Annuncio della disponibilità generale della modalità in tempo reale per Apache Spark Structured Streaming su Databricks
Alimenta i tuoi carichi di lavoro più critici in termini di tempo, dal rilevamento delle frodi alla personalizzazione, con una latenza inferiore al secondo
- Latenza inferiore al secondo su Spark: la modalità Real-Time (RTM) in Apache Spark Structured Streaming è ora disponibile a livello generale, offrendo prestazioni end-to-end in millisecondi alle familiari API Spark ed eliminando la necessità di un altro motore specializzato, come Apache Flink.
- Innovazione architetturale: RTM raggiunge velocità di elaborazione inferiori a 100 ms attraverso tre innovazioni: flusso continuo di dati, pianificazione della pipeline e shuffle in streaming.
- Provato su larga scala: leader del settore come Coinbase, DraftKings e MakeMyTrip stanno utilizzando RTM per alimentare casi d'uso operativi mission-critical, con alcuni che ottengono una riduzione della latenza superiore all'80%.
Per anni, Apache Spark Structured Streaming ha gestito alcuni dei carichi di lavoro di streaming più esigenti al mondo. Tuttavia, per i casi d'uso a latenza ultra-bassa, i team dovevano mantenere motori separati e specializzati — più comunemente Apache Flink, oltre a Spark, duplicando codebase, modelli di governance e overhead operativo. Ora, Databricks rimuove questo onere per i clienti.
Oggi, siamo entusiasti di annunciare la Disponibilità Generale della Modalità Real-Time (RTM) in Spark Structured Streaming, portando la latenza a livello di millisecondi alle API Spark che già utilizzi. Che si tratti di rilevare frodi in tempo reale o di generare contesto fresco e in tempo reale per guidare i tuoi agenti AI, ora puoi usare Spark per gestire tutti questi casi d'uso.
Gestione di clienti e casi d'uso leader del settore
RTM è già stata adottata da team di organizzazioni leader del settore nei servizi finanziari, e-commerce, media e ad tech per gestire il rilevamento di frodi, la personalizzazione live, il calcolo di feature per ML e l'attribuzione pubblicitaria.
Coinbase, uno dei principali exchange di criptovalute al mondo, utilizza RTM per scalare i propri motori di gestione del rischio e rilevamento frodi ad alta frequenza — elaborando volumi massicci di eventi blockchain e di exchange con la latenza sub-100ms necessaria per proteggere milioni di transazioni di asset digitali.
Sfruttando la Modalità Real-Time in Spark Structured Streaming, abbiamo ottenuto una riduzione superiore all'80% delle latenze end-to-end, raggiungendo P99 sub-100ms e ottimizzando la nostra strategia di ML in tempo reale su larga scala. Questa performance ci consente di calcolare oltre 250 feature ML, tutte gestite da un unico motore Spark.”—Daniel Zhou, Senior Staff Machine Learning Platform Engineer, Coinbase
DraftKings, una delle più grandi piattaforme di sportsbook e fantasy sports del Nord America, utilizza la modalità real-time per gestire il calcolo delle feature per i propri modelli di rilevamento frodi — elaborando stream di eventi di scommesse ad alto throughput con la latenza e l'affidabilità richieste per decisioni di scommesse con denaro reale.
Nelle scommesse sportive live, il rilevamento delle frodi richiede una velocità estrema. L'introduzione della Modalità Real-Time insieme all'API transformWithState in Spark Structured Streaming è stata una svolta per noi. Abbiamo ottenuto miglioramenti sostanziali sia nella latenza che nella progettazione delle pipeline, e per la prima volta, abbiamo creato pipeline di feature unificate per l'addestramento ML e l'inferenza online, raggiungendo latenze ultra-basse che prima semplicemente non erano possibili.”—Maria Marinova, Sr. Lead Software Engineer, DraftKings
MakeMyTrip, una delle principali piattaforme di viaggi online in India per hotel, voli ed esperienze, ha adottato la Modalità Real-Time per gestire esperienze di ricerca personalizzate. RTM ha elaborato ricerche di viaggi ad alto volume per fornire raccomandazioni in tempo reale.
Nella ricerca di viaggi, ogni millisecondo conta. Sfruttando la Modalità Real-Time di Spark (RTM), abbiamo offerto esperienze personalizzate con latenze P50 sub-50ms, generando un aumento del 7% nei tassi di click-through. RTM ha anche trasformato le nostre operazioni sui dati, consentendo un'architettura unificata in cui Spark gestisce tutto, dall'ETL ad alto throughput alle pipeline a latenza ultra-bassa. Mentre ci muoviamo nell'era degli agenti AI, guidarli efficacemente richiede la costruzione di contesto in tempo reale da stream di dati. Stiamo sperimentando con Spark RTM per fornire ai nostri agenti il contesto più ricco e recente necessario per prendere le migliori decisioni possibili. —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
RTM può supportare qualsiasi carico di lavoro che beneficia della trasformazione dei dati in decisioni in millisecondi. Alcuni esempi di casi d'uso includono:
- Esperienze personalizzate nel retail e nei media: Un provider di streaming OTT aggiorna le raccomandazioni dei contenuti immediatamente dopo che un utente ha finito di guardare uno show. Una piattaforma di e-commerce leader ricalcola le offerte di prodotti mentre i clienti navigano — mantenendo alto l'engagement con loop di feedback sub-secondo.
- Monitoraggio IoT: Un'azienda di trasporti e logistica ingesta telemetria live per guidare il rilevamento di anomalie, passando da un processo decisionale reattivo a uno proattivo in millisecondi.
- Rilevamento frodi: Una banca globale elabora transazioni con carte di credito da Kafka in tempo reale e segnala attività sospette, tutto entro 200 millisecondi — riducendo il rischio e il tempo di risposta senza dover riorganizzare la piattaforma.
Cos'è la Modalità Real-Time (RTM)?
RTM è un'evoluzione del motore Spark Structured Streaming che gli consente di raggiungere prestazioni sub-secondo nei benchmark di carichi di lavoro di feature engineering complessi dei clienti.
La modalità microbatch (MBM) predefinita di Structured Streaming è come un bus navetta aeroportuale che aspetta che un certo numero di passeggeri salga prima di partire. D'altra parte, RTM opera come un tapis roulant mobile ad alta velocità, eliminando la limitazione di aspettare che la navetta si riempia. RTM elabora ogni evento non appena arriva, fornendo latenza end-to-end in millisecondi senza uscire dall'ecosistema Spark.
Da secondi a millisecondi: RTM trasforma il motore Spark sostituendo il batching periodico con un flusso di dati continuo, eliminando i colli di bottiglia di latenza dell'ETL tradizionale.
I guadagni di performance di RTM derivano da tre innovazioni architettoniche chiave:
- Flusso di dati continuo: I dati vengono elaborati non appena arrivano invece che in blocchi discreti e periodici.
- Pianificazione pipeline: Gli stage vengono eseguiti contemporaneamente senza blocchi, consentendo ai task downstream di elaborare i dati immediatamente senza aspettare che gli stage upstream finiscano.
- Shuffle in streaming: I dati vengono passati tra i task immediatamente, bypassando i colli di bottiglia di latenza degli shuffle tradizionali basati su disco.
Insieme, trasformano Spark in un motore ad alte prestazioni e a bassa latenza in grado di gestire i casi d'uso operativi più esigenti.
Spark RTM: fino al 92% più veloce di Flink, consente ai team di operare meno infrastrutture e muoversi più velocemente
Per convalidare le prestazioni di Spark RTM, abbiamo confrontato le prestazioni con un motore specializzato popolare, Apache Flink, basato su carichi di lavoro effettivi dei clienti che eseguono il calcolo di feature. Questi pattern di calcolo di feature sono rappresentativi della maggior parte dei casi d'uso ETL a bassa latenza, come il rilevamento frodi, la personalizzazione e l'analisi operativa. Confrontando Spark RTM con Flink, i risultati dimostrano che l'architettura evoluta di Spark fornisce un profilo di latenza comparabile a framework di streaming specializzati. Per maggiori informazioni sui set di dati e sulle query a cui si fa riferimento, consulta questo repository GitHub.
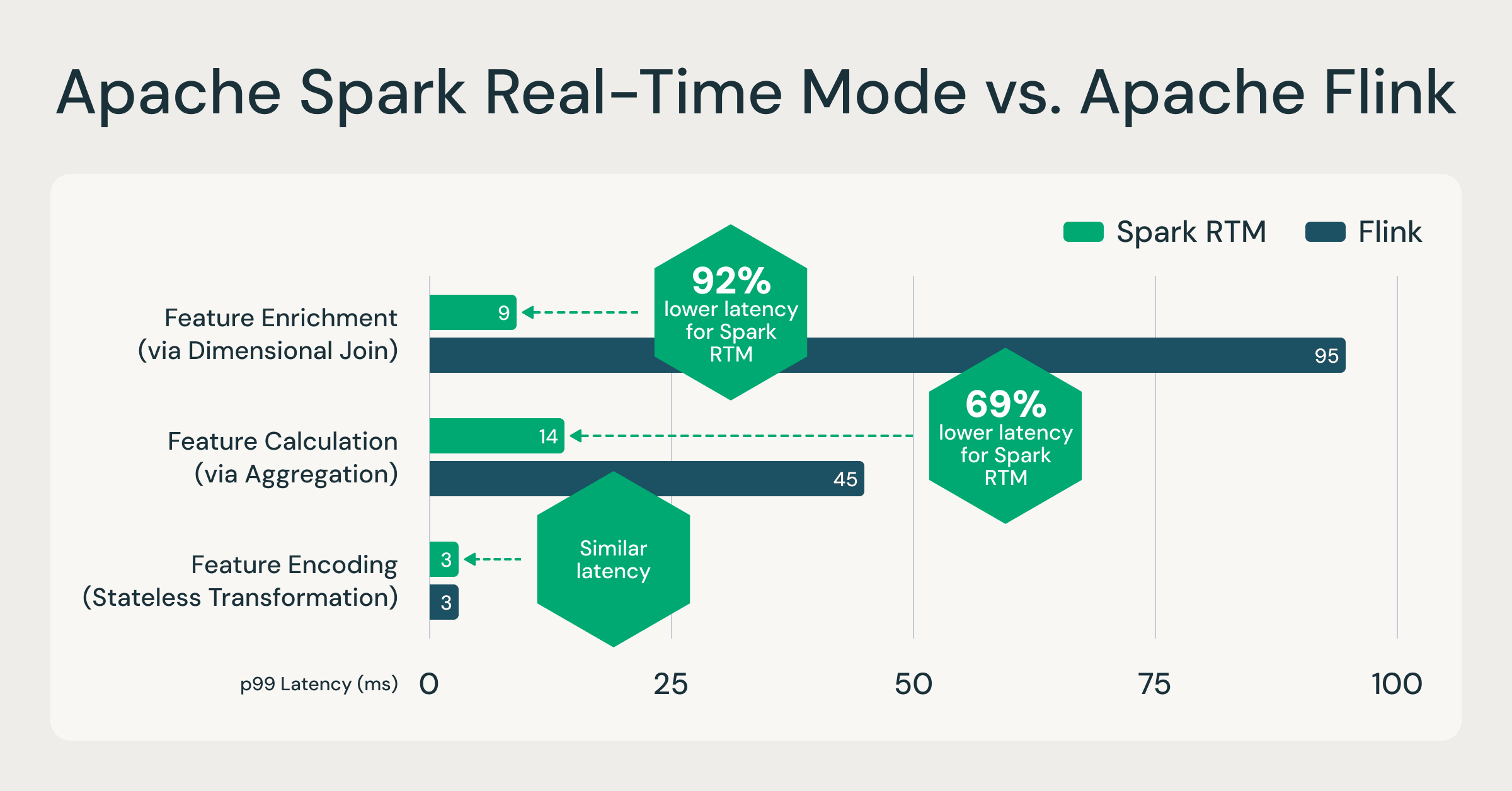
Un motore, fino al 92% più veloce: RTM supera i motori specializzati come Flink, dimostrando che l'analisi operativa a livello di millisecondi non richiede più un motore di streaming separato. Fonte: Benchmark interni basati su pattern di calcolo di feature dei clienti. Query complete disponibili su GitHub.
Mentre la velocità pura conta, il vantaggio più grande di Spark RTM rispetto a motori come Flink è la semplicità che offre ai costruttori. Consente ai team di utilizzare la stessa API Spark sia per l'addestramento batch che per l'inferenza in tempo reale, eliminando efficacemente la "deriva logica" e la duplicazione del codice. Spark RTM consente una scalabilità senza interruzioni, dove una modifica di codice di una sola riga può spostare una pipeline da batch orari a streaming sub-secondo senza ottimizzazioni manuali dell'infrastruttura. In definitiva, riducendo la complessità operativa e la necessità di sistemi specializzati multipli, i team possono sviluppare e distribuire applicazioni in tempo reale in modo significativamente più veloce con Spark RTM.
Iniziare con Spark RTM
Iniziare con RTM è semplice. Se stai già utilizzando Structured Streaming, puoi abilitarlo con un singolo aggiornamento di configurazione — nessuna riscrittura richiesta.
Passaggio 1: Configura il tuo cluster
RTM è attualmente disponibile su compute Classic, sia in modalità di accesso Dedicated che Standard. RTM è supportato su Databricks Runtime (DBR) 16.4 e versioni successive; tuttavia, consigliamo DBR 18.1 per le ultime funzionalità e ottimizzazioni. Durante la creazione del cluster, aggiungi la seguente configurazione Spark:
Passaggio 2: Utilizza il nuovo Real-Time Trigger nella tua query di streaming
Novità di Spark RTM
Dal lancio in Public Preview nell'agosto 2025, Databricks ha continuato ad espandere le capacità di RTM, basandosi sul feedback dei clienti.
Ecco le novità di questa release GA:
- Supporto OSS in Apache Spark 4.1 (trasformazioni stateless): RTM per le trasformazioni stateless è ora disponibile in open-source Apache Spark 4.1. I team che sviluppano su OSS Spark possono sfruttare la modalità real-time per pipeline di proiezione, filtraggio e basate su UDF.
- Supporto per la modalità di accesso standard: RTM ora funziona sia in modalità di accesso dedicata che standard nel compute classico in Python, offrendo ai team maggiore flessibilità nell'utilizzo delle risorse di calcolo per i carichi di lavoro di streaming.
- Checkpointing asincrono dello stato e monitoraggio dei progressi: Il checkpointing dello stato e dei progressi delle query viene ora eseguito in modo asincrono, disaccoppiato dal percorso critico di elaborazione degli eventi. Questo migliora la latenza della modalità real-time per le pipeline stateless e stateful.
- Caricamento dello stato iniziale in transformWithState: transformWithState è un potente operatore di Spark Structured Streaming per la creazione di logiche stateful personalizzate. Gli utenti possono ora caricare lo stato iniziale dal checkpoint di una query preesistente o da una delta table quando utilizzano transformWithState con la modalità Real-Time. Questa funzionalità è fondamentale per l'ingegneria delle feature stateful, consentendo di pre-popolare le query online con il contesto storico senza "partire da zero".
- Metriche e osservabilità migliorate per le UDF: Metriche di latenza più accurate per l'esecuzione di UDF Python esposte tramite il listener StreamingQueryProgress.
- Miglioramenti delle prestazioni per le UDF Stateful Python: Aggiunte ottimizzazioni per migliorare le prestazioni delle operazioni stateful in transformWithState Python, in particolare per le query RTM.
Conclusione
RTM estende Apache Spark Structured Streaming a una nuova classe di carichi di lavoro: applicazioni operative sensibili alla latenza che richiedono una risposta immediata ai dati in streaming. Portando la latenza sub-secondo alle API Spark che il tuo team già utilizza, elimina la necessità di gestire un motore specializzato separato per le tue pipeline più critiche in termini di tempo. Sia che tu stia creando pipeline di rilevamento frodi, motori di personalizzazione o sistemi di calcolo di feature ML, la modalità real-time ti offre la latenza richiesta dalla tua applicazione con la semplicità e l'ampiezza dell'ecosistema Spark.
Risorse Tecniche
Dai un'occhiata alle seguenti risorse per iniziare oggi stesso con RTM:
- Documentazione: Modalità Real-Time in Structured Streaming
- Video on-demand: Introduzione alla Modalità Real-Time
- Blog: Come ottenere il rilevamento frodi in tempo reale: Configurazione di Spark RTM con Databricks Lakebase
- Esempi di codice: Esempi di modalità Real-Time
- Webinar on-demand: Real-Time Mode Technical Deep Dive
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.