Parte 1: Implementazione di CI/CD su Databricks utilizzando Databricks Notebooks e Azure DevOps
Il codice discusso si trova qui.
Questa è la prima parte di una serie di due post sul blog che mostrano come configurare e creare soluzioni MLOps end-to-end su Databricks con notebook e Repos API. Questo post presenta un framework CI/CD su Databricks, basato sui notebook. La pipeline si integra con l'ecosistema Microsoft Azure DevOps per la parte di Continuous Integration (CI) e Repos API per la Continuous Delivery (CD). Nel secondo post, mostreremo come sfruttare la funzionalità Repos API per implementare un ciclo di vita CI/CD completo su Databricks ed estenderlo a una soluzione MLOps completa.
CI/CD con Databricks Repos
Fortunatamente, con le nuove funzionalità fornite da Databricks Repos e Repos API, siamo ora ben equipaggiati per coprire tutti gli aspetti chiave del controllo versione, del testing e delle pipeline che supportano gli approcci MLOps. Databricks Repos consente di clonare interi repository git in Databricks e, con l'aiuto di Repos API, possiamo automatizzare questo processo clonando prima un repository git e quindi effettuando il checkout del branch di nostro interesse. Gli operatori ML possono ora utilizzare una struttura di repository ben nota dagli IDE per strutturare il proprio progetto, basandosi su notebook o file .py per l'implementazione di moduli (con supporto per formati di file arbitrari in Repos previsto nella roadmap). Pertanto, l'intero progetto è controllato in versione da uno strumento a scelta (Github, Gitlab, Azure Repos per citarne alcuni) e si integra molto bene con le pipeline CI/CD comuni. Databricks Repos API ci consente di aggiornare un repo (progetto Git effettuato il checkout come repo in Databricks) all'ultima versione di un branch git specifico.
I team possono seguire il classico ciclo Git flow o GitHub flow durante lo sviluppo. L'intero repository Git può essere effettuato il checkout con Databricks Repos. Gli utenti potranno utilizzare e modificare i notebook, così come i file Python semplici o altri tipi di file di testo con supporto per file arbitrari. Ciò ci consente di utilizzare la classica struttura di progetto, importando moduli da file Python e combinandoli con i notebook:
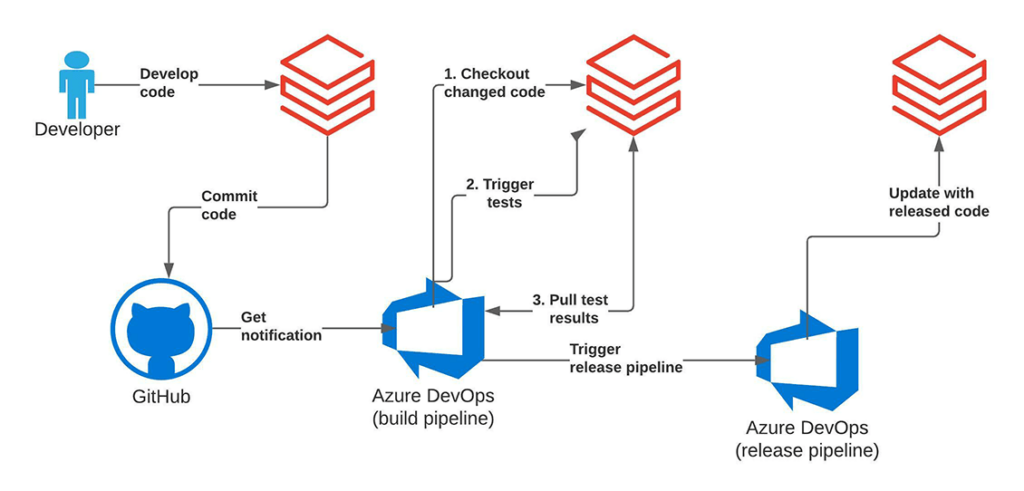
- Sviluppare singole funzionalità in un branch di funzionalità e testare utilizzando unit test (ad esempio, notebook implementati).
- Eseguire il push delle modifiche al branch di funzionalità, dove la pipeline CI/CD eseguirà il test di integrazione.
- Le pipeline CI/CD su Azure DevOps possono attivare Databricks Repos API per aggiornare questo progetto di test all'ultima versione.
- Le pipeline CI/CD attivano il job di test di integrazione tramite Jobs API. I test di integrazione possono essere implementati come un semplice notebook che eseguirà innanzitutto le pipeline che desideriamo testare con configurazioni di test. Ciò può essere fatto semplicemente eseguendo un notebook appropriato eseguendo i moduli corrispondenti o attivando il job reale utilizzando jobs API.
- Esaminare i risultati per contrassegnare l'intera esecuzione del test come verde o rosso.
Esaminiamo ora come possiamo implementare l'approccio descritto sopra. Come flusso di lavoro esemplare, ci concentreremo sui dati provenienti dalla competizione Kaggle Lending Club. Similmente a molte istituzioni finanziarie, vorremmo comprendere e prevedere i dati sul reddito individuale, ad esempio, per valutare il punteggio di credito di una domanda. Per fare ciò, analizziamo varie caratteristiche e attributi dei richiedenti, dall'occupazione attuale, alla proprietà della casa, all'istruzione, ai dati sulla posizione, allo stato civile e all'età. Queste sono le informazioni che una banca ha raccolto (ad esempio, nelle precedenti richieste di credito) e che ora vengono utilizzate per addestrare un modello di regressione.
Inoltre, sappiamo che il nostro business cambia dinamicamente e ci sono un gran numero di nuove osservazioni giornaliere. Con l'ingestione regolare di nuovi dati, il riaddestramento del modello è cruciale. Pertanto, l'attenzione è rivolta all'automazione completa dei job di riaddestramento e dell'intera pipeline di deployment continuo. Per garantire risultati di alta qualità e un'elevata potenza predittiva di un modello appena addestrato, aggiungiamo una fase di valutazione dopo ogni job di addestramento. Qui il modello ML viene valutato su un set di dati curato e confrontato con la versione di produzione attualmente distribuita. Pertanto, la promozione del modello può avvenire solo se la nuova iterazione ha un'elevata potenza predittiva.
Poiché un progetto è attivamente sviluppato e lavorato, il testing completamente automatizzato del nuovo codice e la promozione alla fase successiva del ciclo di vita utilizzano il framework Azure DevOps per la valutazione unit/integration su richieste di push/pull. I test sono orchestrati tramite il framework Azure DevOps ed eseguiti sulla piattaforma Databricks. Ciò copre la parte CI del processo, garantendo un'elevata copertura dei test del nostro codebase, minimizzando la supervisione umana.
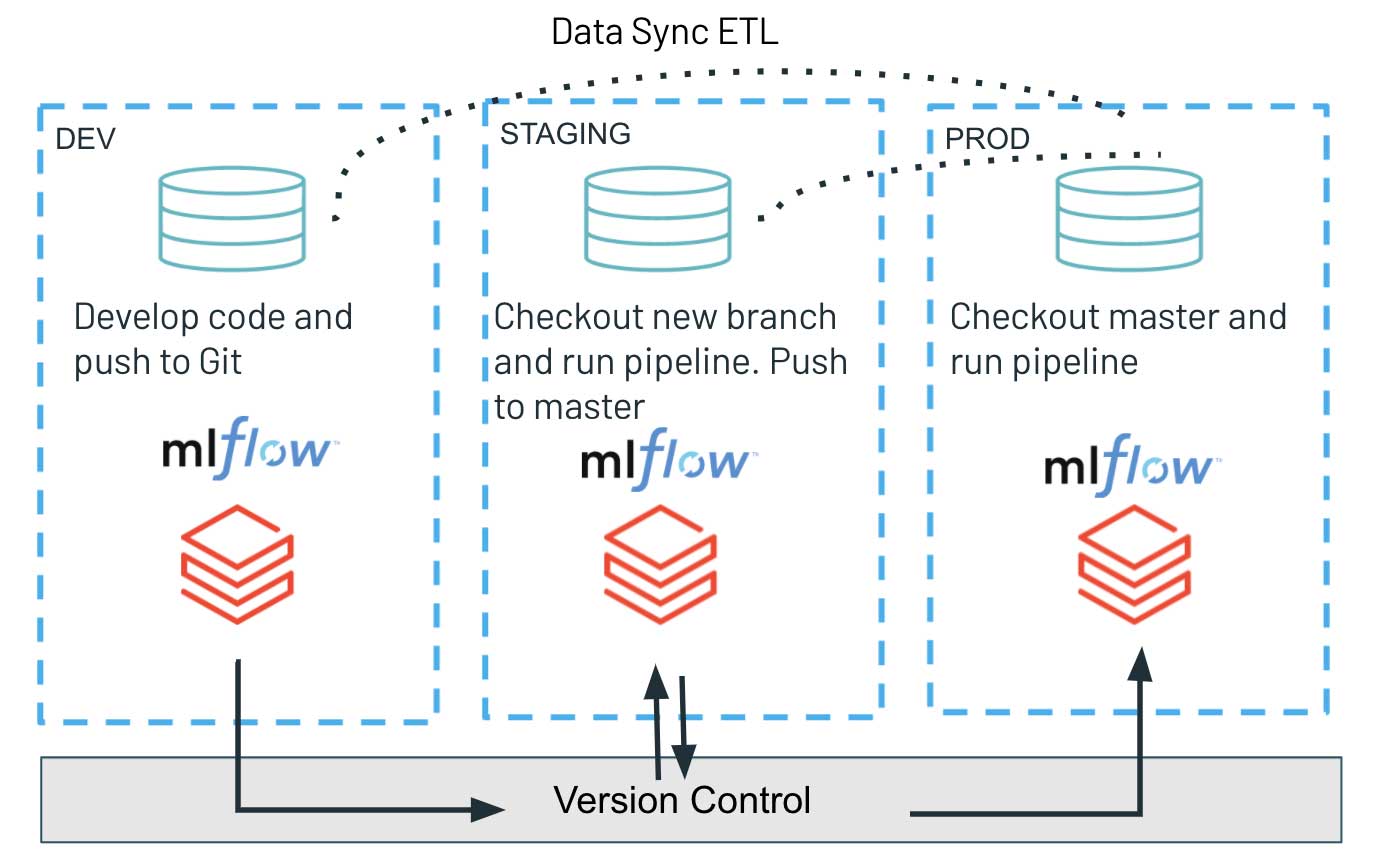
La parte di continuous delivery si basa esclusivamente su Repos API, dove utilizziamo l'interfaccia programmatica per effettuare il checkout dell'ultima versione del nostro codice nel branch Git e distribuire gli script più recenti per eseguire il workload. Ciò ci consente di semplificare il processo di distribuzione degli artefatti e di promuovere facilmente la versione di codice testata da ambienti di sviluppo tramite staging a produzione. Tale architettura garantisce il completo isolamento di vari ambienti ed è tipicamente favorita in ambienti con maggiore sicurezza. Le diverse fasi: dev, staging e prod condividono solo il sistema di controllo versione, minimizzando potenziali interferenze con workload di produzione altamente critici. Allo stesso tempo, il lavoro esplorativo e l'innovazione sono disaccoppiati poiché l'ambiente di sviluppo può avere controlli di accesso più flessibili.
Implementare la pipeline CI/CD utilizzando Azure DevOps e Databricks
Nel seguente repository di codice, abbiamo implementato il progetto ML con una pipeline CI/CD potenziata da Azure DevOps. In questo progetto, utilizziamo notebook per la preparazione dei dati e l'addestramento del modello.
Vediamo come possiamo testare questi notebook su Databricks. Azure DevOps è un framework molto popolare per flussi di lavoro CI/CD completi disponibili su Azure. Per ulteriori informazioni, consultare l'panoramica delle funzionalità fornite e le integrazioni continue con Databricks.
Utilizziamo la pipeline Azure DevOps come file YAML. La pipeline tratta i notebook Databricks come semplici file Python, quindi possiamo eseguirli all'interno della nostra pipeline CI/CD. Abbiamo inserito un file YAML per la nostra pipeline CI/CD Azure in azure-pipelines.yml. La parte più interessante di questo file è una chiamata a Databricks Repos API per aggiornare lo stato del progetto CI/CD su Databricks e una chiamata a Databricks Jobs API per attivare l'esecuzione del job di test di integrazione. Abbiamo sviluppato entrambi questi elementi nello script/notebook deploy.py. Possiamo chiamarlo nel seguente modo all'interno della pipeline Azure DevOps:
Le variabili d'ambiente DATABRICKS_HOST e DATABRICKS_TOKEN sono necessarie al pacchetto databricks_cli per autenticarci rispetto allo spazio di lavoro Databricks che stiamo utilizzando. Queste variabili possono essere gestite tramite gruppi di variabili Azure DevOps.
Esaminiamo ora lo script deploy.py. All'interno dello script, utilizziamo l'API databricks_cli per lavorare con Databricks Jobs API. Innanzitutto, dobbiamo creare un client API:
Successivamente, possiamo creare un nuovo Repo temporaneo su Databricks per il nostro progetto ed eseguire il pull dell'ultima revisione dal nostro Repo appena creato:
Successivamente, possiamo avviare l'esecuzione del job di test di integrazione su Databricks:
Infine, attendiamo il completamento del job e ne esaminiamo il risultato:
Lavorare con più workspace
L'utilizzo della Databricks Repos API per la CD può essere particolarmente utile per i team che mirano a un isolamento completo tra i loro ambienti di sviluppo/staging e produzione. La nuova funzionalità consente ai team di dati, tramite il codice sorgente su Databricks, di distribuire il codebase aggiornato e gli artefatti di un workload attraverso una semplice interfaccia di comando su più ambienti. Essere in grado di eseguire il checkout programmatico del codice sorgente più recente nel sistema di controllo versione garantisce un processo di rilascio tempestivo e semplice.
Per le pratiche MLOps, ci sono numerose considerazioni serie sulla giusta configurazione architetturale tra i vari ambienti. In questo studio, ci concentriamo solo sul paradigma dell'isolamento completo, che coprirebbe anche più istanze di MLflow associate a dev/staging/prod. In quest'ottica, i modelli addestrati in un ambiente di sviluppo non verrebbero spinti allo stadio successivo poiché gli oggetti serializzati vengono caricati attraverso un unico Model Registry comune. L'unico artefatto distribuito è il nuovo codebase della pipeline di addestramento che viene rilasciato ed eseguito nell'ambiente STAGING, con conseguente addestramento e registrazione di un nuovo modello con MLflow.
Questo principio di condivisione nulla, unito a una rigorosa gestione delle autorizzazioni sugli ambienti di produzione/staging, ma a pattern di accesso più rilassati in sviluppo, consente uno sviluppo software robusto e di alta qualità. Allo stesso tempo, offre un maggiore grado di libertà nell'istanza di sviluppo, accelerando l'innovazione e la sperimentazione tra il team di dati.
Riepilogo
In questo post del blog, abbiamo presentato un approccio end-to-end per le pipeline CI/CD su Databricks utilizzando progetti basati su notebook. Questo flusso di lavoro si basa sulla funzionalità Repos API che non solo consente ai team di dati di strutturare e versionare i propri progetti in modo più pratico, ma semplifica notevolmente l'implementazione e l'esecuzione degli strumenti CI/CD. Abbiamo mostrato un'architettura in cui tutti gli ambienti operativi sono completamente isolati, garantendo un elevato grado di sicurezza per i workload di produzione basati su ML.
Le pipeline CI/CD sono alimentate da un framework a scelta e si integrano perfettamente con la Databricks Unified Analytics Platform, attivando l'esecuzione del codice e il provisioning dell'infrastruttura end-to-end. La Repos API semplifica radicalmente non solo la gestione delle versioni, la strutturazione del codice e la parte di sviluppo del ciclo di vita di un progetto, ma anche la continuous delivery, consentendo di distribuire gli artefatti di produzione e il codice tra gli ambienti. È un miglioramento importante che contribuisce all'efficienza e alla scalabilità complessiva di Databricks e migliora notevolmente l'esperienza degli sviluppatori di software.
Il codice discusso può essere trovato qui.
Riferimenti:
- https://www.databricks.com/blog/2021/06/23/need-for-data-centric-ml-platforms.html
- Continuous Delivery for Machine Learning, Martin Fowler, https://martinfowler.com/articles/cd4ml.html,
- Overview of MLOps, https://www.kdnuggets.com/2021/03/overview-mlops.htm Introducing Azure DevOps, https://azure.microsoft.com/en-us/blog/introducing-azure-devops/
- Continuous integration and delivery on Azure Databricks using Azure DevOps, https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops
- Lending club Kaggle data set https://www.kaggle.com/wordsforthewise/lending-club
- Repos for Git integration https://docs.databricks.com/repos.html
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.