo può procedere solo se tutti i processi paralleli che eseguono la materializzazione sono stati completati. Questo fornisce un'opportunità naturale per la riottimizzazione, poiché è quando le statistiche sui dati di tutte le partizioni sono disponibili e le operazioni successive non sono ancora iniziate.
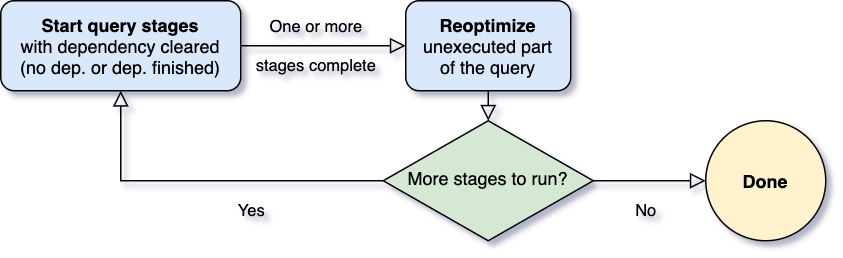
Quando la query inizia, il framework Adaptive Query Execution avvia prima tutti gli stage foglia — gli stage che non dipendono da altri stage. Non appena uno o più di questi stage terminano la materializzazione, il framework li contrassegna come completati nel piano di query fisico e aggiorna il piano di query logico di conseguenza, con le statistiche di runtime recuperate dagli stage completati. Sulla base di queste nuove statistiche, il framework esegue quindi l'ottimizzatore (con un elenco selezionato di regole di ottimizzazione logica), il planner fisico e le regole di ottimizzazione fisica, che includono le regole fisiche regolari e le regole specifiche dell'esecuzione adattiva, come il coalescing delle partizioni, la gestione dello skew join, ecc. Ora che abbiamo un piano di query riottimizzato con alcuni stage completati, il framework di esecuzione adattiva cercherà ed eseguirà nuovi query stage i cui stage figli sono stati tutti materializzati, e ripeterà il processo di esecuzione-riottimizzazione-esecuzione sopra descritto fino al completamento dell'intera query.
In Spark 3.0, il framework AQE è distribuito con tre funzionalità:
- Coalescing dinamico delle partizioni di shuffle
- Commutazione dinamica delle strategie di join
- Ottimizzazione dinamica degli skew join
Le sezioni seguenti tratteranno queste tre funzionalità in dettaglio.
Coalescing dinamico delle partizioni di shuffle
Quando si eseguono query in Spark per gestire dati molto grandi, lo shuffle ha solitamente un impatto molto importante sulle prestazioni delle query, tra molte altre cose. Lo shuffle è un operatore costoso poiché deve spostare dati attraverso la rete, in modo che i dati vengano ridistribuiti nel modo richiesto dagli operatori downstream.
Una proprietà chiave dello shuffle è il numero di partizioni. Il numero migliore di partizioni dipende dai dati, eppure le dimensioni dei dati possono variare notevolmente da stage a stage, da query a query, rendendo difficile la messa a punto di questo numero:
- Se ci sono troppe poche partizioni, la dimensione dei dati di ciascuna partizione può essere molto grande e i task per l'elaborazione di queste grandi partizioni potrebbero dover scrivere dati su disco (ad esempio, quando sono coinvolti sort o aggregate) e, di conseguenza, rallentare la query.
- Se ci sono troppe partizioni, la dimensione dei dati di ciascuna partizione può essere molto piccola e ci saranno molte piccole letture di dati di rete per leggere i blocchi di shuffle, il che può anche rallentare la query a causa del pattern di I/O inefficiente. Avere un gran numero di task grava anche sullo scheduler dei task di Spark.
Per risolvere questo problema, possiamo impostare un numero relativamente elevato di partizioni di shuffle all'inizio, quindi combinare partizioni piccole adiacenti in partizioni più grandi a runtime guardando le statistiche dei file di shuffle.
Ad esempio, supponiamo di eseguire la query SELECT max(i)FROM tbl GROUP BY j. I dati di input tbl sono piuttosto piccoli, quindi ci sono solo due partizioni prima del raggruppamento. Il numero iniziale di partizioni di shuffle è impostato a cinque, quindi dopo il raggruppamento locale, i dati parzialmente raggruppati vengono shufflati in cinque partizioni. Senza AQE, Spark avvierà cinque task per eseguire l'aggregazione finale. Tuttavia, ci sono tre partizioni molto piccole qui, e sarebbe uno spreco avviare un task separato per ciascuna di esse.
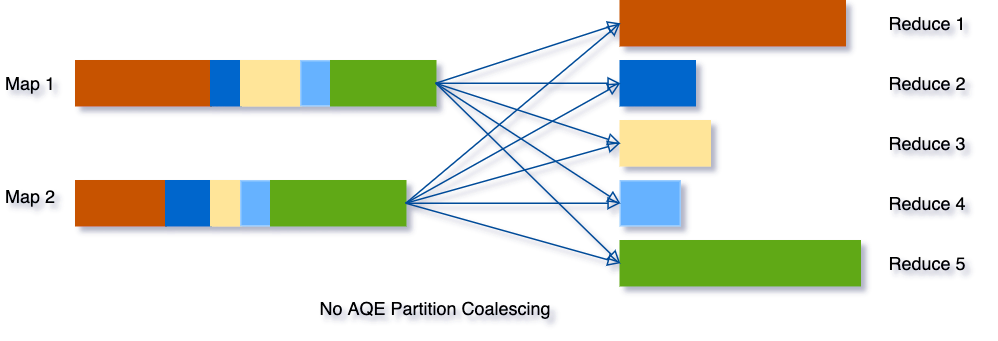
Invece, AQE unisce queste tre piccole partizioni in una e, di conseguenza, l'aggregazione finale richiede solo tre task invece di cinque.

Commutazione dinamica delle strategie di join
Spark supporta diverse strategie di join, tra cui il broadcast hash join è solitamente il più performante se un lato del join può adattarsi bene alla memoria. E per questo motivo, Spark pianifica un broadcast hash join se la dimensione stimata di una relazione di join è inferiore alla soglia di dimensione di broadcast. Ma diverse cose possono far sì che questa stima delle dimensioni vada storta — come la presenza di un filtro molto selettivo — o che la relazione di join sia una serie di operatori complessi oltre a una semplice scansione.
Per risolvere questo problema, AQE ripianifica ora la strategia di join a runtime in base alla dimensione più accurata della relazione di join. Come si vede nel seguente esempio, il lato destro del join risulta essere molto più piccolo della stima e anche abbastanza piccolo da essere trasmesso in broadcast, quindi dopo la riottimizzazione AQE, il sort merge join pianificato staticamente viene ora convertito in un broadcast hash join.
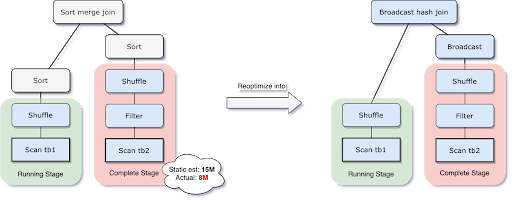
Per il broadcast hash join convertito a runtime, possiamo ottimizzare ulteriormente lo shuffle regolare in uno shuffle localizzato (cioè, uno shuffle che legge su base per mapper invece che per reducer) per ridurre il traffico di rete.
Ottimizzazione dinamica degli skew join
Lo skew dei dati si verifica quando i dati sono distribuiti in modo non uniforme tra le partizioni nel cluster. Uno skew grave può degradare significativamente le prestazioni delle query, specialmente con i join. L'ottimizzazione AQE per gli skew join rileva automaticamente tale skew dalle statistiche dei file di shuffle. Quindi divide le partizioni sbilanciate in sotto-partizioni più piccole, che verranno unite alla partizione corrispondente dall'altro lato rispettivamente.
Prendiamo questo esempio di tabella A join tabella B, in cui la tabella A ha una partizione A0 significativamente più grande delle sue altre partizioni.
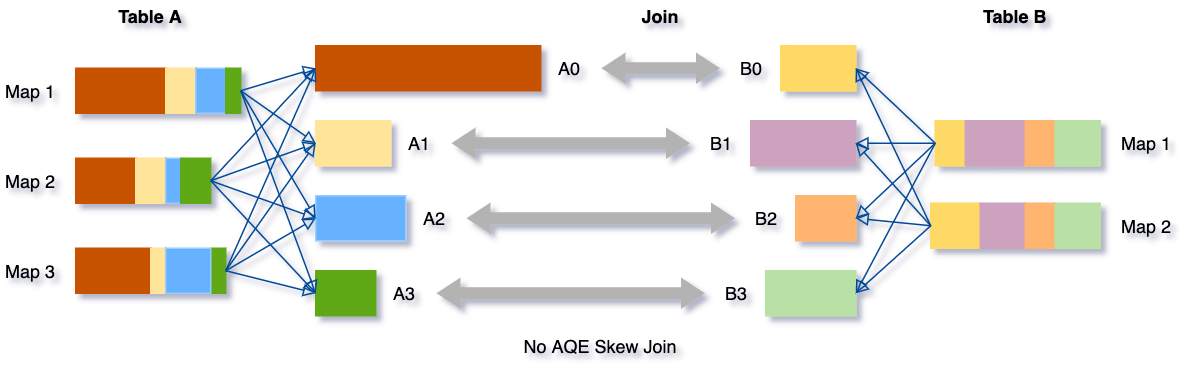
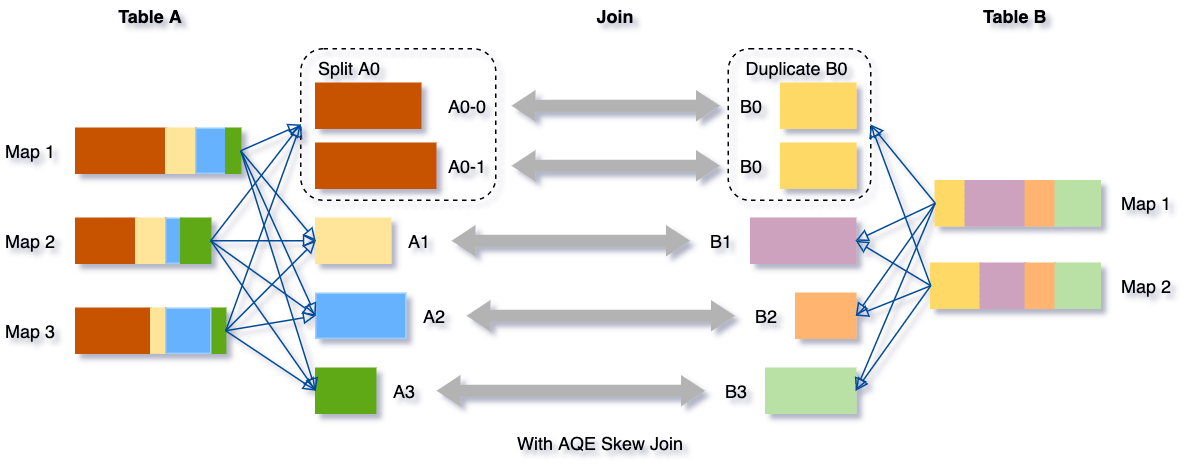
Senza questa ottimizzazione, ci sarebbero quattro task che eseguono il sort merge join con un task che richiede molto più tempo. Dopo questa ottimizzazione, ci saranno cinque task che eseguono il join, ma ogni task richiederà all'incirca lo stesso tempo, con conseguente miglioramento generale delle prestazioni.
Guadagni di prestazioni TPC-DS da AQE
Nei nostri esperimenti utilizzando dati e query TPC-DS, Adaptive Query Execution ha prodotto un aumento delle prestazioni delle query fino a 8 volte e 32 query hanno avuto un aumento superiore a 1,1 volte. Di seguito è riportato un grafico delle 10 query TPC-DS con il maggior miglioramento delle prestazioni da parte di AQE.
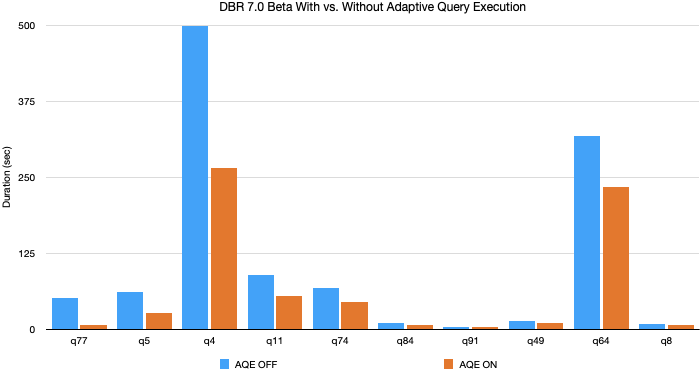
La maggior parte di questi miglioramenti deriva dal coalescing dinamico delle partizioni e dal cambio dinamico della strategia di join, poiché i dati TPC-DS generati casualmente non presentano skew. Tuttavia, abbiamo riscontrato miglioramenti ancora maggiori nei carichi di lavoro di produzione in cui vengono sfruttate tutte e tre le funzionalità di AQE.
Abilitazione di AQE
AQE può essere abilitato impostando la configurazione SQL spark.sql.adaptive.enabled su true (predefinito false in Spark 3.0) e si applica se la query soddisfa i seguenti criteri:
- Non è una query di streaming
- Contiene almeno uno scambio (solitamente quando c'è un operatore di join, aggregazione o finestra) o una sottoquery
Rendendo l'ottimizzazione delle query meno dipendente dalle statistiche statiche, AQE ha risolto una delle maggiori sfide dell'ottimizzazione basata sui costi di Spark: l'equilibrio tra l'overhead della raccolta delle statistiche e l'accuratezza della stima. Per ottenere la migliore accuratezza di stima e il miglior risultato di pianificazione, è solitamente necessario mantenere statistiche dettagliate e aggiornate, alcune delle quali sono costose da raccogliere, come gli istogrammi delle colonne, che possono essere utilizzati per migliorare la stima di selettività e cardinalità o per rilevare lo skew dei dati. AQE ha in gran parte eliminato la necessità di tali statistiche, nonché lo sforzo di ottimizzazione manuale. Inoltre, AQE ha reso l'ottimizzazione delle query SQL più resiliente alla presenza di UDF arbitrari e a modifiche imprevedibili del set di dati, ad esempio aumenti o diminuzioni improvvise delle dimensioni dei dati, skew dei dati frequenti e casuali, ecc. Non è più necessario conoscere i dati in anticipo. AQE analizzerà i dati e migliorerà il piano di query durante l'esecuzione della query, aumentando le prestazioni delle query per analisi più rapide e prestazioni del sistema.
Scopri di più su Spark 3.0 nel nostro webinar di anteprima. Prova AQE in Spark 3.0 oggi stesso gratuitamente su Databricks come parte del nostro Databricks Runtime 7.0.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.