La potenza di RLVR: addestramento di un modello di ragionamento SQL leader su Databricks
Una semplice ricetta per il ragionamento aziendale
Aggiornamento: Puoi leggere di più sui nostri risultati nel nostro nuovo white paper tecnico disponibile qui su arXiv.
Aggiornamento (12 agosto 2025): Il nostro modello addestrato con RLVR raggiunge ora le migliori prestazioni su Bird Bench nella categoria generale single-model se combinato con la self-consistency! Superiamo i risultati single-model sia con che senza self-consistency (sono ammesse chiamate multiple a LLM). Di seguito abbiamo discusso come abbiamo ottenuto il miglior modello nella categoria single-model single LLM-call (cioè, senza self-consistency). Ciò dimostra che la potenza dell'addestramento RLVR e l'uso di strategie di calcolo al momento del test come la self-consistency possono essere combinati in modo efficace. Sia best-of-n che RLVR vengono distribuiti ai nostri clienti in Agent Bricks.
In Databricks, utilizziamo il reinforcement learning (RL) per sviluppare modelli di ragionamento per i problemi che i nostri clienti affrontano, nonché per i nostri prodotti, come il Databricks Assistant e l' AI/BI Genie. Questi compiti includono la generazione di codice, l'analisi dei dati, l'integrazione della conoscenza organizzativa, la valutazione specifica del dominio e l'estrazione di informazioni (IE) da documenti. Compiti come la codifica o l'estrazione di informazioni hanno spesso ricompense verificabili: la correttezza può essere controllata direttamente (ad esempio, superando test, corrispondendo a etichette). Ciò consente il reinforcement learning senza un modello di ricompensa appreso, noto come RLVR (reinforcement learning with verifiable rewards). In altri domini, potrebbe essere richiesto un modello di ricompensa personalizzato, che Databricks supporta anche. In questo post, ci concentriamo sull'impostazione RLVR.
Come esempio della potenza di RLVR, abbiamo applicato il nostro stack di addestramento a un popolare benchmark accademico di data science chiamato BIRD. Questo benchmark studia il compito di trasformare una query in linguaggio naturale in codice SQL che viene eseguito su un database. Questo è un problema importante per gli utenti Databricks, che consente a esperti non SQL di parlare con i propri dati. È anche un compito impegnativo in cui anche i migliori LLM proprietari non funzionano bene out of the box. Sebbene BIRD non catturi completamente la complessità del mondo reale di questo compito né l'ampiezza completa di prodotti come Databricks AI/BI Genie (Figura 1), la sua popolarità ci consente di misurare l'efficacia di RLVR per la data science su un benchmark ben compreso.
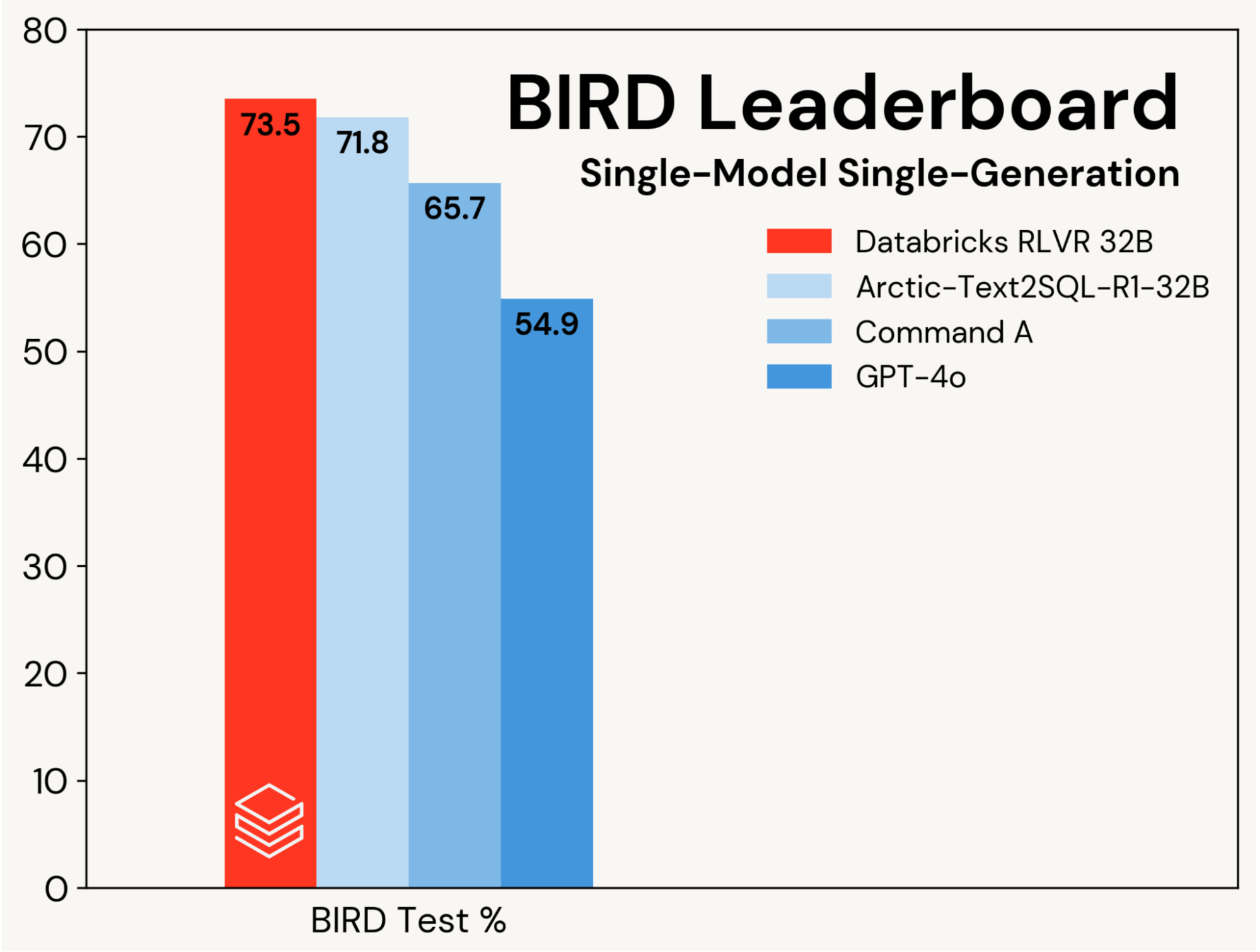
Ci concentriamo sul miglioramento di un modello di codifica SQL di base utilizzando RLVR, isolando questi guadagni dai miglioramenti guidati da progettazioni agentive. Il progresso viene misurato sulla traccia single-model, single-generation della leaderboard BIRD (cioè, senza self-consistency), che valuta su un set di test privato.
Abbiamo stabilito un nuovo stato dell'arte nell'accuratezza dei test del 73,5% su questo benchmark. Lo abbiamo fatto utilizzando il nostro stack RLVR standard e addestrando solo sul set di addestramento BIRD. Il punteggio migliore precedente su questa traccia era 71,8%[1], ottenuto aumentando il set di addestramento BIRD con dati aggiuntivi e utilizzando un LLM proprietario (GPT-4o). Il nostro punteggio è sostanzialmente migliore sia del modello di base originale che degli LLM proprietari (vedi Figura 2). Questo risultato dimostra la semplicità e la generalità di RLVR: abbiamo raggiunto questo punteggio con dati off-the-shelf e i componenti RL standard che stiamo distribuendo in Agent Bricks, e lo abbiamo fatto alla nostra prima sottomissione a BIRD. RLVR è un potente baseline che gli sviluppatori AI dovrebbero considerare ogni volta che sono disponibili dati di addestramento sufficienti.
Abbiamo costruito la nostra sottomissione basandoci sul dev set di BIRD. Abbiamo scoperto che Qwen 2.5 32B Coder Instruct era il miglior punto di partenza. Abbiamo affinato questo modello utilizzando sia Databricks TAO– un metodo RL offline, sia il nostro stack RLVR. Questo approccio, insieme a un'attenta selezione del prompt e del modello, è stato sufficiente per portarci in cima al BIRD Benchmark. Questo risultato è una dimostrazione pubblica delle stesse tecniche che utilizziamo per migliorare prodotti Databricks popolari come AI/BI Genie e Assistant e per aiutare i nostri clienti a costruire agenti utilizzando Agent Bricks.
I nostri risultati evidenziano la potenza di RLVR e l'efficacia del nostro stack di addestramento. Anche i clienti Databricks hanno riportato ottimi risultati utilizzando il nostro stack nei loro domini di ragionamento. Pensiamo che questa ricetta sia potente, componibile e ampiamente applicabile a una serie di compiti. Se desideri provare RLVR su Databricks, contattaci qui.
1Vedi Tabella 1 in https://arxiv.org/pdf/2505.20315
Autori: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.