Creazione di Agenti Aziendali all'Avanguardia 90 volte più Economici con Ottimizzazione Automatica dei Prompt
Databricks Agent Bricks è una piattaforma per la creazione, la valutazione e il deployment di agenti AI di livello enterprise per i flussi di lavoro aziendali. Il nostro obiettivo è aiutare i clienti a raggiungere il miglior equilibrio qualità-costo sulla frontiera di Pareto per le loro attività specifiche del dominio e a migliorare continuamente i loro agenti che ragionano sui propri dati. Per supportare questo, sviluppiamo benchmark incentrati sull'enterprise ed eseguiamo valutazioni empiriche sugli agenti che misurano accuratezza ed efficienza di serving, riflettendo i reali compromessi che le aziende affrontano in produzione.
All'interno del nostro più ampio toolkit di ottimizzazione degli agenti, questo post si concentra sull'ottimizzazione automatica dei prompt, una tecnica che sfrutta la ricerca iterativa e strutturata guidata da segnali di feedback dalla valutazione per migliorare automaticamente i prompt. Dimostriamo come possiamo:
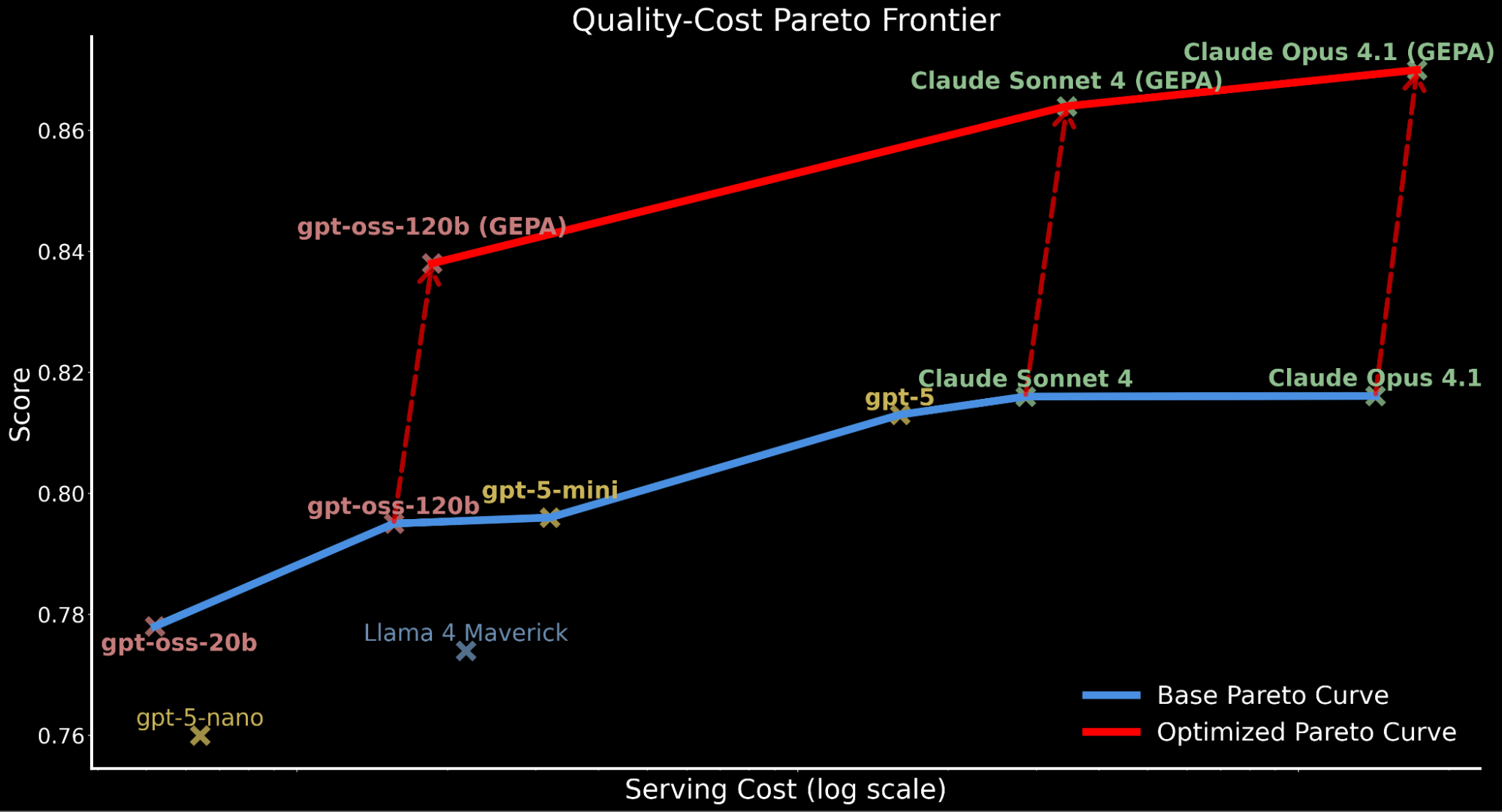
- Consentire ai modelli open-source di superare la qualità dei modelli frontier per le attività enterprise: sfruttando GEPA, una tecnica di ottimizzazione dei prompt recentemente rilasciata dalla ricerca di Databricks e UC Berkeley, presentiamo come gpt-oss-120b superi i modelli proprietari all'avanguardia Claude Sonnet 4 e Claude Opus 4.1 di circa il 3%, essendo rispettivamente circa 20 volte e 90 volte più economico da servire (vedi grafico della frontiera di Pareto di seguito).
- Migliorare ulteriormente i modelli frontier proprietari: applichiamo lo stesso approccio ai principali modelli proprietari, aumentando le prestazioni di base di Claude Opus 4.1 e Claude Sonnet 4 del 6-7% e raggiungendo nuove prestazioni all'avanguardia.
- Offrire un compromesso qualità-costo superiore rispetto a SFT: l'ottimizzazione automatica dei prompt offre prestazioni pari o superiori al supervised fine-tuning (SFT), riducendo i costi di serving del 20%. Mostriamo anche che l'ottimizzazione dei prompt e SFT possono lavorare insieme per migliorare ulteriormente le prestazioni.
Nelle sezioni seguenti, tratteremo
- come valutiamo le prestazioni degli agenti AI nell'information extraction come caso d'uso principale e perché è importante per i flussi di lavoro enterprise;
- una panoramica di come funziona l'ottimizzazione dei prompt, i tipi di benefici che può sbloccare, specialmente in scenari in cui il finetuning non è pratico, e i guadagni di prestazioni sulla nostra pipeline di valutazione;
- per contestualizzare questi guadagni, misureremo l'impatto dell'ottimizzazione dei prompt e analizzeremo l'economia alla base di queste tecniche;
- il confronto delle prestazioni con il supervised finetuning (SFT), evidenziando il compromesso qualità-costo superiore dell'ottimizzazione dei prompt;
- conclusioni e prossimi passi, in particolare come iniziare ad applicare queste tecniche direttamente con Databricks Agent Bricks per creare agenti AI di prima classe ottimizzati per il deployment enterprise nel mondo reale.
Valutazione degli ultimi LLM su IE Bench
Information Extraction (IE) è una funzionalità principale di Agent Bricks, che converte fonti non strutturate come PDF o documenti scansionati in record strutturati. Nonostante i rapidi progressi nelle capacità di intelligenza artificiale generativa, l'IE rimane difficile su scala enterprise:
- I documenti sono lunghi e pieni di gergo specifico del dominio
- Gli schemi sono complessi, gerarchici e contengono ambiguità
- Le etichette sono spesso rumorose e incoerenti
- La tolleranza operativa all'errore nell'estrazione è bassa
- Requisito di alta affidabilità ed efficienza dei costi per carichi di lavoro di inferenza su larga scala
Di conseguenza, osserviamo che le prestazioni possono variare ampiamente per dominio e complessità del compito, quindi la costruzione di sistemi AI composti adeguati per l'IE in diversi casi d'uso richiede una valutazione approfondita delle varie capacità degli agenti AI.
Per esplorare questo, abbiamo sviluppato IE Bench, una suite di valutazione completa che copre molteplici domini enterprise del mondo reale come finanza, legale, commercio e sanità. Il benchmark riflette complesse sfide del mondo reale, inclusi documenti che superano le 100 pagine, che coprono entità di estrazione con oltre 70 campi e schemi gerarchici con più livelli annidati. Riportiamo le valutazioni sul set di test tenuto nascosto del benchmark per fornire una misura affidabile delle prestazioni nel mondo reale.
Abbiamo confrontato l'ultima generazione di modelli open-source serviti tramite l'API Databricks Foundation Models, inclusa la serie gpt-oss appena rilasciata, nonché i principali modelli proprietari di più fornitori, inclusa l'ultima famiglia GPT-5.1
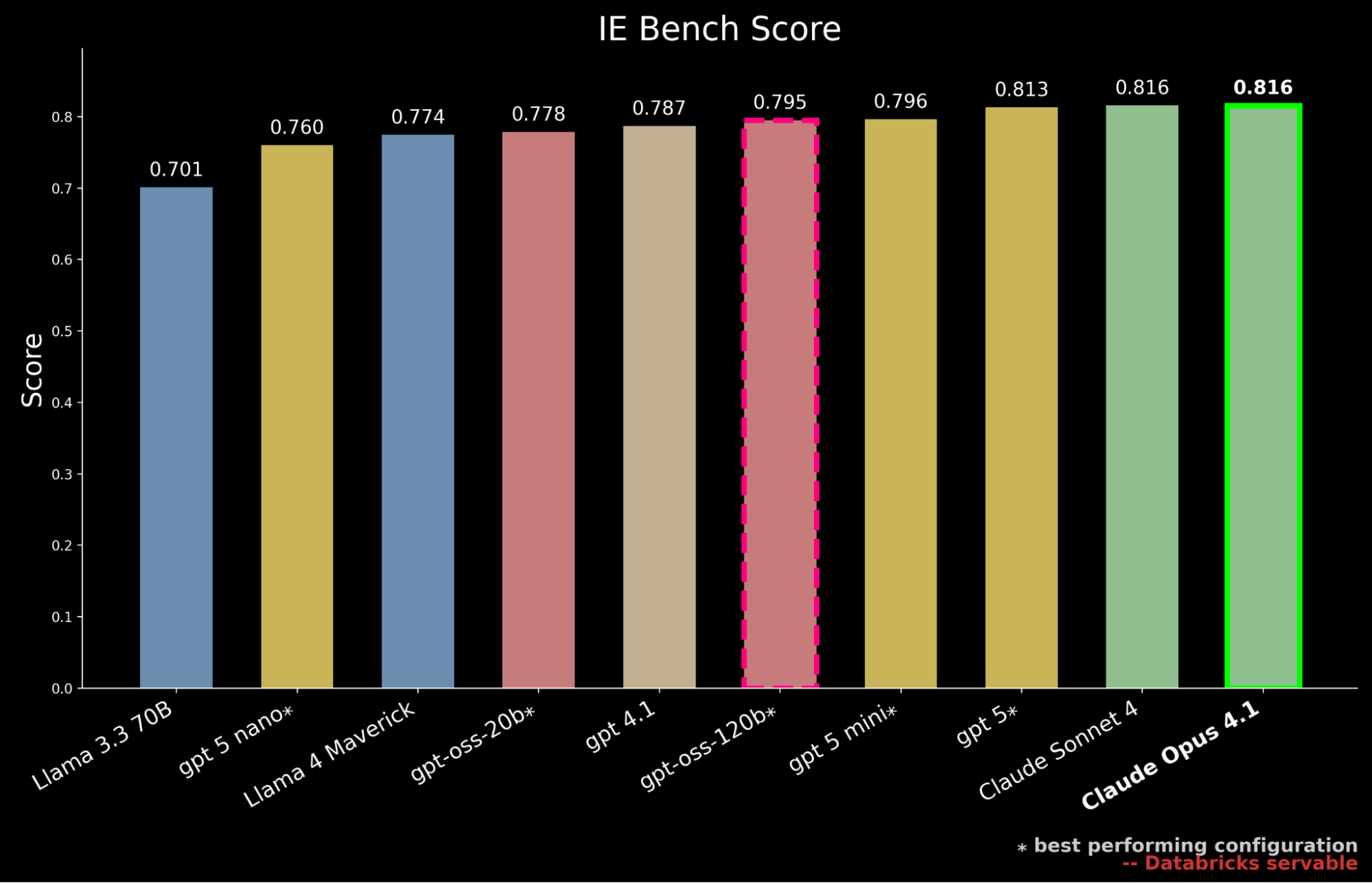
I nostri risultati mostrano che gpt-oss-120b è il modello open-source con le migliori prestazioni su IE Bench, superando le precedenti prestazioni all'avanguardia open-source di Llama 4 Maverick di circa il 3% pur avvicinandosi al livello di prestazioni di gpt-5-mini, segnando un passo avanti significativo per i modelli open-source. Tuttavia, rimane ancora indietro rispetto alle prestazioni dei modelli frontier proprietari, inseguendo gpt-5, Claude Sonnet 4 e Claude Opus 4.1, che raggiunge il punteggio più alto nel benchmark.
Tuttavia, negli ambienti enterprise, le prestazioni devono essere valutate anche rispetto al costo di serving. Contestualizziamo ulteriormente i nostri risultati precedenti evidenziando che gpt-oss-120b eguaglia le prestazioni di gpt-5-mini pur sostenendo solo circa il 50% del costo di serving. 2 I modelli frontier proprietari sono in gran parte più costosi con gpt-5 a circa 10 volte il costo di serving di gpt-oss-120b, Claude Sonnet 4 a circa 20 volte e Claude Opus 4.1 a circa 90 volte.
Per illustrare il compromesso qualità-costo tra i modelli, tracciamo la frontiera di Pareto di seguito, raffigurando le prestazioni di base per tutti i modelli prima di qualsiasi miglioramento.
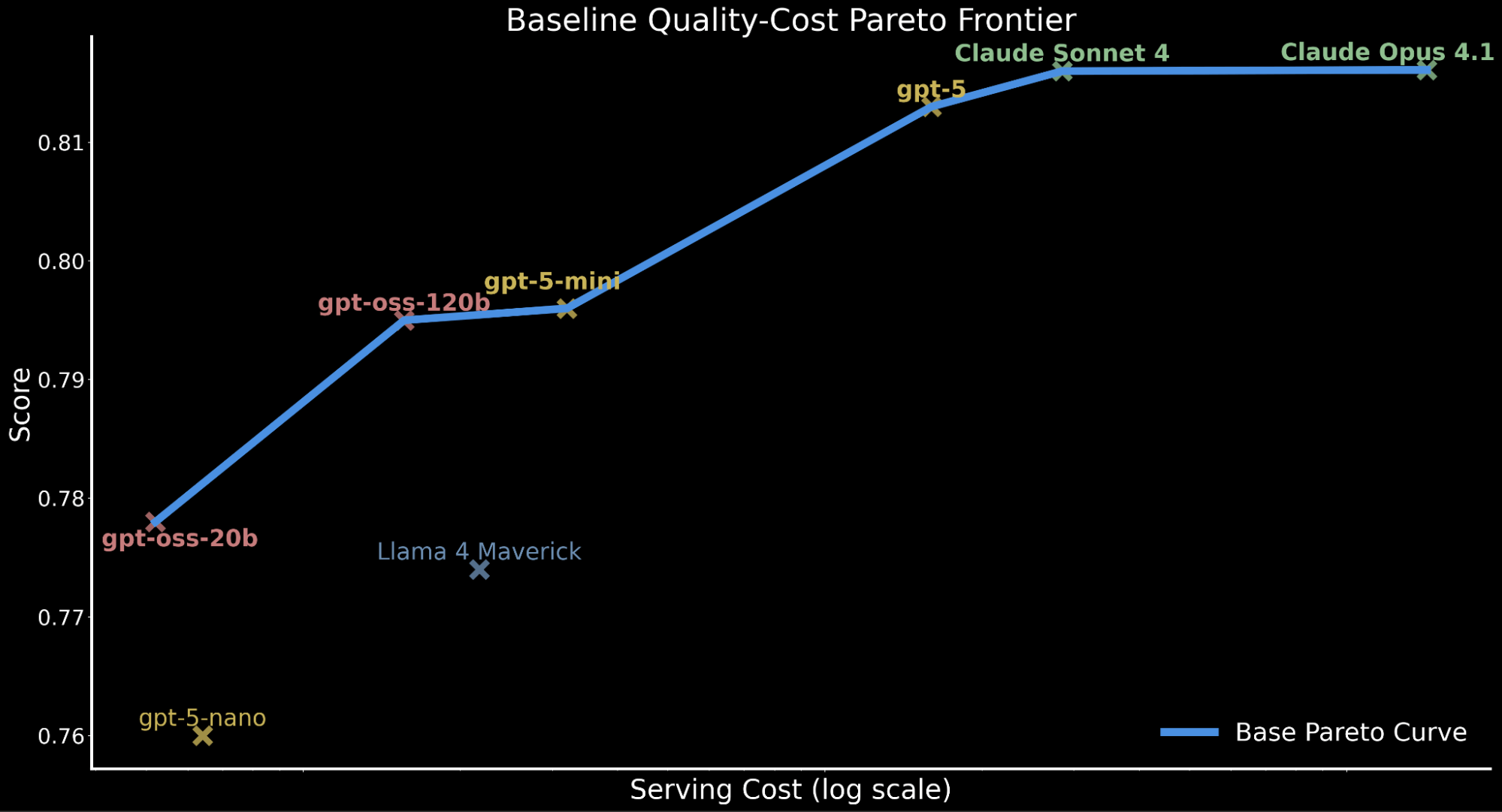
Questo compromesso qualità-costo ha implicazioni significative per i carichi di lavoro enterprise che richiedono inferenza su larga scala e che devono considerare il budget di calcolo e il throughput di serving mantenendo un'accuratezza performante.
Questo motiva la nostra esplorazione: possiamo spingere gpt-oss-120b a una qualità di livello frontier preservando la sua efficienza in termini di costi? Se così fosse, ciò fornirebbe prestazioni leader sulla frontiera costo-qualità e sarebbe servibile per l'adozione enterprise su Databricks.
Ottimizzazione dei modelli open-source per superare le prestazioni dei modelli frontier
Esploriamo l'ottimizzazione automatica dei prompt come metodo sistematico per aumentare le prestazioni del modello. L'ingegneria manuale dei prompt può fornire guadagni, ma tipicamente dipende dall'esperienza del dominio e dalla sperimentazione per tentativi ed errori. Questa complessità aumenta ulteriormente nei sistemi AI composti che integrano più chiamate LLM e strumenti esterni che devono essere ottimizzati insieme, rendendo l'ottimizzazione manuale dei prompt impraticabile da scalare o mantenere nelle pipeline di produzione.
L'ottimizzazione dei prompt offre un approccio diverso, sfruttando la ricerca strutturata guidata da segnali di feedback per migliorare automaticamente i prompt. Tali ottimizzatori sono indipendenti dalla pipeline e sono in grado di ottimizzare congiuntamente più prompt interdipendenti in pipeline multi-stadio, rendendo queste tecniche robuste e adattabili nei sistemi AI composti e in diverse attività.
Per testare questo, applichiamo algoritmi di ottimizzazione automatica dei prompt, in particolare MIPROv2, SIMBA e GEPA, un nuovo ottimizzatore di prompt proveniente dalla ricerca di Databricks e UC Berkeley che combina il riflesso basato sul linguaggio con la ricerca evolutiva per migliorare i sistemi AI. Applichiamo questi algoritmi per valutare come il prompting ottimizzato possa colmare il divario tra il modello open-source con le migliori prestazioni, gpt-oss-120b, e i modelli frontier closed-source all'avanguardia.
Consideriamo le seguenti configurazioni di ottimizzatori automatici di prompt nella nostra esplorazione
Ogni tecnica di ottimizzazione del prompt si basa su un modello ottimizzatore per perfezionare diversi aspetti del prompt per un modello studente di destinazione. A seconda dell'algoritmo, il modello ottimizzatore può generare esempi few-shot da tracce avviate per applicare l'apprendimento in-context e/o proporre e migliorare le istruzioni del task attraverso algoritmi di ricerca che eseguono riflessioni iterative utilizzando feedback per mutare e selezionare prompt migliori attraverso prove di ottimizzazione. Queste informazioni vengono distillate in prompt migliorati che il modello studente utilizzerà al momento dell'inferenza durante il serving. Sebbene lo stesso LLM possa essere utilizzato per entrambi i ruoli, sperimentiamo anche l'uso di un modello con prestazioni "più elevate" come modello ottimizzatore per esplorare se una guida di qualità superiore possa migliorare ulteriormente le prestazioni del modello studente.
Basandoci sui nostri precedenti risultati che identificano gpt-oss-120b come il modello open-source leader su IE Bench, lo consideriamo il nostro modello studente di base per esplorare ulteriori miglioramenti.
Quando ottimizziamo gpt-oss-120b, consideriamo due configurazioni:
- gpt-oss-120b (ottimizzatore) → gpt-oss-120b (studente)
- Claude Sonnet 4 (ottimizzatore) → gpt-oss-120b (studente)
Poiché Claude Sonnet 4 raggiunge prestazioni leader su IE Bench rispetto a gpt-oss-120b, ed è relativamente più economico rispetto a Claude Opus 4.1 con prestazioni simili, esploriamo l'ipotesi se l'applicazione di un modello ottimizzatore più potente possa produrre prestazioni migliori per gpt-oss-120b.
Valutiamo ogni configurazione attraverso le tecniche di ottimizzazione e confrontiamo con il rispettivo baseline gpt-oss-120b:
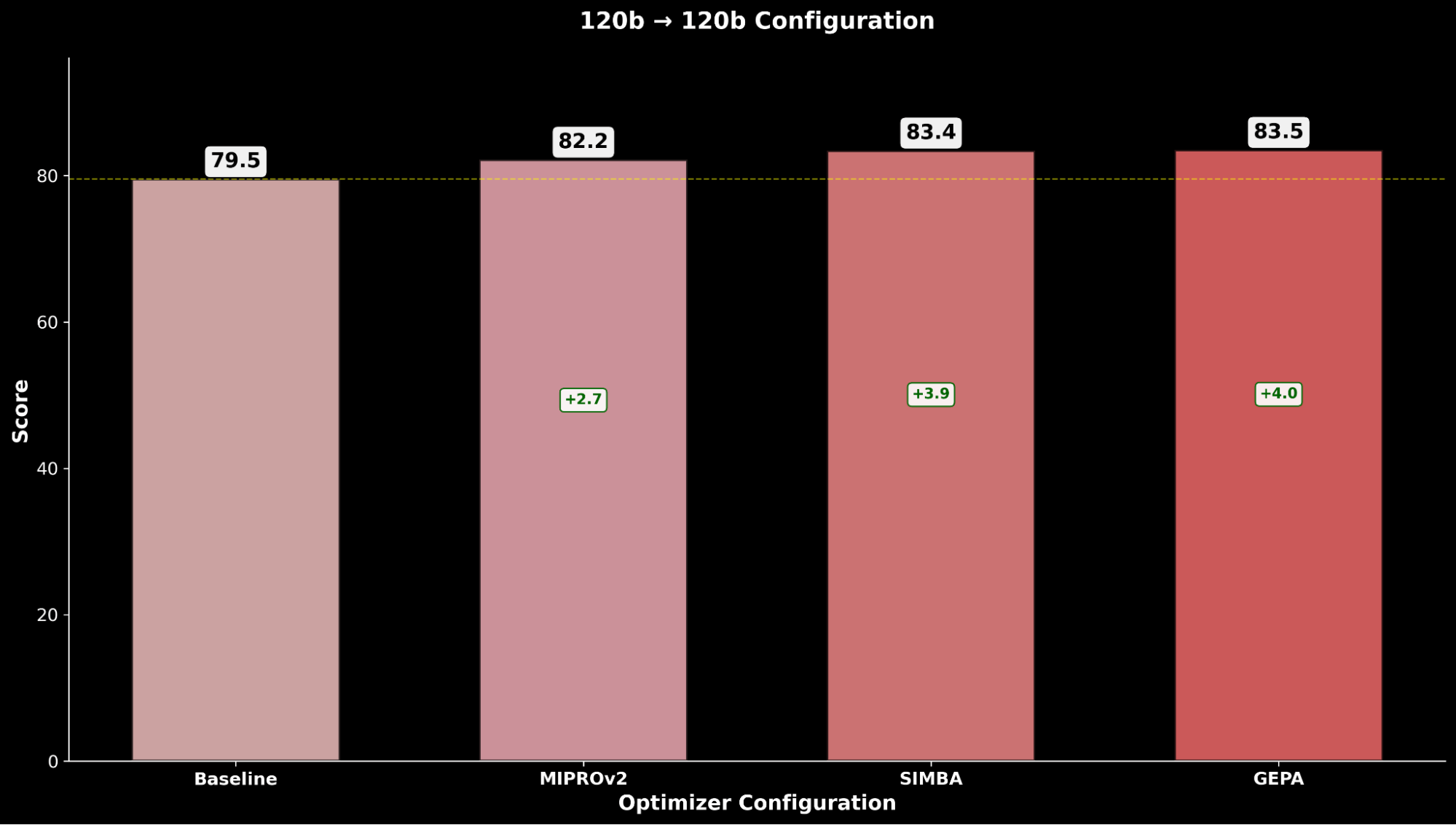
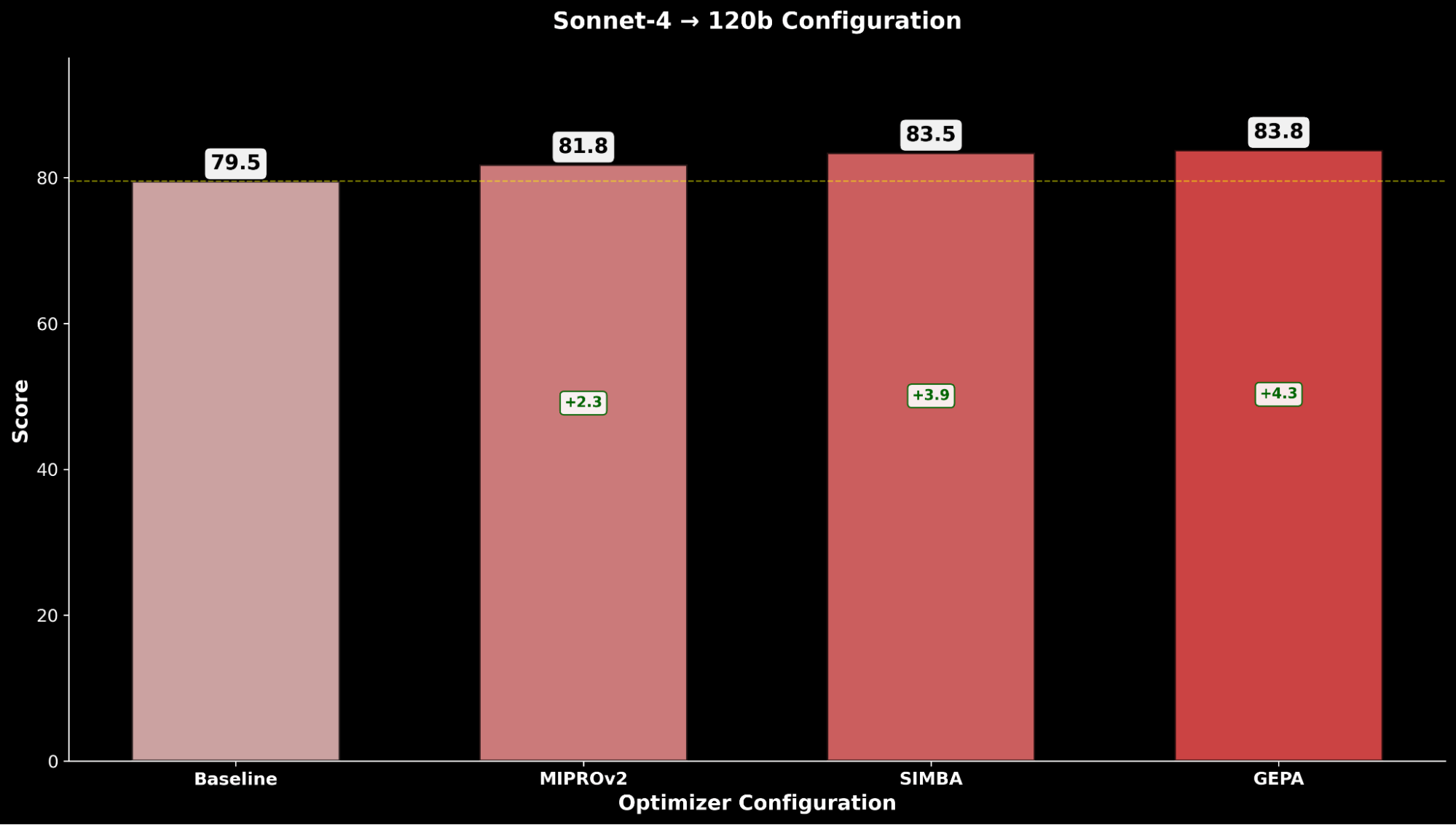
Attraverso IE Bench, scopriamo che l'ottimizzazione di gpt-oss-120b con Claude Sonnet 4 come modello ottimizzatore ottiene il maggior miglioramento rispetto alle prestazioni di base di gpt-oss-120b, con un significativo miglioramento di +4,3 punti rispetto al baseline e un miglioramento di +0,3 punti rispetto all'ottimizzazione di gpt-oss-120b con se stesso come modello ottimizzatore, evidenziando il vantaggio derivante dall'uso di un modello ottimizzatore più potente.
Confrontiamo la configurazione gpt-oss-120b ottimizzata GEPA con le migliori prestazioni contro i modelli Claude di frontiera:
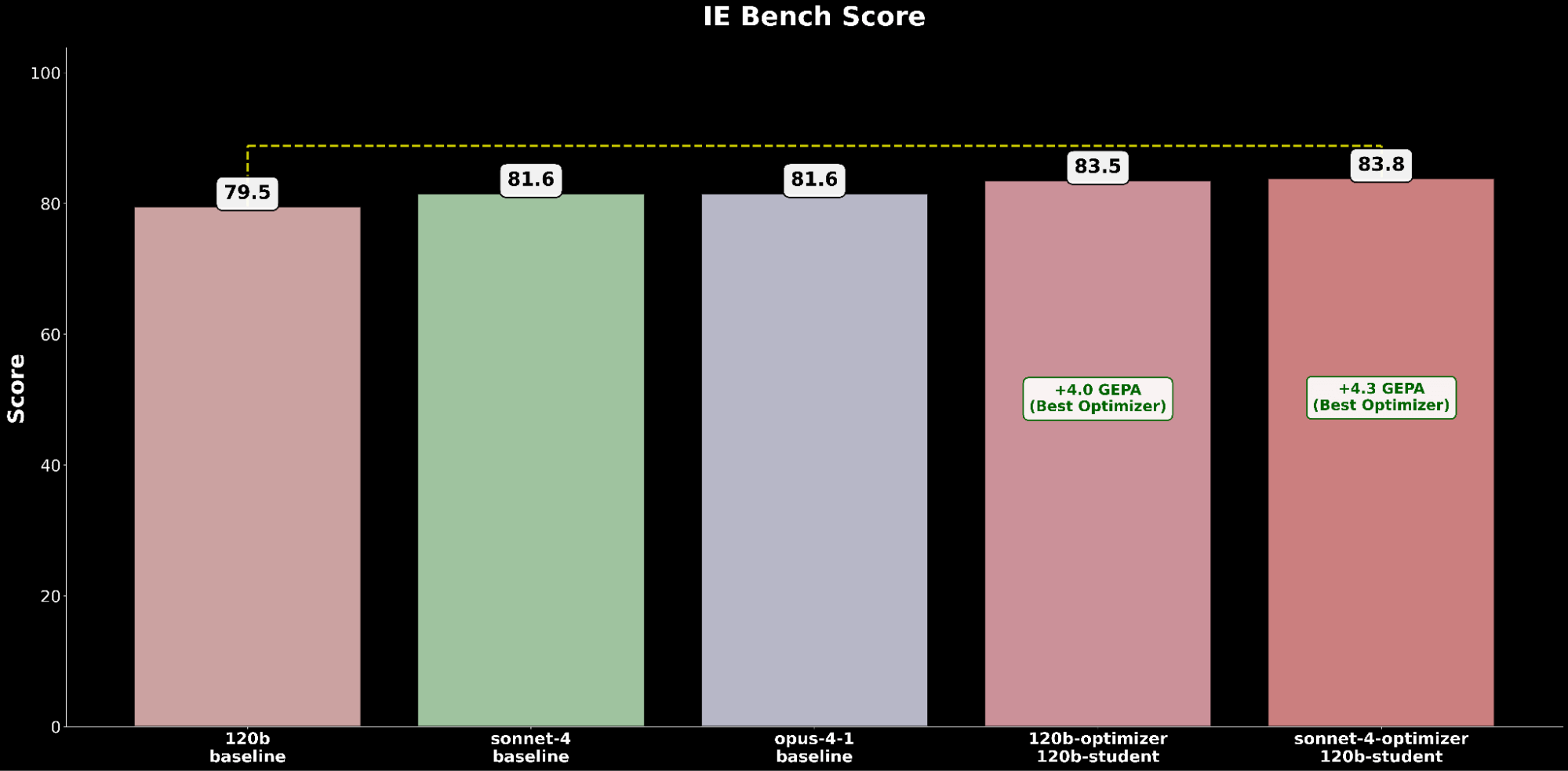
La configurazione ottimizzata gpt-oss-120b supera le prestazioni di base dello stato dell'arte di Claude Opus 4.1 con un guadagno assoluto di +2,2, evidenziando i benefici dell'ottimizzazione automatica dei prompt nell'elevare un modello open-source a superare i modelli proprietari leader nelle capacità IE.
Ottimizzare i modelli di frontiera per aumentare ulteriormente il soffitto delle prestazioni
Visto il significato dell'ottimizzazione automatica dei prompt, esploriamo se l'applicazione dello stesso principio ai modelli di frontiera leader Claude Sonnet 4 e Claude Opus 4.1 possa spingere ulteriormente il soffitto delle prestazioni raggiungibili per IE Bench.
Quando ottimizziamo ciascun modello proprietario, consideriamo le seguenti configurazioni:
- Claude Sonnet 4 (ottimizzatore) → Claude Sonnet 4 (studente)
- Claude Opus 4.1 (ottimizzatore) → Claude Opus 4.1 (studente)
Consideriamo le configurazioni predefinite dei modelli ottimizzatori poiché questi modelli definiscono già il limite di performance.
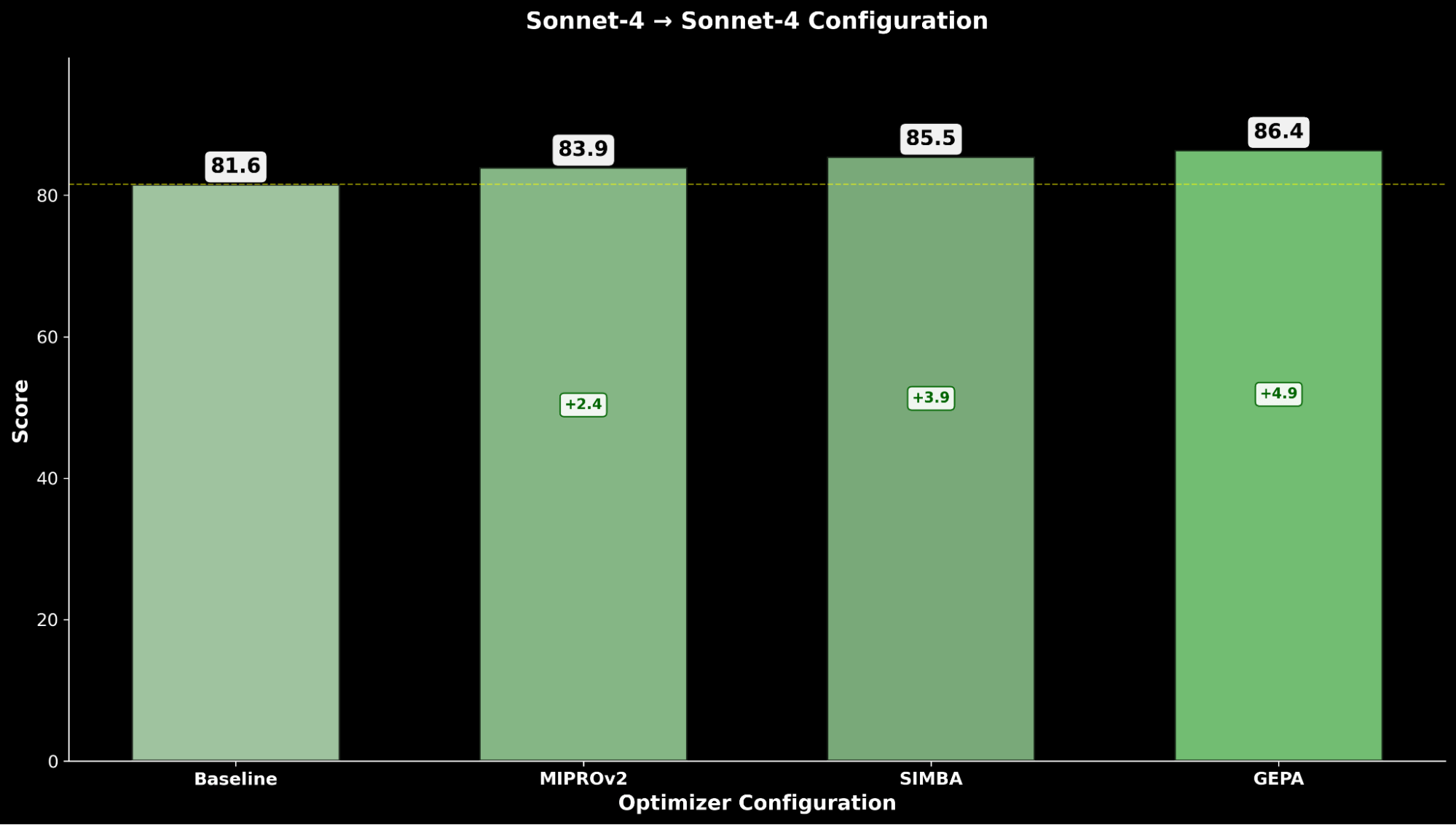
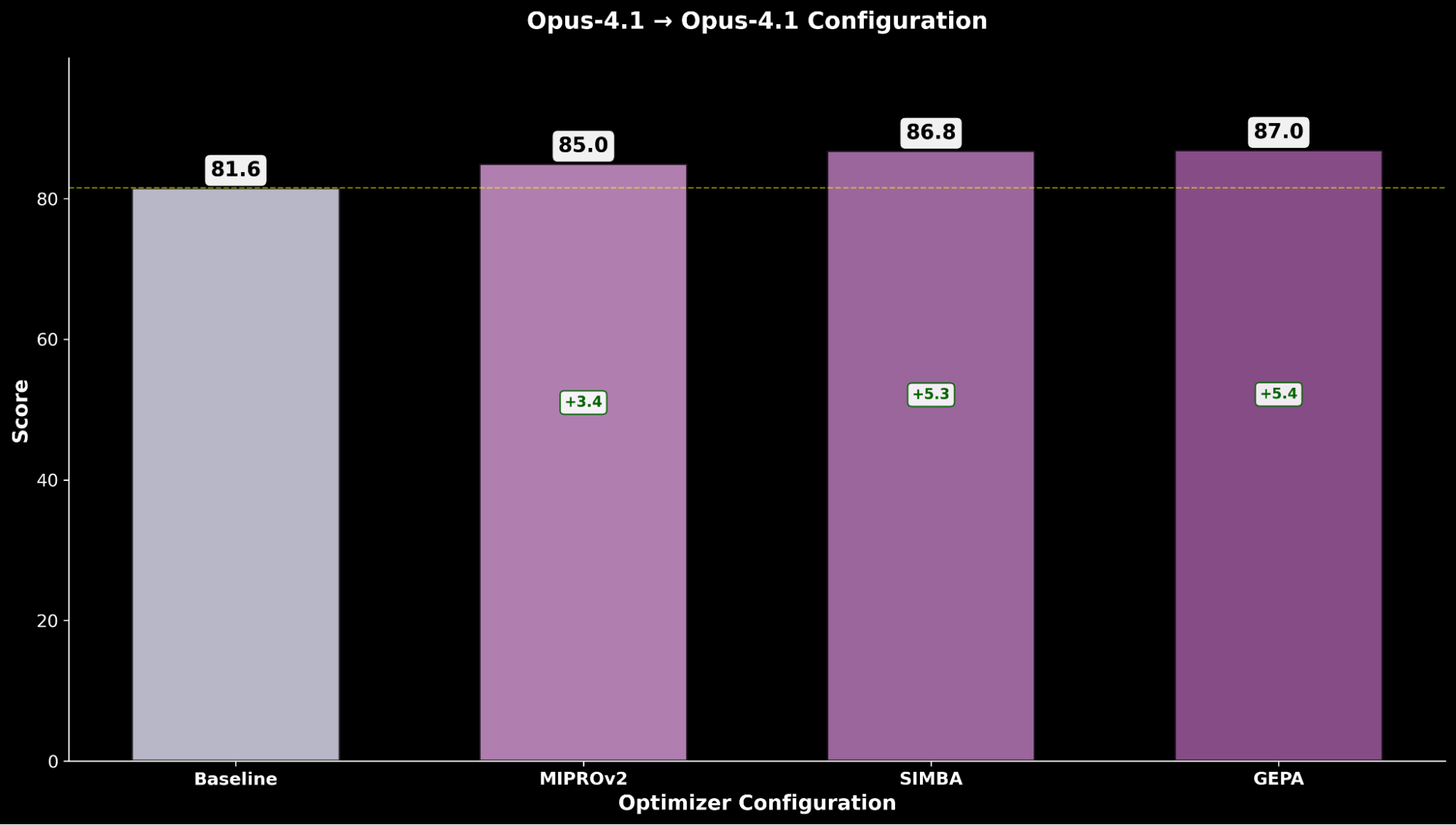
L'ottimizzazione di Claude Sonnet 4 ottiene un miglioramento del +4.8 rispetto alle performance di base, mentre Claude Opus 4.1 ottimizzato ottiene le migliori performance complessive, con un significativo miglioramento di +6.4 punti rispetto alle precedenti performance allo stato dell'arte.
Aggregando i risultati degli esperimenti, osserviamo un trend costante di ottimizzazione automatica dei prompt che fornisce sostanziali guadagni di performance su tutte le performance di base dei modelli.
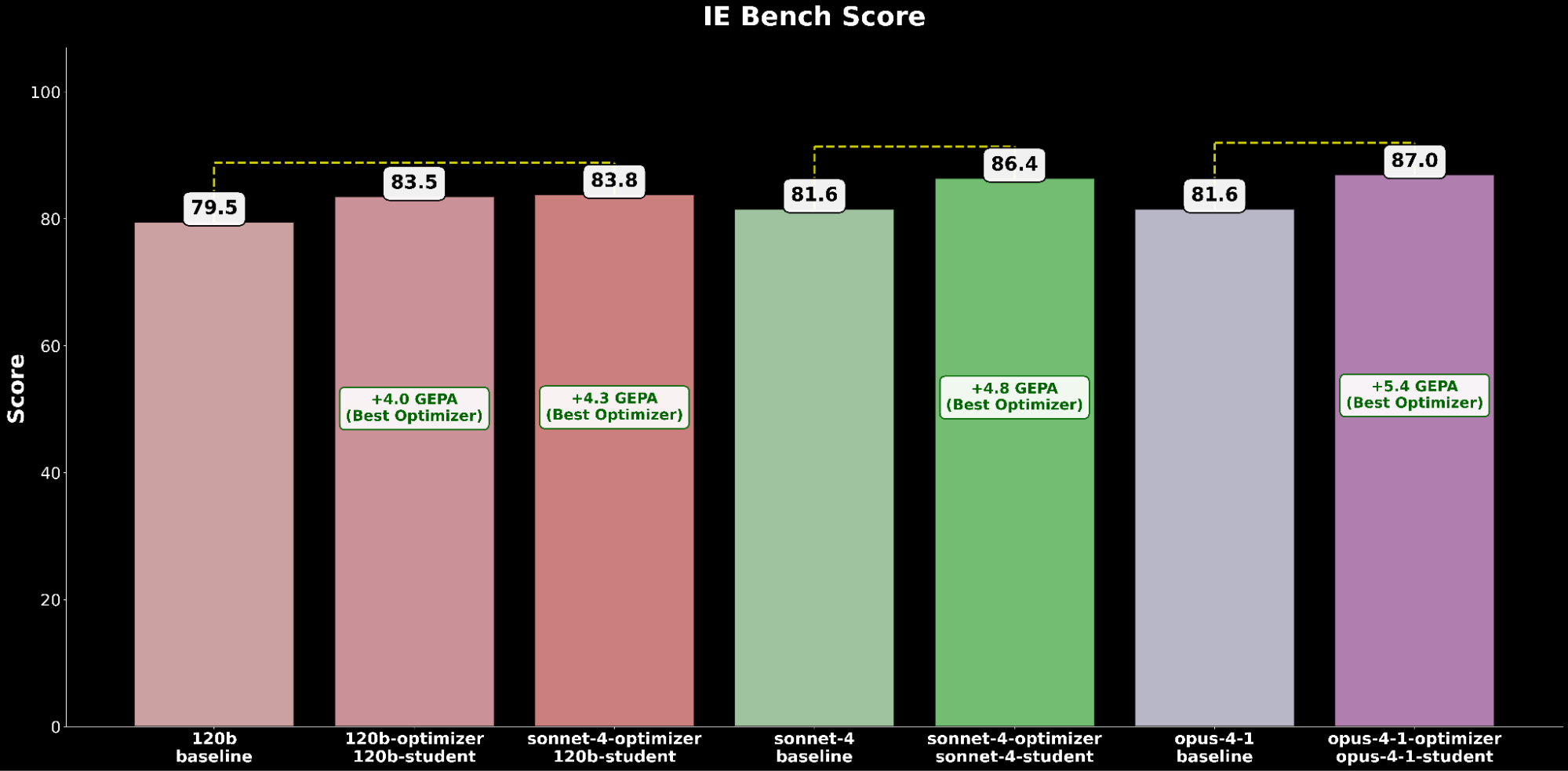
Sia nelle valutazioni di modelli open-source che closed-source, troviamo costantemente che GEPA è l'ottimizzatore con le migliori performance, seguito da SIMBA e poi MIPRO, sbloccando significativi miglioramenti di qualità utilizzando l'ottimizzazione automatica dei prompt.
Tuttavia, considerando il costo, osserviamo che GEPA ha un overhead di runtime relativamente più alto (poiché l'esplorazione dell'ottimizzazione può richiedere circa O(3x) chiamate LLM in più (~2-3 ore) rispetto a MIPRO e SIMBA (~1 ora))3 durante questa analisi empirica di IE Bench. Pertanto, consideriamo l'efficienza dei costi e aggiorniamo il nostro frontiera di Pareto qualità-costo includendo le performance dei modelli ottimizzati.
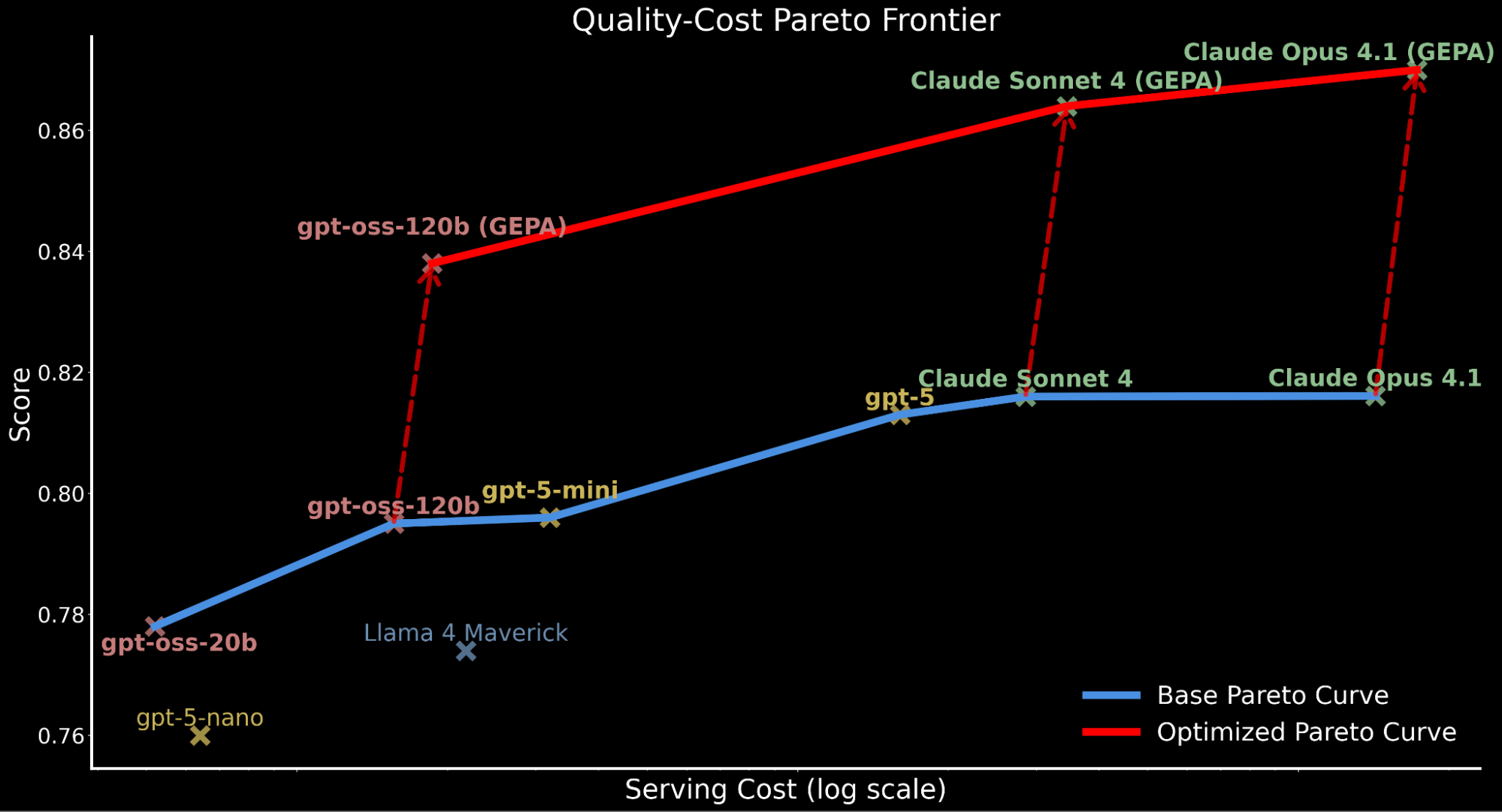
Evidenziamo come l'applicazione dell'ottimizzazione automatica dei prompt sposti l'intera curva di Pareto verso l'alto, stabilendo un nuovo stato dell'arte in termini di efficienza:
- gpt-oss-120b ottimizzato con GEPA supera le performance di base di Claude Sonnet 4 e Claude Opus 4.1 pur essendo 22x e 90x più economico.
- Per i clienti che danno priorità alla qualità rispetto al costo, Claude Opus 4.1 ottimizzato con GEPA porta a nuove performance allo stato dell'arte, evidenziando potenti guadagni per i modelli frontier che non possono essere sottoposti a fine-tuning.
- Attribuiamo l'aumento totale del costo di serving per i modelli ottimizzati con GEPA ai prompt più lunghi e dettagliati rispetto al prompt di base prodotto tramite ottimizzazione.
Applicando ottimizzazioni automatiche dei prompt agli agenti, presentiamo una soluzione che soddisfa i principi fondamentali di Agent Bricks di alte performance ed efficienza dei costi.
Confronto con SFT
Il Supervised Fine-Tuning (SFT) è spesso considerato il metodo predefinito per migliorare le performance dei modelli, ma come si confronta con l'ottimizzazione automatica dei prompt?
Per rispondere a questa domanda, abbiamo condotto un esperimento su un sottoinsieme di IE Bench, scegliendo gpt 4.1 per valutare le performance di SFT e dell'ottimizzazione automatica dei prompt (escludiamo gpt-oss e gpt-5 da questi confronti poiché i modelli non erano stati rilasciati al momento della valutazione).
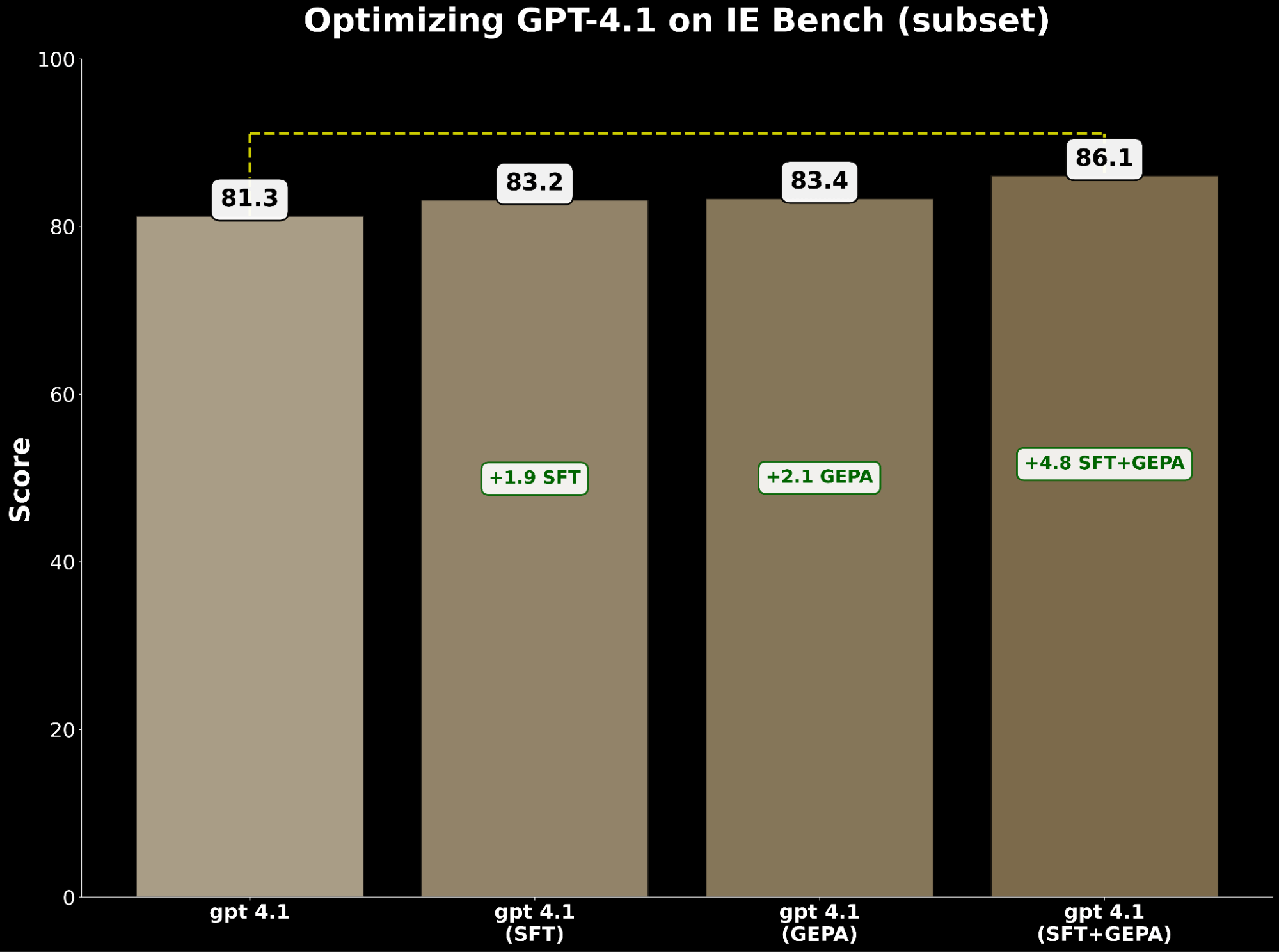
Sia SFT che l'ottimizzazione dei prompt migliorano indipendentemente gpt-4.1. Nello specifico:
- SFT gpt-4.1 ha guadagnato +1.9 punti rispetto alla base.
- GEPA-optimized gpt-4.1 ha guadagnato +2.1 punti, superando leggermente SFT.
Ciò dimostra che l'ottimizzazione dei prompt può eguagliare, e persino superare, i miglioramenti del fine-tuning supervisionato.
Ispirati da BetterTogether, una tecnica che considera l'alternanza tra ottimizzazione dei prompt e fine-tuning dei pesi del modello per migliorare le performance LLM, applichiamo GEPA sopra SFT e otteniamo un guadagno di +4.8 punti rispetto alla base, evidenziando il forte potenziale di combinare queste tecniche.
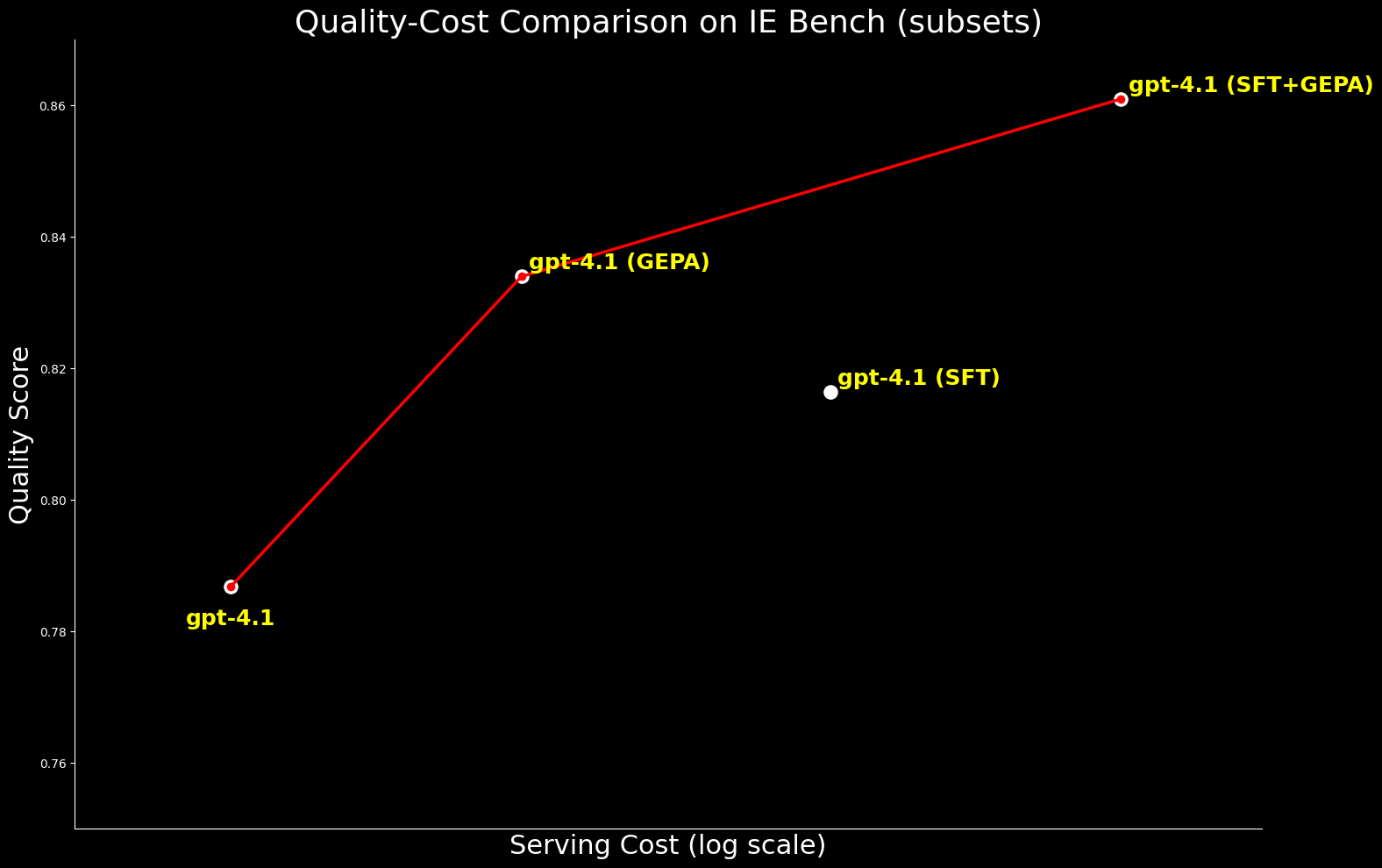
Dal punto di vista dei costi, gpt-4.1 ottimizzato con GEPA è circa il 20% più economico da servire rispetto a gpt-4.1 ottimizzato con SFT, pur offrendo una migliore qualità. Ciò evidenzia che GEPA offre un bilanciamento qualità-costo premium rispetto a SFT. Inoltre, possiamo massimizzare la qualità assoluta combinando GEPA con SFT, che offre un miglioramento del 2.7% rispetto al solo SFT, ma con un costo di serving superiore di circa il 22%.4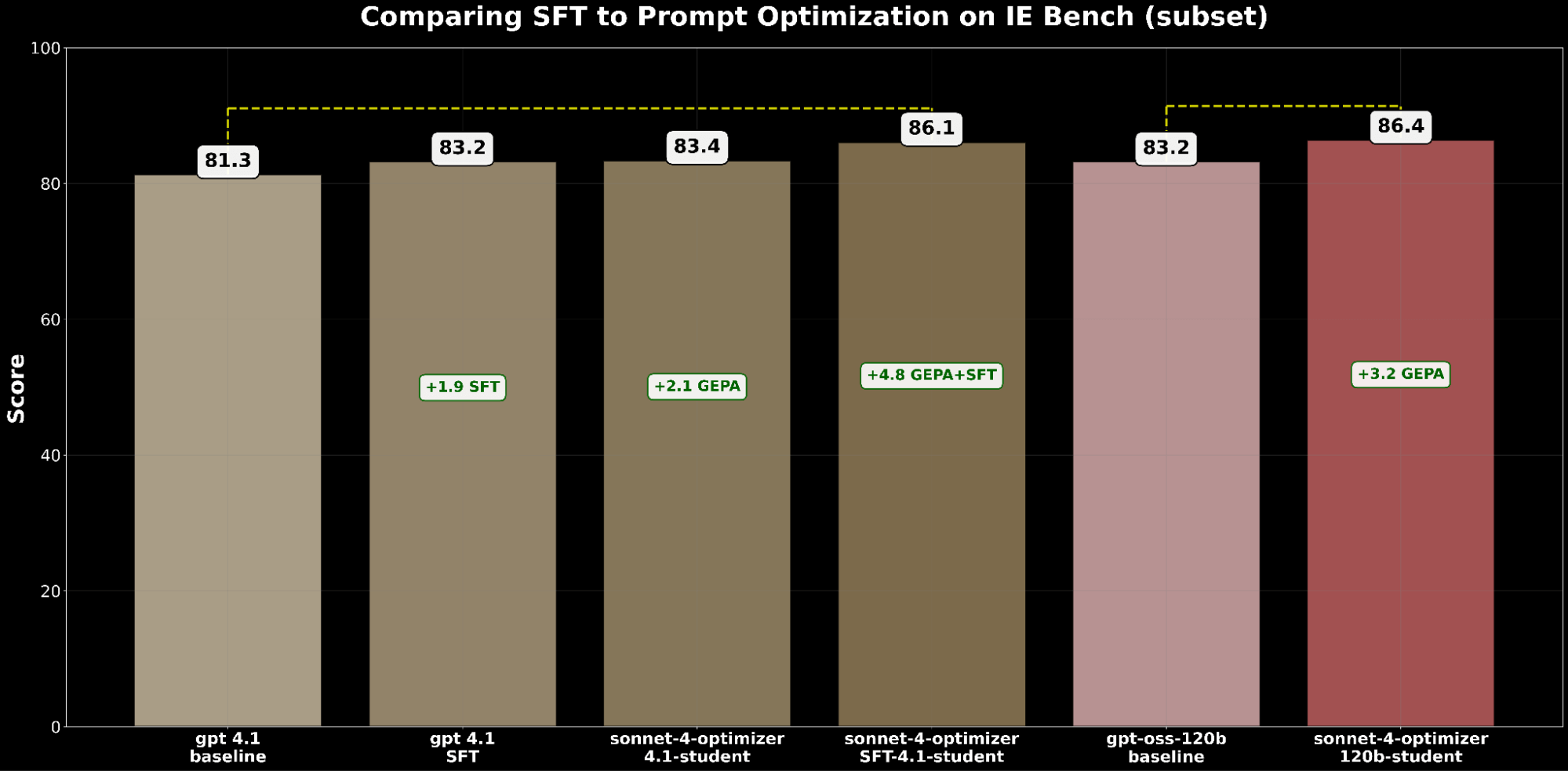
Abbiamo esteso il confronto a gpt-oss-120b per esaminare il frontiera qualità-costo. Mentre gpt-4.1 ottimizzato con SFT+GEPA si avvicina - entro lo 0.3% delle performance di gpt-oss-120b ottimizzato con GEPA - quest'ultimo offre la stessa qualità a un costo di serving 15 volte inferiore, rendendolo molto più pratico e attraente per il deployment su larga scala.

Insieme, questi confronti evidenziano i forti guadagni di performance resi possibili dall'ottimizzazione GEPA, sia utilizzata da sola che in combinazione con SFT. Evidenziano inoltre l'eccezionale efficienza qualità-costo di gpt-oss-120b quando ottimizzato con GEPA.
Costo Totale
Per valutare l'ottimizzazione in termini reali, consideriamo il costo totale per i clienti. L'obiettivo dell'ottimizzazione non è solo migliorare l'accuratezza, ma anche produrre un agente efficiente in grado di gestire le richieste in produzione. Questo rende essenziale considerare sia il costo di ottimizzazione che il costo di serving di grandi volumi di richieste.
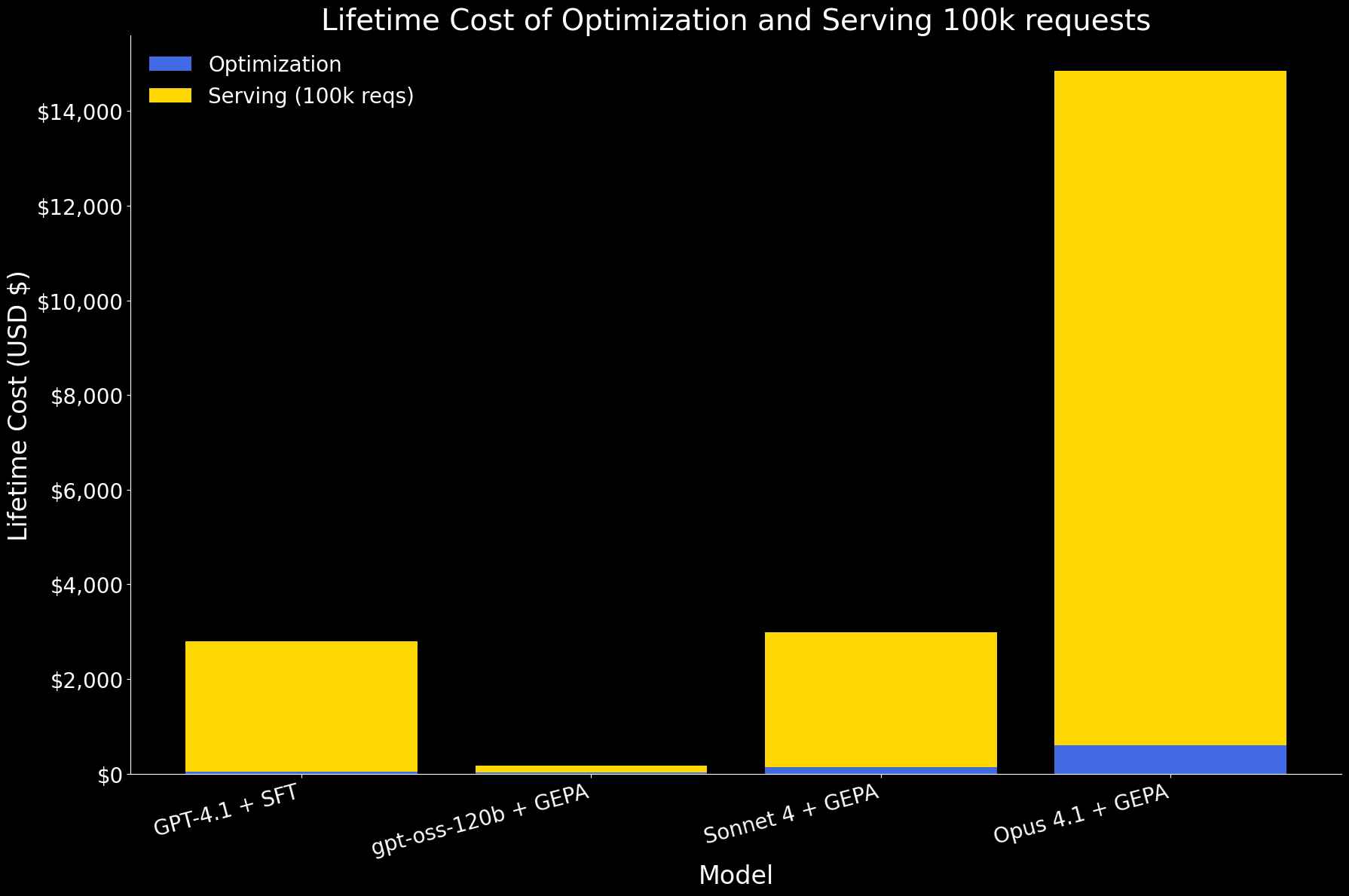
Nel primo grafico sottostante, mostriamo il costo totale per l'ottimizzazione di un agente e il serving di 100.000 richieste, suddiviso nelle componenti di ottimizzazione e serving. A questa scala, il serving domina il costo complessivo. Tra i modelli:
- gpt-oss-120b con GEPA è di gran lunga il più efficiente, con costi di un ordine di grandezza inferiori sia per l'ottimizzazione che per il serving.
- GPT 4.1 con SFT e Sonnet 4 con GEPA hanno un costo totale simile.
- Opus 4.1 con GEPA è il più costoso, principalmente a causa del suo elevato prezzo di serving.
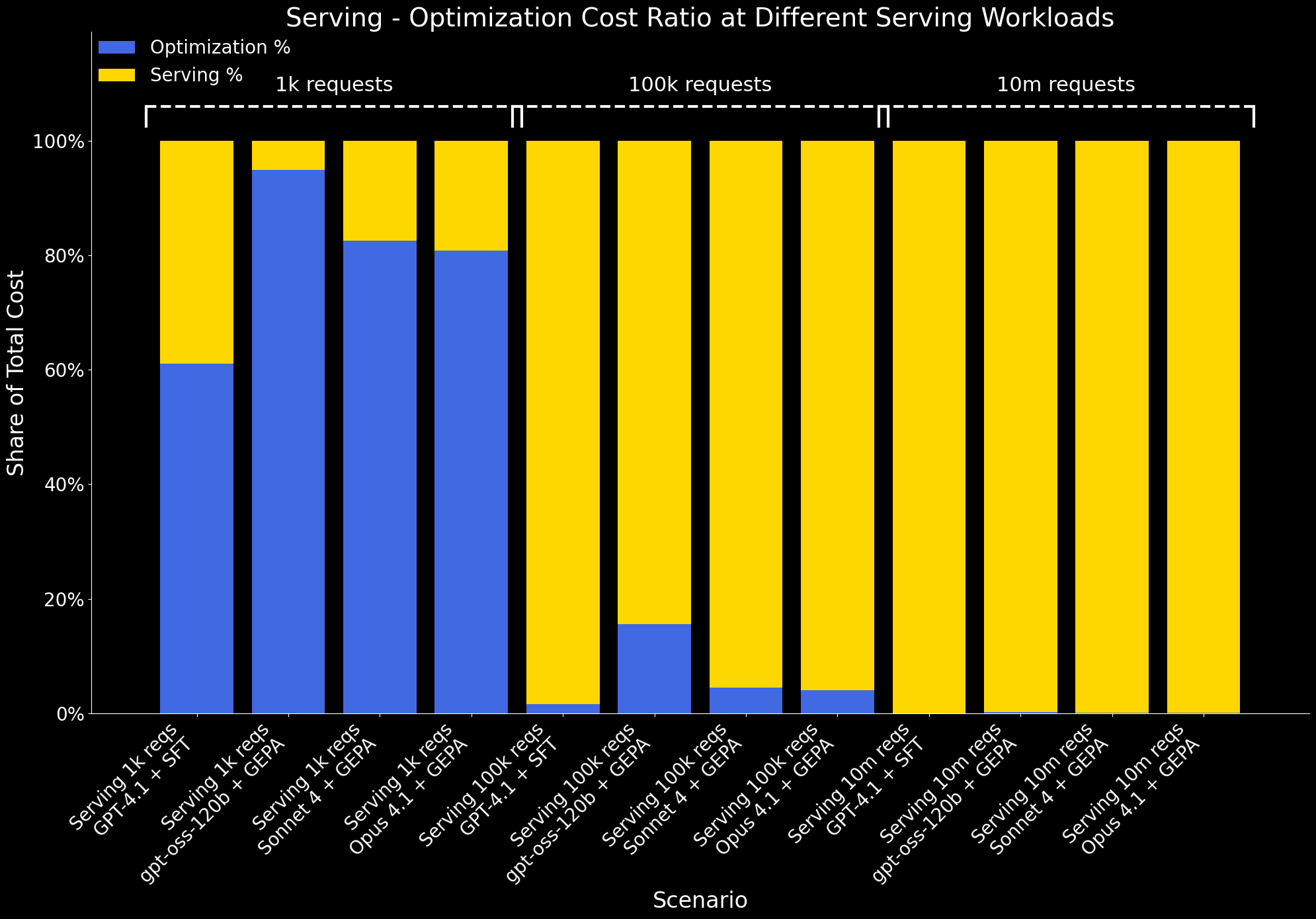
Esaminiamo anche come cambia il rapporto tra costo di ottimizzazione e costo di serving a diverse scale di carico di lavoro:
- Con 1.000 richieste di serving, i costi di serving sono minimi, quindi l'ottimizzazione rappresenta una quota elevata del costo totale.
- Con 100.000 richieste, i costi di serving aumentano significativamente e l'overhead di ottimizzazione viene ammortizzato. A questa scala, il beneficio dell'ottimizzazione – migliori performance a un costo di serving inferiore – supera chiaramente il suo costo una tantum.
- Con 10 milioni di richieste, i costi di ottimizzazione diventano trascurabili rispetto ai costi di serving e non sono più visibili nel grafico.
Riepilogo
In questo post del blog, abbiamo dimostrato che l'ottimizzazione automatica dei prompt è una leva potente per migliorare le performance LLM nei task di AI enterprise:
- Abbiamo sviluppato IE Bench, una suite di valutazione completa che copre domini reali e cattura complesse sfide di information extraction.
- Applicando l'ottimizzazione automatica dei prompt GEPA, aumentiamo le performance del modello open-source leader gpt-oss-120b per superare le performance del modello proprietario allo stato dell'arte Claude Opus 4.1 di circa il 3%, pur essendo 90 volte più economico da servire.
- La stessa tecnica si applica ai modelli proprietari frontier, potenziando Claude Sonnet 4 e Claude Opus 4.1 del 6-7%.
- Rispetto al Supervised Fine-Tuning (SFT), l'ottimizzazione GEPA offre un trade-off qualità-costo superiore per l'uso enterprise. Offre performance pari o superiori a SFT riducendo i costi di serving del 20%.
- L'analisi del costo totale mostra che, quando si serve su larga scala (ad es. 100.000 richieste), l'overhead di ottimizzazione una tantum viene rapidamente ammortizzato e i benefici superano di gran lunga il costo. In particolare, GEPA su gpt-oss-120b offre un costo totale inferiore di un ordine di grandezza rispetto ad altri modelli frontier, rendendolo una scelta molto attraente per gli agenti AI enterprise.
Nel complesso, i nostri risultati dimostrano che l'ottimizzazione dei prompt sposta il frontiera di Pareto qualità-costo per i sistemi AI enterprise, aumentando sia le performance che l'efficienza.
L'ottimizzazione automatica dei prompt, insieme alle funzionalità TAO, RLVR e ALHF pubblicate in precedenza, è ora disponibile in Agent Bricks. Il principio fondamentale di Agent Bricks è aiutare le aziende a creare agenti che ragionino accuratamente sui tuoi dati e raggiungano qualità e efficienza dei costi all'avanguardia per attività specifiche del dominio. Unificando la valutazione, l'ottimizzazione automatica e il deployment governato, Agent Bricks consente ai tuoi agenti di adattarsi ai tuoi dati e alle tue attività, apprendere dal feedback e migliorare continuamente nelle tue attività specifiche del dominio aziendale. Incoraggiamo i clienti a provare l'estrazione di informazioni e altre funzionalità di Agent Bricks per ottimizzare gli agenti per i propri casi d'uso aziendali.
1 Sia per la serie di modelli gpt-oss che gpt-5, seguiamo le best practice del formato Harmony di OpenAI che inserisce lo schema JSON di destinazione nel messaggio dello sviluppatore per generare output strutturato.
Inoltre, analizziamo i diversi sforzi di ragionamento per la serie gpt-oss (basso, medio, alto) e la serie gpt-5 (minimo, basso, medio, alto) e riportiamo le migliori prestazioni di ciascun modello in tutti gli sforzi di ragionamento.
2 Per le stime dei costi di serving, utilizziamo i prezzi pubblicati dalle piattaforme dei fornitori di modelli (OpenAI e Anthropic per i modelli proprietari) e da Artificial Analysis per i modelli open-source. I costi vengono calcolati applicando questi prezzi alle distribuzioni di token di input e output osservate in IE Bench, ottenendo il costo totale di serving per ciascun modello.
3 Il tempo di esecuzione effettivo dell'ottimizzazione automatica dei prompt è difficile da stimare, poiché dipende da molti fattori. Qui forniamo una stima approssimativa basata sulla nostra esperienza empirica.
4 Stimiamo il costo di serving di SFT gpt-4.1 utilizzando i prezzi pubblicati da OpenAI per i modelli fine-tuned. Per i modelli ottimizzati GEPA, calcoliamo il costo di serving in base all'utilizzo dei token di input e output misurato dei prompt ottimizzati.
Autori: Arnav Singhvi, Ivan Zhou, Erich Elsen, Krista Opsahl-Ong, Michael Bendersky, Matei Zaharia, Xing Chen, Omar Khattab, Xiangrui Meng, Simon Favreau-Lessard
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.