Che cosa è MLOps?
Pratiche e strumenti per distribuire, monitorare e gestire modelli di ML in produzione, collegando sviluppo e operazioni per sistemi di ML affidabili e riproducibili
- Copre l'intero ciclo di vita del ML, inclusi monitoraggio degli esperimenti, controllo delle versioni dei modelli, feature store, test automatizzati, pipeline CI/CD, containerizzazione e registro dei modelli per flussi di lavoro riproducibili di sviluppo e distribuzione.
- Implementa sistemi di monitoraggio che tracciano le metriche delle prestazioni del modello, la deriva dei dati, la latenza delle previsioni, l'utilizzo delle risorse e i KPI aziendali, con avvisi automatici e trigger di riaddestramento che mantengono la qualità del modello di produzione.
- Soddisfa i requisiti di governance tramite audit trail, controlli di accesso, monitoraggio della discendenza dei modelli, strumenti di spiegazione e documentazione di conformità, consentendo pratiche di intelligenza artificiale responsabili e conformità normativa.
Che cos'è MLOps?
MLOps sta per Machine Learning Operations. MLOps è una funzione chiave della tecnologia di Machine Learning, nata per snellire il processo che porta i modelli di machine learning in produzione e per le fasi successive di manutenzione e monitoraggio. MLOps è una funzione collaborativa che spesso coinvolge data scientist, tecnici DevOps e IT.
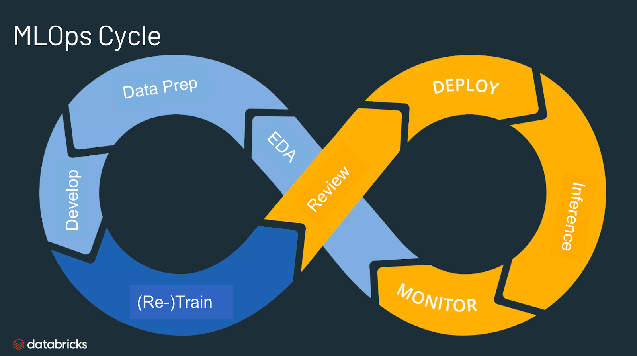
A che cosa serve MLOps?
MLOps è un approccio utile per la creazione e la qualità di soluzioni di machine learning e AI. Adottando un approccio MLOps, data scientist e tecnici di machine learning possono collaborare e accelerare lo sviluppo e la produzione di modelli, mettendo in atto pratiche di integrazione e implementazione continua (CI/CD) con adeguati processi di monitoraggio, convalida e governance di modelli ML.
Perché serve MLOps?
Produzionalizzare il machine learning è difficile. Il ciclo di vita del machine learning è costituito da numerosi componenti complessi, quali acquisizione e preparazione dei dati, addestramento e messa a punto dei modelli, monitoraggio e spiegabilità dei modelli, e molto altro. Richiede inoltre collaborazione e passaggi fra i vari team, dall'ingegneria dei dati alla data science, fino all'ingegneria ML. Naturalmente serve il massimo rigore operativo affinché tutti questi processi siano sincronizzati e funzionino in tandem. MLOps comprende la sperimentazione, l'iterazione e il miglioramento continuo del ciclo di vita del machine learning.
Quali sono i vantaggi di MLOps?
I benefici principali di MLOps sono efficienza, scalabilità e riduzione del rischio. Efficienza: MLOps consente ai team di gestione dei dati di velocizzare lo sviluppo dei modelli, realizzare modelli ML di qualità superiore e accelerare l'implementazione e la produzione. Scalabilità: MLOps favorisce anche una scalabilità e gestione su larga scala, potendo supervisionare, controllare, gestire e monitorare migliaia di modelli per attività di integrazione continua, fornitura continua e implementazione continua (CI/CD). In particolare, MLOps offre la riproducibilità delle pipeline ML, favorendo una collaborazione più stretta fra i team di gestione dei dati, riducendo i conflitti con DevOps e IT, e accelerando i tempi di rilascio. Riduzione del rischio: i modelli di machine learning devono spesso essere sottoposti a verifiche regolatorie e di deriva; MLOps offre maggiore trasparenza e risposte più rapide a queste richieste, oltre a una maggiore conformità alle politiche di un'organizzazione o di un settore industriale.
Quali sono i componenti di MLOps?
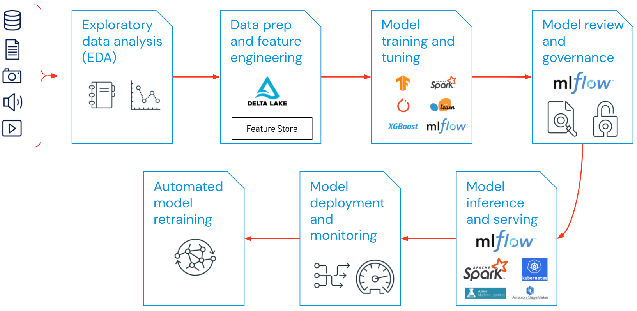
La portata di MLOps nei progetti di machine learning può essere più o meno ampia a seconda delle necessità del progetto stesso. In alcuni casi, MLOps può abbracciare tutto il percorso dalla pipeline di dati alla produzione del modello, mentre altri progetti possono richiedere l'implementazione MLOps del solo processo di realizzazione del modello. La maggior parte delle imprese applica i principi MLOps alle seguenti attività:
- Analisi esplorativa dei dati (EDA)
- Preparazione dei dati e ingegnerizzazione delle feature
- Addestramento e messa a punto di modelli
- Revisione e governance di modelli
- Inferenza di modelli e model serving
- Monitoraggio di modelli
- Riaddestramento automatizzato di modelli
Il playbook sull'AI agentiva per l'enterprise

Quali sono le best practice per MLOps?
Le best practice per MLOps possono essere delineate entro la fase in cui vengono applicati i principi MLOps.
- Analisi esplorativa dei dati (EDA) - Esplora, condividi e prepara i dati in modo iterativo per il ciclo di vita del machine learning, creando set di dati, tabelle e visualizzazioni riproducibili, editabili e condivisibili.
- Preparazione dei dati e ingegnerizzazione delle feature - Trasforma, aggrega e de-duplica i dati in modo iterativo per creare funzionalità raffinate. In particolare, rendi le funzionalità visibili e condivisibili per tutti i team di gestione dei dati, grazie a un negozio di funzionalità.
- Addestramento e messa a punto dei modelli - Usa librerie open-source comuni come scikit-learn e hyperopt per addestrare i modelli e migliorarne le prestazioni. Un'alternativa più semplice consiste nell'utilizzo di strumenti di machine learning automatizzati come AutoML per effettuare automaticamente prove di esecuzione e creare codice revisionabile e implementabile.
- Revisione e governance di modelli - Traccia la provenienza e le versioni dei modelli e gestisci gli artefatti e le transizioni dei modelli lungo tutto il ciclo di vita. Scopri, condividi e collabora su diversi modelli ML con l'ausilio di una piattaforma MLOps open-source come MLflow.
- Inferenza di modelli e model serving - Gestisci la frequenze di aggiornamento dei modelli, i tempi di richiesta delle inferenze e altri aspetti specifici della produzione in test e controllo di qualità. Usa strumenti CI/CD come repository e orchestratori (che attingono ai principi DevOps) per automatizzare la pipeline pre-produzione.
- Implementazione e monitoraggio di modelli - Automatizza i permessi e la creazione di cluster per produzionalizzare modelli registrati. Abilita gli endpoint del modello API REST.
- Riaddestramento automatizzato di modelli - Crea avvisi e automazioni per effettuare interventi correttivi in caso di deriva del modello dovuta a differenze fra i dati di addestramento e di inferenza.
Qual è la differenza fra MLOps e DevOps?
MLOps è un set di pratiche di ingegnerizzazione specifiche per progetti di machine learning che attinge ai principi DevOps più diffusamente adottati nell'ingegneria software. Mentre DevOps propone un approccio rapido e continuamente iterativo alla realizzazione di applicazioni, MLOps utilizza gli stessi principi per portare i modelli di machine learning in produzione. In entrambi i casi, i risultati sono una migliore qualità del software, patch e release più veloci e clienti più soddisfatti.
L'addestramento di modelli linguistici di grandi dimensioni (LLMOps) si differenzia dal tradizionale MLOps?
Molti concetti di MLOps restano validi, ma ci sono altri aspetti da considerare quando si addestrano modelli LLM come Dolly. Passiamo in rassegna alcuni aspetti chiave in cui l'addestramento di LLM potrebbe differire dal tradizionale approccio MLOps:
- Risorse di calcolo: Addestrare e mettere a punto modelli linguistici di grandi dimensioni comporta tipicamente l'esecuzione di calcoli su grandi set di dati con un'ordine di grandezza molto superiore alla norma. Per accelerare questo processo si utilizza hardware specializzato, come le GPU, in grado di elaborare i dati in parallelo molto più velocemente. Avere accesso a queste risorse di calcolo specializzate diventa essenziale sia per l'addestramento, sia per l'implementazione di modelli LLM. In virtù del costo dell'inferenza, sono altrettanto importanti le tecniche di compressione e distillazione dei modelli.
- Apprendimento per trasferimento: A differenza di molti modelli ML tradizionali che vengono creati o addestrati da zero, molti modelli LLM nascono da un modello base e vengono successivamente perfezionati con nuovi dati per migliorarne le prestazioni in ambiti specifici. Questa messa a punto assicura prestazioni allo stato dell'arte per applicazioni specifiche, utilizzando meno dati e meno risorse di calcolo.
- Feedback umano: I progressi più rilevanti nell'addestramento di modelli linguistici di grandi dimensioni sono stati ottenuti grazie all'apprendimento supportato dal feedback fornito da esseri umani (RLHF). In generale, poiché i modelli LLM devono spesso svolgere compiti "aperti", il riscontro da parte degli utilizzatori finale dell'applicazione è fondamentale per valutare le prestazioni di un modello. Integrando questo ciclo di feedback nelle pipeline LLMOps, si migliorano le prestazioni del modello LLM addestrato.
- Ottimizzazione degli iperparametri: Nel ML classico, la messa a punto degli iperparametri è spesso incentrata sul miglioramento della precisione o altre metriche. Per i modelli LLM, questa ottimizzazione diventa importante anche per ridurre il costo e la potenza di calcolo richiesta per addestramento e inferenza. Ad esempio, piccoli aggiustamenti alle dimensioni dei batch e alle tariffe di apprendimento possono cambiare radicalmente la velocità e i costi dell'addestramento. Quindi, sia il machine learning tradizionale, sia i modelli LLM traggono beneficio dal tracciamento e dall'ottimizzazione del processo di messa a punto, anche se in diversa misura.
- Metriche di prestazioni: I modelli ML tradizionali hanno metriche di prestazioni definite molto chiaramente, come accuratezza, AUC, punteggio F1 ecc. Queste metriche sono piuttosto semplici da calcolare. Quando si tratta di valutare modelli LLM, tuttavia, subentra una serie di metriche standard e punteggi completamente diversa, come gli algoritmi BLEU (Bilingual Evaluation Understudy) e ROGUE (Recall-Oriented Understudy for Gisting Evaluation), che richiedono ulteriori valutazioni in fase di implementazione.
Che cos'è una piattaforma MLOps?
Una piattaforma MLOps offre a data scientist e ingegneri software un ambiente collaborativo che favorisce l'esplorazione iterativa dei dati e offre funzionalità di collaborazione in tempo reale per il tracciamento di esperimenti, l'ingegnerizzazione di funzionalità e la gestione di modelli, oltre a processi controllati per la transizione, l'implementazione e il monitoraggio di modelli. MLOps automatizza gli aspetti di operatività e sincronizzazione del ciclo di vita del machine learning.
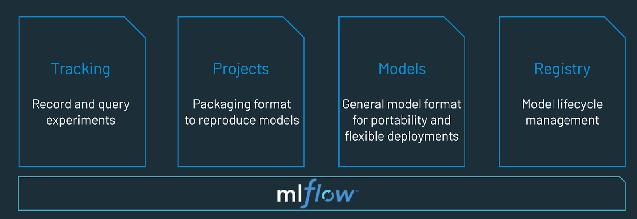
Prova Databricks, un ambiente completamente gestito per MLflow), la principale piattaforma MLOps aperta a livello mondiale. https://www.databricks.com/try/databricks-free-ml
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.