Modellazione visiva dei dati tramite erwin Data Modeler di Quest sulla Databricks Lakehouse Platform
Modellazione dei dati tramite erwin su Databricks
di Vani Mishra, Abhishek Dey, Leo Mao, Soham Bhatt e Pradeep Anandapu
Questo è un post collaborativo tra Databricks e Quest Software. Ringraziamo Vani Mishra, Director of Product Management presso Quest Software per il suo contributo.
Data Modeling using erwin Data Modeler
Man mano che i clienti modernizzano il loro patrimonio di dati per Databricks, stanno consolidando vari data mart e EDW in un'unica architettura lakehouse scalabile che supporta ETL, BI e AI. Di solito, uno dei primi passi di questo percorso inizia con la valutazione dei modelli di dati esistenti dei sistemi legacy e la loro razionalizzazione e conversione nelle zone Bronze, Silver e Gold dell'architettura Databricks Lakehouse. Uno strumento di data modeling robusto in grado di visualizzare, progettare, distribuire e standardizzare gli asset di dati del lakehouse semplifica notevolmente il percorso di progettazione e migrazione del lakehouse, nonché accelera gli aspetti di data governance.
Siamo lieti di annunciare la nostra partnership e l'integrazione di erwin Data Modeler by Quest con la Databricks Lakehouse Platform per soddisfare queste esigenze. I data modeler possono ora modellare e visualizzare le strutture dati del lakehouse con erwin Data Modeler per creare modelli di dati logici e fisici per accelerare la migrazione a Databricks. I data modeler e gli architetti possono rapidamente reingegnerizzare o ricostruire database e le loro tabelle e viste sottostanti su Databricks. Ora puoi accedere facilmente a erwin Data Modeler da Databricks Partner Connect!
Ecco alcuni dei motivi principali per cui gli strumenti di data modeling come erwin Data Modeler sono importanti:
- Migliore comprensione dei dati: gli strumenti di data modeling forniscono una rappresentazione visiva di strutture dati complesse, rendendo più facile per gli stakeholder comprendere le relazioni tra i diversi elementi di dati.
- Maggiore accuratezza e coerenza: gli strumenti di data modeling possono aiutare a garantire che i database siano progettati con accuratezza e coerenza, riducendo il rischio di errori e incoerenze nei dati.
- Facilitare la collaborazione: con gli strumenti di data modeling, più stakeholder possono collaborare alla progettazione di un database, garantendo che tutti siano sulla stessa lunghezza d'onda e che lo schema risultante soddisfi le esigenze di tutti gli stakeholder.
- Migliori prestazioni del database: database ben progettati possono migliorare le prestazioni delle applicazioni che si basano su di essi, portando a un'elaborazione dei dati più rapida ed efficiente.
- Manutenzione più semplice: con un database ben progettato, le attività di manutenzione come l'aggiunta di nuovi elementi di dati o la modifica di quelli esistenti diventano più semplici e meno soggette a errori.
- Miglioramento della data governance, della data intelligence e della gestione dei metadati.
In questo blog, dimostreremo tre scenari su come erwin Data Modeler può essere utilizzato con Databricks:
- Il primo scenario è in cui un team vuole creare un nuovo Entity Relationship Diagram (ERD) basato sulla documentazione del team di business. L'obiettivo è creare un diagramma ER per il modello logico che un'unità aziendale possa comprendere e applicare relazioni, definizioni e regole aziendali così come applicate nel sistema. Sulla base di questo modello logico, costruiremo anche un modello fisico per Databricks.
- Nel secondo scenario, l'unità aziendale sta costruendo un modello di dati visivo tramite reverse engineering dal loro attuale ambiente Databricks, per comprendere definizioni aziendali, relazioni e prospettive di governance, al fine di collaborare con il team di reporting e governance.
- Nel terzo scenario, il team di architetti della piattaforma sta consolidando i propri vari Enterprise Data Warehouse (EDW) e data mart come Oracle, SQL Server, Teradata, MongoDB, ecc. nella piattaforma Databricks Lakehouse e costruendo un modello Master consolidato.
Una volta completata la creazione dell'ERD, ti mostreremo come generare un file DDL/SQL per il team di progettazione fisica di Databricks.
Scenario #1: Creare un nuovo modello di dati logico e fisico da implementare in Databricks
Il primo passo sarà la selezione di un modello Logico/Fisico come mostrato qui:
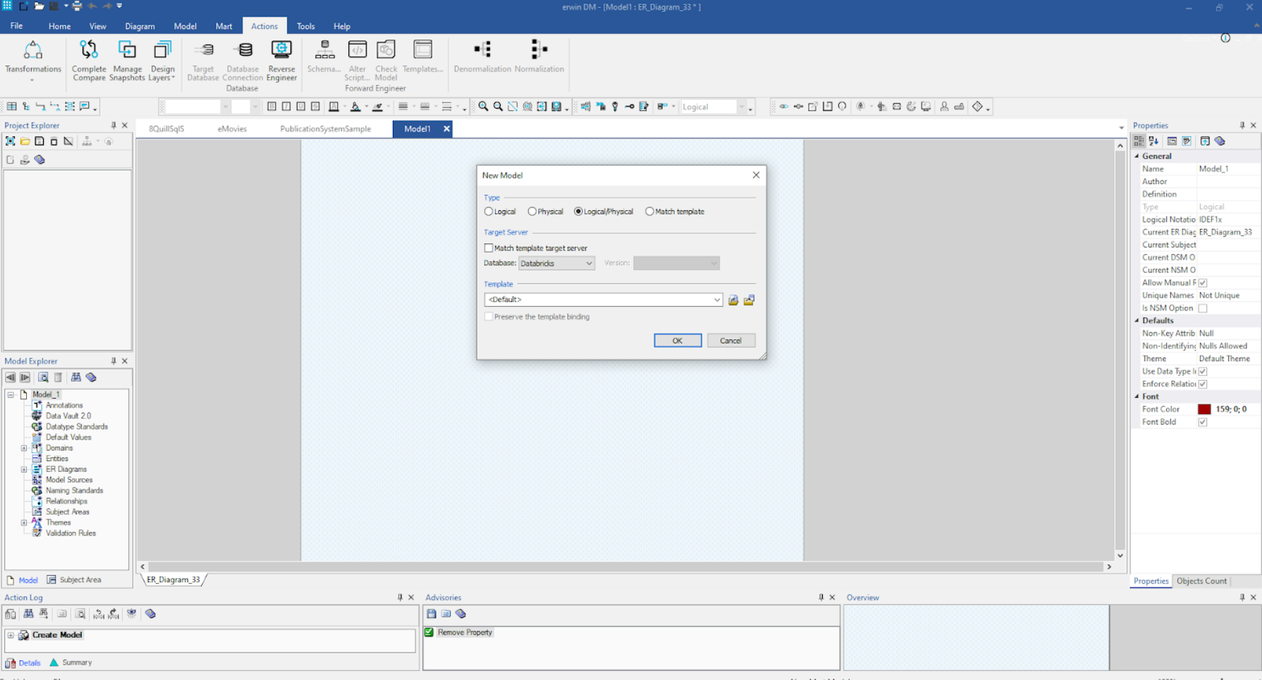
Una volta selezionato, puoi iniziare a costruire le tue entità, attributi, relazioni, definizioni e altri dettagli in questo modello.
Lo screenshot seguente mostra un esempio di modello avanzato:
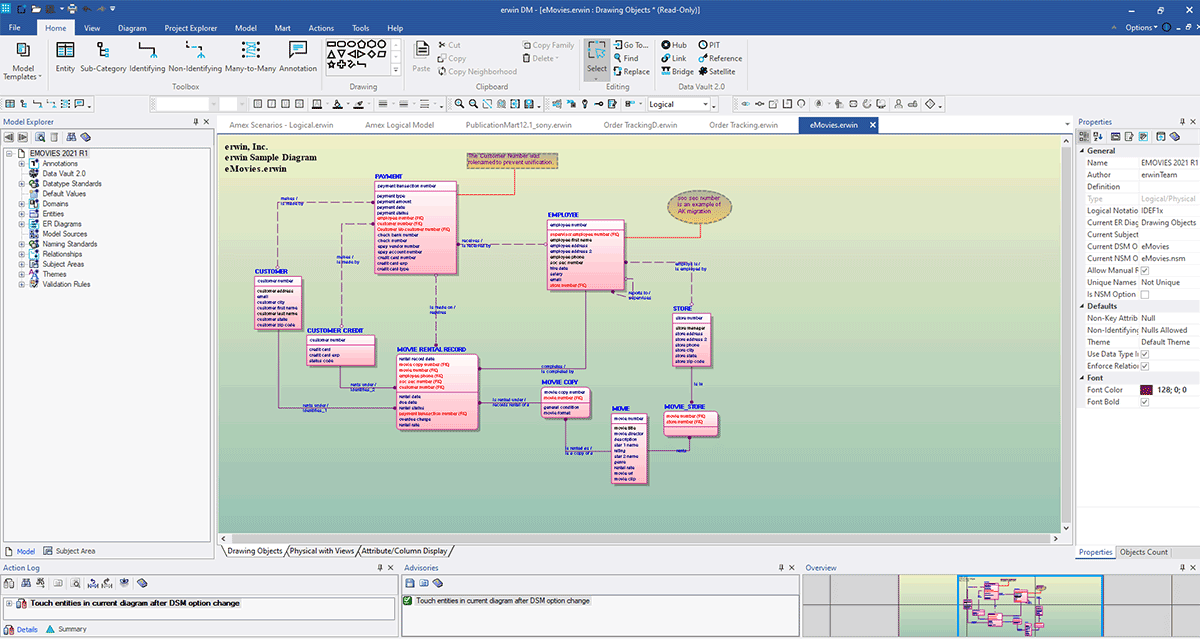
Qui puoi costruire il tuo modello e documentare i dettagli secondo necessità. Per saperne di più su come utilizzare erwin Data modeler, fai riferimento alla loro documentazione di aiuto online.
Scenario #2: Reverse Engineering di un modello di dati dalla Databricks Lakehouse Platform
Il reverse engineering di un modello di dati consiste nel creare un modello di dati da un database o script esistente. Lo strumento di modellazione crea una rappresentazione grafica degli oggetti del database selezionati e delle relazioni tra gli oggetti. Questa rappresentazione grafica può essere un modello logico o fisico.
Ci connetteremo a Databricks da erwin Data modeler tramite Partner Connect:
Opzioni di connessione:
| Parametro | Descrizione | Informazioni aggiuntive |
|---|---|---|
| Tipo di connessione | Specifica il tipo di connessione che si desidera utilizzare. Selezionare Usa origine dati ODBC per connettersi utilizzando l'origine dati ODBC definita. Selezionare Usa connessione JDBC per connettersi tramite JDBC. | |
| Origine dati ODBC | Specifica l'origine dati a cui si desidera connettersi. L'elenco a discesa mostra le origini dati definite sul computer. | Questa opzione è disponibile solo quando il Tipo di connessione è impostato su Usa origine dati ODBC. |
| Invoca amministratore ODBC. | Specifica se si desidera avviare il software Amministratore ODBC e visualizzare la finestra di dialogo Seleziona origine dati. È quindi possibile selezionare un'origine dati definita in precedenza o crearne una nuova. | Questa opzione è disponibile solo quando il Tipo di connessione è impostato su Usa origine dati ODBC. |
| Stringa di connessione | Specifica la stringa di connessione in base all'istanza JDBC nel seguente formato: jdbc:spark://<server-hostname>:443/default;transportMode=http;ssl=1;httpPath=<http-path> | Questa opzione è disponibile solo quando il Tipo di connessione è impostato su Usa connessione JDBC. Ad esempio: jdbc:spark://<url>.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<workspaceid>/xxxx |
Lo screenshot seguente mostra la connettività JDBC tramite erwin DataModeler al Databricks SQL Warehouse.
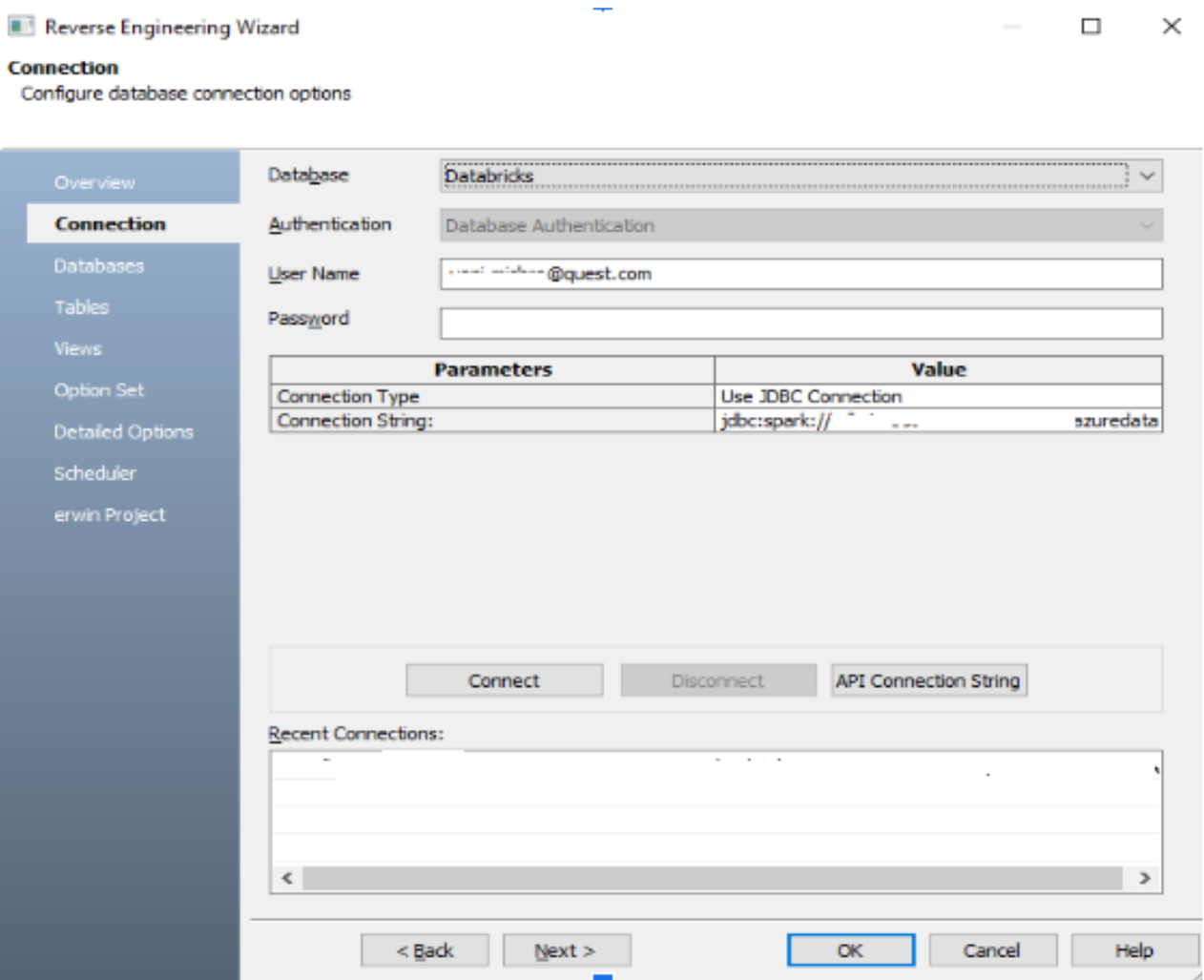
Ci consente di visualizzare tutti i database disponibili e selezionare in quale database costruire il nostro modello ERD, come mostrato di seguito.
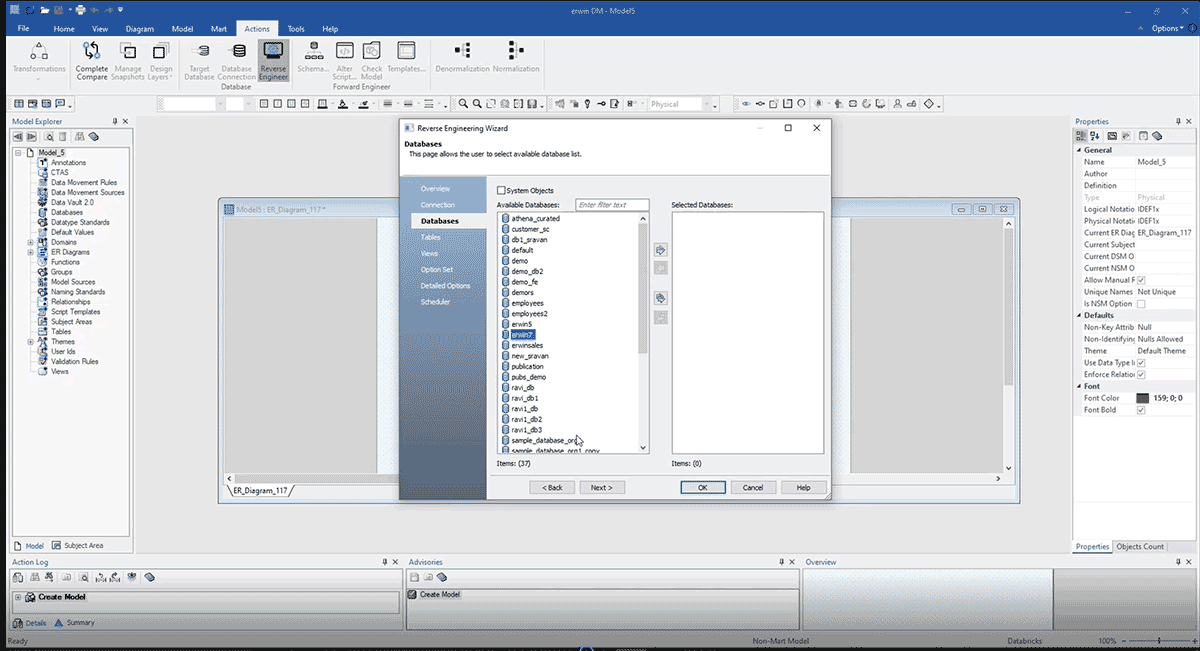
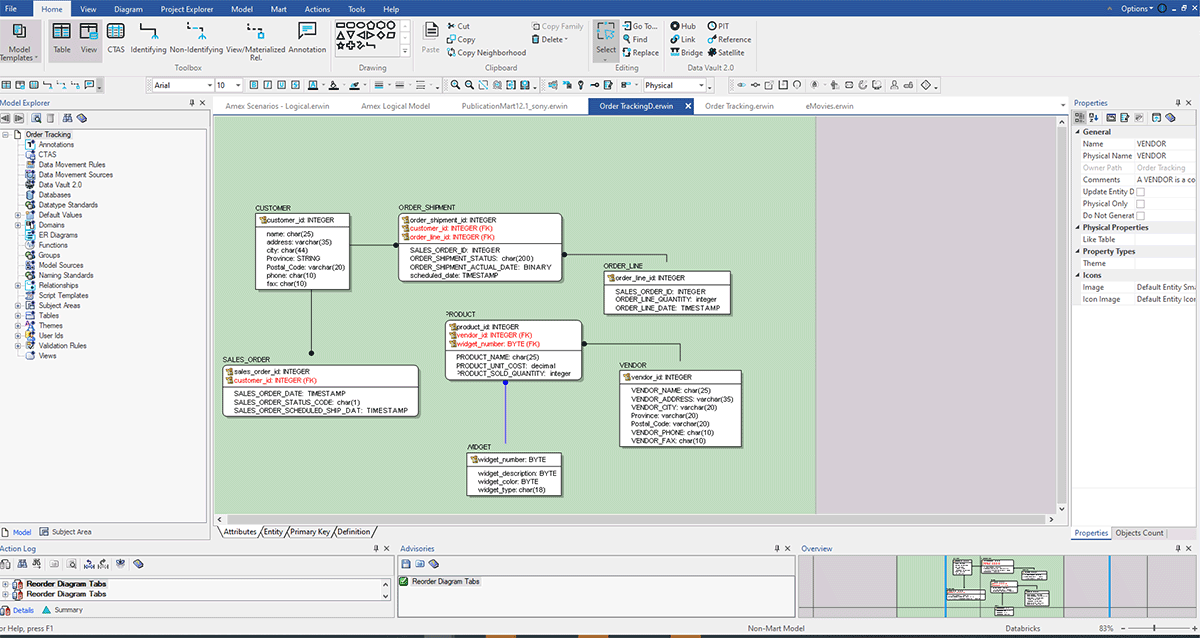
Lo screenshot sopra mostra un ERD creato dopo il reverse engineering da Databricks con il metodo sopra descritto. Ecco alcuni vantaggi del reverse engineering di un modello di dati:
- Migliore comprensione dei sistemi esistenti: effettuando il reverse engineering di un sistema esistente, è possibile comprendere meglio come funziona e come interagiscono le sue varie componenti. Aiuta a identificare eventuali problemi o aree di miglioramento.
- Risparmio sui costi: il reverse engineering può aiutare a identificare le inefficienze in un sistema esistente, portando a risparmi sui costi ottimizzando i processi o identificando aree di risorse dispendiose.
- Risparmio di tempo: il reverse engineering può far risparmiare tempo consentendo di riutilizzare codice o strutture dati esistenti anziché partire da zero.
- Migliore documentazione: il reverse engineering può aiutare a creare una documentazione accurata e aggiornata per un sistema esistente, che può essere utile per la manutenzione e lo sviluppo futuro.
- Migrazione semplificata: L'ingegneria inversa può aiutarti a comprendere le strutture e le relazioni dei dati in un sistema esistente, facilitando la migrazione dei dati a un nuovo sistema o database.
Nel complesso, l'ingegneria inversa è preziosa e un passo fondamentale per la modellazione dei dati. L'ingegneria inversa consente una comprensione più approfondita di un sistema esistente e dei suoi componenti, un accesso controllato al processo di progettazione aziendale, piena trasparenza attraverso il ciclo di vita della modellazione, miglioramenti dell'efficienza, risparmio di tempo e costi e una migliore documentazione che porta a migliori obiettivi di governance.
Scenario n. 3: Migrare modelli di dati esistenti a Databricks.
Gli scenari sopra descritti presuppongono che tu stia lavorando con una singola origine dati, ma la maggior parte delle aziende dispone di diversi data mart e EDW per supportare le proprie esigenze di reporting. Immagina che la tua azienda rientri in questa descrizione e stia ora intraprendendo la creazione di un Databricks Lakehouse per consolidare le sue piattaforme dati nel cloud in un'unica piattaforma unificata per BI e AI. In quella situazione, sarà facile utilizzare erwin Data Modeler per convertire i tuoi modelli di dati esistenti da un EDW legacy a un modello di dati Databricks. Nell'esempio seguente, un modello di dati creato per un EDW come SQL Server, Oracle o Teradata può ora essere implementato in Databricks modificando il database di destinazione in Databricks.
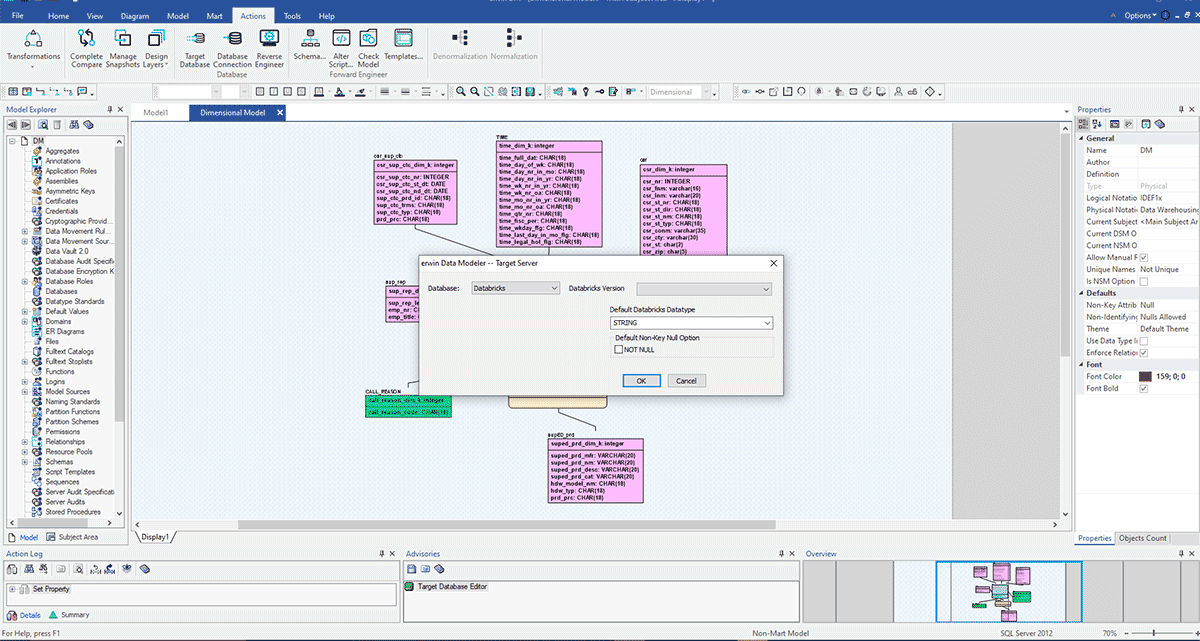
Come puoi vedere nell'area cerchiata, questo modello è stato creato per SQL Server. Ora convertiremo questo modello e migreremo la sua implementazione a Databricks modificando il server di destinazione. Questo tipo di facile conversione dei tuoi modelli di dati aiuta le organizzazioni a migrare rapidamente e in sicurezza i modelli di dati da database legacy o on-premise al cloud e a governare tali set di dati durante il loro ciclo di vita.
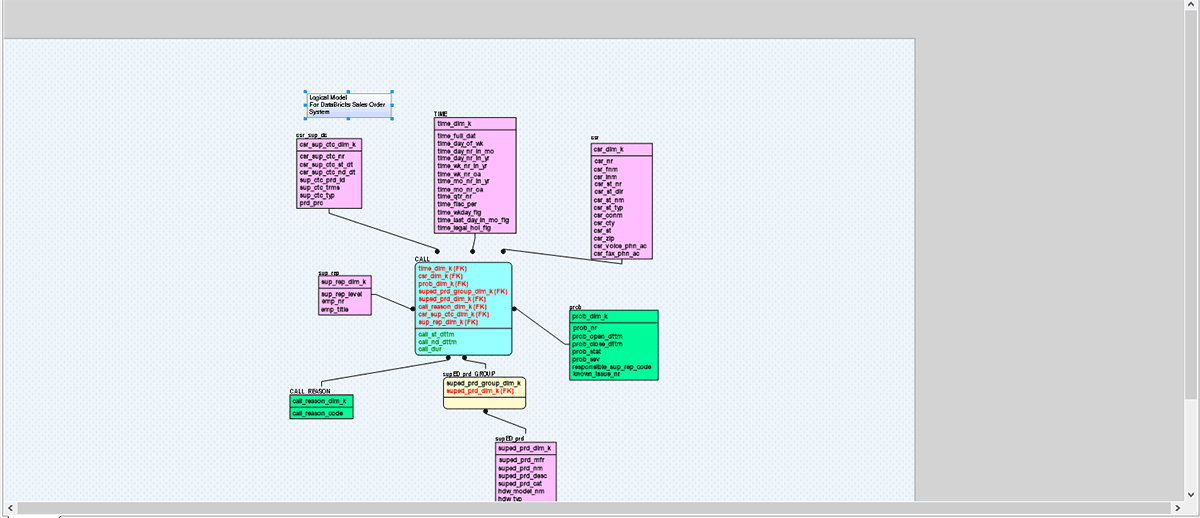
Nell'immagine sopra, abbiamo provato a convertire un modello di dati legacy basato su SQL Server in Databricks con pochi semplici passaggi. Questo tipo di percorso di migrazione semplificato consente e aiuta le organizzazioni a migrare rapidamente e in sicurezza i propri dati e asset a Databricks, incoraggia la collaborazione remota e migliora la sicurezza.
Ora passiamo alla nostra parte finale; una volta che l'ER Model è pronto e approvato dal team di architettura dei dati, puoi generare rapidamente un file .sql da erwin DM o connetterti a Databricks e ingegnerizzare in avanti questo modello direttamente su Databricks.
Segui gli screenshot qui sotto, che spiegano il processo passo dopo passo per creare un file DDL o un modello di database per Databricks.
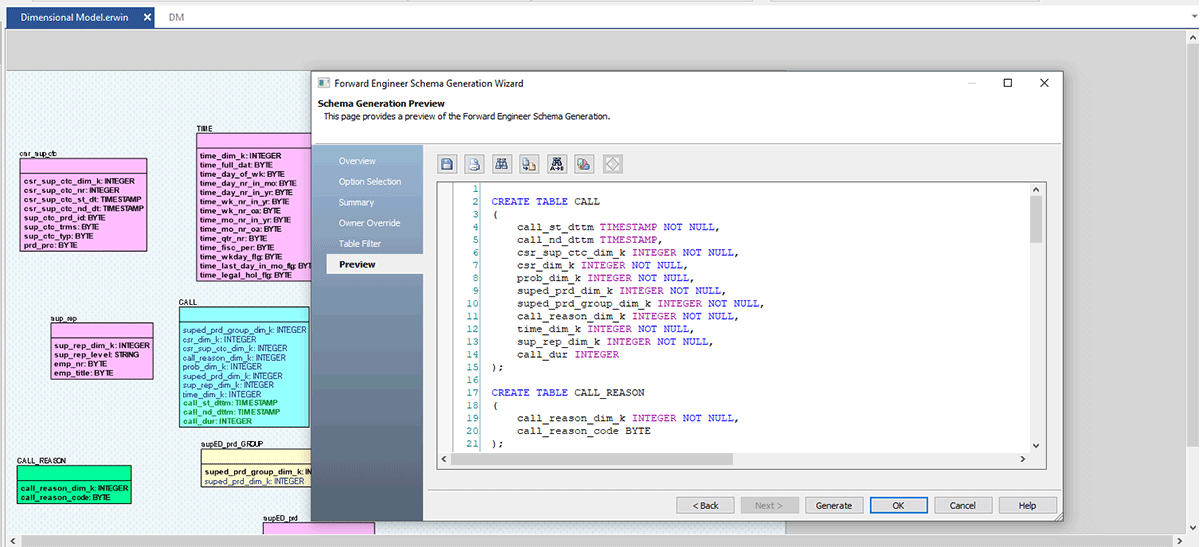
erwin Data Modeler Mart supporta anche GitHub. Questo supporto abilita il requisito del tuo team DevOps di controllare i tuoi script nei repository di controllo sorgente aziendali di tua scelta. Ora, con il supporto Git, puoi collaborare facilmente con gli sviluppatori e seguire i flussi di lavoro di controllo delle versioni.
Conclusione
In questo blog, abbiamo dimostrato quanto sia facile creare, eseguire l'ingegneria inversa o l'ingegneria in avanti di modelli di dati utilizzando erwin Data Modeler e creare modelli di dati visivi per la migrazione delle definizioni delle tabelle a Databricks ed eseguire l'ingegneria inversa di modelli di dati per la Data Governance e la creazione di livelli semantici.
Questo tipo di pratica di modellazione dei dati è l'elemento chiave per aggiungere valore alla tua:
- Pratica di Data Governance
- Riduzione dei costi e raggiungimento di un time-to-value più rapido per i tuoi dati e metadati
- Comprensione e miglioramento dei risultati aziendali e dei relativi metadati
- Riduzione di complessità e rischi
- Miglioramento della collaborazione tra il team IT e gli stakeholder aziendali
- Migliore documentazione
- Infine, un percorso semplice per migrare da database legacy alla piattaforma Databricks
Inizia a usare erwin da Databricks Partner Connect.
Prova Databricks gratuitamente per 14 giorni.
Prova erwin Data modeler
** erwin DM 12.5 è in arrivo con il supporto di Unity Catalog di Databricks, dove potrai visualizzare le tue chiavi primarie e straniere.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.