Annuncio del Clustering Liquido Automatico
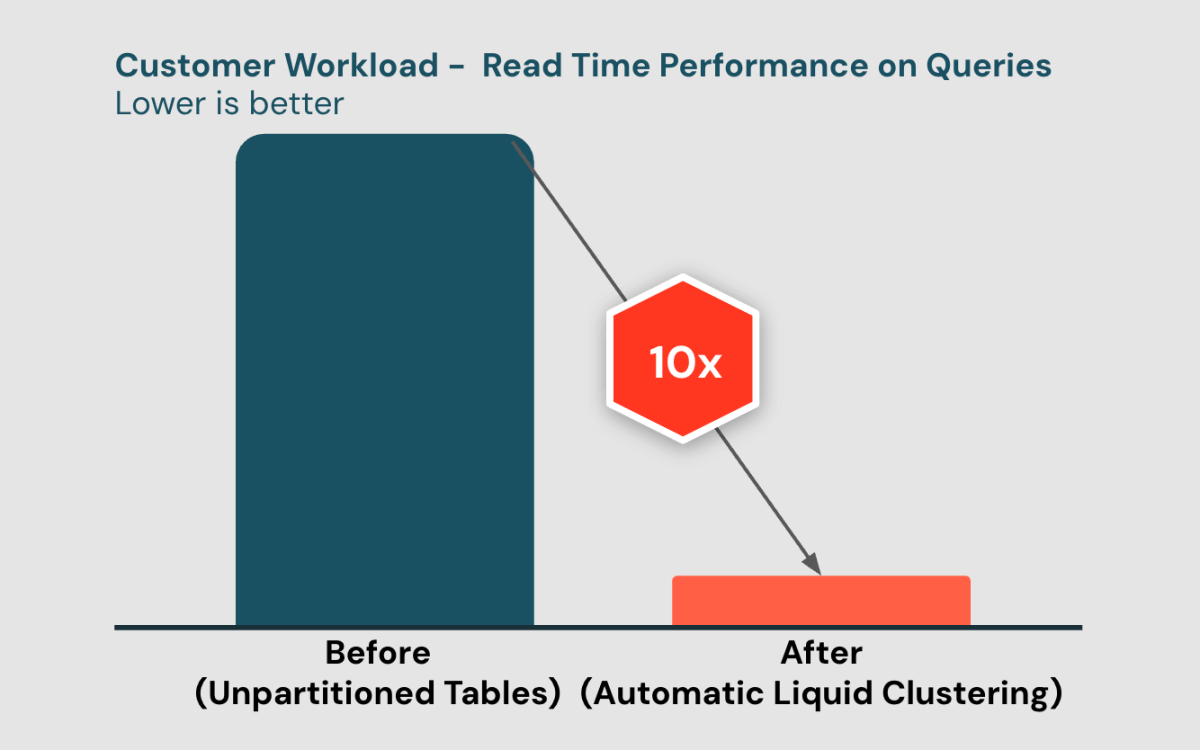
Layout dei dati ottimizzato per query fino a 10 volte più veloci
di Cindy Jiang, Supun Nakandala, Naga Raju Bhanoori, Eric Liang e Parimarjan Negi
- Liquid Clustering automatico, basato su Predictive Optimization, automatizza la selezione delle chiavi di clustering per migliorare continuamente le prestazioni delle query e ridurre i costi.
- Processi di selezione robusti e monitoraggio continuo mantengono le tabelle ottimizzate.
- Il TCO è ridotto al minimo valutando automaticamente se i guadagni di prestazioni superano i costi.
Siamo lieti di annunciare l'anteprima pubblica di Automatic Liquid Clustering, basata su Predictive Optimization. Questa funzionalità applica e aggiorna automaticamente le colonne di Liquid Clustering sulle tabelle gestite di Unity Catalog, migliorando le prestazioni delle query e riducendo i costi.
Automatic Liquid Clustering semplifica la gestione dei dati eliminando la necessità di ottimizzazioni manuali. In precedenza, i team di dati dovevano progettare manualmente il layout specifico dei dati per ciascuna delle loro tabelle. Ora, Predictive Optimization sfrutta la potenza di Unity Catalog per monitorare e analizzare i tuoi dati e i pattern di query.
Per abilitare Automatic Liquid Clustering, configura le tue tabelle UC gestite non partizionate o Liquid impostando il parametro CLUSTER BY AUTO.
Una volta abilitato, Predictive Optimization analizza come vengono interrogate le tue tabelle e seleziona in modo intelligente le chiavi di clustering più efficaci in base al tuo carico di lavoro. Quindi, raggruppa automaticamente la tabella, garantendo che i dati siano organizzati per prestazioni ottimali delle query. Qualsiasi motore che legge dalla tabella Delta beneficia di questi miglioramenti, portando a query significativamente più veloci. Inoltre, poiché i pattern di query cambiano, Predictive Optimization regola dinamicamente lo schema di clustering, eliminando completamente la necessità di ottimizzazioni manuali o decisioni sul layout dei dati durante la configurazione delle tue tabelle Delta.
Durante la Private Preview, decine di clienti hanno testato Automatic Liquid Clustering e hanno ottenuto ottimi risultati. Molti ne hanno apprezzato la semplicità e i guadagni di prestazioni, con alcuni che lo utilizzano già per le loro tabelle gold e pianificano di estenderlo a tutte le tabelle Delta.
I clienti in anteprima come Healthrise hanno segnalato miglioramenti significativi nelle prestazioni delle query con Automatic Liquid Clustering:
“Abbiamo distribuito Automatic Liquid Clustering su tutte le nostre tabelle gold. Da allora, le nostre query sono state fino a 10 volte più veloci. Tutti i nostri carichi di lavoro sono diventati molto più efficienti senza alcun lavoro manuale necessario nella progettazione del layout dei dati o nell'esecuzione della manutenzione.” —Li Zou, Principal Data Engineer, Brian Allee, Director, Data Services | Technology & Analytics, Healthrise
Scegliere il miglior layout dei dati è un problema complesso
Applicare il miglior layout dei dati alle tue tabelle migliora significativamente le prestazioni delle query e l'efficienza dei costi. Tradizionalmente, con il partizionamento, i clienti hanno trovato difficile progettare la giusta strategia di partizionamento per evitare skew dei dati e conflitti di concorrenza. Per migliorare ulteriormente le prestazioni, i clienti potrebbero utilizzare ZORDER sopra il partizionamento, ma ZORDER è sia costoso che ancora più complicato da gestire.
Liquid Clustering semplifica notevolmente le decisioni relative al layout dei dati e offre la flessibilità di ridefinire le chiavi di clustering senza riscrivere i dati. I clienti devono solo scegliere le chiavi di clustering basandosi esclusivamente sui pattern di accesso alle query, senza doversi preoccupare della cardinalità, dell'ordine delle chiavi, delle dimensioni dei file, del potenziale skew dei dati, della concorrenza e delle future modifiche ai pattern di accesso. Abbiamo lavorato con migliaia di clienti che hanno beneficiato di migliori prestazioni delle query con Liquid Clustering, e ora abbiamo oltre 3000 clienti attivi mensilmente che scrivono oltre 200 PB di dati su tabelle con clustering Liquid al mese.
Tuttavia, anche con i progressi di Liquid Clustering, devi ancora scegliere le colonne su cui raggruppare in base a come interroghi la tua tabella. I team di dati devono capire:
- Quali tabelle beneficeranno di Liquid Clustering?
- Quali sono le migliori colonne di clustering per questa tabella?
- Cosa succede se i miei pattern di query cambiano man mano che le esigenze aziendali evolvono?
Inoltre, all'interno di un'organizzazione, gli ingegneri dei dati devono spesso collaborare con più consumatori downstream per capire come vengono interrogate le tabelle, tenendo al contempo il passo con i pattern di accesso in evoluzione e gli schemi in evoluzione. Questa sfida diventa esponenzialmente più complessa man mano che il volume dei tuoi dati scala con maggiori esigenze di analisi.
Come Automatic Liquid Clustering evolve il tuo Data Layout
Con Automatic Liquid Clustering, Databricks si occupa di tutte le decisioni relative al layout dei dati per te – dalla creazione della tabella, al clustering dei tuoi dati e all'evoluzione del tuo layout dei dati – permettendoti di concentrarti sull'estrazione di insight dai tuoi dati.
Vediamo Automatic Liquid Clustering in azione con una tabella di esempio.
Considera una tabella example_tbl, che viene interrogata frequentemente per data e ID cliente. Contiene dati dal 5-6 febbraio e ID cliente da A a F. Senza alcuna configurazione del layout dei dati, i dati vengono archiviati nell'ordine di inserimento, risultando nel seguente layout:
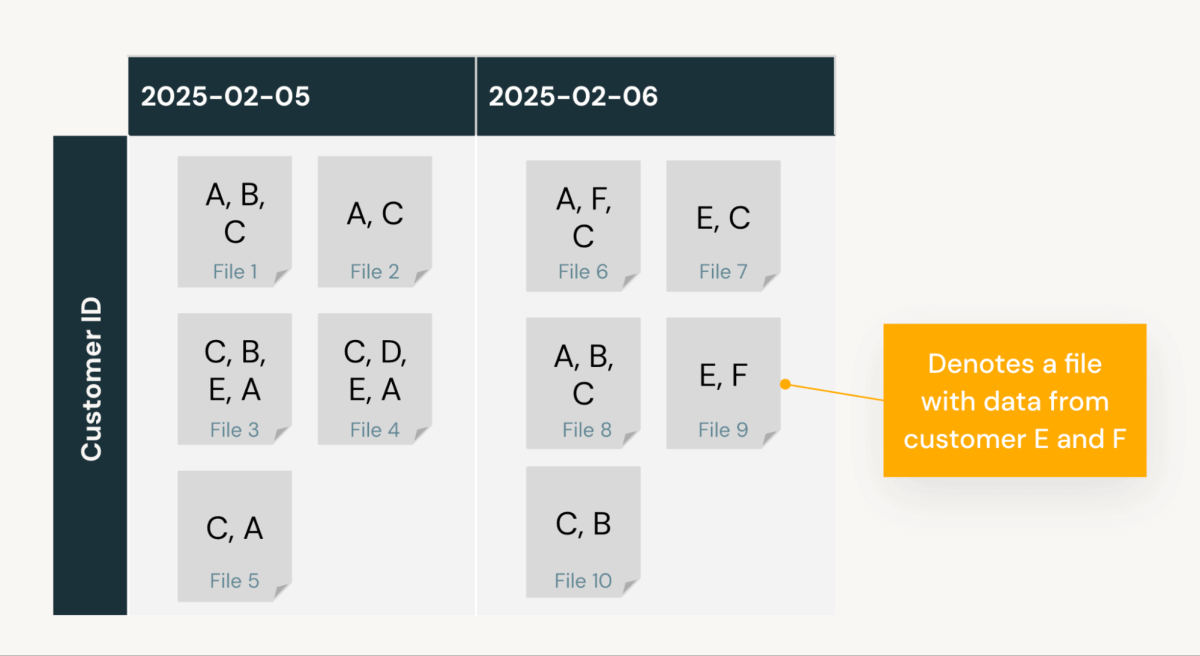
Supponiamo che il cliente esegua SELECT * FROM example_tbl WHERE date = '2025-02-05' AND customer_id = 'B'. Il motore di query sfrutta le statistiche di data skipping di Delta (valori min/max, conteggi null, record totali per file) per identificare i file pertinenti da scansionare. La potatura delle letture di file non necessarie è cruciale, poiché riduce il numero di file scansionati durante l'esecuzione della query, migliorando direttamente le prestazioni della query e riducendo i costi di calcolo. Meno file una query deve leggere, più veloce ed efficiente diventa.
In questo caso, il motore identifica 5 file per il 5 febbraio, poiché metà dei file ha un valore min/max per la colonna data che corrisponde a quella data. Tuttavia, poiché le statistiche di data skipping forniscono solo valori min/max, questi 5 file hanno tutti un customer_id min/max che suggerisce che il cliente B si trova da qualche parte nel mezzo. Di conseguenza, la query deve scansionare tutti e 5 i file per estrarre le voci per il cliente B, portando a un tasso di potatura dei file del 50% (lettura di 5 file su 10).

Come vedi, il problema principale è che i dati del cliente B non sono co-locati in un unico file. Ciò significa che l'estrazione di tutte le voci per il cliente B richiede anche la lettura di una quantità significativa di voci per altri clienti.
Esiste un modo per migliorare la potatura dei file e le prestazioni delle query qui? Automatic Liquid Clustering può migliorare entrambi. Ecco come:
Dietro le quinte di Automatic Liquid Clustering: Come funziona
Una volta abilitato, Automatic Liquid Clustering esegue continuamente i seguenti tre passaggi:
- Raccolta di telemetria per determinare se la tabella beneficerà dell'introduzione o dell'evoluzione delle chiavi di Liquid Clustering.
- Modellazione del carico di lavoro per comprendere e identificare le colonne idonee.
- Applicazione della selezione delle colonne ed evoluzione degli schemi di clustering basata su analisi costi-benefici.

Passaggio 1: Analisi della telemetria
Predictive Optimization raccoglie e analizza le statistiche di scansione delle query, come predicati di query e filtri JOIN, per determinare se una tabella beneficerà di Liquid Clustering.
Con il nostro esempio, Predictive Optimization rileva che le colonne 'date' e 'customer_id' vengono interrogate frequentemente.
Passaggio 2: Modellazione del carico di lavoro
Predictive Optimization valuta il carico di lavoro delle query e identifica le migliori chiavi di clustering per massimizzare il data skipping.
Apprende dai pattern di query passati e stima i potenziali guadagni di prestazioni di diversi schemi di clustering. Simulando query passate, prevede quanto efficacemente ogni opzione ridurrebbe la quantità di dati scansionati.
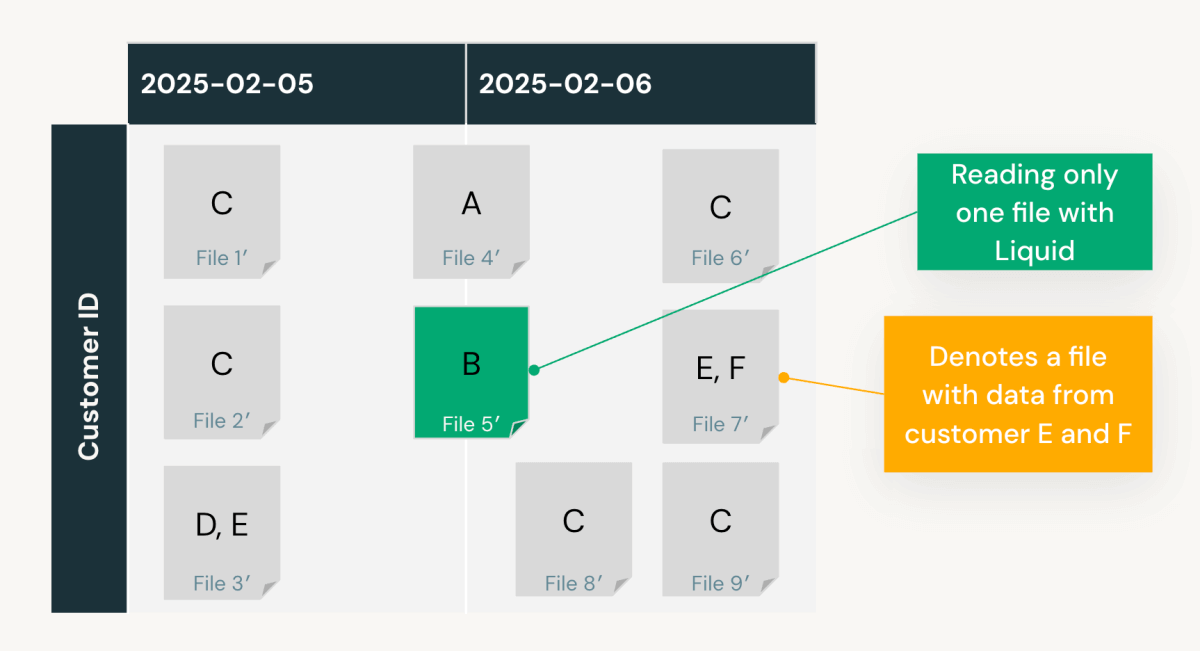
Nel nostro esempio, utilizzando le scansioni registrate su ‘date’ e ‘customer_id’ e assumendo query coerenti, Predictive Optimization calcola che:
- Il clustering per
‘date’legge 5 file con tassi di pruning del 50%. - Il clustering per
‘customer_id’, legge circa 2 file (una stima) con un tasso di pruning dell'80%.- Il clustering per entrambi
‘date’e‘customer_id’(vedere il layout dei dati di seguito) legge solo 1 file con un tasso di pruning del 90%.
- Il clustering per entrambi

Passaggio 3: Ottimizzazione Costi-Benefici
La Piattaforma Databricks garantisce che qualsiasi modifica alle chiavi di clustering fornisca un chiaro beneficio in termini di prestazioni, poiché il clustering può introdurre un overhead aggiuntivo. Una volta identificate le nuove candidate per le chiavi di clustering, Predictive Optimization valuta se i guadagni di prestazioni superano i costi. Se i benefici sono significativi, aggiorna le chiavi di clustering sulle tabelle gestite da Unity Catalog.
Nel nostro esempio, il clustering per ‘date’ e ‘customer_id’ si traduce in un tasso di pruning dei dati del 90%. Poiché queste colonne vengono interrogate frequentemente, i ridotti costi di calcolo e le migliori prestazioni delle query giustificano l'overhead del clustering.
I clienti in anteprima hanno evidenziato l'efficacia in termini di costi di Predictive Optimization, in particolare il suo basso overhead rispetto alla progettazione manuale dei layout dei dati. Aziende come CFC Underwriting hanno segnalato un costo totale di proprietà inferiore e significativi guadagni di efficienza.
“Ci piace molto l'Automatic Liquid Clustering di Databricks perché ci dà la tranquillità di avere il layout dei dati più ottimizzato out-of-the-box. Ci ha anche fatto risparmiare molto tempo eliminando la necessità di un ingegnere per mantenere il layout dei dati. Grazie a questa funzionalità, abbiamo notato che i nostri costi di calcolo sono diminuiti anche mentre abbiamo aumentato il volume dei nostri dati.” —Nikos Balanis, Head of Data Platform, CFC
La funzionalità in sintesi: Predictive Optimization sceglie le chiavi di liquid clustering per tuo conto, in modo che i risparmi di costo previsti dallo skipping dei dati superino il costo previsto del clustering.
Inizia Oggi
Se non hai ancora abilitato Predictive Optimization, puoi farlo selezionando Abilitato accanto a Predictive Optimization nella console dell'account sotto Impostazioni > Abilitazione funzionalità.

Novità in Databricks? Dal 11 novembre 2024, Databricks ha abilitato Predictive Optimization per impostazione predefinita su tutti i nuovi account Databricks, eseguendo ottimizzazioni per tutte le tue tabelle gestite da Unity Catalog.
Inizia oggi impostando CLUSTER BY AUTO sulle tue tabelle gestite da Unity Catalog. È richiesto Databricks Runtime 15.4+ per CREARE nuove tabelle AUTO o ALTERARE tabelle Liquid / non partizionate esistenti. Nel prossimo futuro, Automatic Liquid Clustering sarà abilitato per impostazione predefinita per le tabelle gestite da Unity Catalog appena create. Resta sintonizzato per maggiori dettagli.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.