Presentiamo l'ecosistema di storage Databricks: la governance del patrimonio dati aziendale, ovunque si trovi
Basato su OpenSharing open source, il nostro nuovo ecosistema di partner di storage porta Databricks Data Intelligence Platform direttamente sulla tua infrastruttura on-premises e ibrida, senza copiare un singolo byte.
di Rupal Jain e Denis Dubeau
- La sfida: Le organizzazioni devono conservare enormi quantità di dati on-premises, in cloud privati e in ambienti edge per soddisfare rigidi requisiti normativi e di sovranità dei dati, mantenere una bassa latenza all'edge o gestire un'immensa gravità dei dati, il tutto portando al contempo l'AI cloud moderna e la governance in tali ambienti.
- Di cosa si tratta: Il Databricks Storage Ecosystem collega in modo nativo le piattaforme di storage ibride e on-premises a Databricks utilizzando il protocollo OpenSharing. Ciò consente alle organizzazioni di stabilire una governance dei dati centralizzata e di scalare la GenAI su tutta la loro infrastruttura ibrida.
- Il risultato: Utilizzando un'architettura zero-copy, le aziende possono eseguire Databricks Serverless Compute, Genie e LLM direttamente sui loro dataset on-premises senza copiare un singolo file. Questo trasforma istantaneamente i dati isolati in asset attivi e pronti per l'AI per casi d'uso avanzati, come l'addestramento di modelli su dati ingegneristici riservati o l'analisi della telemetria di rete in loco.
I dati che non si possono spostare
Per anni, la strategia dei dati aziendali è stata semplice: spostare tutto sul cloud. Migrare i data lake e i data warehouse sul cloud, e la governance sarebbe seguita di conseguenza. Era una storia lineare, finché non ha smesso di esserlo.
Oggi, alcune delle aziende più sofisticate al mondo ci dicono chiaramente: non possono — e non vogliono — spostare tutti i loro dati sul cloud. I principali produttori di semiconduttori stanno addestrando modelli su dataset di progettazione riservati che non devono mai lasciare le loro sedi. Le società di trading globali dispongono di enormi volumi di dati storici sui tick, per i quali i costi di egress dal cloud rendono impossibile la migrazione. Le banche di livello Tier-1 hanno adottato strategie "Hybrid Forever", modernizzando lo storage on-premises e mantenendo al contempo una rigorosa sovranità dei dati. Le principali aziende farmaceutiche eseguono ogni giorno milioni di esperimenti sui farmaci su patrimoni di dati on-premises su scala petabyte, soggetti a severi controlli normativi.
Questi non sono casi isolati. Rappresentano un cambiamento strutturale nel modo in cui le aziende concepiscono i dati: da "Migra tutto" a "Governa tutto".
I fattori trainanti sono reali e cumulativi:
- Sovranità dei dati e normative: i servizi finanziari, il settore sanitario e le organizzazioni governative operano nel rispetto di mandati — GDPR, HIPAA, NIS2, regole di residenza dei dati specifiche per settore — che richiedono che i dati rimangano all'interno di giurisdizioni specifiche o in ambienti isolati (air-gapped). La migrazione al cloud non è facoltativa; per determinati dataset è vietata per legge.
- Gravità dei dati e costi: su scala petabyte ed exabyte, la convenienza economica della migrazione al cloud viene meno del tutto. I costi di egress, le spese di storage e l'enorme volume di dati rendono il modello "sposta tutto una volta sola" finanziariamente insostenibile. Alcuni dei più grandi rivenditori al mondo stanno attivamente rimpatriando i carichi di lavoro analitici dal cloud alle infrastrutture on-premises proprio per questo motivo.
- Latenza e carichi di lavoro edge: i carichi di lavoro del settore retail, manifatturiero e delle telecomunicazioni richiedono un accesso a bassa latenza ai dati on-premises ed edge. I provider di telecomunicazioni acquisiscono quotidianamente enormi volumi di telemetria di rete on-premises per alimentare operazioni di rete basate sull'AI che non possono tollerare i tempi di trasmissione (round-trip) del cloud.
- AI sui dark data: vasti archivi di dati di backup, archivi non strutturati e dataset secondari — che rappresentano centinaia di exabyte in tutta l'azienda — contengono un immenso valore per l'AI che non è mai stato sbloccato perché la governance non lo ha mai raggiunto.
Il segnale è inequivocabile. Abbiamo ricevuto richieste da centinaia di clienti che chiedono esplicitamente la connettività di storage on-premises e ibrido a Unity Catalog. Il mercato del Software-Defined Storage (SDS) varrà centinaia di miliardi di dollari nel 2026, e i partner aziendali che gestiscono questo patrimonio — che detengono collettivamente più di 2 zettabyte di dati in gestione — stanno costruendo insieme a noi.
Presentazione dell'ecosistema di storage Databricks
Oggi siamo entusiasti di annunciare il Databricks Software-Defined Storage (SDS) Ecosystem — una nuova categoria di partner creata appositamente per portare la Databricks Intelligence Platform sui dati aziendali, ovunque essi risiedano: on-premises, nei cloud privati e negli ambienti edge. Se oggi sei un'azienda che gestisce petabyte di dati su queste piattaforme, non devi più scegliere tra la tua infrastruttura di storage non cloud esistente e Databricks AI.
Per troppo tempo le aziende hanno dovuto scegliere tra l'infrastruttura di storage on-premises su cui fanno affidamento e l'AI cloud-native che desiderano creare. Costringere i clienti a migrare enormi quantità di dati utilizzando pipeline complesse solo per sbloccare quell'intelligenza è un modello superato. Unendo questi partner leader del settore, poniamo fine a questo compromesso e portiamo l'intelligenza di Databricks direttamente dove risiedono i dati aziendali. Ma questo lancio è solo il primo giorno. Stiamo gettando le basi per garantire che presto ogni dato ibrido, strutturato o non strutturato, sia immediatamente pronto per l'AI generativa senza dover mai copiare un singolo byte. —Stephen Orban, SVP, Product Partnerships & Ecosystem, Databricks
Al centro di questo ecosistema c'è OpenSharing, un protocollo open-source per la condivisione sicura e controllata dei dati. I nostri partner di storage stanno implementando server OpenSharing per esporre i propri patrimoni di dati direttamente a Databricks Serverless Compute. Il percorso è semplice: il partner di storage attiva un endpoint OpenSharing, tu lo connetti a Unity Catalog e ottieni istantaneamente un accesso sicuro e controllato ai tuoi dati on-premises in Databricks senza alcuna migrazione dei dati.
Questa integrazione fornisce un unico catalogo unificato per l'intero ambiente ibrido. I clienti possono ora utilizzare Databricks Serverless Compute, Genie, AgentBricks e l'addestramento dei modelli per interrogare ed elaborare dati che non lasciano mai la sede locale. Il risultato? Zero spostamenti di dati, nessuna duplicazione dei dati e zero rischi di conformità.
Questa non è un'aspirazione futura. I clienti possono provare queste integrazioni già oggi. I partner che sviluppano queste integrazioni seguono il Partner Well-Architected Framework — un progetto tecnico che copre i criteri di architettura, sicurezza e certificazione.
I clienti desiderano abbattere i silos di dati e unificare l'intero patrimonio di dati e AI, compresa la grande quantità di dati che risiede ancora on-premises. Grazie ai partner di storage on-premises che sfruttano il protocollo open-source Open Sharing, i clienti possono ora unificare, governare e analizzare senza problemi tutto il loro patrimonio di dati in Databricks Unity Catalog, sbloccando l'intero valore dei loro dati nella Databricks Data Intelligence Platform. —Jonathan Keller, VP, Product Management, Databricks
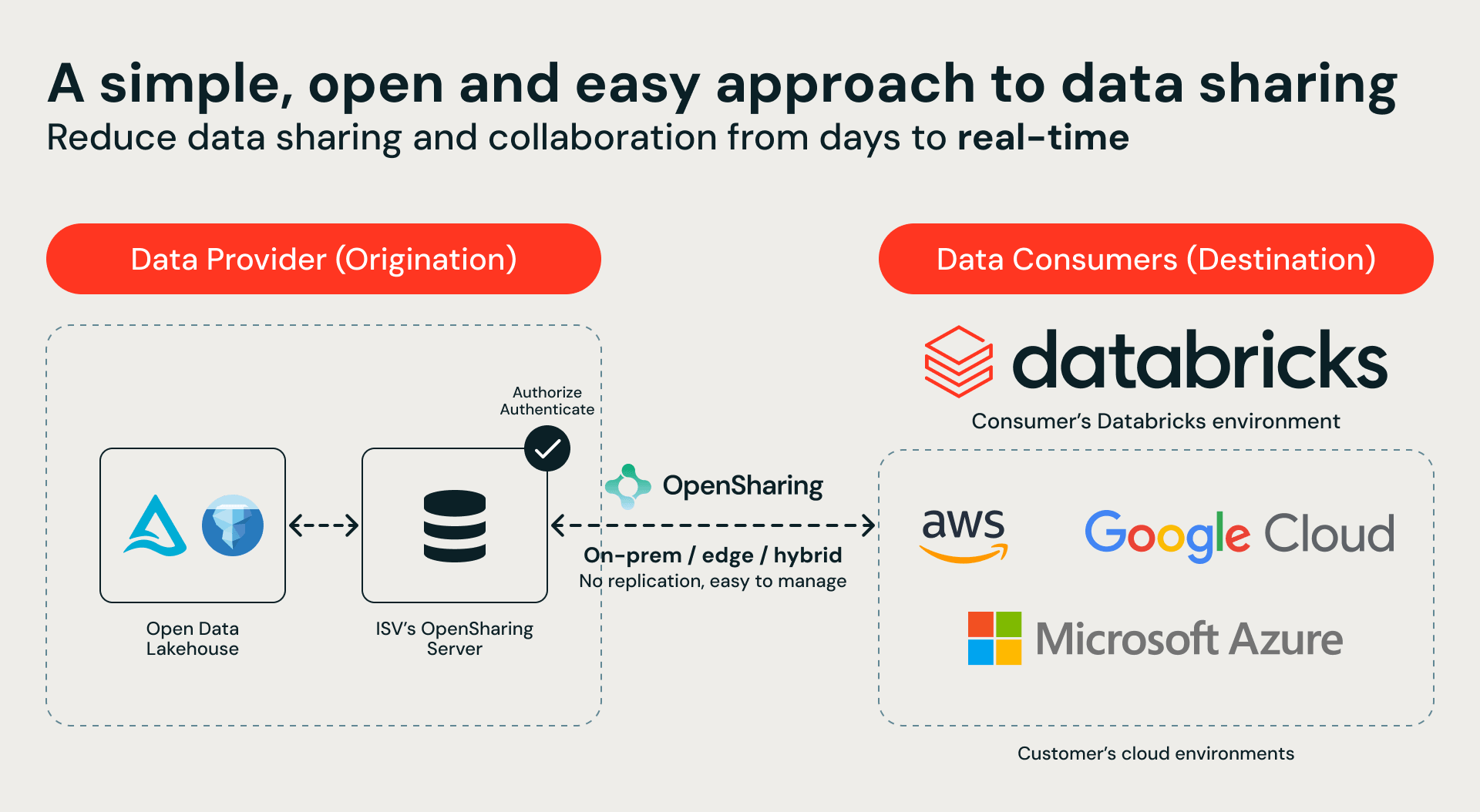
I nostri partner di lancio
Siamo orgogliosi di annunciare le integrazioni con i seguenti provider di storage leader del settore:

MinIO — Disponibilità generale (demo, blog)
MinIO AIStor è il ponte che collega perfettamente la Databricks Data Intelligence Platform con i dati aziendali che non possono essere spostati sul cloud. Implementando in modo nativo il protocollo aperto Open Sharing a livello di storage, AIStor elimina la complessità e consente ai clienti Databricks di interrogare in modo efficiente le tabelle live on-premises Apache Iceberg™️ e Delta sotto la completa governance di Unity Catalog. Estende Serverless Compute, Genie e Agent Bricks ai dati on-premises, portando tutta la potenza della Databricks Platform sui dati più critici di un'azienda.
Le iniziative di AI e analytics sono spesso limitate dal luogo in cui risiedono i dati, in particolare in ambienti con severi requisiti di sicurezza, sovranità o operativi. Portando OpenSharing nativo su AIStor, consentiamo alle organizzazioni di esporre in modo sicuro i dati dove risiedono, offrendo al contempo a Databricks un accesso continuo tramite standard aperti. Ciò rimuove un ostacolo importante tra i dati aziendali e l'AI, consentendo alle organizzazioni di attivare dati precedentemente inaccessibili per l'AI, l'analytics e le applicazioni agentiche senza compromettere il controllo. —Ugur Tigli, Chief Technology Officer, MinIO
Everpure (in precedenza Pure Storage) — Private Preview (demo, blog)
Everpure e Databricks consentono alle organizzazioni di utilizzare i dati on-premises direttamente nel cloud, eliminando la necessità di replicare o duplicare i dati. Ciò viene offerto tramite un connettore OpenSharing che collega i dati nell'object storage con i workspace principali di Databricks in modo sicuro e controllato.
Everpure e Databricks consentono alle organizzazioni di accedere e analizzare i dati on-premises direttamente dal cloud, senza la necessità di replicarli o duplicarli. Spostare continuamente i dati tra ambienti diversi è costoso e insostenibile su scala. I clienti cercano un approccio più semplice che bilanci costi, conformità e sovranità dei dati, riducendo al contempo la complessità operativa. —Chadd Kenney, VP of Product Management, Everpure
Qumulo — Private Preview a luglio 2026 (blog)
Qumulo ha integrato OpenSharing con il suo nuovo NeuralSearch, consentendo ai clienti di condividere in modo sicuro i dati archiviati su Qumulo con Databricks in ambienti core, cloud ed edge, senza replicazione, costi aggiuntivi o complessità. Utilizzando NeuralSearch, gli utenti possono scoprire dataset rilevanti, inclusi i contenuti non strutturati, tramite query in linguaggio naturale e condividere in modo fluido queste tabelle curate con Databricks tramite OpenSharing.
Le organizzazioni non possono più permettersi i costi, la complessità e i ritardi legati alla copia di enormi dataset tra ambienti diversi solo per supportare l'AI e l'analytics. Combinando Qumulo NeuralSearch con Databricks OpenSharing, i clienti possono scoprire, governare e condividere in modo sicuro sia dati tabulari che non strutturati tra data center core, sedi edge e cloud pubblici, in tempo reale e senza spostare i dati stessi. Insieme, aiutiamo le organizzazioni ad accelerare le iniziative di AI, unificare la governance e ottenere più rapidamente insight da dati distribuiti a livello globale, mantenendo al contempo un'unica fonte di verità. —Brandon Whitelaw, SVP and Head of Product di Qumulo
VAST Data — Private Preview ad agosto 2026
VAST Data sta estendendo il VAST AI Operating System con il supporto a OpenSharing per aiutare le aziende a connettere i workflow di Databricks con i dati residenti su infrastrutture on-premise e ibride, senza richiedere migrazioni o spostamenti massivi di dati. L'integrazione offrirà ai clienti una maggiore flessibilità per accedere, elaborare e rendere operativi i dati in ambienti cloud, data center e infrastrutture AI emergenti, supportando al contempo moderni carichi di lavoro di AI e analytics ibridi.
L'infrastruttura AI sta diventando fondamentalmente ibrida. I clienti desiderano sempre più la possibilità di elaborare i dati ovunque sia più conveniente dal punto di vista economico e operativo, pur mantenendo un accesso fluido tra i vari ambienti. Il supporto a OpenSharing estende la capacità del VAST AI Operating System di connettere i workflow di Databricks con i dati residenti su infrastrutture cloud e on-premise per moderne applicazioni di AI e analytics. A differenza delle piattaforme di storage tradizionali, VAST combina servizi dati, elaborazione distribuita e orchestrazione dell'infrastruttura AI in un sistema operativo unificato per i dati AI su scala. —John Mao, Vice President, Global Technology Alliances di VAST Data
I prossimi passi
Integrazioni in arrivo
Oltre ai nostri partner di lancio, la crescita dell'ecosistema di storage continua ad accelerare. Abbiamo ottenuto l'impegno di Cohesity, Commvault, HPE, NetApp, Nutanix e Rubrik per realizzare integrazioni native entro la fine dell'anno.
Insieme, questi partner, insieme a quelli di lancio, gestiscono centinaia di exabyte di dati aziendali, che spaziano da media non strutturati ad alte prestazioni, archivi di backup secondari, storage cloud conveniente e infrastrutture di cloud privato iperconvergente.
Sbloccare i dati non strutturati
Il lancio di oggi rende i dati strutturati e tabulari completamente governati e accessibili in tutto questo ecosistema. Sappiamo però che le opportunità più entusiasmanti risiedono nei dati non strutturati: immagini, PDF, video, scansioni mediche, simulazioni ingegneristiche e archivi di backup che rappresentano la maggior parte dei dati aziendali gestiti, nonché la materia prima per la prossima generazione di pipeline RAG e modelli ottimizzati.
Stiamo lavorando attivamente per estendere il protocollo OpenSharing con le API Volumes, esponendo i file non strutturati dallo storage on-premise direttamente a Databricks per i carichi di lavoro GenAI. Grazie a questa novità, i partner che gestiscono enormi patrimoni di dati non strutturati — dagli archivi multimediali e di imaging ai repository di backup aziendali — sbloccheranno una classe completamente nuova di casi d'uso AI per i loro clienti.
Questo è ciò che significa governare tutto.
Entra a far parte dell'ecosistema
Se sei un fornitore di storage interessato a creare un'integrazione OpenSharing, visita il Partner Well Architected Framework o contatta il team Databricks Partner per iniziare.
Se sei un cliente aziendale che desidera connettere il proprio parco storage on-premise a Databricks, contatta il tuo account team per saperne di più.
L'era del "Migra tutto" è finita. L'era del "Governa tutto" inizia oggi.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.