Accelerare l'inferenza LLM con la cache dei prompt per modelli open-source su Databricks
Inferenza LLM OSS più veloce e sicura con la cache dei prompt.
di Pei-Lun Liao, Asfandyar Qureshi, Roshan Regula, Bruce Fontaine, James Thomas e Chenyang Yu
- La cache dei prompt riutilizza i prefissi di prompt ripetuti in modo che gli LLM vengano eseguiti più velocemente. Riduce la latenza e aumenta il throughput automaticamente.
- Databricks ora supporta la cache dei prompt per modelli open-source in carichi di lavoro batch, pay-per-token e provisioned. Non è necessaria alcuna configurazione.
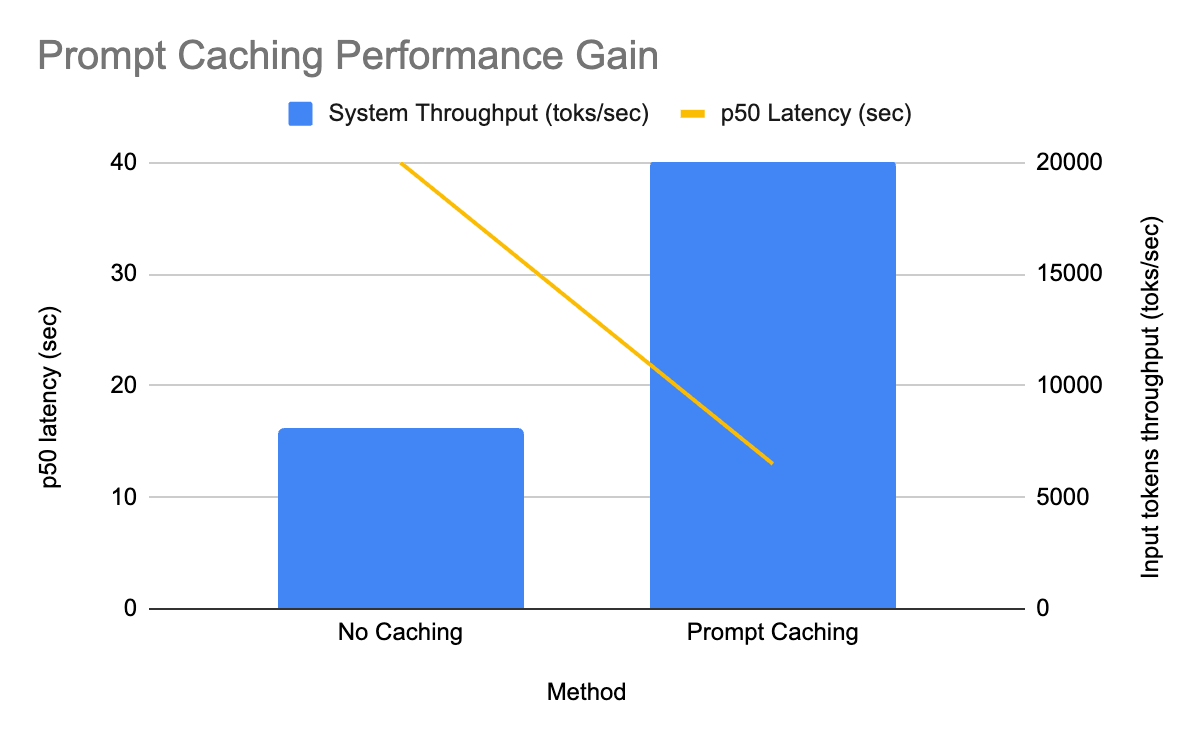
- In produzione su GPT-OSS, la cache dei prompt ha aumentato il throughput di 2,5 volte e ridotto la latenza P50 di 3 volte.
Perché la cache dei prompt è importante
L'inferenza dei modelli linguistici di grandi dimensioni (LLM) spesso comporta prompt ripetuti: pensa allo stesso prompt di sistema o di istruzione che appare in migliaia di richieste. Riprocessare quel prefisso identico per ogni chiamata spreca cicli di calcolo, aumenta la latenza e incrementa i costi.
La cache dei prompt elimina questa ridondanza, fornendo:
- Latenza inferiore: la fase di prefill può essere saltata quando la cache viene trovata.
- Throughput maggiore: vengono elaborati più token per unità modello.
La cache dei prompt può essere una tecnica potente per migliorare la qualità di un modello in domini specifici senza compromettere il throughput dei token del modello. Le query possono condividere un ampio prompt di sistema specifico del dominio, con il costo di calcolo di quel prompt condiviso ammortizzato su tutte quelle query. Modelli all'avanguardia, come Claude, utilizzano prompt di sistema che sono lunghi migliaia di token sotto il cofano. Inoltre, nella nostra ricerca pubblicata di recente abbiamo dimostrato che l'ottimizzazione automatica dei prompt consente ai modelli open-source di superare la qualità dei modelli all'avanguardia per le attività aziendali.
Disponibilità delle funzionalità
Databricks fornisce già la cache dei prompt integrata per i modelli proprietari (GPT, Gemini, Claude). Abbiamo ora esteso questa funzionalità ai modelli open-weights che alimentano le nostre API di modelli fondazionali (FMAPIs) per inferenza batch, pay-per-token e carichi di lavoro con throughput provisionato. Si applica anche a tutti i servizi di livello superiore alimentati da un modello fondazionale, ad esempio Agent Bricks, Genie, AI Functions.
La cache dei prompt è ora supportata per i seguenti modelli OSS ospitati su Databricks:
- GPT‑OSS 20B e 120B
- Gemma 3 12B
- Llama 3.1 8B fine-tuned (tramite PEFT serving)
- Llama 3.1 8B e 3.3 70B
Continueremo a implementare questa funzionalità per i nostri altri modelli. La sicurezza è una preoccupazione di prima classe in Databricks. Le cache dei prompt sono isolate, risiedono solo nella memoria volatile e non vengono mai persistite. È importante notare che la cache è implicita: i clienti non devono configurare nulla, il nostro sistema è stato creato per eseguire automaticamente la cache dei prompt e il riutilizzo per migliorare il throughput.
Impatto nel mondo reale: inferenza batch su GPT OSS
Abbiamo implementato la cache dei prompt per i nostri modelli GPT‑OSS per primi e abbiamo immediatamente riscontrato miglioramenti misurabili in una delle pipeline di inferenza batch di produzione su larga scala:
- Il throughput dei token di input per replica è aumentato di 2,5 volte
- La latenza P50 è diminuita di 3 volte
- Tutto questo con un rapporto di cache hit relativamente basso del 30%
Conclusione
Riutilizzando automaticamente le cache KV per prompt identici, Databricks ti consente di eseguire LLM open-source in modo più rapido, conveniente e sicuro, il tutto senza richiedere alcuna configurazione aggiuntiva. Sia che tu stia servendo chat in tempo reale, elaborando in batch grandi raccolte di documenti o creando agenti AI, la cache dei prompt può trasformare una buona pipeline di inferenza in un'ottima. Provala con il tuo prossimo deployment di modelli OSS e osserva le metriche di performance salire.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.