TAO: Utilizzo del calcolo in fase di test per addestrare LLM efficienti senza dati etichettati
I modelli linguistici di grandi dimensioni (LLM) sono difficili da adattare a nuovi compiti aziendali. Il prompting è soggetto a errori e ottiene guadagni di qualità limitati, mentre il fine-tuning richiede grandi quantità di dati etichettati manualmente che non sono disponibili per la maggior parte dei compiti aziendali. Oggi introduciamo un nuovo metodo di ottimizzazione dei modelli che richiede solo dati di utilizzo non etichettati, consentendo alle aziende di migliorare la qualità e i costi dell'IA utilizzando solo i dati che già possiedono. Il nostro metodo, Test-time Adaptive Optimization (TAO), sfrutta il calcolo al momento del test (come reso popolare da o1 e R1) e il reinforcement learning (RL) per insegnare a un modello a svolgere meglio un compito basandosi solo su esempi di input passati, il che significa che scala con un budget di calcolo di ottimizzazione regolabile, non con lo sforzo di etichettatura umana. Fondamentalmente, sebbene TAO utilizzi il calcolo al momento del test, lo utilizza come parte del processo per addestrare un modello; tale modello esegue quindi il compito direttamente con bassi costi di inferenza (cioè, non richiede calcolo aggiuntivo al momento dell'inferenza). Sorprendentemente, anche senza dati etichettati, TAO può raggiungere una qualità del modello migliore rispetto al fine-tuning tradizionale e può portare modelli open source economici come Llama alla qualità di modelli proprietari costosi come GPT-4o e o3-mini.
TAO fa parte del programma del nostro team di ricerca sulla Data Intelligence, ovvero il problema di far eccellere l'IA in domini specifici utilizzando i dati che le aziende già possiedono. Con TAO, otteniamo tre risultati entusiasmanti:
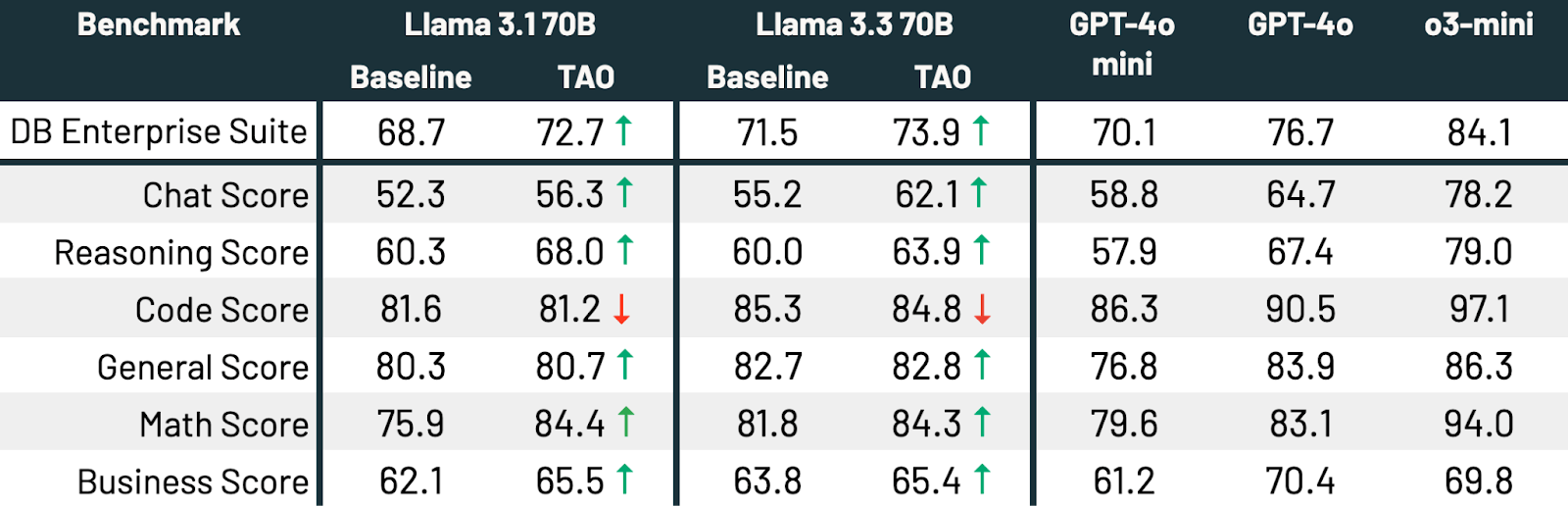
- Su compiti aziendali specializzati come la risposta a domande su documenti e la generazione di SQL, TAO supera il fine-tuning tradizionale su migliaia di esempi etichettati. Porta modelli open source efficienti come Llama 8B e 70B a una qualità simile a quella di modelli costosi come GPT-4o e o3-mini1 senza la necessità di etichette.
- Possiamo anche utilizzare il TAO multi-task per migliorare un LLM in modo generale su molti compiti. Senza utilizzare etichette, TAO migliora le prestazioni di Llama 3.3 70B del 2,4% su un benchmark aziendale generale.
- Aumentare il budget di calcolo di TAO al momento dell'ottimizzazione produce una migliore qualità del modello con gli stessi dati, mentre i costi di inferenza del modello ottimizzato rimangono invariati.
La Figura 1 mostra come TAO migliora i modelli Llama su tre compiti aziendali: FinanceBench, DB Enterprise Arena e BIRD-SQL (utilizzando il dialetto Databricks SQL)². Nonostante abbia accesso solo agli input degli LLM, TAO supera il fine-tuning tradizionale (FT) con migliaia di esempi etichettati e porta Llama allo stesso livello di modelli proprietari costosi.
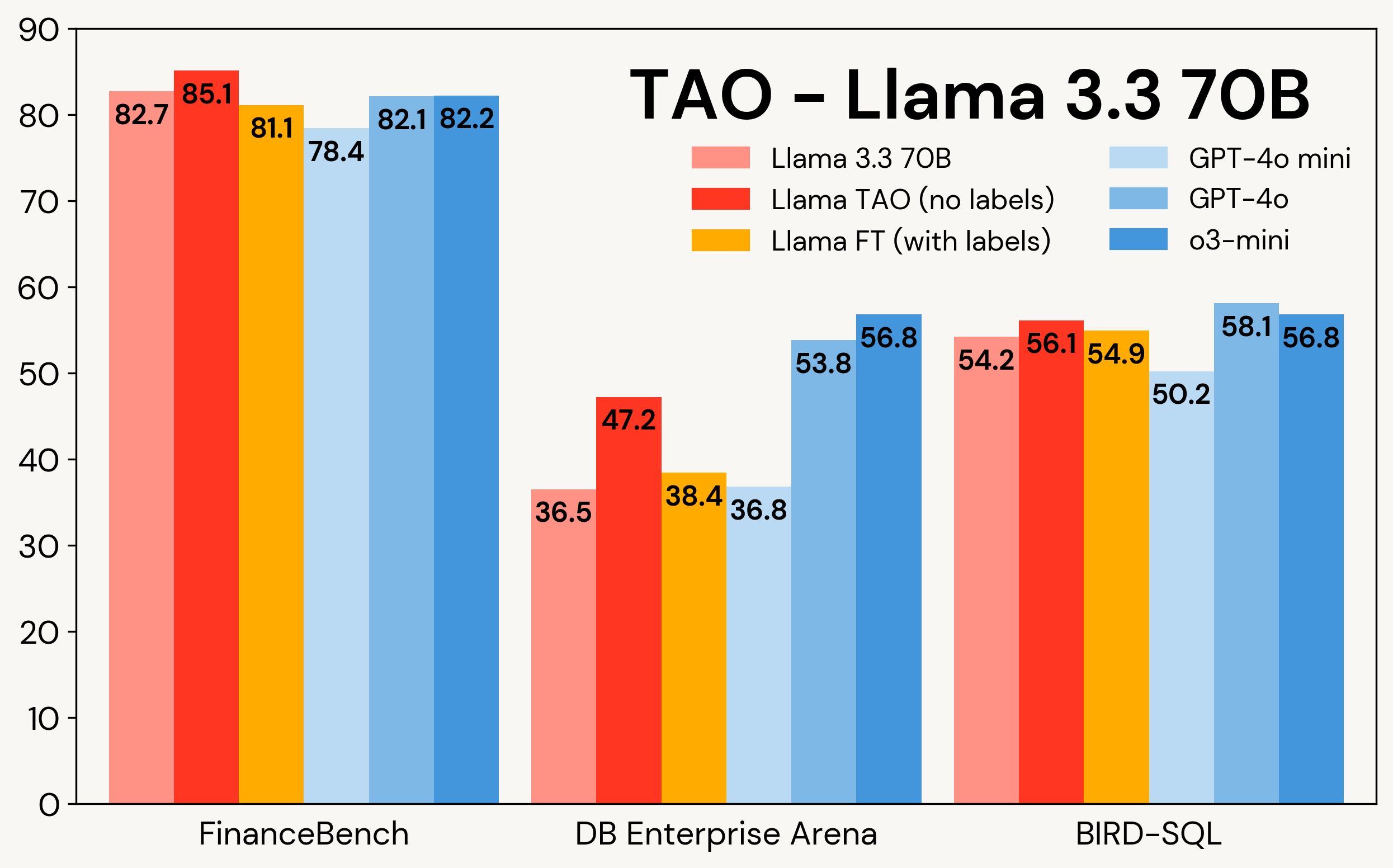
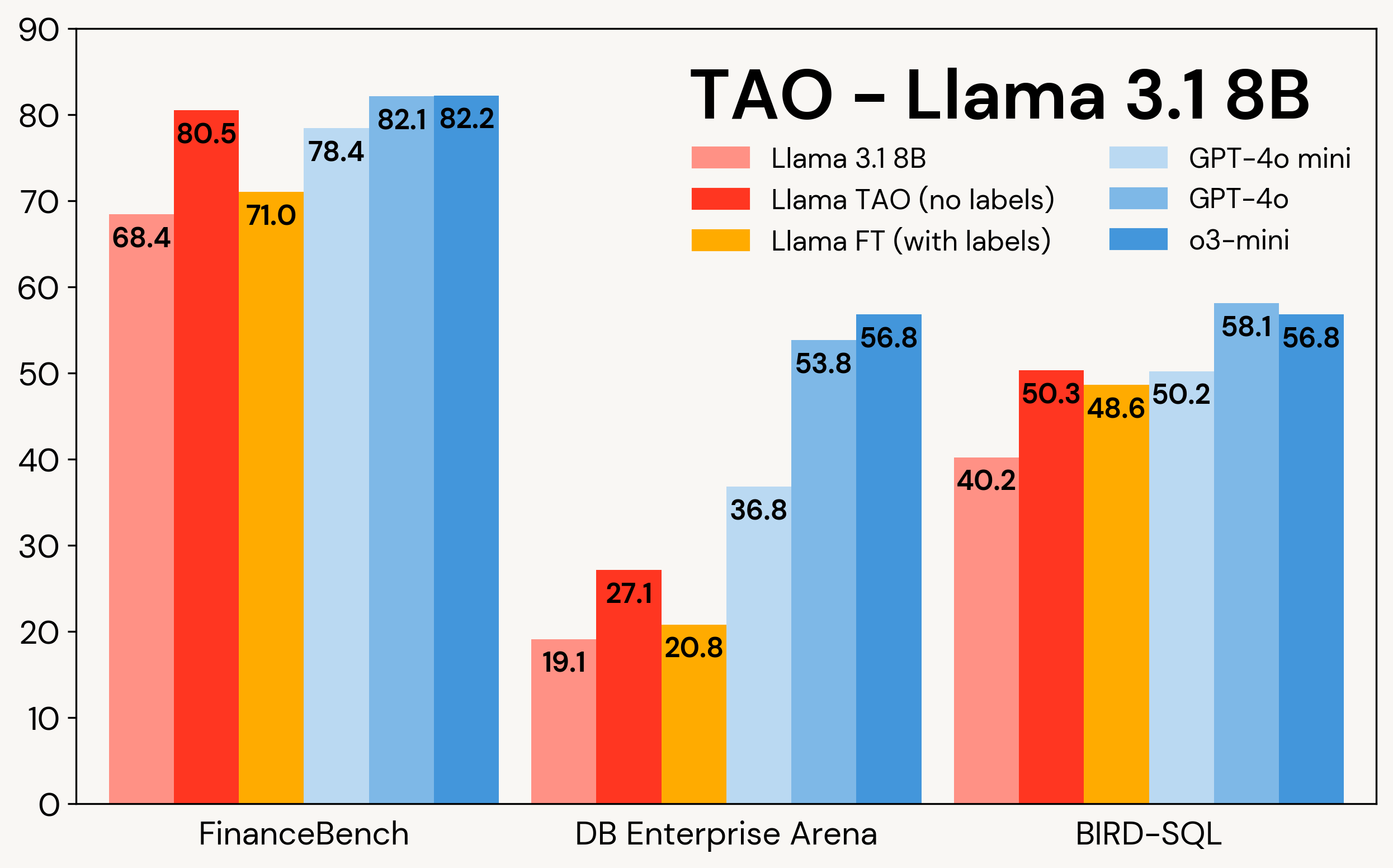
Figura 1: TAO su Llama 3.1 8B e Llama 3.3 70B su tre benchmark aziendali. TAO porta a miglioramenti sostanziali della qualità, superando il fine-tuning e sfidando costosi LLM proprietari.
TAO è ora disponibile in anteprima per i clienti Databricks che desiderano ottimizzare Llama e alimenterà diversi prodotti in arrivo. Compila questo modulo per esprimere il tuo interesse a provarlo sui tuoi compiti come parte dell'anteprima privata. In questo post, descriviamo più in dettaglio come funziona TAO e i nostri risultati con esso.
Come Funziona TAO? Utilizzo del Calcolo al Momento del Test e del Reinforcement Learning per Ottimizzare i Modelli
Invece di richiedere dati di output annotati manualmente, l'idea chiave in TAO è utilizzare il calcolo al momento del test per far esplorare a un modello risposte plausibili per un compito, quindi utilizzare il reinforcement learning per aggiornare un LLM in base alla valutazione di queste risposte. Questa pipeline può essere scalata utilizzando il calcolo al momento del test, invece di costosi sforzi umani, per aumentare la qualità. Inoltre, può essere facilmente personalizzata utilizzando insight specifici del compito (ad esempio, regole personalizzate). Sorprendentemente, l'applicazione di questa scalatura con modelli open source di alta qualità porta in molti casi a risultati migliori rispetto alle etichette umane.
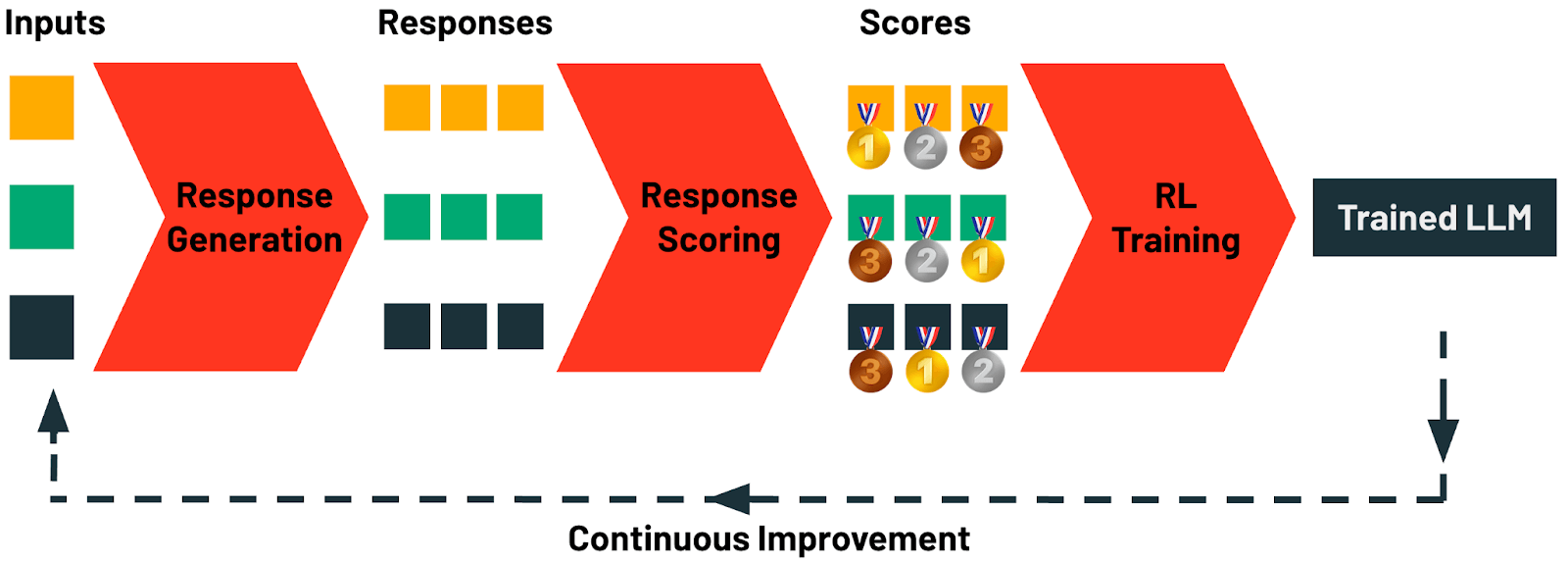
Nello specifico, TAO comprende quattro fasi:
- Generazione delle Risposte: Questa fase inizia con la raccolta di prompt o query di input di esempio per un compito. Su Databricks, questi prompt possono essere raccolti automaticamente da qualsiasi applicazione AI utilizzando il nostro AI Gateway. Ogni prompt viene quindi utilizzato per generare un set diversificato di risposte candidate. È possibile applicare qui un ricco spettro di strategie di generazione, che vanno dal semplice prompting chain-of-thought a tecniche di ragionamento sofisticate e prompting strutturato.
- Valutazione delle Risposte: In questa fase, le risposte generate vengono valutate sistematicamente. Le metodologie di valutazione includono una varietà di strategie, come il reward modeling, la valutazione basata sulle preferenze o la verifica specifica del compito utilizzando LLM judge o regole personalizzate. Questa fase garantisce che ogni risposta generata sia valutata quantitativamente per qualità e allineamento con i criteri.
- Addestramento con Reinforcement Learning (RL): Nella fase finale, viene applicato un approccio basato su RL per aggiornare l'LLM, guidando il modello a produrre output strettamente allineati con le risposte ad alto punteggio identificate nel passaggio precedente. Attraverso questo processo di apprendimento adattivo, il modello affina le sue previsioni per migliorare la qualità.
- Miglioramento Continuo: L'unico dato di cui TAO ha bisogno sono gli input di esempio degli LLM. Gli utenti creano naturalmente questi dati interagendo con un LLM. Non appena il tuo LLM viene distribuito, inizi a generare dati di addestramento per il ciclo successivo di TAO. Su Databricks, il tuo LLM può migliorare più lo usi, grazie a TAO.
Fondamentalmente, sebbene TAO utilizzi il calcolo al momento del test, lo utilizza per addestrare un modello che poi esegue un compito direttamente con bassi costi di inferenza. Ciò significa che i modelli prodotti da TAO hanno lo stesso costo e velocità di inferenza del modello originale, significativamente inferiori rispetto ai modelli con calcolo al momento del test come o1, o3 e R1. Come dimostrano i nostri risultati, i modelli open source efficienti addestrati con TAO possono competere in qualità con i principali modelli proprietari.
TAO fornisce un nuovo e potente metodo nel toolkit per l'ottimizzazione dei modelli AI. A differenza del prompt engineering, che è lento e soggetto a errori, e del fine-tuning, che richiede la produzione di etichette umane costose e di alta qualità, TAO consente agli ingegneri AI di ottenere ottimi risultati semplicemente fornendo esempi di input rappresentativi del loro compito.
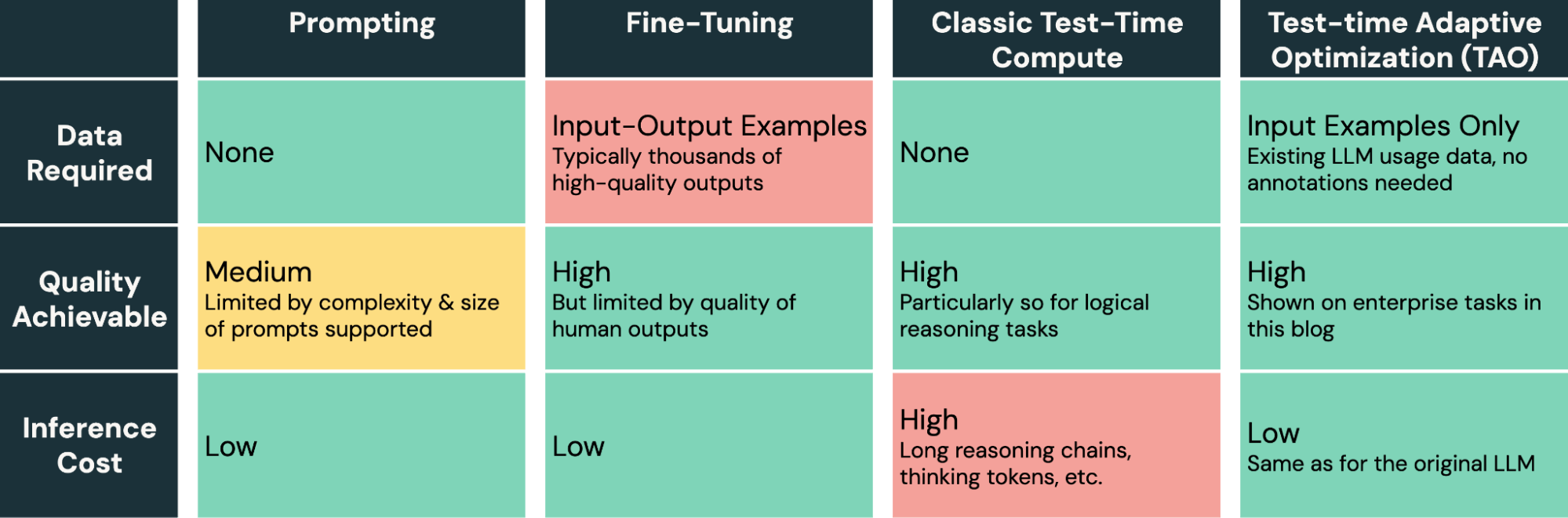
TAO è un metodo altamente flessibile che può essere personalizzato se necessario, ma la nostra implementazione predefinita in Databricks funziona bene out-of-the-box su diversi compiti aziendali. Al centro della nostra implementazione ci sono nuove tecniche di reinforcement learning e reward modeling sviluppate dal nostro team che consentono a TAO di apprendere tramite esplorazione e quindi di ottimizzare il modello sottostante utilizzando RL. Ad esempio, uno degli ingredienti che alimentano TAO è un modello di ricompensa personalizzato che abbiamo addestrato per compiti aziendali, DBRM, in grado di produrre segnali di valutazione accurati su un'ampia gamma di compiti.
Migliorare le Prestazioni dei Compiti con TAO
In questa sezione, approfondiamo come abbiamo utilizzato TAO per ottimizzare gli LLM su compiti aziendali specializzati. Abbiamo selezionato tre benchmark rappresentativi, inclusi popolari benchmark open source e quelli interni che abbiamo sviluppato come parte della nostra Suite di Benchmark per la Data Intelligence (DIBS).

Per ogni compito, abbiamo valutato diversi approcci:
- Utilizzo di un modello Llama open source (Llama 3.1-8B o Llama 3.3-70B) pronto all'uso.
- Fine-tuning su Llama. Per fare ciò, abbiamo utilizzato o creato set di dati di input-output ampi e realistici con migliaia di esempi, che è solitamente ciò che è necessario per ottenere buone prestazioni con il fine-tuning. Questi includevano:
- 7200 domande sintetiche su documenti SEC per FinanceBench.
- 4800 input scritti da esseri umani per DB Enterprise Arena.
- 8137 esempi dal set di addestramento BIRD-SQL, modificati per corrispondere al dialetto Databricks SQL.
- TAO su Llama, utilizzando solo gli input di esempio dei nostri set di dati di fine-tuning, ma non gli output, e utilizzando il nostro modello di ricompensa DBRM focalizzato sull'azienda. DBRM stesso non è addestrato su questi benchmark.
- LLM proprietari di alta qualità – GPT 4o-mini, GPT 4o e o3-mini.
Come mostrato nella Tabella 3, attraverso tutti e tre i benchmark e entrambi i modelli Llama, TAO migliora significativamente le prestazioni di base di Llama, anche oltre quelle del fine-tuning.

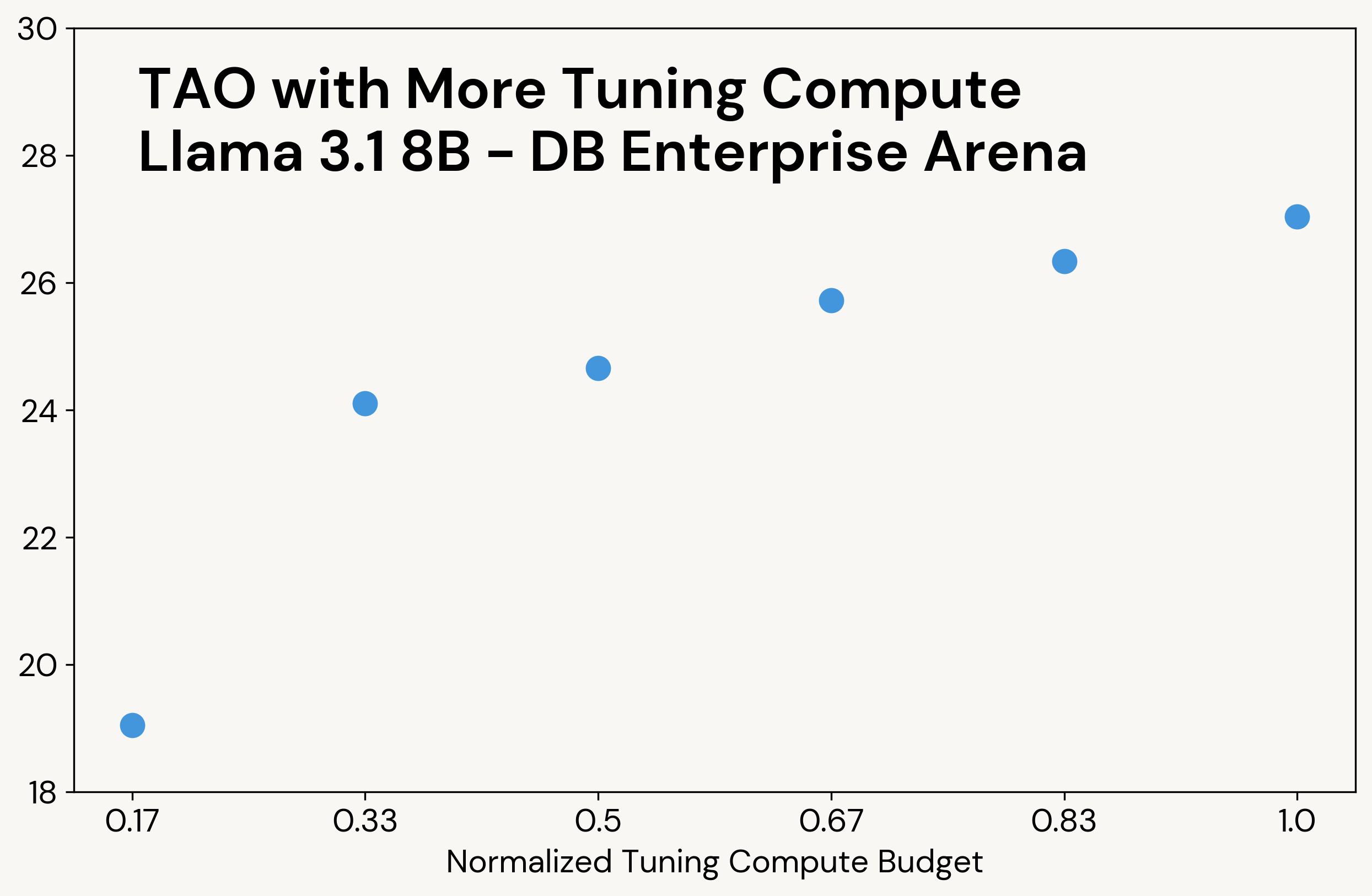
Come il classico calcolo al momento del test, TAO produce risultati di qualità superiore quando gli viene dato accesso a più risorse di calcolo (vedi Figura 3 per un esempio). A differenza del calcolo al momento del test, tuttavia, questo calcolo aggiuntivo viene utilizzato solo durante la fase di tuning; il LLM finale ha lo stesso costo di inferenza del LLM originale. Ad esempio, o3-mini produce 5-10 volte più token di output rispetto agli altri modelli nei nostri task, con conseguente costo di inferenza proporzionalmente più elevato, mentre TAO ha lo stesso costo di inferenza del modello Llama originale.
Migliorare l'intelligenza multitask con TAO
Finora, abbiamo utilizzato TAO per migliorare i LLM su singoli task specifici, come la generazione di SQL. Tuttavia, man mano che gli agenti diventano più complessi, le aziende necessitano sempre più di LLM in grado di eseguire più di un task. In questa sezione, mostriamo come TAO possa migliorare ampiamente le prestazioni del modello su una serie di task aziendali.
In questo esperimento, abbiamo raccolto 175.000 prompt che riflettono un set diversificato di task aziendali, tra cui codifica, matematica, risposta a domande, comprensione di documenti e chat. Abbiamo quindi eseguito TAO su Llama 3.1 70B e Llama 3.3 70B. Infine, abbiamo testato una suite di task rilevanti per le aziende, che include popolari benchmark per LLM (ad es. Arena Hard, LiveBench, GPQA Diamond, MMLU Pro, HumanEval, MATH) e benchmark interni in diverse aree rilevanti per le aziende.
TAO migliora significativamente le prestazioni di entrambi i modelli[t][u]. Llama 3.3 70B e Llama 3.1 70B migliorano rispettivamente del 2,4 e 4,0%. TAO avvicina significativamente Llama 3.3 70B a GPT-4o sui task aziendali[v][w]. Tutto ciò è ottenuto senza costi di etichettatura umana, solo dati di utilizzo rappresentativi del LLM e la nostra implementazione di produzione di TAO. La qualità migliora in ogni sottoscore tranne la codifica, dove le prestazioni sono statiche.
Utilizzare TAO in pratica
TAO è un potente metodo di tuning che funziona sorprendentemente bene su molti task sfruttando il calcolo al momento del test. Per utilizzarlo con successo sui tuoi task, avrai bisogno di:
- Input di esempio sufficienti per il tuo task (diverse migliaia), raccolti da un'applicazione AI distribuita (ad es. domande inviate a un agente) o generati sinteticamente.
- Un metodo di punteggio sufficientemente accurato: per i clienti Databricks, uno strumento potente qui è il nostro modello di ricompensa personalizzato, DBRM, che alimenta la nostra implementazione di TAO, ma puoi aumentare DBRM con regole di punteggio personalizzate o verificatori se sono applicabili al tuo task.
Una best practice che abiliterà TAO e altri metodi di miglioramento del modello è creare un data flywheel per le tue applicazioni AI. Non appena distribuisci un'applicazione AI, puoi raccogliere input, output del modello e altri eventi tramite servizi come Databricks Inference Tables. Puoi quindi utilizzare solo gli input per eseguire TAO. Più persone utilizzano la tua applicazione, più dati avrai per ottimizzarla e - grazie a TAO - migliore sarà il tuo LLM.
Conclusione e come iniziare su Databricks
In questo blog, abbiamo presentato Test-time Adaptive Optimization (TAO), una nuova tecnica di tuning dei modelli che ottiene risultati di alta qualità senza bisogno di dati etichettati. Abbiamo sviluppato TAO per affrontare una sfida chiave che abbiamo visto affrontare ai clienti aziendali: mancavano i dati etichettati necessari per il fine-tuning standard. TAO utilizza il calcolo al momento del test e il reinforcement learning per migliorare i modelli utilizzando i dati che le aziende hanno già, come esempi di input, rendendo semplice migliorare la qualità di qualsiasi applicazione AI distribuita e ridurre i costi utilizzando modelli più piccoli. TAO è un metodo altamente flessibile che dimostra la potenza del calcolo al momento del test per lo sviluppo di AI specializzato, e crediamo che darà agli sviluppatori un nuovo strumento potente e semplice da usare insieme al prompting e al fine-tuning.
I clienti Databricks stanno già utilizzando TAO su Llama in anteprima privata. Compila questo modulo per esprimere il tuo interesse a provarlo sui tuoi task come parte dell'anteprima privata. TAO viene anche incorporato in molti dei nostri prossimi aggiornamenti e lanci di prodotti AI - resta sintonizzato!
¹ Autori: Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Jose Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² Utilizziamo o3-mini-medium in tutto questo blog.
³ Questo è il benchmark BIRD-SQL modificato per il dialetto e i prodotti SQL di Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.