Implementazione del ripristino di emergenza per un'area di lavoro Databricks
di Ankit Shah e Lorin Dawson
Questo post è una continuazione di Panoramica, strategie e valutazione del Disaster Recovery e Automazione e strumenti di Disaster Recovery per un workspace Databricks.
Il Disaster Recovery (DR) si riferisce a un insieme di policy, strumenti e procedure che consentono il recupero o la continuazione di infrastrutture e sistemi tecnologici critici dopo un disastro naturale o causato dall'uomo. Anche se i Cloud Service Provider come AWS, Azure, Google Cloud e le aziende SaaS implementano misure di protezione contro i singoli punti di guasto, i guasti si verificano. La gravità dell'interruzione e il suo impatto su un'organizzazione possono variare. Per i carichi di lavoro cloud-native, un modello di disaster recovery chiaro è fondamentale.
Configurazione del Disaster Recovery per Databricks
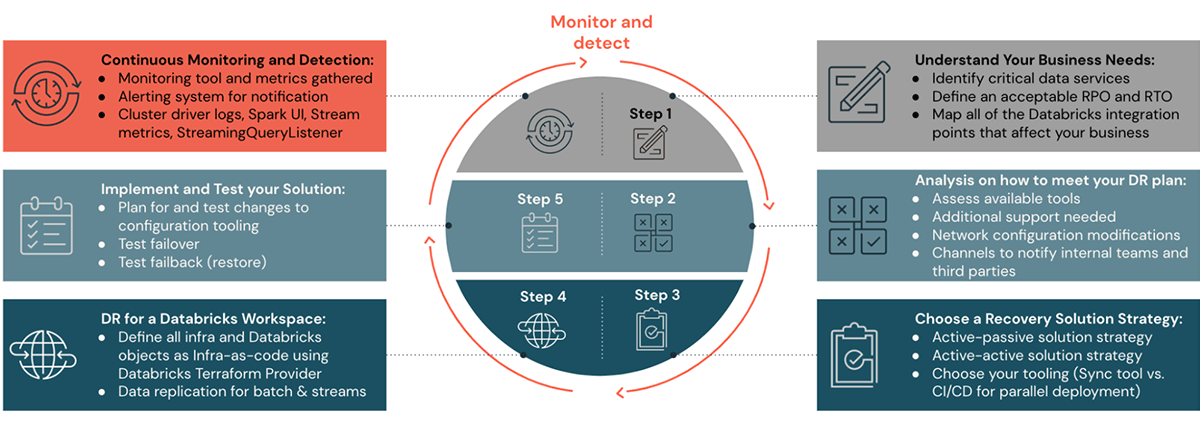
Si prega di consultare i precedenti post del blog di questa serie di blog sul DR per comprendere i passaggi da uno a quattro su come pianificare, impostare una strategia di soluzione DR e automatizzare. Nei passaggi cinque e sei di questo post del blog, esamineremo come monitorare, eseguire e convalidare una configurazione DR.
Soluzione di Disaster Recovery
Una tipica implementazione Databricks include una serie di asset critici, come codice sorgente dei notebook, query, configurazioni di job e cluster, che devono essere recuperati senza problemi per garantire un'interruzione minima e un servizio continuativo agli utenti finali.
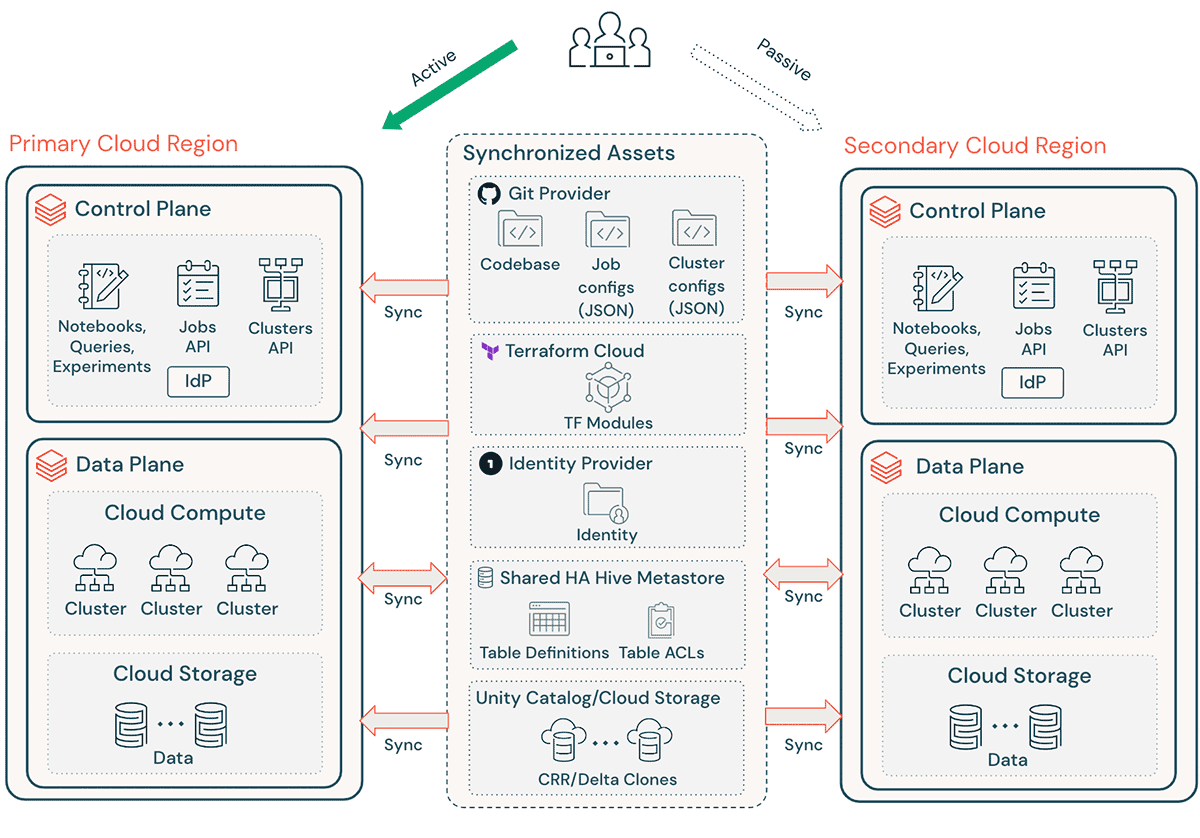
Considerazioni di alto livello sul DR:
- Assicurati che la tua architettura sia replicabile tramite Terraform (TF), rendendo possibile creare e ricreare questo ambiente altrove.
- Utilizza Databricks Repos (AWS | Azure | GCP) per sincronizzare Notebook e codice applicativo in file arbitrari supportati (AWS | Azure | GCP).
- Utilizza Terraform Cloud per attivare le esecuzioni TF (plan e apply) per pipeline di infrastruttura e applicazioni, mantenendo lo stato.
- Replica i dati dagli account di storage cloud come Amazon S3, Azure ADLS e GCS nella regione DR. Se sei su AWS, puoi anche archiviare i dati utilizzando S3 Multi-Region Access Points in modo che i dati si estendano su più bucket S3 in diverse regioni AWS.
- Le definizioni dei cluster Databricks possono contenere informazioni specifiche della zona di disponibilità. Utilizza l'attributo cluster “auto-az” quando esegui Databricks su AWS per evitare problemi durante il failover regionale.
- Gestisci il configuration drift nella Regione DR. Assicurati che la tua infrastruttura, i dati e la configurazione siano come necessario nella Regione DR.
- Per il codice e gli asset di produzione, utilizza strumenti CI/CD che inviano contemporaneamente modifiche ai sistemi di produzione in entrambe le regioni. Ad esempio, quando si invia codice e asset da staging/sviluppo a produzione, un sistema CI/CD li rende disponibili in entrambe le regioni contemporaneamente.
- Utilizza Git per sincronizzare i file TF e la codebase dell'infrastruttura, le configurazioni dei job e le configurazioni dei cluster.
- Le configurazioni specifiche della regione dovranno essere aggiornate prima di eseguire il `apply` TF in una regione secondaria.
Nota: alcuni servizi come Feature Store, pipeline MLflow, tracciamento esperimenti ML, gestione modelli e deployment di modelli non possono essere considerati fattibili al momento per il Disaster Recovery. Per Structured Streaming e Delta Live Tables, è necessario un deployment attivo-attivo per mantenere garanzie exactly-once, ma la pipeline avrà una consistenza eventuale tra le due regioni.
Ulteriori considerazioni di alto livello sono disponibili nei precedenti post di questa serie.
Monitoraggio e Rilevamento
È fondamentale sapere il prima possibile se i tuoi carichi di lavoro non sono in uno stato sano, in modo da poter dichiarare rapidamente un disastro e recuperare da un incidente. Questo tempo di risposta, unito alle informazioni appropriate, è fondamentale per raggiungere obiettivi di recupero aggressivi. È fondamentale considerare il rilevamento degli incidenti, la notifica, l'escalation, la scoperta e la dichiarazione nella tua pianificazione e nei tuoi obiettivi per fornire obiettivi realistici e raggiungibili.
Notifiche sullo stato del servizio
La Pagina di stato Databricks fornisce una panoramica di tutti i servizi Databricks core per il control plane. Puoi visualizzare facilmente lo stato di un servizio specifico consultando la pagina di stato. Facoltativamente, puoi anche iscriverti agli aggiornamenti di stato sui singoli componenti del servizio, che inviano un avviso ogni volta che lo stato a cui sei iscritto cambia.
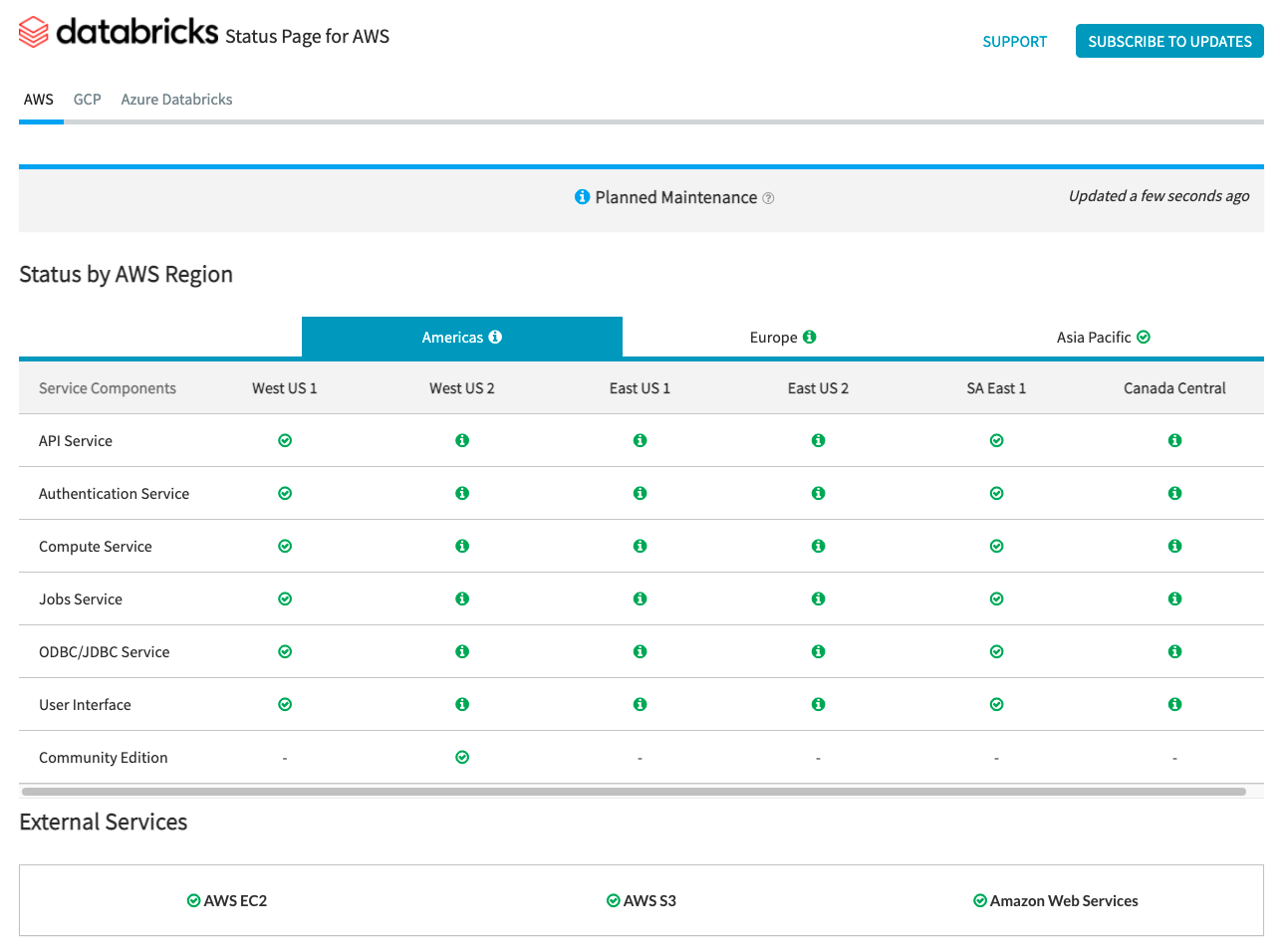
Per i controlli di stato relativi al data plane, è necessario utilizzare AWS Health Dashboard, Azure Status Page e GCP Service Health Page per il monitoraggio.
AWS e Azure offrono endpoint API che gli strumenti possono utilizzare per acquisire e avvisare sui controlli di stato.
Monitoraggio e allertamento dell'infrastruttura
L'utilizzo di uno strumento per raccogliere e analizzare dati dall'infrastruttura consente ai team di monitorare le prestazioni nel tempo. Ciò potenzia proattivamente i team per ridurre al minimo i tempi di inattività e il degrado del servizio complessivo. Inoltre, il monitoraggio nel tempo stabilisce una baseline per le prestazioni di picco necessaria come riferimento per ottimizzazioni e allertamento.
Nel contesto del DR, un'organizzazione potrebbe non essere in grado di attendere gli avvisi dai propri provider di servizi. Anche se i requisiti RTO/RPO sono sufficientemente permissivi da attendere un avviso dal provider di servizi, notificare in anticipo il team di supporto del fornitore aprirà una linea di comunicazione anticipata.
DataDog e Dynatrace sono strumenti di monitoraggio popolari che forniscono integrazioni e agenti per AWS, Azure, GCP e cluster Databricks.
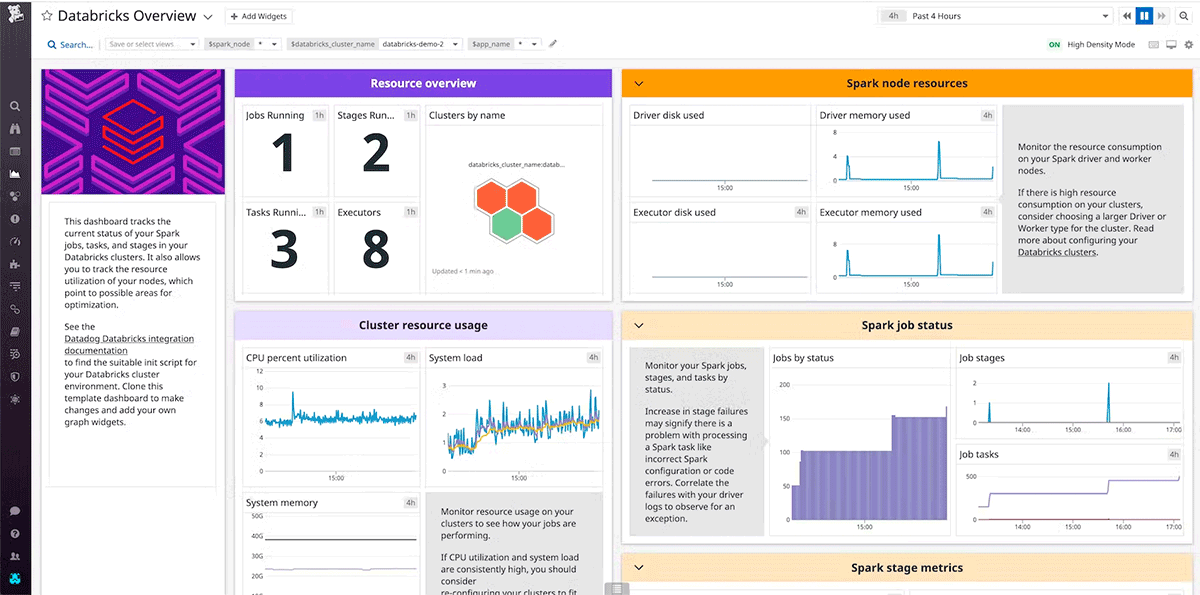
Health Check
Per i requisiti RTO più stringenti, è possibile implementare il failover automatico basato sugli health check dei Servizi Databricks e di altri servizi con cui il carico di lavoro interagisce direttamente nel Data Plane, ad esempio, object store e servizi VM dei provider cloud.
Progetta health check che siano rappresentativi dell'esperienza utente e basati su Key Performance Indicator (KPI). Gli health check superficiali (heartbeat) possono valutare se il sistema è operativo, ovvero se il cluster è in esecuzione. Mentre gli health check approfonditi, come le metriche di sistema della CPU dei singoli nodi, l'utilizzo del disco e le metriche Spark per ogni stage attivo o partizione memorizzata nella cache, vanno oltre i semplici heartbeat per determinare un degrado significativo delle prestazioni. Utilizza health check approfonditi basati su più segnali in base alla funzionalità e alle prestazioni di base del carico di lavoro.
Esercita cautela se automatizzi completamente la decisione di failover utilizzando i controlli di integrità. Se si verificano falsi positivi o viene attivato un allarme, ma l'azienda può assorbire l'impatto, non è necessario eseguire il failover. Un falso failover introduce rischi di disponibilità e rischi di corruzione dei dati, ed è un'operazione costosa in termini di tempo. Si raccomanda di avere un human-in-loop, come un responsabile degli incidenti on-call, per prendere la decisione se viene attivato un allarme. Un failover non necessario può essere catastrofico e la revisione aggiuntiva aiuta a determinare se il failover è richiesto.
Esecuzione di una Soluzione di DR
A grandi linee, esistono due scenari di esecuzione per una soluzione di Disaster Recovery (DR). Nel primo scenario, il sito di DR è considerato temporaneo. Una volta ripristinato il servizio nel sito primario, la soluzione deve orchestrare un failover dal sito di DR al sito primario permanente. Limitare la creazione di nuovi artefatti mentre il sito di DR è attivo dovrebbe essere scoraggiato poiché è temporaneo e complica il failback in questo scenario. Al contrario, nel secondo scenario, il sito di DR verrà promosso a nuovo primario, consentendo agli utenti di riprendere il lavoro più velocemente poiché non devono attendere il ripristino dei servizi. Inoltre, questo scenario non richiede failback, ma il sito primario precedente deve essere preparato come nuovo sito di DR.
In entrambi gli scenari, ogni regione nell'ambito della soluzione di DR dovrebbe supportare tutti i servizi richiesti, e un processo che convalida che l'area di lavoro di destinazione sia in buone condizioni operative deve esistere come salvaguardia. La convalida può includere autenticazione simulata, query automatizzate, chiamate API e controlli ACL.
Failover
Quando si attiva un failover al sito di DR, la soluzione non può presumere che sia possibile arrestare il sistema in modo ordinato. La soluzione dovrebbe tentare di arrestare i servizi in esecuzione nel sito primario, registrare lo stato di arresto per ciascun servizio, quindi continuare a tentare di arrestare i servizi senza lo stato appropriato a intervalli di tempo definiti. Ciò riduce il rischio che i dati vengano elaborati simultaneamente nei siti primario e di DR, minimizzando la corruzione dei dati e facilitando il processo di failback una volta ripristinati i servizi.
I passaggi principali per attivare il sito di DR includono:
- Eseguire un processo di arresto sul sito primario per disabilitare pool, cluster e job pianificati nella regione primaria in modo che, se il servizio guasto ritorna online, la regione primaria non inizi a elaborare nuovi dati.
- Confermare che l'infrastruttura e le configurazioni del sito di DR siano aggiornate.
- Controllare la data dei dati sincronizzati più recenti. Vedere Terminologia del settore del disaster recovery. I dettagli di questo passaggio variano in base a come si sincronizzano i dati e alle esigenze aziendali specifiche.
- Stabilizzare le origini dati e assicurarsi che siano tutte disponibili. Includere tutte le origini dati esterne critiche, come object storage, database, sistemi pub/sub, ecc.
- Informare gli utenti della piattaforma.
- Avviare i pool pertinenti (o aumentare il numero di istanze inattive minime a numeri pertinenti).
- Avviare i cluster, i job e gli SQL Warehouse pertinenti (se non terminati).
- Modificare l'esecuzione concorrente per i job ed eseguire i job pertinenti. Questi potrebbero essere job eseguiti una tantum o periodici.
- Attivare le pianificazioni dei job.
- Per qualsiasi strumento esterno che utilizza un URL o un nome di dominio per la tua area di lavoro Databricks, aggiornare le configurazioni per tenere conto del nuovo piano di controllo. Ad esempio, aggiornare gli URL per le API REST e le connessioni JDBC/ODBC. L'URL rivolto ai clienti dell'applicazione web Databricks cambia quando cambia il piano di controllo, quindi informa gli utenti della tua organizzazione del nuovo URL.
Failback
Il ritorno al sito primario durante il Failback è più facile da controllare e può essere eseguito in una finestra di manutenzione. Il Failback seguirà un piano molto simile al Failover, con quattro eccezioni principali:
- La regione di destinazione sarà la regione primaria.
- Poiché il Failback è un processo controllato, l'arresto è un'attività una tantum che non richiede controlli di stato per arrestare i servizi mentre tornano online.
- Il sito di DR dovrà essere reimpostato secondo necessità per eventuali failover futuri.
- Qualsiasi lezione appresa dovrebbe essere incorporata nella soluzione di DR e testata per futuri eventi di disastro.
Conclusione
Testa regolarmente la tua configurazione di disaster recovery in condizioni reali per assicurarti che funzioni correttamente. Ha poco senso mantenere una soluzione di disaster recovery che non può essere utilizzata quando è necessaria. Alcune organizzazioni testano la loro infrastruttura di DR eseguendo failover e failback tra regioni ogni pochi mesi. Regolarmente, il failover al sito di DR testa le tue ipotesi e i tuoi processi per garantire che soddisfino i requisiti di ripristino in termini di RPO e RTO. Ciò garantisce anche che le politiche e le procedure di emergenza della tua organizzazione siano aggiornate. Testa eventuali modifiche organizzative richieste ai tuoi processi e alle tue configurazioni in generale. Il tuo piano di disaster recovery ha un impatto sulla tua pipeline di deployment, quindi assicurati che il tuo team sia consapevole di ciò che deve essere mantenuto in sincronia.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.