Dietro le quinte con Lakebase
Ramificare il ciclo di sviluppo (Parte 1)
Per trent'anni, il database operativo e il database analitico sono stati due artefatti, due piani di governance, due budget e, solitamente, due rotazioni on-call, collegati da un processo ETL scritto frettolosamente e che nessuno vuole gestire. Questa separazione non è mai stata una scelta progettuale; era un vincolo fisico. OLTP e OLAP avevano layout di archiviazione, profili di calcolo e modalità di errore genuinamente diversi, quindi abbiamo costruito due piattaforme e le abbiamo collegate in seguito.
Quel vincolo si sta dissolvendo. Quando lo storage è condiviso, il calcolo è serverless e isolato per carico di lavoro, e la governance risiede a livello di catalogo, "operativo" e "analitico" cessano di essere categorie architetturali e diventano pattern di accesso alla stessa base.
Per verificare se ciò fosse effettivamente vero in pratica, abbiamo preso Backstage, il portale per sviluppatori interni di Spotify, notoriamente pesante in termini di stato, lo abbiamo scollegato dal suo database Postgres standard e lo abbiamo puntato a Databricks Lakebase. In questa serie in tre parti, esploreremo cosa succede ai cicli di deployment (Parte 1), alla governance (Parte 2) e a FinOps (Parte 3) quando si abbatte il muro tra l'applicazione operativa e la piattaforma dati.
La Configurazione: Puntare Backstage a Lakebase
Lakebase espone una superficie Postgres serverless (sfruttando l'architettura di Neon sotto il cofano) che risiede all'interno della Databricks Platform. Poiché parla Postgres con protocollo wire, Backstage non sa né si preoccupa di non stare comunicando con RDS.
Per collegarlo è stato necessario puntare app-config.yaml a Lakebase e sostituire la ricerca in-memory predefinita di Backstage con PgSearchEngine. Un ostacolo immediato: Lakebase rifiuta i classici Databricks Personal Access Token, aspettandosi invece un OAuth JWT. La CLI fornisce databricks postgres generate-database-credential che genera un JWT limitato e di breve durata per un endpoint specifico, l'approccio previsto per app e CI. Per questo POC, abbiamo incapsulato quel comando in uno script cron leggero che riscriveva il DATABRICKS_TOKEN nel nostro file .env ogni 50 minuti per gestire la scadenza del token.
Una volta risolta l'autenticazione, le migrazioni Knex sono state eseguite correttamente e il portale era online.
Il Branching Cambia il Ciclo di Sviluppo del Database
La cosa più sottovalutata di un Postgres tradizionale non è il suo set di funzionalità; è il ritmo che impone ai team che lo gestiscono.
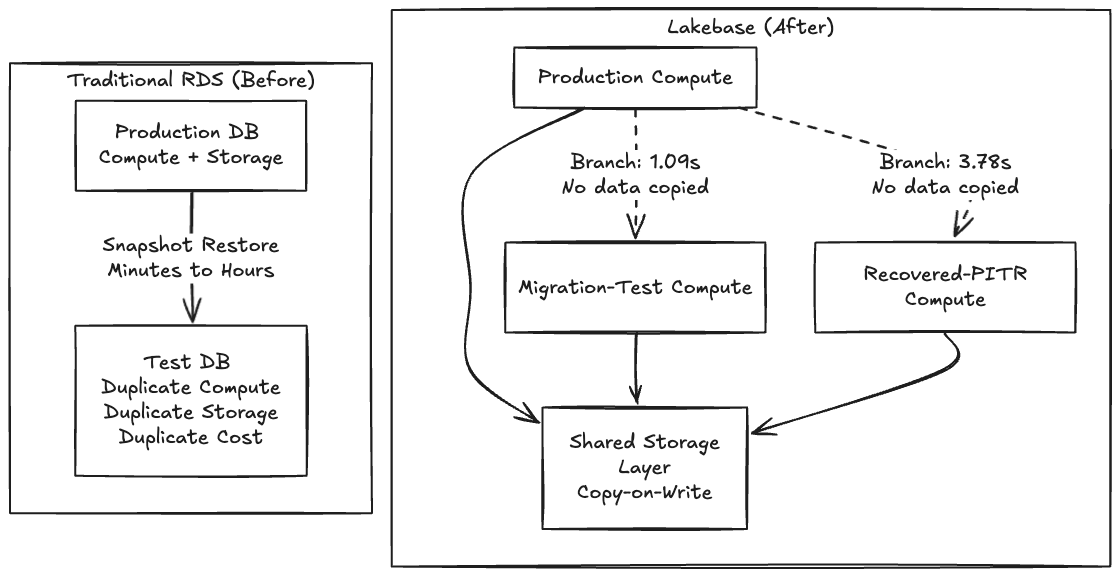
Thoughtworks è un sostenitore costante di Backstage come fondamento per gli IDP attraverso il Technology Radar, quindi, oltre ad avere molta familiarità con lo strumento, abbiamo scelto Backstage per questo POC perché le sue migrazioni di schema sono notoriamente fragili e sembrava un'opportunità perfetta per testare un'integrazione con Lakebase. Su RDS tradizionale, testare una migrazione rischiosa significa attendere minuti o ore per ripristinare uno snapshot su un'istanza parallela. Poiché creare una copia è lento e costoso, i team semplicemente non testano. Incrociano le dita ed eseguono la migrazione durante una finestra di manutenzione.
Quando creare una copia diventa gratuito, smetti di chiedere "questa modifica è abbastanza sicura da eseguire?" e inizi a chiedere "quale fork di produzione voglio provare per primo?"
Poiché Lakebase separa lo storage dal calcolo utilizzando un'architettura copy-on-write, la creazione di un branch non copia alcun dato, crea un puntatore alle stesse pagine sottostanti e diverge solo in scrittura. Ecco perché l'operazione è istantanea.
Una difficoltà che la documentazione non rende evidente: il corpo della richiesta deve annidare tutto all'interno di un oggetto spec, e devi specificare ttl, expire_time, o no_expiry. Senza ciò, l'API restituisce "Expiration must be specified."
Il piano di controllo lo ha riconosciuto istantaneamente. La copia effettiva del catalogo Backstage da ~63 MB sul piano dati è arrivata in 1,09 secondi.
Ripristino Point-in-Time: Il Pulsante Annulla
Il branching e il ripristino point-in-time (PITR) sono essenzialmente lo stesso primitivo: il branching è solo PITR con source_branch_time = now. Per testare il ripristino con dati realmente eliminati, abbiamo svuotato la nostra tabella final_entities, riducendo il conteggio da 32 a 0.
Abbiamo quindi creato un branch di ripristino da un timestamp catturato secondi prima dell'eliminazione:
Il tempo trascorso end-to-end è stato di 3,78 secondi.
La verifica dei dati ha confermato che il branch ripristinato aveva tutte e 32 le entità; la produzione era ancora a zero, confermando che l'eliminazione era reale e che i branch sono completamente isolati. In particolare, abbiamo richiesto le 22:56:02Z, ma Lakebase si è allineato alle 22:55:50Z, 12 secondi prima, tornando indietro al record WAL più vicino. Questa granularità a livello WAL è un'importante avvertenza per i flussi di lavoro di ripristino sensibili al tempo, ma il ciclo dell'incidente si è comunque concluso in meno di un minuto.
Quando lo stato del database diventa un artefatto economico e facilmente duplicabile invece di un volume EBS da 2 TB, ogni operazione rischiosa ottiene una prova generale e ogni incidente ottiene un annullamento.
Dalla Capacità Infrastrutturale al Flusso di Lavoro dello Sviluppatore
Come dimostrato sopra, ciò prova che il branching del database funziona: una copia in 1 secondo, un ripristino in 4 secondi e un'applicazione reale che non ne percepisce la differenza. Ma c'è un divario tra "il database può fare il branching" e "il mio team fa il branching del database con la stessa naturalezza con cui fa il branching del codice". Colmare questo divario è dove si può realizzare un impatto massiccio sulla produttività degli sviluppatori con guadagni oggettivi.
Abbiamo trascorso gli ultimi mesi lavorando con i team di sviluppo per rispondere a una domanda specifica: cosa succede alla velocità di un team quando il branching del database diventa invisibile – quando non è un comando CLI che esegui, ma qualcosa che accade automaticamente come parte di ciò che già fai nel tuo editor preferito? Sono in corso lavori su un'estensione VS Code/Cursor che sincronizza automaticamente i branch git e database per dimostrarlo, ma gli strumenti sono secondari rispetto a ciò che abilitano.
Cosa Abilita il Branching
Tra i team con cui abbiamo avuto esperienza, il ciclo di sprint senza branching del database si presenta così:
- Creare un branch git per lo sviluppo di funzionalità
- Scrivere oggetti mock per ogni interfaccia del database (MockUserRepository, MockOrderService...) a scopo di test
- Scrivere unit test con un database mockato o in-memory (H2, SQLite)
- Inviare una PR, farla revisionare e unire il codice
- Effettuare il deployment in un ambiente di staging condiviso
- Scoprire che la migrazione dello schema non funziona con dati reali o che la dimensione dei dati è un blocco
- Correggere la migrazione dello schema, effettuare nuovamente il deployment, ripetere
Con la disponibilità della funzionalità di branching dei database, il ciclo di sviluppo delle funzionalità di uno sviluppatore cambia:
- Crea un branch git – un branch del database Lakebase può essere creato automaticamente in meno di 1 secondo
- La tua IDE si connette immediatamente al database del branch reale
- Scrivi codice ed esegui migrazioni contro dati reali del database live dalla prima riga di codice
- Scrivi test di integrazione contro il database reale – non mock del database
- È possibile sperimentare più soluzioni, poiché il rollback delle modifiche al database è banale
- Esegui il push e apri una PR – la CI crea il proprio branch del database, convalida sia il codice che lo schema, pubblica un diff dello schema
- I membri del team QA possono ottenere il proprio branch del database per test distruttivi – può essere resettato in pochi secondi
- Merge – Una volta eseguito il merge, la pipeline CD può eseguire la migrazione degli ambienti upstream come UAT e produzione e ripulire tutti i branch – codice e dati.
Gli oggetti mock scompaiono. Le collisioni di staging scompaiono. Il "funziona sulla mia macchina ma si rompe in staging" scompare, gli sviluppatori ottengono un database live per provare più soluzioni. Le modifiche al database che prima venivano scoperte al momento del deployment vengono ora individuate durante lo sviluppo, dove sono economiche da correggere. Branch istantanei per test di performance, branch isolati e usa e getta per test funzionali e un branch in esecuzione per gli stakeholder UAT diventano banali.
Nella nostra esperienza con più team partner che valutano questo flusso di lavoro, gli oggetti mock rappresentano il 20-30% del codice di test. Non si tratta di copertura dei test, ma di infrastruttura di test. Infrastruttura che nel tempo diverge dal comportamento di produzione, creando una falsa sicurezza. Quando il branching di un database equivalente alla produzione non costa nulla, il mocking diventa la scelta costosa.
La domanda ora è quanto del tuo sprint stai dedicando a soluzioni alternative per un vincolo che non esiste più.
Nella Parte 2 di questa serie, esamineremo cosa succede alla sicurezza e alla conformità quando questo database operativo viene assorbito direttamente in Unity Catalog, il livello di governance unificato di Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.