Introduzione della modalità in tempo reale in Apache Spark™ Structured Streaming
Elabora eventi in millisecondi utilizzando il nuovo trigger Real-Time di Spark
di Jerry Peng, Siying Dong, Abhay Bothra, Fatih Emekci, Karthikeyan Ramasamy, Navneeth Nair, Indrajit Roy, Matt Jones, Craig Lukasik e Ryan Nienhuis
- Elaborazione in streaming in millisecondi: Spark Structured Streaming introduce la modalità in tempo reale per elaborare i dati in millisecondi, abilitando una nuova classe di applicazioni a bassa latenza.
- Nessuna riscrittura necessaria: i team possono abilitare la modalità in tempo reale con una semplice modifica di configurazione, senza necessità di replatforming o revisioni del codice.
- Ora in anteprima pubblica: disponibile su Databricks con supporto per sorgenti e sink popolari; ideale per il rilevamento di frodi, la personalizzazione live e il serving di feature ML.
Apache Spark™ Structured Streaming ha a lungo alimentato pipeline mission-critical su larga scala, dall'ETL in streaming all'analisi quasi in tempo reale e al machine learning. Ora, stiamo espandendo tale capacità a una classe di carichi di lavoro completamente nuova con la modalità in tempo reale, un nuovo tipo di trigger che elabora gli eventi man mano che arrivano, con latenza nell'ordine dei decine di millisecondi.
A differenza dei trigger micro-batch esistenti, che elaborano i dati secondo una pianificazione fissa (trigger ProcessingTime) o elaborano tutti i dati disponibili prima di arrestarsi (trigger AvailableNow), la modalità in tempo reale elabora continuamente i dati ed emette i risultati non appena sono pronti. Ciò abilita casi d'uso a bassissima latenza come il rilevamento di frodi, la personalizzazione live e il serving di feature di machine learning in tempo reale, il tutto senza modificare il codice esistente o effettuare replatforming.
Questa nuova modalità viene contribuita all'open source Apache Spark ed è ora disponibile in anteprima pubblica su Databricks.
In questo post, tratteremo:
- Cos'è la modalità in tempo reale e come funziona
- I tipi di applicazioni che abilita
- Come puoi iniziare a usarla oggi
Cos'è la modalità in tempo reale?
La modalità in tempo reale offre un'elaborazione continua a bassa latenza in Spark Structured Streaming, con latenze p99 fino a pochi millisecondi. I team possono abilitarla con una singola modifica di configurazione, senza necessità di riscrivere o replatformare, mantenendo le stesse API di Structured Streaming che utilizzano oggi.
Come funziona la modalità in tempo reale
La modalità in tempo reale esegue processi di streaming a lunga esecuzione che pianificano gli stage in modo concorrente. I dati passano tra i task in memoria utilizzando uno shuffle in streaming, che:
- Riduce l'overhead di coordinamento
- Elimina i ritardi di pianificazione fissi della modalità micro-batch
- Offre prestazioni costanti inferiori al secondo
Nei test interni di Databricks, le latenze p99 variavano da pochi millisecondi a circa 300 ms, a seconda della complessità della trasformazione:
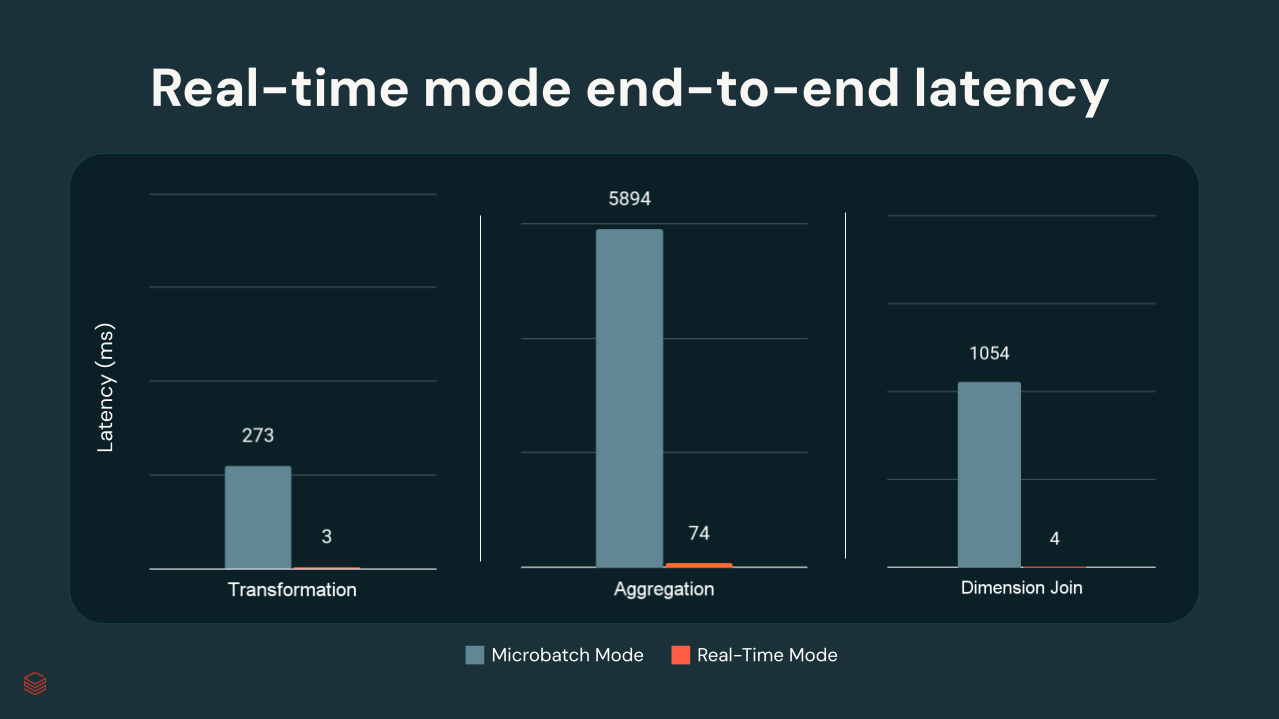
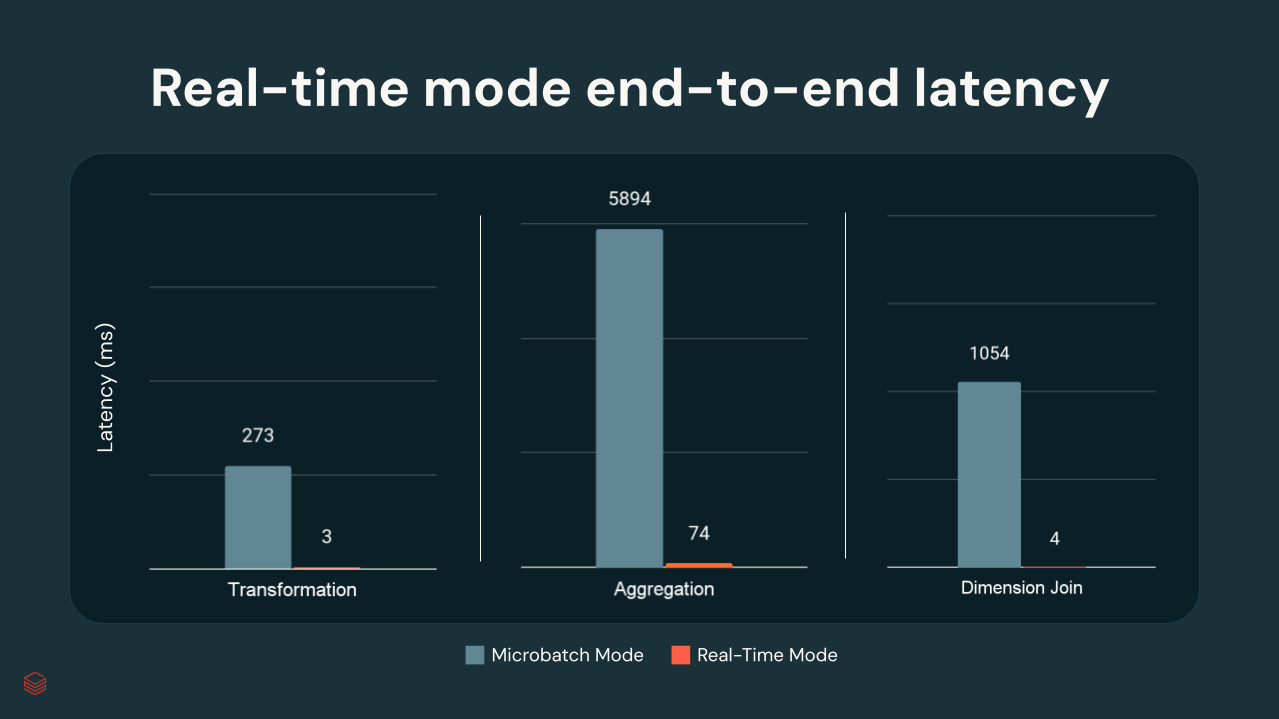{kind=link}
Applicazioni e casi d'uso
La modalità in tempo reale è progettata per applicazioni di streaming che richiedono un'elaborazione a bassissima latenza e tempi di risposta rapidi, spesso nel percorso critico delle operazioni aziendali.
La modalità in tempo reale in Spark Structured Streaming ha prodotto risultati notevoli nei nostri primi test. Per una pipeline di autorizzazione dei pagamenti mission-critical, dove eseguiamo crittografia e altre trasformazioni, abbiamo raggiunto una latenza end-to-end P99 di soli 15 millisecondi. Siamo ottimisti riguardo alla scalabilità di questa elaborazione a bassa latenza attraverso i nostri flussi di dati, rispettando costantemente rigorosi SLA. —Raja Kanchumarthi, Lead Data Engineer, Network International

Oltre al caso d'uso di autorizzazione dei pagamenti di Network International citato sopra, diversi primi utilizzatori l'hanno già utilizzata per alimentare un'ampia gamma di carichi di lavoro:
Rilevamento frodi nei servizi finanziari: Una banca globale elabora transazioni con carta di credito da Kafka in tempo reale e segnala attività sospette, il tutto entro 200 millisecondi, riducendo il rischio e i tempi di risposta senza replatforming.
Esperienze personalizzate nel retail e nei media: Un provider di streaming OTT aggiorna le raccomandazioni sui contenuti immediatamente dopo che un utente ha finito di guardare uno spettacolo. Una piattaforma di e-commerce leader ricalcola le offerte di prodotti mentre i clienti navigano, mantenendo alto l'engagement con loop di feedback inferiori al secondo.
Stato della sessione live e cronologia delle ricerche: Un importante sito di viaggi traccia e visualizza le ricerche recenti di ciascun utente in tempo reale tra i dispositivi. Ogni nuova query aggiorna istantaneamente la cache della sessione, consentendo risultati personalizzati e autocompletamento senza ritardi.
Serving di feature ML in tempo reale: Un'app di consegna di cibo aggiorna le feature come la posizione del conducente e i tempi di preparazione in millisecondi. Questi aggiornamenti fluiscono direttamente nei modelli di machine learning e nelle app rivolte agli utenti, migliorando l'accuratezza delle stime e l'esperienza del cliente.
Questi sono solo alcuni esempi. La modalità in tempo reale può supportare qualsiasi carico di lavoro che beneficia della trasformazione dei dati in decisioni in millisecondi, dagli avvisi dei sensori IoT e la visibilità della catena di approvvigionamento alla telemetria di gioco live e alla personalizzazione in-app.
Iniziare con la modalità in tempo reale
La modalità in tempo reale è ora disponibile in anteprima pubblica su Databricks. Se stai già utilizzando Structured Streaming, puoi abilitarla con una singola configurazione e un aggiornamento del trigger, senza necessità di riscrivere il codice.
Per provarla in DBR 16.4 o versioni successive:
- Crea un cluster (consigliamo la modalità dedicata) su Databricks con accesso all'anteprima pubblica.
Abilita la modalità in tempo reale impostando la seguente configurazione:
Utilizza il nuovo trigger nella tua query:
Checkpointing
L'opzione trigger(RealTimeTrigger.apply(...)) abilita la nuova modalità di esecuzione in tempo reale, consentendoti di ottenere latenze di elaborazione inferiori al secondo. RealTimeTrigger accetta un argomento che specifica la frequenza con cui la query esegue il checkpoint. Ad esempio, trigger(RealTimeTrigger.apply(“x minuti”)) Per impostazione predefinita, l'intervallo di checkpoint è di 5 minuti, il che funziona bene per la maggior parte dei casi d'uso. La riduzione di questo intervallo aumenta la frequenza dei checkpoint, ma può influire sulla latenza. La maggior parte delle sorgenti e dei sink di streaming sono supportati, inclusi Kafka, Kinesis e forEach per la scrittura su sistemi esterni.
Riepilogo
La modalità in tempo reale è ideale per casi d'uso che richiedono la latenza più bassa possibile. Per molti carichi di lavoro analitici, la modalità micro-batch standard potrebbe essere più conveniente pur soddisfacendo i requisiti di latenza. La modalità in tempo reale introduce un leggero overhead di sistema, quindi ne consigliamo l'uso per pipeline sensibili alla latenza come quelle degli esempi sopra. Il supporto per sorgenti e sink aggiuntivi è in espansione e stiamo lavorando attivamente per ampliare la compatibilità e ridurre ulteriormente la latenza.
Per maggiori dettagli, consulta la documentazione sulla modalità in tempo reale per i dettagli completi sull'implementazione, le sorgenti e i sink supportati e gli esempi di query. Troverai tutto ciò che ti serve per abilitare il nuovo trigger e configurare i tuoi carichi di lavoro di streaming.
Per una panoramica più ampia delle novità in Apache Spark, incluso come la modalità in tempo reale si inserisce nell'evoluzione del motore, guarda la keynote di Michael Armbrust su Spark da DAIS 2025. Copre i cambiamenti architetturali dietro il prossimo capitolo di Spark, con la modalità in tempo reale come parte centrale della storia.
Per approfondire l'ingegneria alla base della modalità in tempo reale, guarda la nostra sessione di approfondimento tecnico dei nostri ingegneri, che illustra la progettazione e l'implementazione.
E per vedere come la modalità in tempo reale si inserisce nella strategia di streaming più ampia su Databricks, consulta la Guida completa allo streaming sulla Piattaforma di Intelligenza dei Dati.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.