La modalità in tempo reale di Apache Spark per il gaming: un modo migliore per gestire la sessionizzazione in tempo reale
Crea pipeline di streaming stateful che tracciano milioni di sessioni attive di dispositivi di gioco, producendo heartbeat in tempo reale con latenza inferiore al secondo in Apache Spark
- Scopri come la modalità Real-Time di Apache Spark™ consente la sessionizzazione in tempo reale per milioni di sessioni di dispositivi attivi
- Scopri come i timer di transformWithState alimentano heartbeat proattivi e basati su timer, generando output in base a una pianificazione e indipendentemente dai dati in ingresso
- Vedi come la modalità Real-Time, associata a transformWithState, sostituisce le applicazioni interne personalizzate e i motori di streaming esterni, offrendo una precisione inferiore al secondo sia per l'elaborazione degli input che per l'output basato su timer.
Nel settore del gaming, ogni millisecondo conta. Per guidare la personalizzazione in-game, alimentare i motori di raccomandazione e prendere decisioni dinamiche sulla programmazione dei contenuti, le piattaforme devono elaborare i dati delle sessioni di milioni di giocatori in tutto il mondo con una latenza inferiore al secondo.
Oggi, soddisfare questi requisiti di latenza ultra-bassa non richiede più un'architettura frammentata con più motori. In questo blog esploreremo un'implementazione reale di Apache Spark Real-Time Mode. Sfruttando il nuovo operatore transformWithState per logiche con stato complesse, mostreremo come Spark offra prestazioni end-to-end nell'ordine dei millisecondi. Scopri come il tuo team può accelerare lo sviluppo e creare applicazioni operative mission-critical utilizzando il familiare ecosistema Structured Streaming.
Panoramica del caso d'uso
Dall'inizio alla fine del gioco: perché il tracciamento delle sessioni è importante
Per le piattaforme di gaming, sapere quali dispositivi sono attivi e per quanto tempo non è solo una questione di infrastruttura, ma guida il business. I dati delle sessioni in tempo reale alimentano esperienze in-game personalizzate, motori di raccomandazione, decisioni sulla programmazione dei contenuti e forniscono segnali sullo stato di salute dei dispositivi su milioni di console e PC. I team operativi li utilizzano per applicare il parental control e rilevare pattern di sessione anomali.
Fondamenti degli eventi di sessione
I eventi di sessione provenienti sia da console che da PC fluiscono nei topic Kafka. Ogni evento contiene un ID dispositivo e un ID sessione. L'ID dispositivo identifica la console o il PC; l'ID sessione identifica la sessione di gioco. Può essere attiva solo una sessione per dispositivo alla volta.
La pipeline gestisce quattro scenari:
- Inizio sessione (GameStart): arriva un evento di inizio. La pipeline memorizza l'ID sessione e l'ora di inizio, emette un evento SessionActive e registra un timer del tempo di elaborazione di 30 secondi. Se per quel dispositivo era già attiva un'altra sessione, termina prima quella precedente.
- Heartbeat di sessione (Active): il timer si attiva ogni 30 secondi. La pipeline calcola now - start_time, emette un heartbeat SessionActive con la durata corrente e registra nuovamente il timer.
- Fine sessione (GameEnd): arriva un evento di fine corrispondente alla sessione attiva. La pipeline emette un SessionEnd con la durata finale e cancella lo stato.
- Timeout di sessione (GameSessionTimeout): il timer si attiva e la durata calcolata supera un massimo configurabile. Invece di emettere un heartbeat, la pipeline emette un SessionEnd con un motivo di timeout e pulisce lo stato.
Perché Spark con Real-Time Mode rappresenta una svolta
Spark Structured Streaming in modalità micro-batch può gestire la sessionizzazione con stato, ma quando il caso d'uso richiede una precisione inferiore al secondo sia per l'elaborazione degli input che per l'output basato su timer, il micro-batch non è sufficiente. In passato, questo divario spingeva i team a gestire motori specializzati aggiuntivi o a creare soluzioni personalizzate.
Con Apache Flink: è possibile implementare la gestione dello stato e i timer, ma adottare Flink significa adottare un intero ecosistema parallelo: un cluster separato, uno state backend, un modello di deployment, uno stack di monitoraggio e una codebase, il tutto insieme alla piattaforma Databricks. Il risultato è la frammentazione dell'infrastruttura, la complessità operativa e i costi di gestione e personale per un secondo motore di streaming.
Con soluzioni interne personalizzate: alcuni team creano il proprio servizio di sessionizzazione, ad esempio un sistema di attori basato su Akka in cui ogni dispositivo riceve un attore che gestisce lo stato della sessione, i timer e l'emissione di heartbeat. Questi comportano lo stesso sovraccarico infrastrutturale e operativo di Flink, con una sfida in più: non sono scalabili. Distribuire milioni di attori con stato tra i nodi è qualcosa che devi progettare da solo. Questi sistemi funzionano inizialmente, ma nel tempo finiscono in modalità di manutenzione: abbastanza stabili da funzionare, ma non facilmente estensibili.
Oggi, Real-Time Mode colma questo divario per i clienti, offrendo una precisione inferiore al secondo con le stesse API Spark che i team già utilizzano, il tutto in un unico motore unificato.
Real-Time Mode con transformWithState
transformWithState è un operatore di nuova generazione in Spark Structured Streaming che rende flessibile e scalabile l'elaborazione complessa con stato. Le caratteristiche principali includono la gestione dello stato orientata agli oggetti, tipi di dati compositi, logica basata su timer, supporto automatico TTL e l'evoluzione dello schema. Combinato con Real-Time Mode, offre una precisione inferiore al secondo sia per l'elaborazione degli input che per l'output basato su timer.
Il caso d'uso della sessionizzazione nel gaming richiede due cose:
- Elaborazione reattiva: gestione dell'inizio e della fine delle sessioni man mano che arrivano.
- Output proattivo: generazione pianificata di un heartbeat per ogni sessione attiva, indipendentemente dai dati in arrivo.
transformWithState offre entrambe le funzionalità in una singola classe StatefulProcessor con due metodi dedicati.
handleInputRows() reagisce agli eventi Kafka in arrivo, elaborando l'inizio e la fine delle sessioni e mantenendo lo stato di sessionizzazione man mano che arrivano gli eventi.
handleExpiredTimer() gestisce tutto ciò che accade nel mezzo, attivandosi per produrre output proattivi come heartbeat e timeout, indipendentemente dall'arrivo di nuovi dati.
Come funziona: creazione di una pipeline di sessionizzazione in tempo reale per il gaming
Panoramica dell'architettura della pipeline
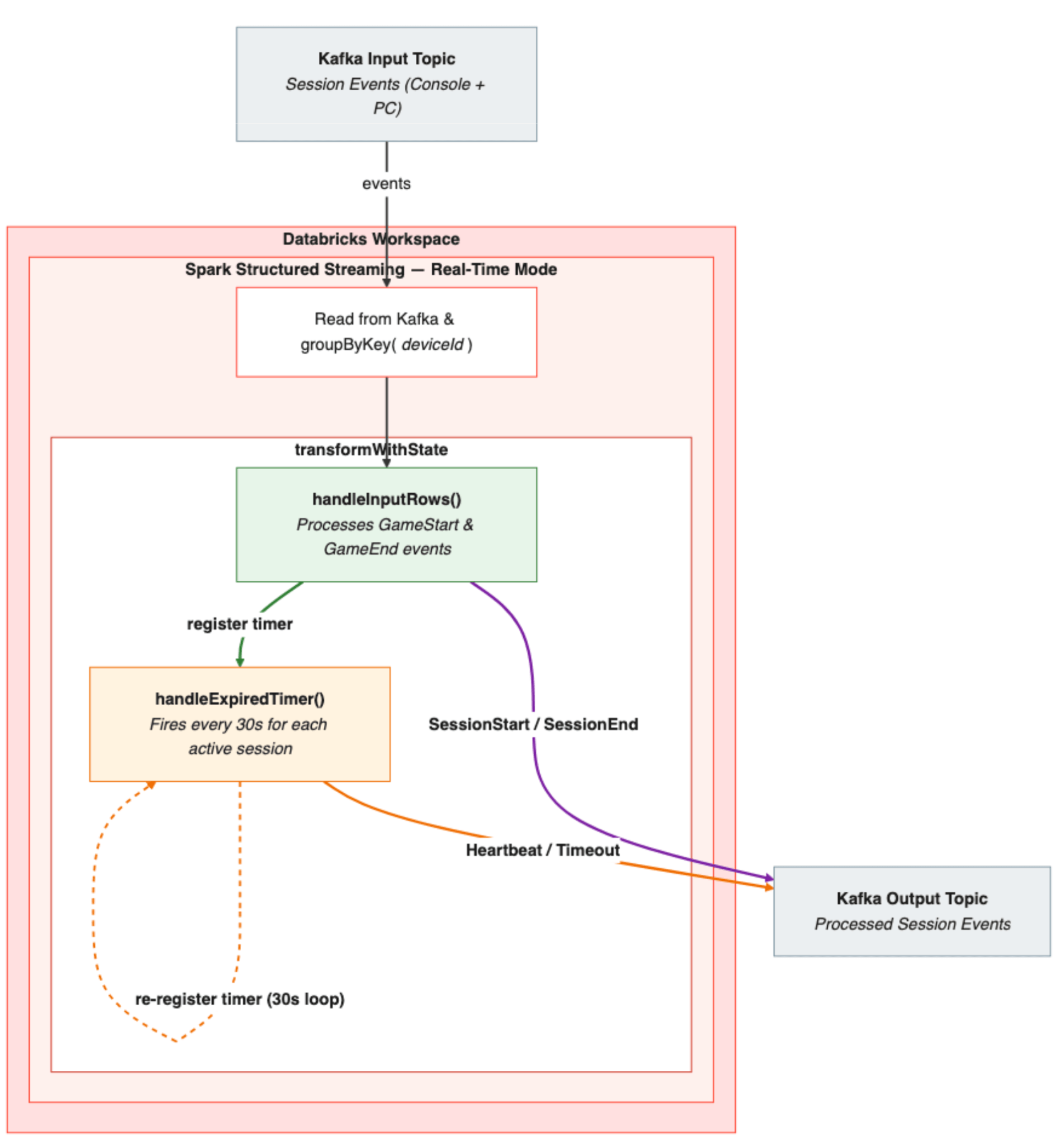
- Ingestione degli eventi: gli eventi di sessione (inizi e fini) da console e PC arrivano sui topic Kafka. Ogni evento viene analizzato e un deviceId viene derivato dall'identificatore specifico del dispositivo.
- Raggruppamento con stato: lo stream viene raggruppato per deviceId, garantendo che tutti gli eventi per un determinato dispositivo siano instradati alla stessa istanza del processore con stato.
- Elaborazione: transformWithState applica il processore di sessionizzazione, che utilizza una MapState con chiave basata sull'ID sessione per tracciare la sessione attiva per dispositivo. Quando arriva un inizio sessione, handleInputRows() memorizza lo stato della sessione, emette un evento SessionActive e registra il primo timer di 30 secondi. Da quel momento in poi, handleExpiredTimer() subentra, emettendo heartbeat ogni 30 secondi e controllando i timeout. Quando arriva un evento di fine sessione, handleInputRows() lo riprende in carico, emettendo un SessionEnd con la durata finale, cancellando lo stato e arrestando il ciclo del timer.
- Output: gli eventi di sessione elaborati (inizi, heartbeat, fini e timeout) vengono scritti come JSON in un topic Kafka di output, pronti per il consumo a valle.
Approfondimento sull'implementazione
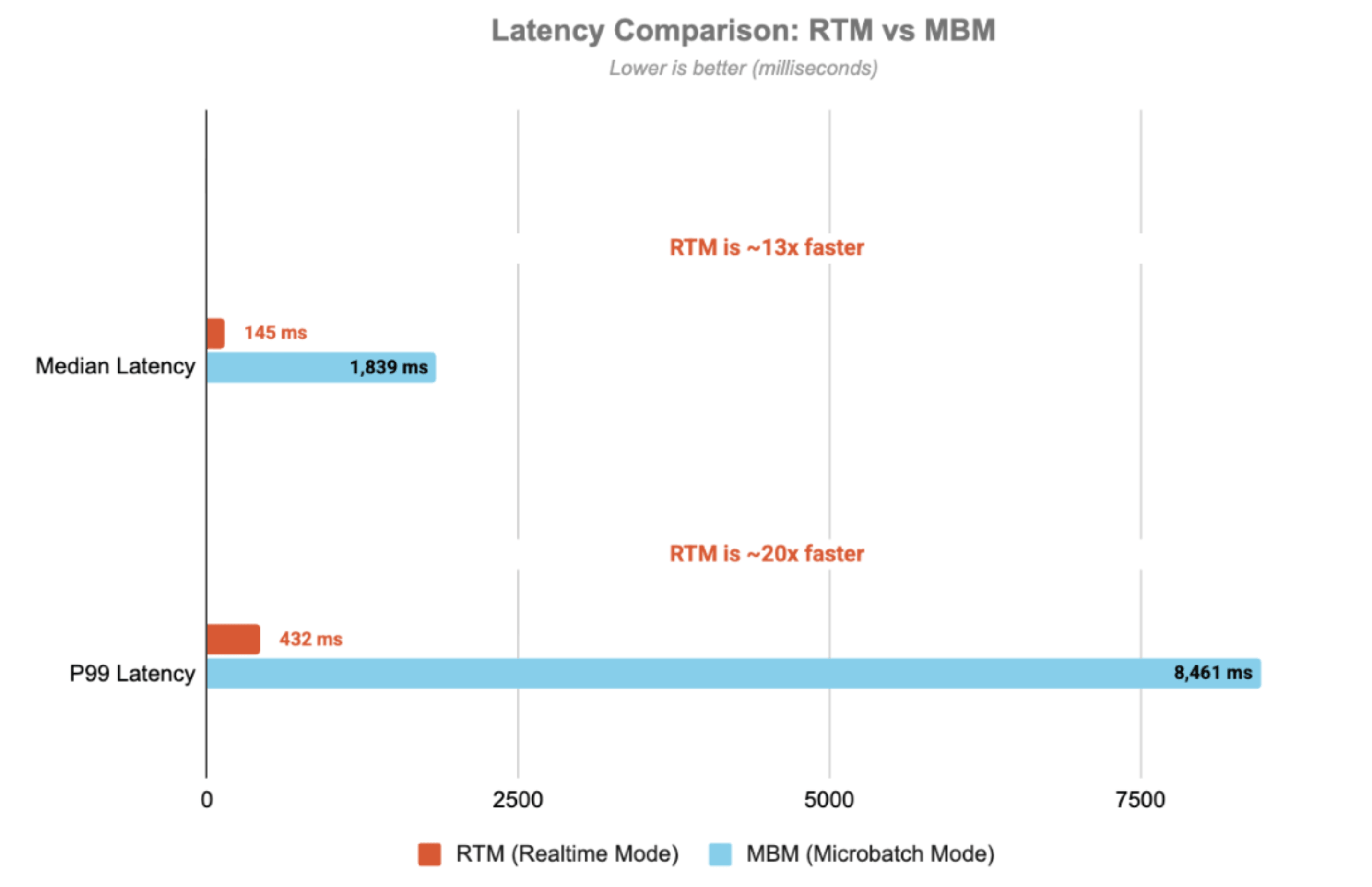
Per una panoramica dettagliata dell'architettura, dell'implementazione del codice e delle considerazioni sulla produzione, consulta questo blog di accompagnamento , in cui esaminiamo il codice StatefulProcessor, il ciclo di vita dei timer, i pattern di gestione dello stato e il monitoraggio con StreamingQueryListener. I seguenti risultati illustrano le caratteristiche di throughput e latenza della pipeline, evidenziando le significative differenze di latenza tra la modalità micro-batch (MBM) e la Real-Time Mode (RTM):
Throughput
Per convalidare la pipeline in condizioni di carico reali, abbiamo effettuato dei test con il seguente throughput sostenuto:
Metrica (al minuto) | Valore |
Eventi di input (inizi + fini sessione) | ~500.000 |
Numero di sessioni attive | ~4 milioni |
Record di heartbeat emessi | ~8 milioni |
Amplificazione input-to-output | ~16x |
La stragrande maggioranza dell'output non è attivata dai dati in arrivo, ma è generata interamente da handleExpiredTimer(), che emette proattivamente heartbeat in modo pianificato.
Latenza
La latenza viene misurata end-to-end, dal timestamp del topic Kafka di input al timestamp del topic di output. Con la Real-Time Mode, la pipeline raggiunge una latenza p99 di 432 ms, ovvero 20 volte più veloce rispetto alla modalità micro-batch.
Conclusione
Casi d'uso come la sessionizzazione dei giochi richiedono pipeline che vanno oltre l'elaborazione degli eventi in arrivo: emettere in modo proattivo heartbeat secondo una pianificazione, tracciare milioni di sessioni simultanee e gestire lo stato in modo efficiente. Questo pattern non è limitato al gaming. Qualsiasi carico di lavoro che necessiti di un output basato su timer (heartbeat IoT, tracciamento delle sessioni, avvisi in tempo reale, monitoraggio delle apparecchiature) può essere creato nello stesso modo.
I timer in transformWithState rendono tutto questo possibile. Una singola classe StatefulProcessor gestisce l'intero ciclo di vita della sessione: elaborazione reattiva degli input e output proattivo basato su timer. In combinazione con la Real-Time Mode, i record di input vengono elaborati e i timer si attivano con una precisione inferiore al secondo, non al successivo intervallo di batch, ma subito. Tutto all'interno di Databricks, senza un secondo motore.
Se utilizzi già pipeline di Structured Streaming in modalità micro-batch e stai cercando un secondo motore per ottenere una latenza inferiore, prova prima la Real-Time Mode. Il passaggio richiede solo la modifica di un singolo trigger: nessuna riscrittura, nessuna migrazione di piattaforma:
Provalo tu stesso:
- Notebook di accompagnamento con generatore di dati: esegui l'intera pipeline di sessionizzazione dei giochi e confronta tu stesso la latenza MBM rispetto a RTM.
- Guida alle API transformWithState: variabili di stato, timer, TTL ed evoluzione dello schema
- Riferimento per la Real-Time Mode: operatori supportati, modalità di esecuzione, sorgenti, sink e supporto linguistico
La Real-Time Mode è ora generalmente disponibile.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.