Come semplificare la CDC con il Change Data Feed di Delta Lake
Prova questo notebook in Databricks
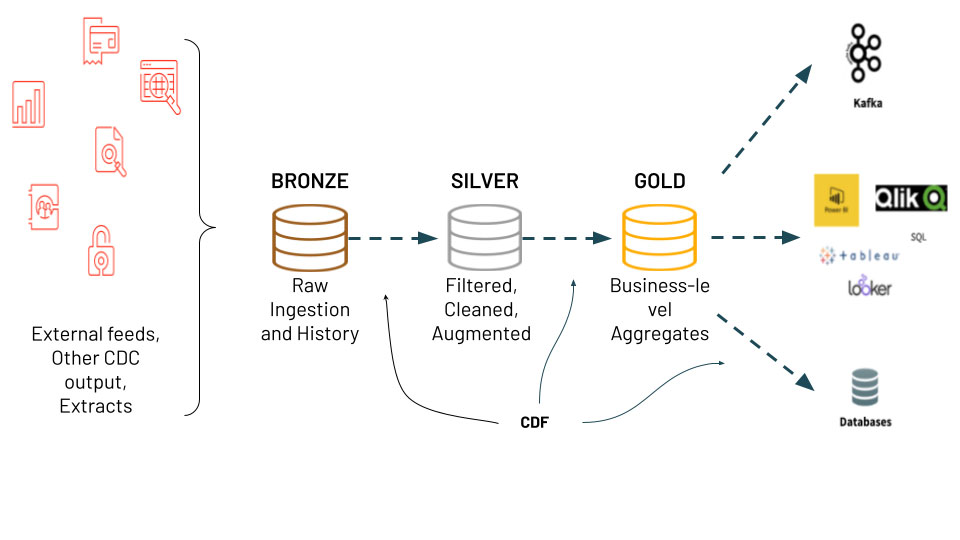
Change data capture (CDC) è un caso d'uso che vediamo molti clienti implementare in Databricks – puoi consultare il nostro precedente approfondimento sull'argomento qui. Tipicamente vediamo la CDC utilizzata in un'architettura di ingestione verso analisi chiamata architettura medallion. L'architettura medallion che prende dati grezzi caricati dai sistemi sorgente e raffina i dati attraverso tabelle bronze, silver e gold. La CDC e l'architettura medallion offrono molteplici vantaggi agli utenti poiché solo i dati modificati o aggiunti devono essere elaborati. Inoltre, le diverse tabelle nell'architettura consentono a diversi utenti, come Data Scientist e Analisti BI, di utilizzare i dati corretti e aggiornati per le loro esigenze. Siamo lieti di annunciare la nuova entusiasmante funzionalità Change Data Feed (CDF) in Delta Lake che rende questa architettura più semplice da implementare e possibili le operazioni MERGE e il versionamento del log di Delta Lake!
Ottieni un'anteprima di l'ebook di O'Reilly per la guida passo passo necessaria per iniziare a usare Delta Lake.
Perché è necessaria la funzionalità CDF?
Molti clienti utilizzano Databricks per eseguire la CDC, poiché è più semplice da implementare con Delta Lake rispetto ad altre tecnologie Big Data. Tuttavia, anche con gli strumenti giusti, la CDC può essere ancora difficile da eseguire. Abbiamo progettato la CDF per rendere la codifica ancora più semplice e affrontare i principali punti critici relativi alla CDC, tra cui:
- Controllo Qualità - Le modifiche a livello di riga sono difficili da ottenere tra le versioni.
- Inefficienza - Può essere inefficiente tenere conto delle righe non modificate poiché le modifiche della versione corrente sono a livello di file e non di riga.
Ecco come l'implementazione del Change Data Feed (CDF) aiuta a risolvere i problemi sopra menzionati:
- Semplicità e praticità - Utilizza un modello comune e facile da usare per identificare le modifiche, rendendo il tuo codice semplice, pratico e facile da capire.
- Efficienza - La capacità di avere solo le righe che sono state modificate tra le versioni, rende il consumo downstream delle operazioni Merge, Update ed Delete estremamente efficiente.
La CDF cattura le modifiche solo da una tabella Delta ed è solo proiettata in avanti una volta abilitata.
Change Data Feed in Azione!
Analizziamo un esempio di CDF per un caso d'uso comune: previsioni finanziarie. Il notebook a cui si fa riferimento all'inizio di questo blog elabora dati finanziari. L'Estimated Earnings Per Share (EPS) sono dati finanziari di analisti che prevedono l'utile per azione trimestrale di un'azienda. I dati grezzi possono provenire da molte fonti diverse e da più analisti per più azioni.
Con la funzionalità CDF, i dati vengono semplicemente inseriti nella tabella bronze (ingestione grezza), quindi filtrati, puliti e arricchiti nella tabella silver e, infine, i valori aggregati vengono calcolati nella tabella gold in base ai dati modificati nella tabella silver.
Sebbene queste trasformazioni possano diventare complesse, fortunatamente, ora la funzionalità CDF basata su righe è semplice ed efficiente. Ma come si usa? Approfondiamo!
NOTA: L'esempio qui si concentra sulla versione SQL della CDF e anche su un modo specifico per utilizzare le operazioni, per valutare le variazioni, consultare la documentazione qui
Abilitazione della CDF su una tabella Delta Lake
Per avere la funzionalità CDF disponibile su una tabella, devi prima abilitare la funzionalità su detta tabella. Di seguito è riportato un esempio di abilitazione della CDF per la tabella bronze alla creazione della tabella. Puoi anche abilitare la CDF su una tabella come aggiornamento della tabella. Inoltre, puoi abilitare la CDF su un cluster per tutte le tabelle create dal cluster. Per queste variazioni, consulta la documentazione qui.

Il Change Data Feed è una funzionalità proiettata in avanti, catturerà le modifiche una volta impostata la proprietà della tabella e non prima
Interrogazione dei dati di modifica
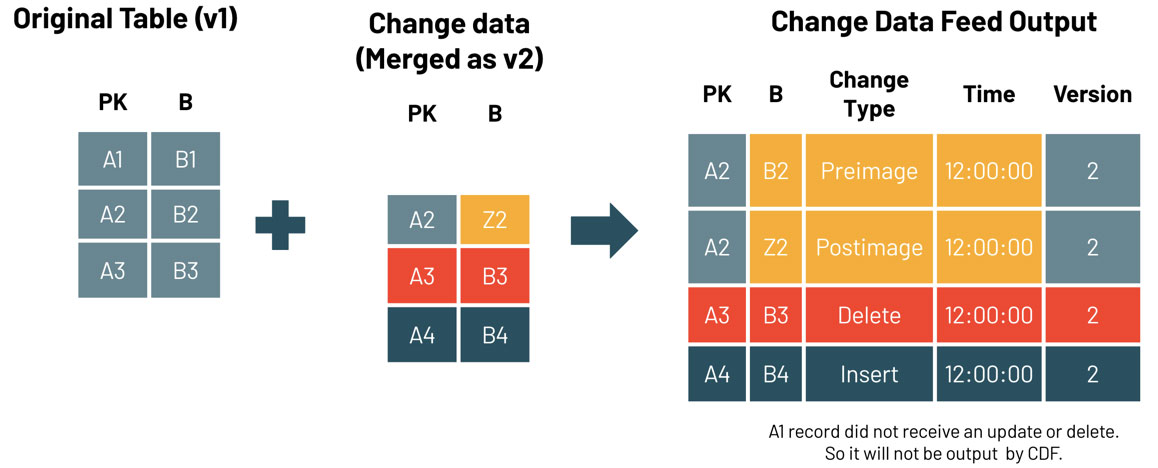
Per interrogare i dati di modifica, utilizza l'operazione table_changes. L'esempio seguente include righe inserite e due righe che rappresentano l'immagine pre- e post- di una riga aggiornata, in modo da poter valutare le differenze nelle modifiche, se necessario. Esiste anche un tipo di modifica delete che viene restituito per le righe eliminate.
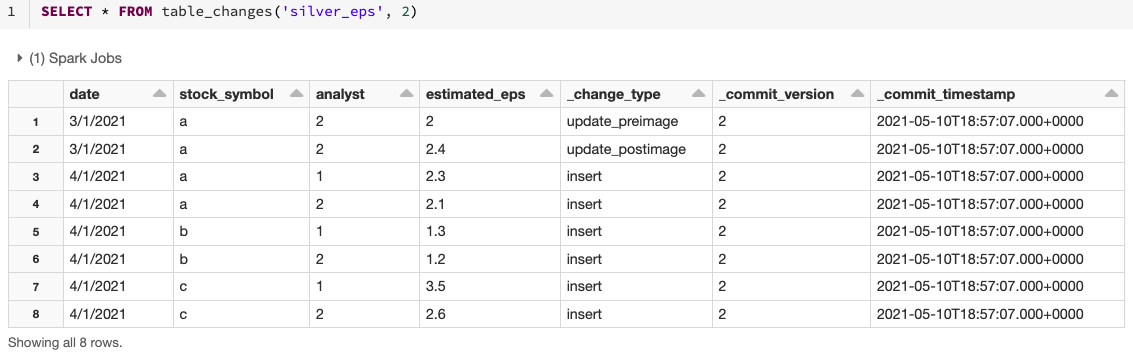
Questo esempio accede ai record modificati in base alla versione iniziale, ma puoi anche limitare le versioni in base alla versione finale, nonché ai timestamp iniziali e finali, se necessario. Questo esempio si concentra su SQL, ma ci sono anche modi per accedere a questi dati in Python, Scala, Java e R. Per queste variazioni, consulta la documentazione qui.
Utilizzo dei dati di riga CDF in un'istruzione MERGE
Le istruzioni MERGE aggregate, come il merge nella tabella gold, possono essere complesse per natura, ma la funzionalità CDF rende la codifica di queste istruzioni più semplice ed efficiente.
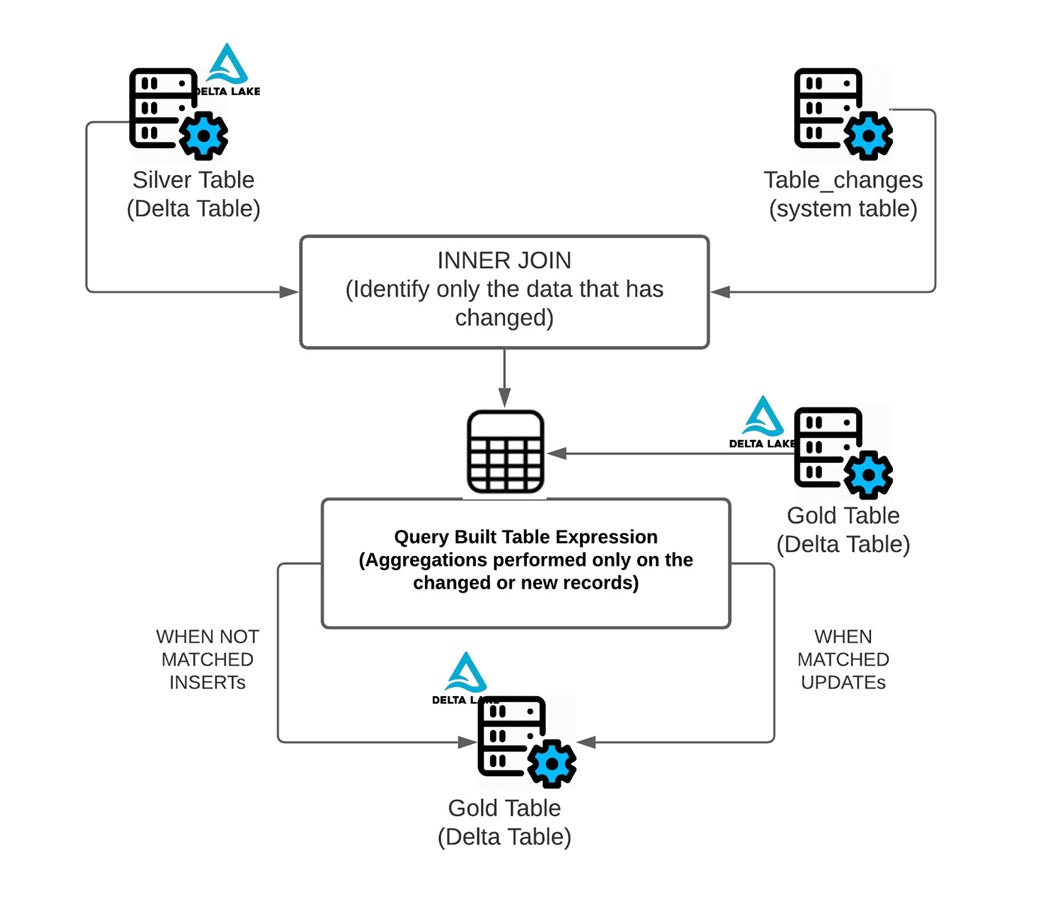
Come visto nel diagramma sopra, la CDF semplifica la derivazione delle righe modificate, poiché esegue solo l'aggregazione necessaria sui dati che sono stati modificati o sono nuovi utilizzando l'operazione table_changes. Di seguito, puoi vedere come utilizzare i dati modificati per determinare quali date e simboli azionari sono stati modificati.
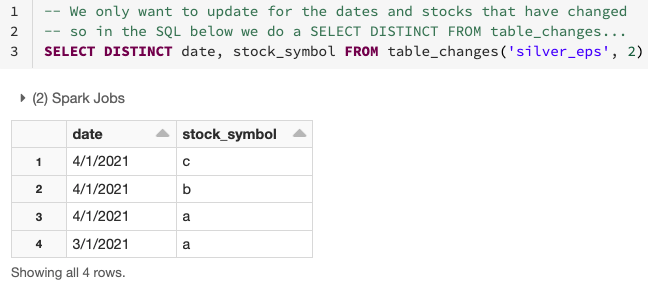
Come mostrato di seguito, puoi utilizzare i dati modificati dalla tabella silver per aggregare solo i dati sulle righe che devono essere aggiornate o inserite nella tabella gold. Per fare ciò, utilizza INNER JOIN su table_changes('nome_tabella','versione')
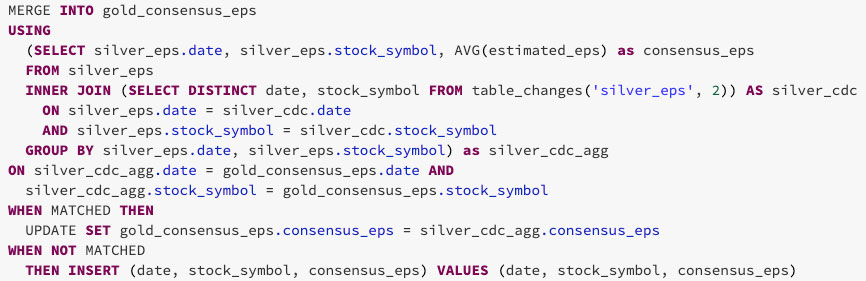
Il risultato finale è una versione chiara e concisa di una tabella gold che può cambiare incrementalmente nel tempo!
Casi d'uso tipici
Ecco alcuni casi d'uso comuni e i vantaggi della nuova funzionalità CDF:
Tabelle Silver e Gold
Migliora le prestazioni di Delta elaborando solo le modifiche successive al confronto MERGE iniziale per accelerare e semplificare le operazioni ETL/ELT.
Viste materializzate
Crea viste aggregate di informazioni aggiornate da utilizzare in BI e analisi senza dover rielaborare le tabelle sottostanti complete, aggiornando invece solo dove sono avvenute le modifiche.
Trasmetti modifiche
Invia il Change Data Feed ai sistemi downstream come Kafka o RDBMS che possono utilizzarlo per elaborare in modo incrementale nelle fasi successive delle pipeline di dati.
Tabella di audit
La cattura degli output del Change Data Feed come tabella Delta fornisce archiviazione perpetua e capacità di query efficiente per visualizzare tutte le modifiche nel tempo, inclusi gli eliminamenti e gli aggiornamenti.
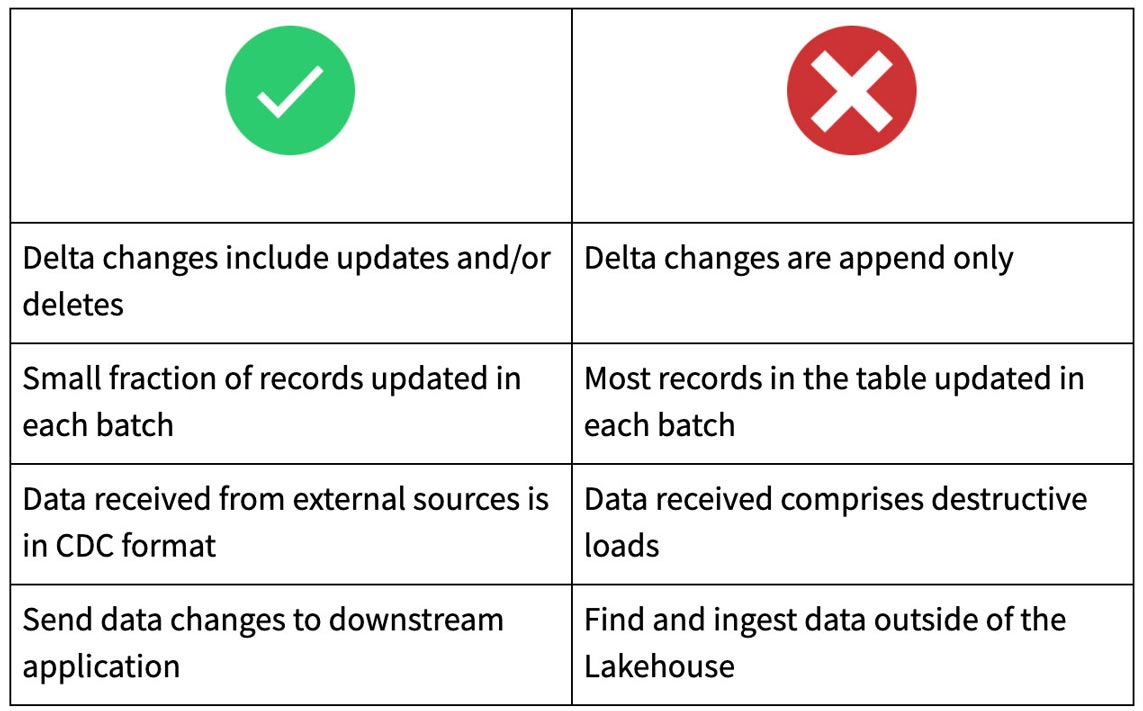
Quando usare Change Data Feed
Conclusione
In Databricks, ci sforziamo di rendere possibile l'impossibile e semplice ciò che è difficile. CDC, versionamento del log e implementazione MERGE erano virtualmente impossibili su larga scala fino alla creazione di Delta Lake. Ora lo stiamo rendendo più semplice ed efficiente con l'entusiasmante funzionalità Change Data Feed (CDF)!
Prova questo notebook in Databricks
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.