Introduzione ai Profili Dati nel Notebook Databricks
Semplificare l'analisi esplorativa dei dati
di Edward Gan, Moonsoo Lee e Austin Ford
Prima che uno scienziato dei dati possa scrivere un report di analisi o addestrare un modello di machine learning (ML), deve comprendere la struttura e il contenuto dei propri dati. Questa analisi esplorativa dei dati è iterativa, con ogni fase del ciclo che spesso coinvolge le stesse tecniche di base: visualizzazione delle distribuzioni dei dati e calcolo di statistiche riassuntive come conteggio delle righe, conteggio dei null, media, frequenze degli elementi, ecc. Sfortunatamente, generare manualmente queste visualizzazioni e statistiche è macchinoso e soggetto a errori, specialmente per grandi set di dati. Per affrontare questa sfida e semplificare l'analisi esplorativa dei dati, introduciamo le funzionalità di profilazione dei dati nel Notebook Databricks.
Profilazione dei dati nel Notebook
I team di dati che lavorano su un cluster con DBR 9.1 o versioni successive hanno due modi per generare profili dati nel Notebook: tramite l'interfaccia utente dell'output della cella e tramite la libreria dbutils. Quando si visualizzano i contenuti di un DataFrame utilizzando la funzione display di Databricks (AWS|Azure|Google) o i risultati di una query SQL, gli utenti vedranno una scheda “Profilo Dati” a destra della scheda “Tabella” nell'output della cella. Cliccando su questa scheda verrà eseguito automaticamente un nuovo comando che genera un profilo dei dati nel DataFrame. Il profilo includerà statistiche riassuntive per colonne numeriche, stringa e data, nonché istogrammi delle distribuzioni dei valori per ciascuna colonna. Si noti che questo comando profilerà l'intero set di dati nel DataFrame o nei risultati della query SQL, non solo la porzione visualizzata nella tabella (che può essere troncata).
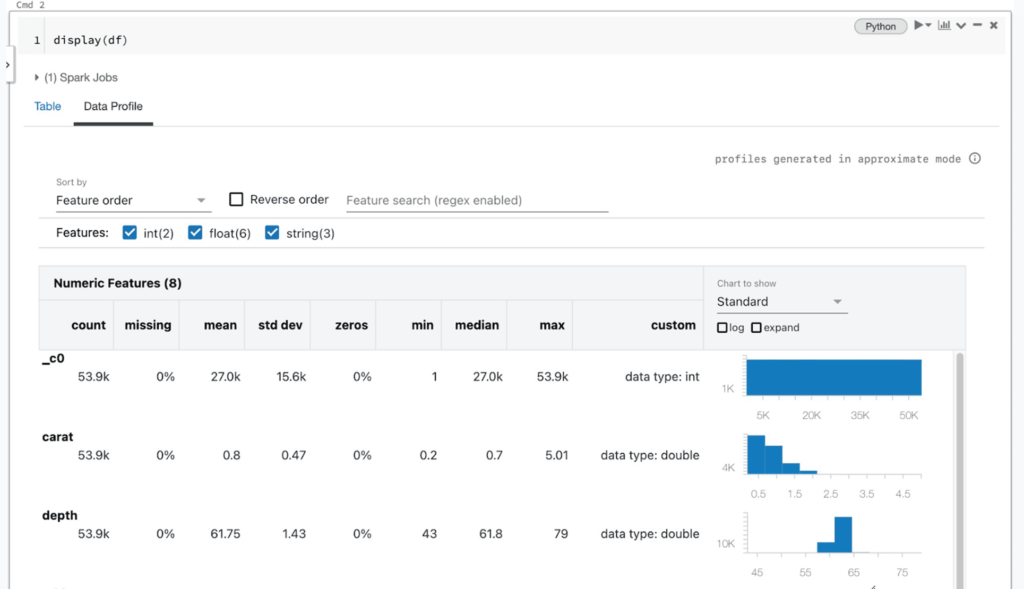
Sotto il cofano, l'interfaccia utente del notebook emette un nuovo comando per calcolare un profilo dati, che viene implementato tramite una query Apache Spark™ generata automaticamente per ciascun set di dati. Questa funzionalità è disponibile anche tramite l'API dbutils in Python, Scala e R, utilizzando il comando dbutils.data.summarize(df). Per ulteriori informazioni, consultare la documentazione (AWS|Azure|Google).
Prova oggi stesso i profili dati durante l'anteprima dei DataFrame nei notebook Databricks!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.