Best practice per il Model Serving con QPS elevato su Databricks
Potenzia le applicazioni di ML in tempo reale in modo nativo all'interno della Lakehouse
di Tejas Sundaresan, Anshul Gupta, Arjun DCunha e Mike Del Balso
- Il Model Serving supporta endpoint in tempo reale che scalano fino a oltre 300.000 QPS (CPU), con un motore potenziato specializzato per ML in tempo reale a bassa latenza.
- I clienti utilizzano il Model Serving per potenziare applicazioni di ML in tempo reale con QPS elevato come sistemi di raccomandazione, rilevamento di frodi, ricerca e altri casi d'uso.
- Utilizza endpoint ottimizzati per il routing, best practice per gli endpoint e ottimizzazioni lato client per raggiungere target di prestazioni elevate durante il serving dei tuoi modelli.
I clienti si aspettano risposte istantanee in ogni interazione, che si tratti di una raccomandazione elaborata in millisecondi, di un addebito fraudolento bloccato prima che venga autorizzato o di un risultato di ricerca che appare immediato all'utente. Su larga scala, l'offerta di queste esperienze dipende da sistemi di erogazione di modelli che rimangono veloci, stabili e prevedibili anche con un carico sostenuto e irregolare.
Con l'aumento del traffico fino a decine o centinaia di migliaia di richieste al secondo, molti team si trovano ad affrontare la stessa serie di sfide. La latenza diventa incostante, i costi dell'infrastruttura aumentano e i sistemi richiedono una messa a punto costante per gestire picchi e cali della domanda. Diventa anche più difficile diagnosticare gli errori man mano che vengono integrati più componenti, distogliendo i team dal miglioramento dei modelli e concentrandoli invece sul mantenimento dei sistemi di produzione.
Questo post spiega come il Model Serving di Databricks supporta carichi di lavoro in tempo reale con QPS elevato e delinea le best practice concrete che puoi applicare per ottenere bassa latenza, throughput elevato e prestazioni prevedibili in produzione.
Databricks Model Serving: semplice e scalabile per carichi di lavoro a QPS elevato
Databricks Model Serving fornisce un'infrastruttura di serving completamente gestita e scalabile direttamente all'interno della tua lakehouse Databricks. È sufficiente prendere un modello esistente nel registro dei modelli, distribuirlo e ottenere un endpoint REST su un'infrastruttura gestita altamente scalabile e ottimizzata per il traffico a QPS elevato.
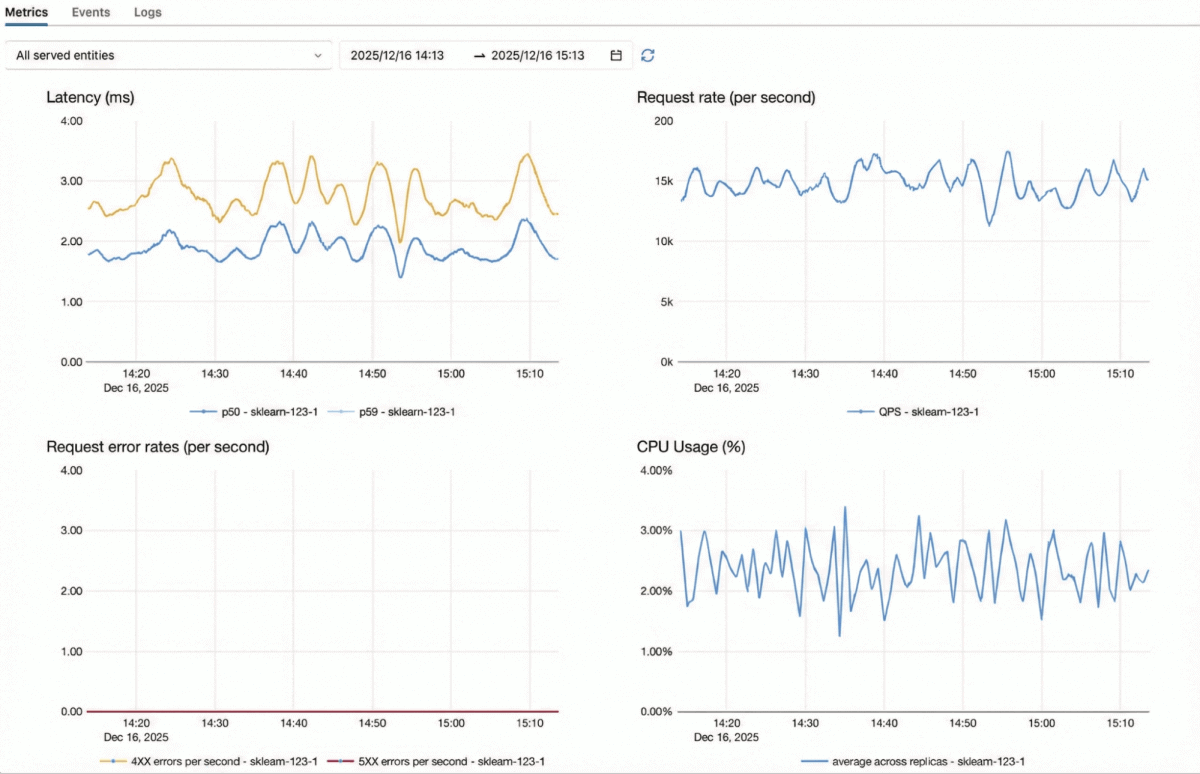
Databricks Model Serving è ottimizzato per carichi di lavoro mission-critical a QPS elevato:
- Motore adattivo in tempo reale – Un server di modelli auto-ottimizzante che si adatta al carico di lavoro di ciascun modello, consentendo un throughput e un utilizzo delle risorse maggiori dallo stesso hardware.
- Architettura completamente scalabile in orizzontale – Il nostro server di inferenza, il livello di autenticazione, il proxy e il limitatore di velocità sono tutti progettati per scalare in orizzontale in modo indipendente, consentendo al sistema di sostenere volumi di richieste molto elevati.
- Scalabilità elastica rapida – I server di inferenza possono aumentare e diminuire di capacità, adattandosi a picchi o cali improvvisi di traffico senza sovra-provisioning.
- Integrazione nativa con il negozio di funzionalità: il Feature Serving di Databricks si integra perfettamente con il Model Serving, consentendoti di implementare funzionalità e modelli insieme come un'unica applicazione completa.
- Nativo per Lakehouse: i clienti possono centralizzare funzionalità, addestramento, MLOps tramite MLFlow, erogazione e monitoraggio in tempo reale dei propri sistemi di ML di produzione in un unico stack unificato, riducendo la complessità operativa e velocizzando le distribuzioni.
Il Model Serving di Databricks consente al nostro team di implementare modelli di machine learning con l'affidabilità e la scalabilità necessarie per le applicazioni in tempo reale. È progettato per gestire carichi di lavoro con QPS elevato, massimizzando al contempo l'utilizzo dell'hardware. Inoltre, Databricks fornisce una soluzione di negozio di funzionalità SOTA con ricerche superveloci necessarie per tali carichi di lavoro. Con queste funzionalità, i nostri ingegneri di ML possono concentrarsi su ciò che conta: perfezionare le prestazioni del modello e migliorare l'esperienza utente. —Bojan Babic, Ingegnere di ricerca, You.com
Best practice per ottenere prestazioni a QPS elevato con il Model Serving
Una volta gettate queste basi, il passo successivo è ottimizzare gli endpoint, i modelli e le applicazioni client per ottenere costantemente un throughput elevato e una bassa latenza, specialmente con l'aumento del traffico. Le seguenti best practice supportano implementazioni reali per i clienti che eseguono da milioni a miliardi di inferenze ogni giorno.
Consulta la nostra guida alle best practice per maggiori dettagli.
Best practice 1: riduzione della latenza tramite l'utilizzo di endpoint con ottimizzazione del percorso
Un primo passo fondamentale per garantire che il livello di rete sia ottimizzato per un throughput/QPS elevato e una bassa latenza. Model Serving esegue questa operazione per te tramite endpoint ottimizzati per il routing. Quando si abilita l'ottimizzazione del percorso su un endpoint, Databricks Model Serving ottimizza la rete e il routing per le richieste di inferenza, consentendo una comunicazione più rapida e diretta tra il client e il modello. Ciò riduce significativamente il tempo necessario affinché una richiesta raggiunga il modello ed è particolarmente utile per applicazioni a bassa latenza come i sistemi di raccomandazione, la ricerca e il rilevamento di frodi.

{kind=link}
Best Practice 2: Ottimizzare il modello e rendere efficienti gli endpoint
In scenari a throughput elevato, ridurre la complessità del modello, scaricare l'elaborazione dall'endpoint di serving e scegliere i target di concorrenza giusti aiuta il tuo endpoint a Scale verso volumi di richieste elevati con la giusta quantità di compute necessaria. In questo modo i tuoi endpoint sono efficienti in termini di costi, ma possono comunque essere scalati per raggiungere gli obiettivi di prestazione.
- Dimensioni e complessità del modello: i modelli più piccoli e meno complessi comportano generalmente tempi di inferenza più rapidi e un QPS più elevato. Prendi in considerazione tecniche come la quantizzazione del modello o il pruning se il modello è di grandi dimensioni.
- Pre-elaborazione e post-elaborazione: scarica le fasi complesse di pre-elaborazione e post-elaborazione dall'endpoint di serving, ove possibile. Ciò garantisce che il tuo endpoint di model serving esegua solo il passaggio cruciale dell'inferenza.
- Scalabilità: configura i tuoi limiti di concorrenza con provisioning in base ai requisiti di QPS e latenza previsti. Ciò garantisce che l'endpoint sia sufficiente per gestire il carico di base e che il massimo consenta di gestire i picchi di domanda.
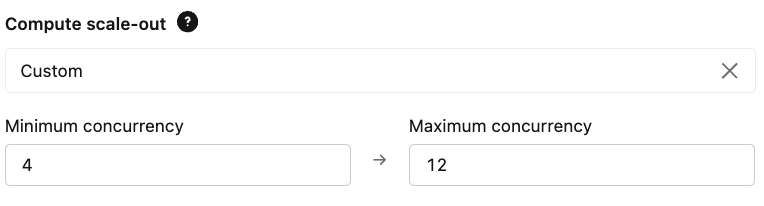
{kind=link}
Con il Model Serving di Databricks, possiamo gestire carichi di lavoro ad alto QPS come la personalizzazione e i consigli in tempo reale. Offre ai nostri brand la Scale e la velocità necessarie per fornire esperienze di contenuti su misura ai nostri milioni di lettori. —Oscar Celma, SVP of Data Science e Analitiche di prodotto di Conde Nast
Best practice 3: ottimizzare il codice lato client
L'ottimizzazione del codice lato client garantisce che le richieste vengano elaborate rapidamente e che le istanze di compute dell'endpoint siano completamente utilizzate, consentendo di ottenere un migliore throughput QPS, risparmi sui costi e una minore latenza.
- Pooling delle connessioni: utilizza il pooling delle connessioni sul lato client per ridurre l'overhead derivante dalla creazione di nuove connessioni per ogni richiesta. L'SDK di Databricks utilizza sempre le best practice per la connessione, tuttavia, se devi utilizzare un client personalizzato, presta attenzione alla strategia di gestione della connessione.
- Dimensioni del payload: mantenere i payload di richiesta e risposta più piccoli possibile per ridurre al minimo il tempo di trasferimento sulla rete.
- Batching lato client: se la tua applicazione può inviare più richieste in una singola chiamata, abilita il batching lato client. Questo può ridurre in modo significativo l'overhead per ogni previsione.
Inviare richieste in batch quando si chiamano gli endpoint di Model Serving di Databricks
Comincia oggi
- Prova il Model Serving di Databricks! Inizia a implementare i modelli di ML come API REST.
- Per saperne di più: consulta la documentazione di Databricks sul Custom Model Serving.
- Guida per QPS elevati: consulta la guida alle best practice per il serving con QPS elevato con il Model Serving di Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.