AiChemy: Agente di prossima generazione con MCP, Skill e Dati personalizzati per la scoperta di farmaci
AiChemy accelera la scoperta di farmaci integrando dati personalizzati ed esterni (OpenTargets, PubChem, PubMed) attraverso un sistema multi-agente che utilizza MCP, Skills, AI Search e Genie su Databricks
di Yen Low e Sean Zhang
- Una guida alla creazione di AiChemy, un sistema multi-agente su Databricks che integra basi di conoscenza esterne (OpenTargets, PubChem, PubMed) tramite il Model Context Protocol (MCP) con dati strutturati e non strutturati su Databricks.
- La sfida che risolve: Accelera la ricerca interdisciplinare sulla scoperta di farmaci consentendo la collaborazione autonoma tra diversi agenti AI, permettendo loro di setacciare enormi set di dati disparati e fornire risultati tracciabili e basati su prove.
- Risultati: I ricercatori possono identificare bersagli di malattie, valutare candidati farmaci, recuperare proprietà dettagliate ed eseguire valutazioni di sicurezza, portando a una scoperta di farmaci e alla generazione di lead più efficienti.
I sistemi multi-agente accelerano la ricerca interdisciplinare
Immagina sistemi di IA multi-agente che collaborano come un team di esperti interdisciplinari, analizzando autonomamente enormi set di dati per scoprire nuovi pattern e ipotesi. Questo è ora convenientemente realizzabile con il Model Context Protocol (MCP), un nuovo standard per integrare facilmente diverse fonti di dati e strumenti. Il crescente ecosistema di server MCP, dalle basi di conoscenza ai generatori di report, offre capacità infinite.
Cosa fa AiChemy
Incontra AiChemy, un assistente multi-agente che combina server MCP esterni come OpenTargets, PubChem e PubMed con le tue librerie chimiche su Databricks, in modo che le basi di conoscenza combinate possano essere analizzate e interpretate meglio insieme. Ha anche Skills che possono essere caricate opzionalmente per fornire istruzioni dettagliate per la produzione di report specifici per attività, formattati in modo coerente per esigenze di ricerca, normative o aziendali.
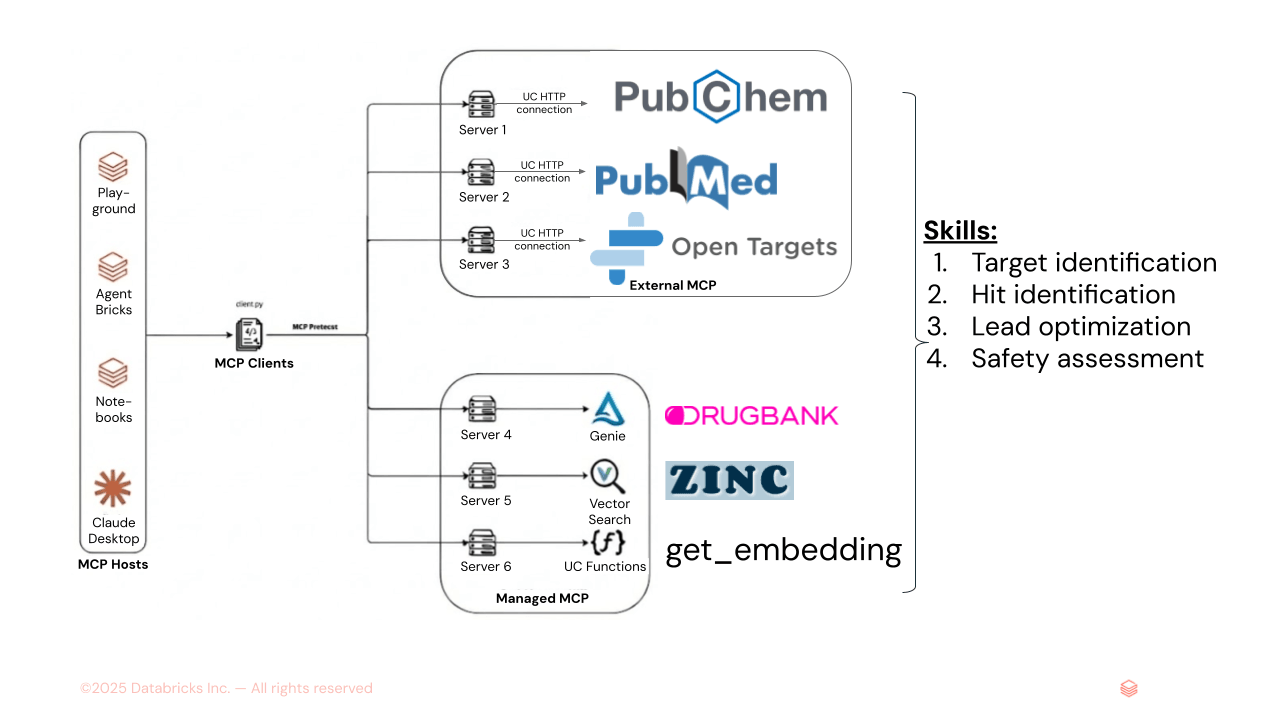
Figura 1. AiChemy è un supervisore multi-agente che comprende server MCP esterni PubChem, PubMed e OpenTargets, e server MCP gestiti da Databricks di Genie Space (text-to-SQL per dati strutturati di DrugBank) e di AI Search (per dati non strutturati come embedding molecolari ZINC). Le Skills possono anche essere caricate per specificare la sequenza delle attività e la formattazione e lo stile dei report per garantire un output coerente.
Le sue capacità chiave includono l'identificazione di target di malattie e candidati farmaci, il recupero delle loro proprietà chimiche e farmacocinetiche dettagliate e la fornitura di valutazioni di sicurezza e tossicità. Fondamentalmente, AiChemy supporta le sue scoperte con prove verificabili da fonti di dati attendibili, rendendolo ideale per la ricerca.
Caso d'uso 1: Comprendere i meccanismi delle malattie, trovare target trattabili e generazione di lead
Il pannello Guided Tasks fornisce i prompt e le Skills degli agenti necessari per eseguire i passaggi chiave nel flusso di lavoro di scoperta di farmaci: malattia -> target -> farmaco -> validazione della letteratura.
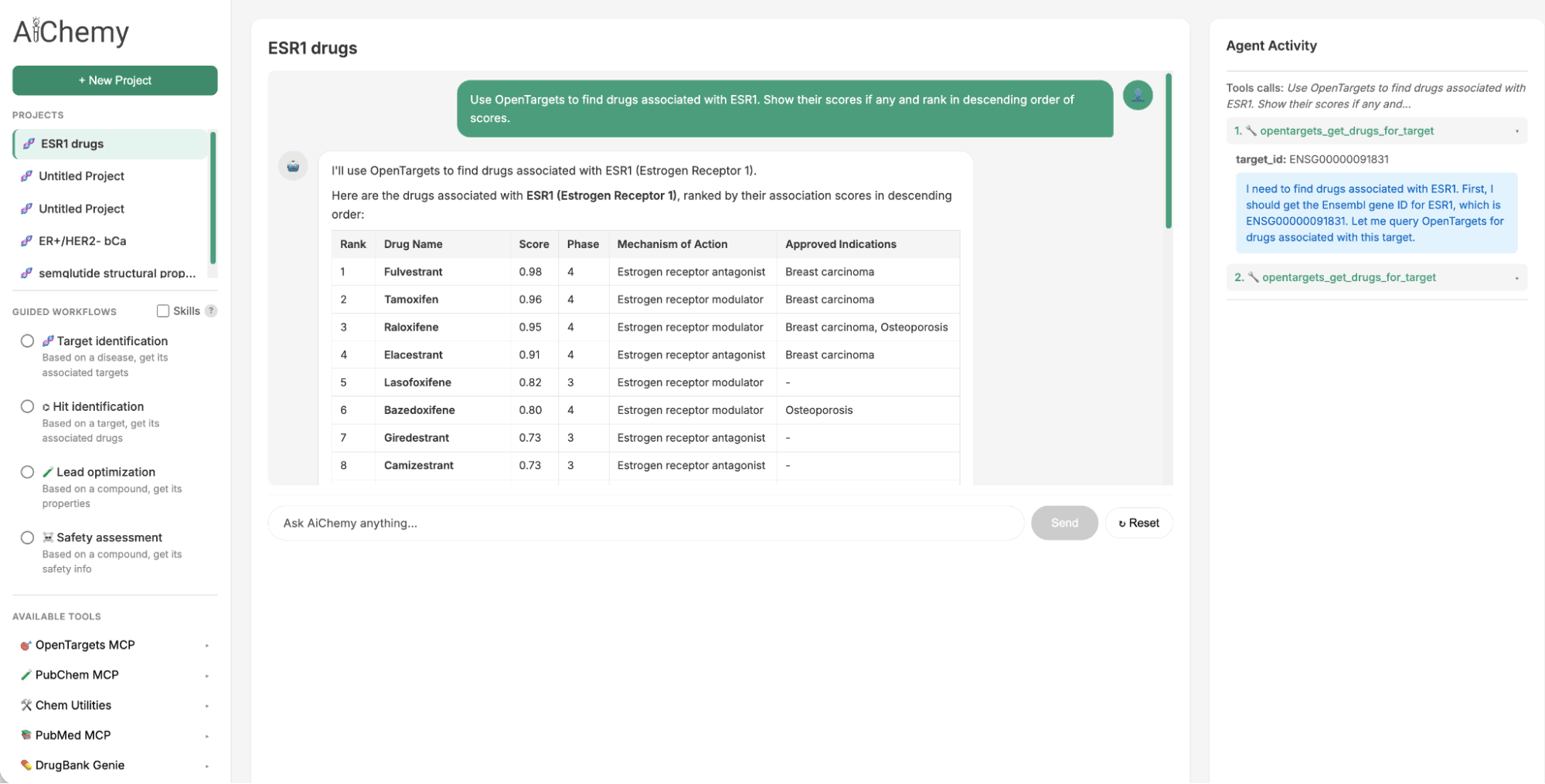
- Identifica Target Terapeutici: Partendo da un sottotipo di malattia specifico, come il cancro al seno Estrogen Receptor-positivo (ER+)/HER2-negativo (HER2-) (dove ER e HER2 sono biomarcatori proteici chiave), trova target terapeutici associati (ad es. ESR1).
- Trova Farmaci Associati: Utilizza il target identificato (ad es. ESR1) per trovare potenziali candidati farmaci.
- Valida con la Letteratura: Per un dato candidato farmaco (ad es. camizestrant), controlla la letteratura scientifica per prove a supporto.
Caso d'uso 2: Generazione di lead per somiglianza chimica
Per identificare un successore del Modulatore Selettivo del Recettore degli Estrogeni (SERM) orale approvato nel 2023, Elacestrant, possiamo sfruttare la somiglianza chimica. Cerchiamo nella vasta libreria chimica ZINC15 molecole simili a Elacestrant, poiché i principi della Relazione Quantitativa Struttura-Attività (QSAR) suggeriscono che condivideranno proprietà simili. Questo viene ottenuto interrogando Databricks AI Search, che utilizza l'embedding molecolare Extended-Connectivity Fingerprint (ECFP) a 1024 bit di Elacestrant (come vettore di query) per trovare gli embedding più simili all'interno dell'indice di 250.000 molecole di ZINC.
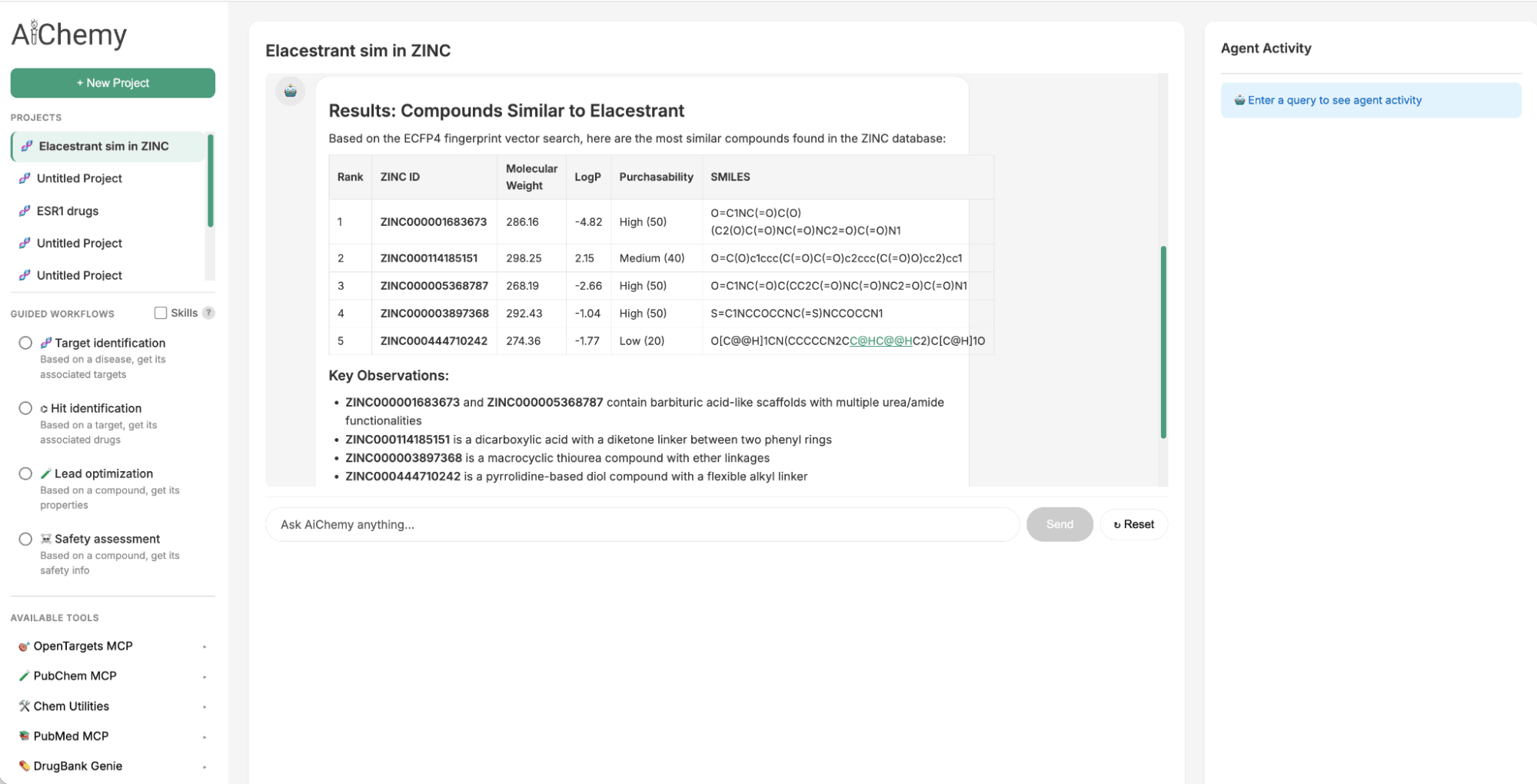
Figura 2. AiChemy include la ricerca vettoriale del database ZINC di 250.000 molecole disponibili in commercio. Ciò ci consente di generare composti lead per somiglianza chimica. In questo screenshot, abbiamo chiesto ad AiChemy di trovare nel database vettoriale ZINC i composti più simili a Elacestrant basati sull'embedding molecolare ECFP4.
Costruisci il tuo supervisore multi-agente per la ricerca
Personalizzeremo un supervisore multi-agente su Databricks integrando server MCP pubblici con dati proprietari su Databricks. Per raggiungere questo obiettivo, hai la possibilità di utilizzare opzioni no-code come Agent Bricks o opzioni di codifica come i Notebook. Il Databricks Playground consente una rapida prototipazione e iterazione dei tuoi agenti.
Passaggio 1: Prepara i componenti richiesti per il supervisore multi-agente
Il sistema multi-agente ha 5 worker:
- OpenTargets: server MCP esterno di un knowledge graph malattia-target-farmaco
- PubMed: server MCP esterno della letteratura biomedica
- PubChem: server MCP esterno dei composti chimici
- Libreria Farmaci (Genie): Una libreria chimica con proprietà farmacologiche strutturate, trasformata in uno spazio Genie per fornire funzionalità text-to-SQL.
- Libreria Chimica (AI Search): Una libreria proprietaria di dati chimici non strutturati con embedding di impronte molecolari, preparata come indice vettoriale per facilitare la ricerca di somiglianza tramite embedding.
Passaggio 1a: Connettiti in modo sicuro ai server MCP pubblici tramite le connessioni Unity Catalog (UC) nell'interfaccia utente o in un Databricks Notebook (ad es. 4_connect_ext_mcp_opentarget.py).
Passaggio 1b: Assicurati che la tua tabella strutturata (ad es. DrugBank) sia trasformata in uno spazio Genie con funzionalità text-to-SQL utilizzando l'interfaccia utente. Vedi 1_load_drugbank and descriptors.py
Passaggio 1c: Assicurati che la tua libreria chimica non strutturata sia creata come indice vettoriale nell'interfaccia utente o in un Notebook per abilitare la ricerca di somiglianza. Vedi 2_create VS zinc15.py
Passaggio 2 (Opzione Semplice): Costruisci il supervisore multi-agente utilizzando il Supervisor Agent no-code in 2 minuti
Per assemblarli, prova i Agent Bricks senza codice che creano un agente supervisore con i componenti sopra tramite l'interfaccia utente e lo distribuiscono a un endpoint API REST, tutto in pochi minuti.
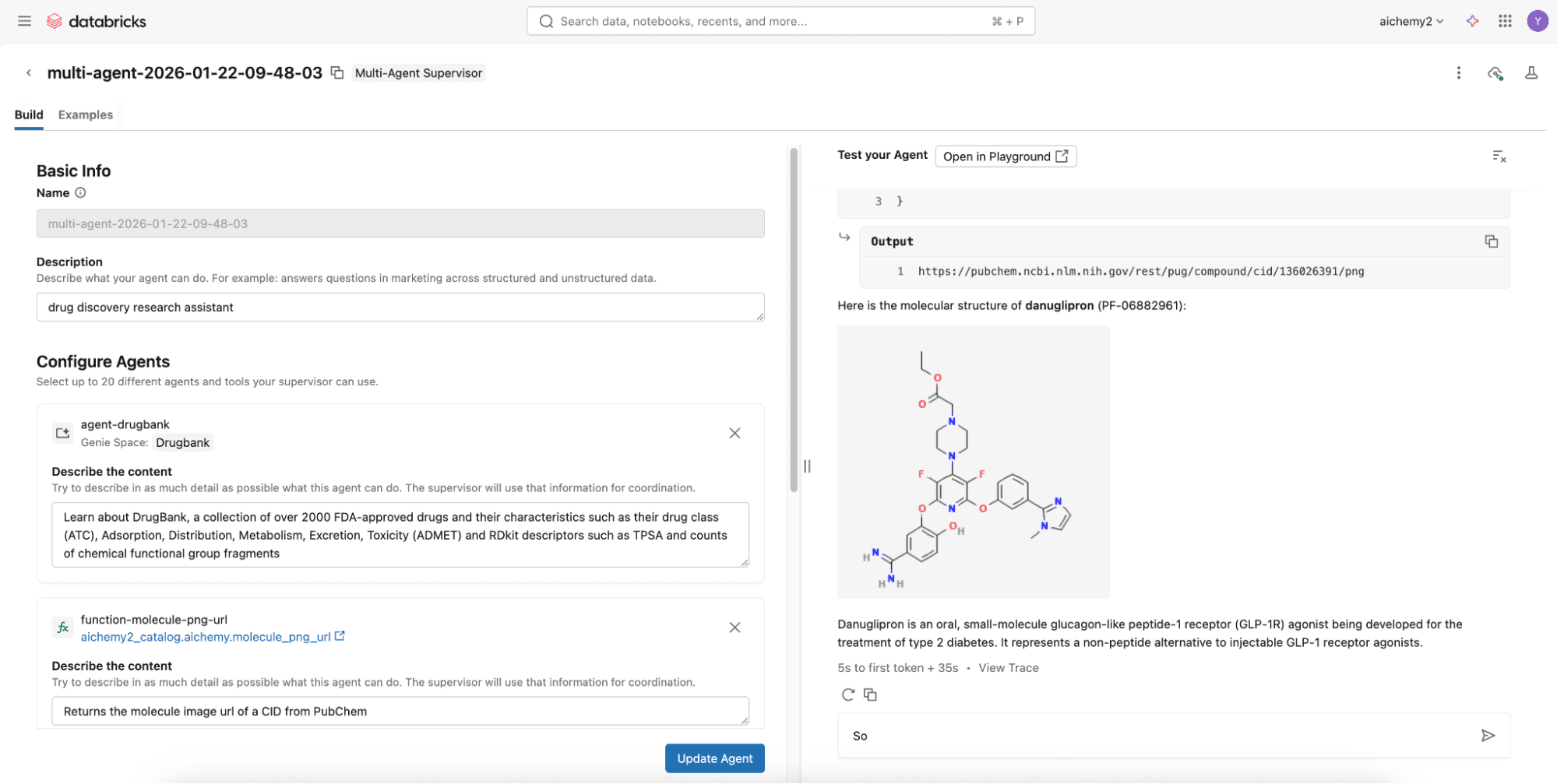
Passaggio 2 (Opzione avanzata): Crea il supervisore multi-agente utilizzando i notebook Databricks
Per funzionalità più avanzate come la memoria agentica e le Skills, sviluppa un supervisore Langgraph su notebook Databricks per integrarlo con Lakebase, il database Databricks Serverless Postgres. Dai un'occhiata a questo repository di codice dove puoi semplicemente definire i componenti multi-agente (vedi Passaggio 1) nel config.yml.
Una volta definito il config.yml, puoi distribuire il supervisore multi-agente come MLflow AgentServer (wrapper FastAPI) con un'interfaccia utente web React. Distribuiscili entrambi su Databricks Apps tramite l'interfaccia utente o Databricks CLI. Imposta i permessi appropriati affinché gli utenti possano utilizzare l'app Databricks e affinché il principal di servizio dell'app possa accedere alle risorse sottostanti (ad esempio, esperimento per il logging delle tracce, scope dei segreti, se presenti).
Passaggio 3: Valuta e monitora il tuo agente
Ogni invocazione dell'agente viene registrata automaticamente e tracciata in un esperimento MLflow Databricks utilizzando gli standard OpenTelemetry. Ciò consente una facile valutazione delle risposte offline o online per migliorare l'agente nel tempo. Inoltre, il tuo agente multi-agente distribuito utilizza l'LLM dietro AI Gateway in modo da poter godere dei vantaggi della governance centralizzata, delle protezioni integrate e dell'osservabilità completa per la prontezza alla produzione.
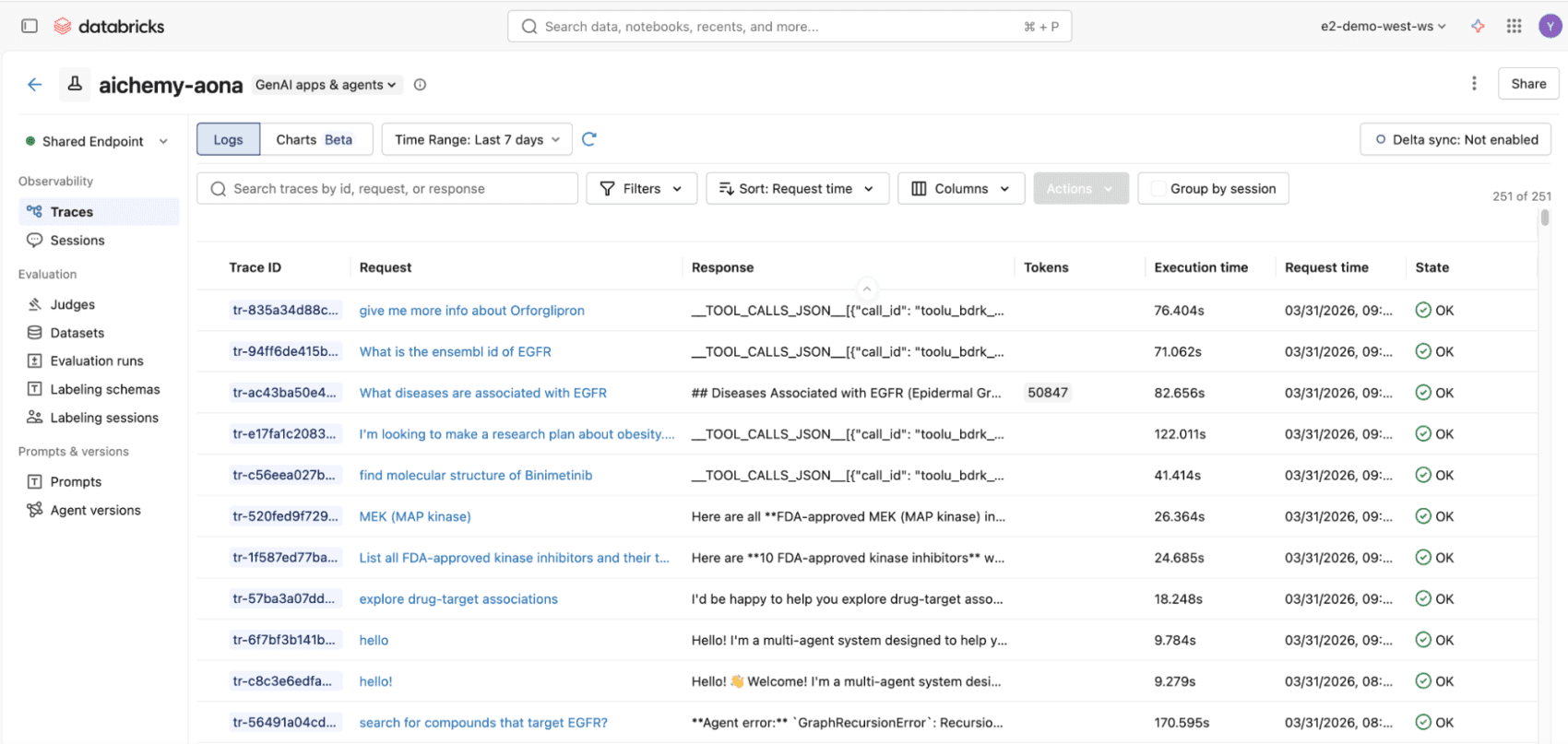
Figura 3. Tutte le invocazioni al multiagente, sia tramite interfaccia utente React che API REST, verranno registrate in tracce MLflow, conformi agli standard OpenTelemetry, per un'osservabilità end-to-end.
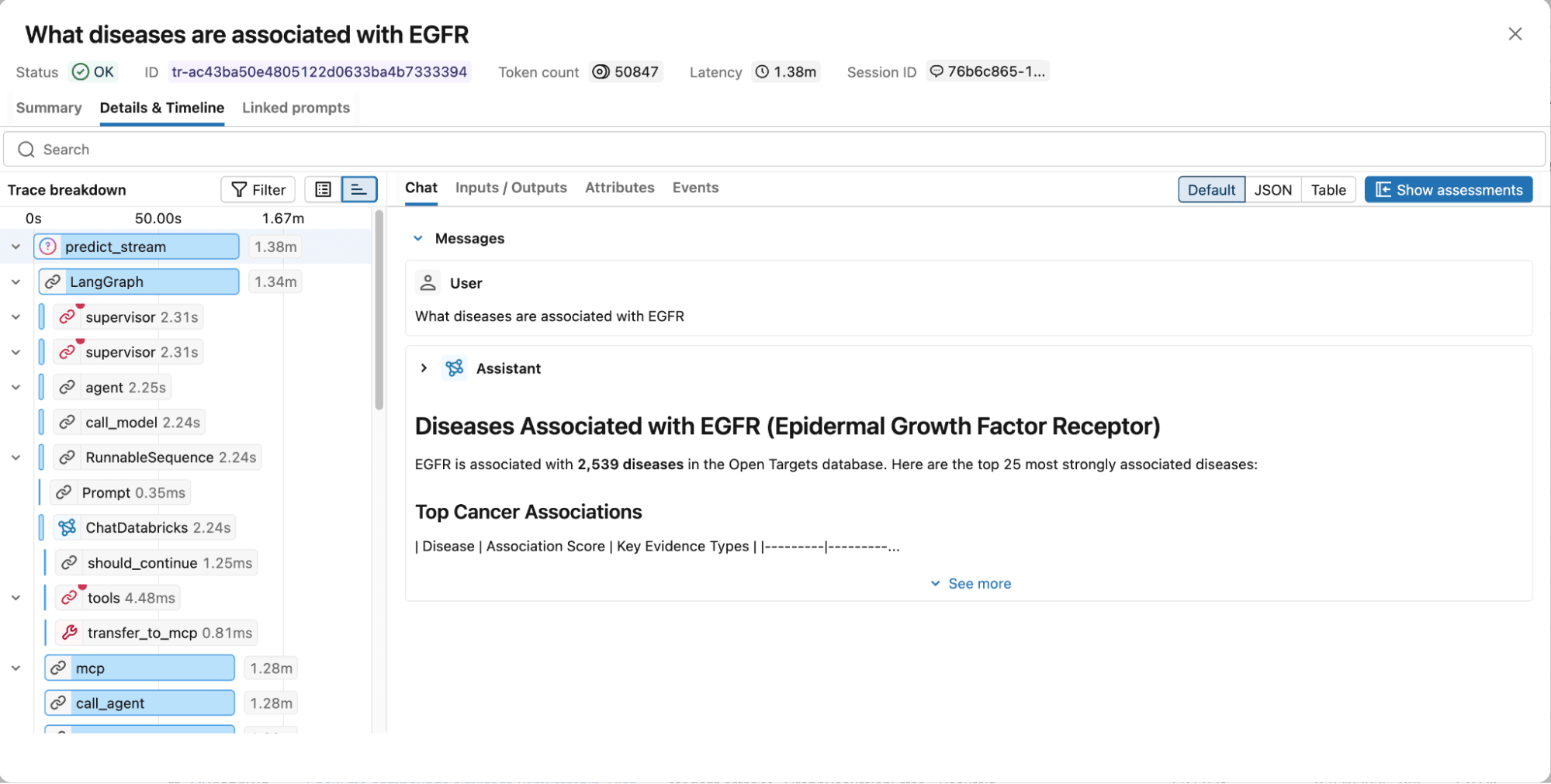
Figura 4. Le tracce MLflow catturano l'intero grafo di esecuzione, inclusi i passaggi di ragionamento, le chiamate agli strumenti, i documenti recuperati, la latenza e l'utilizzo dei token per un facile debug e ottimizzazione.
Prossimi Passaggi
Ti invitiamo a esplorare l'app web AiChemy e il repository Github. Inizia a costruire il tuo sistema multi-agente personalizzato con l'intuitivo framework Agent Bricks senza codice su Databricks, così potrai smettere di cercare e iniziare a scoprire!

(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.