Puntatori BI Serving; Massimizzazione per Prestazioni e TCO
Una guida dal basso verso l'alto allo stack di serving BI di Databricks — dal layout fisico alle metriche governate alla materializzazione consapevole degli aggregati
- Struttura il tuo livello fisico con schemi a stella, clustering liquido e Ottimizzazione Predittiva per accelerare le query BI.
- Definisci le metriche di business governate una sola volta con le Viste Metriche di Unity Catalog — un livello semantico headless che serve ogni strumento BI, spazio Genie e agente AI da un'unica fonte di verità.
- Abilita la materializzazione consapevole degli aggregati per ottenere prestazioni pre-aggregate in stile OLAP senza costruire e mantenere tabelle aggregate separate.
I tuoi dashboard di BI sono lenti e ottimizzarli ti costa troppo tempo e denaro.
È uno schema familiare. Una query del dashboard richiede 30 secondi, quindi qualcuno crea una tabella aggregata per velocizzarla. Quella tabella necessita di una pipeline di aggiornamento. La pipeline necessita di monitoraggio. Quindi un secondo strumento di BI necessita degli stessi dati in una forma leggermente diversa, quindi qualcuno crea un'altra tabella aggregata utilizzando una pipeline separata. In breve tempo, ti ritrovi a gestire una proliferazione di aggregati, estrazioni e layer semantici specifici per lo strumento, ognuno con la propria finestra di obsolescenza, i propri gap di governance e la propria voce nella fattura di calcolo.
I carichi di lavoro di BI sono diversi dagli altri carichi di lavoro analitici. Sono altamente concorrenti, sensibili alla latenza e ripetitivi nei loro pattern di query. Questa combinazione richiede un approccio deliberato alla modellazione, archiviazione, ottimizzazione e servizio dei dati. La buona notizia: Databricks fornisce uno stack completo per il servizio di BI, dal layout fisico dei dati a un layer semantico governato, e ogni layer amplifica i guadagni di performance del layer sottostante.
Questo post illustra lo stack dal basso verso l'alto, con indicazioni pratiche su dove concentrarsi per i maggiori miglioramenti nelle performance delle query e nei costi.
Lo Stack di Servizio BI
Prima di approfondire ogni layer, ecco il quadro completo:
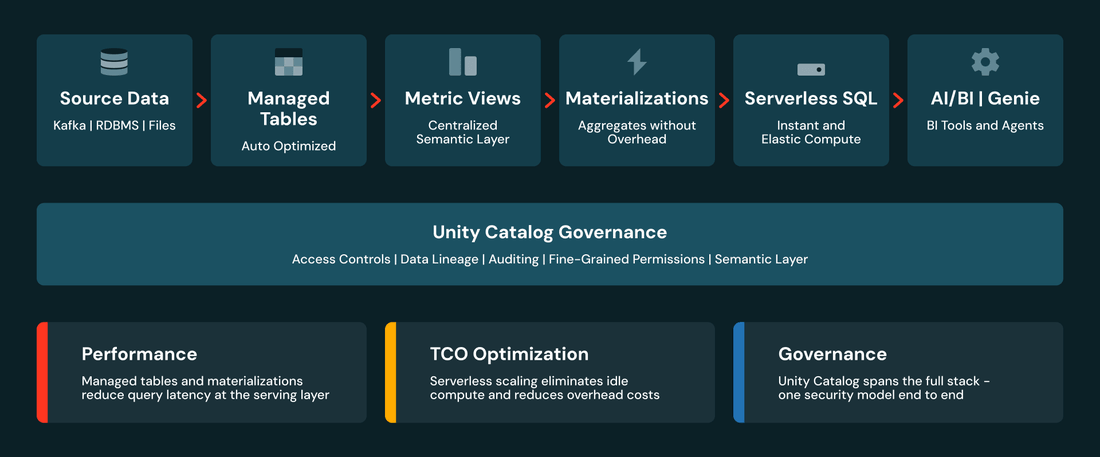
Unity Catalog fornisce governance in tutto il processo: lineage e controllo degli accessi dai dati grezzi attraverso la semantica fino al consumo. Ogni layer affronta un aspetto diverso di performance e costo. Analizziamoli.
Ottimizzare il Layer Fisico
Il layer fisico è dove la maggior parte delle performance di BI viene vinta o persa. Se lo fai bene, ogni query ne beneficia, prima ancora di aver toccato il layer semantico.
Inizia con la Modellazione Dimensionale
Gli schemi a stella rimangono il gold standard per le performance delle query di BI. Tabelle dimensionali ampie e denormalizzate unite a tabelle dei fatti tramite chiavi surrogate offrono all'ottimizzatore di query percorsi di join puliti e prevedibili.
Databricks supporta pienamente i costrutti di modellazione relazionale di cui hai bisogno: vincoli di chiave primaria e esterna (con RELY per hint all'ottimizzatore), colonne identity per chiavi surrogate e vincoli CHECK e NOT NULL. Se stai seguendo un'architettura medallion, mantieni i tuoi modelli normalizzati o Data Vault in Silver e crea schemi a stella denormalizzati in Gold per il consumo di BI.
Per schemi di implementazione dettagliati — gestione SCD Type-1 e Type-2, ETL di tabelle dei fatti con MERGE, dimensioni che arrivano in ritardo — consulta la serie di blog Implementing a Dimensional Data Warehouse in Databricks SQL.
Usa Tabelle Gestite
Le tabelle gestite di Unity Catalog sono il fondamento per tutto il resto in questo stack. Unity Catalog gestisce tutte le responsabilità di lettura, scrittura, archiviazione e ottimizzazione per le tabelle gestite. Questo sblocca funzionalità automatiche che non ottieni con le tabelle esterne: Predictive Optimization (trattato di seguito) è abilitato per impostazione predefinita. Il clustering liquido automatico seleziona chiavi di clustering che si adattano al variare dei pattern di query. La cache dei metadati è sempre attiva, riducendo le richieste di archiviazione cloud e velocizzando la pianificazione delle query.
Usa tabelle gestite in tutta la piattaforma, non solo per il servizio di BI, ma attraverso i layer Bronze, Silver e Gold. Sono il tipo di tabella predefinito in Unity Catalog e i benefici di performance e governance si accumulano con ogni altra ottimizzazione in questo stack.
Applica il Clustering Liquido
Liquid clustering sostituisce il partizionamento statico e il Z-ORDER manuale — e a differenza di questi approcci, puoi ridefinire le chiavi di clustering senza riscrivere i dati esistenti. Aggiungi CLUSTER BY (col1, col2) alla creazione della tabella o usa ALTER TABLE su tabelle esistenti. Se non sei sicuro di quali colonne scegliere, CLUSTER BY AUTO consente a Predictive Optimization di selezionare le chiavi in base ai pattern di query osservati.
Per i carichi di lavoro di BI, esegui il clustering sulle colonne di filtro e join più comuni: chiavi data, regione, categoria di prodotto. Puoi selezionare fino a quattro colonne e, se due colonne sono altamente correlate, includine solo una. Quando i dashboard filtrano sulle colonne di clustering, il clustering liquido migliora le performance delle query tramite lo skipping dei dati.
Lascia che Predictive Optimization Gestisca il Resto
Predictive Optimization esegue automaticamente OPTIMIZE, VACUUM e la raccolta di statistiche sulle tabelle che trarrebbero beneficio da queste operazioni, quindi non è necessario pianificare questi job da soli. Raccoglie statistiche di skipping dei dati Delta e statistiche dell'ottimizzatore di query durante le scritture Photon, e riempie le statistiche per le tabelle esistenti. Nei carichi di lavoro osservati, questo ha fornito un miglioramento medio delle performance del 22%. Per i carichi di lavoro di BI con pattern di filtro ripetitivi, l'impatto è particolarmente significativo: statistiche migliori significano migliore skipping dei dati e piani di query più efficienti.
Abilita Predictive Optimization a livello di catalogo e lascialo funzionare. L'uso di Predictive Optimization è una delle ottimizzazioni a più alto rendimento e minor sforzo che puoi fare.
Il risultato: le query di BI scansionano meno dati, eseguono join in modo più efficiente e costano meno per l'esecuzione, e non hai ancora toccato il layer semantico.
Metric Views: Definisci le Tue Metriche Una Volta
Qui le cose si fanno interessanti. La maggior parte delle organizzazioni ha le stesse metriche di business definite in più posti: un calcolo dei ricavi in uno strumento di BI, uno leggermente diverso in un altro, una terza variante in una notebook SQL che qualcuno ha scritto il trimestre scorso. Ogni definizione diverge indipendentemente. Nessuno è sicuro di quale sia quella giusta.
Metric Views in Unity Catalog risolvono questo problema fornendo un layer BI headless: un layer semantico singolo e governato dove definisci il tuo modello dati e i KPI una volta, indipendentemente da qualsiasi strumento di BI specifico. Li definisci centralmente in SQL o nell'interfaccia utente point-and-click in Unity Catalog Explorer. AI/BI Dashboards, Genie, notebook SQL e strumenti di BI di terze parti risolvono le metriche dalle stesse definizioni. Definisci una metrica una volta e ogni consumatore, umano o AI, ottiene la stessa risposta.
Metric Views vanno oltre le definizioni centralizzate delle metriche: i metadati semantici sono ciò che le distingue. Campi come display_name, comment e synonyms forniscono ai sistemi AI il contesto necessario per interpretare correttamente le domande di business. Quando un utente chiede a Genie "qual è stato il nostro fatturato la scorsa settimana?", quelle annotazioni sono il modo in cui Genie mappa il linguaggio naturale alla metrica e alle dimensioni corrette. Nessun prompt personalizzato, nessun glossario separato. Lo stesso vale per gli agenti AI basati su Databricks: qualsiasi agente con accesso a Unity Catalog può scoprire e interrogare metriche governate attraverso il layer semantico invece di SQL codificato. Più ricchi sono i tuoi metadati, più accuratamente l'AI fornisce la risposta giusta.
Ecco un esempio che utilizza una tabella di sistema, poiché ogni cliente Databricks ha accesso, ma lo stesso schema si applica ai KPI di business come ricavi, volume ordini o fidelizzazione clienti. Questa Metric View calcola le metriche del warehouse DBSQL:
I consumatori interrogano la Metric View utilizzando MEASURE() per fare riferimento alle definizioni delle metriche governate:
Le metriche sono definite una volta nella Metric View. Ogni dashboard, spazio Genie o notebook che interroga metv_dbsql_metrics ottiene lo stesso risultato. Di seguito è riportato un dashboard che utilizza la vista metrica come sorgente.
Ecco Genie che utilizza la stessa vista delle metriche.
Per i team con definizioni di metriche sparse in più strumenti di BI, le Viste Metriche (Metric Views) offrono un modo per consolidare il livello semantico in Databricks. Invece di mantenere logiche di metriche separate in ogni strumento, le definisci una volta in Unity Catalog e colleghi i tuoi strumenti di BI a quella origine governata.
L'implementazione principale è open-source in Apache Spark™ (SPARK-54119), con supporto OSS per Unity Catalog in arrivo — così stai costruendo su uno standard aperto senza vendor lock-in. Tale apertura è ancora più importante man mano che l'AI si assume più carico di lavoro di BI. Gli agenti che interrogano i tuoi dati necessitano di una definizione coerente e leggibile dalla macchina di cosa significa ogni metrica, e uno standard aperto consente a qualsiasi strumento o agente — non solo quelli specifici del fornitore — di ragionare sulle stesse metriche governate.
Materializzazione delle Viste Metriche: Prestazioni OLAP Senza Sovraccarico
Tradizionalmente, quando le dashboard di BI erano troppo lente, la soluzione era costruire tabelle aggregate. Creavi viste materializzate o tabelle di pre-aggregazione personalizzate sopra il tuo schema a stella, impostavi pipeline di aggiornamento e reindirizzavi i tuoi strumenti di BI alle nuove tabelle. Funzionava, ma aggiungeva un intero livello di oggetti e pipeline da mantenere — e ogni volta che la logica di aggregazione cambiava, dovevi aggiornare le query dello strumento di BI per farle corrispondere.
La materializzazione delle Viste Metriche offre un'alternativa più semplice. Quando abiliti la materializzazione su una Vista Metrica, la piattaforma mantiene automaticamente i risultati pre-aggregati dietro le stesse definizioni di metriche che gli strumenti di BI già interrogano — nessuna tabella aggregata separata da costruire, nessuna query dello strumento di BI da rifattorizzare. Ecco cosa succede sotto il cofano:
- Pre-aggregazione automatica: I risultati delle metriche vengono pre-calcolati e archiviati
- Aggiornamento incrementale: Le metriche rimangono aggiornate senza ri-calcolo completo
- Riscrittura intelligente delle query: Il motore instrada le query alla migliore materializzazione disponibile
- Instradamento trasparente: Gli utenti interrogano le metriche allo stesso modo — il sistema fornisce il percorso più veloce
Le query delle dashboard che in precedenza scansionavano tabelle di fatti complete ora accedono a materializzazioni pre-aggregate — con latenza inferiore e costi di calcolo inferiori. Gli esempi di dashboard e Genie sopra hanno entrambi interrogato la stessa Vista Metrica, e a entrambi è stato instradato in modo trasparente il percorso di query a una materializzazione. Il piano di query seguente da Genie mostra questo in azione.
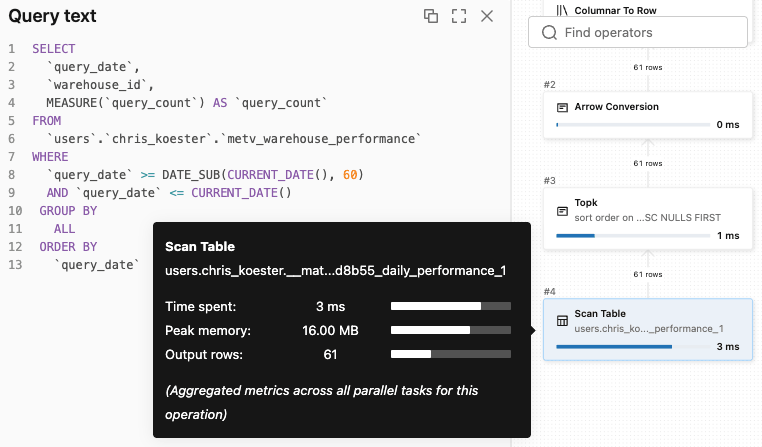
Puntatori Pratici sul TCO
Query più veloci e costi inferiori non sono obiettivi in competizione — ogni ottimizzazione che riduce i dati scansionati riduce anche il calcolo per cui paghi. E ogni ottimizzazione nello stack si accumula. Il clustering liquido (Liquid clustering) e statistiche migliori migliorano lo skipping dei dati e i piani di query. Le materializzazioni possono essere aggiornate in modo incrementale, riducendo il calcolo che i warehouse SQL necessitano per servire le dashboard. Ecco alcuni altri modi per ridurre i costi:
- Dimensiona correttamente il tuo warehouse SQL. Utilizza warehouse SQL serverless con auto-scaling per i picchi di concorrenza di BI. Paghi per ciò che usi, non per la capacità di picco.
- Sfrutta i livelli di caching di DBSQL. La cache su disco mantiene i dati "caldi" localmente al warehouse, e la cache dei risultati delle query (QRC) serve query ripetute senza ri-esecuzione. Per le dashboard con pattern di query coerenti, il caching trasforma molte richieste in risposte a latenza di millisecondi a costi di calcolo quasi nulli.
- Elimina il movimento ridondante dei dati. Servi la BI direttamente dal lakehouse tramite DirectQuery o connessioni live, invece di usare estratti o importazioni.
- Monitora con le tabelle di sistema. Tabelle di sistema come
system.billing.usageesystem.query.historypossono essere utilizzate per tracciare l'utilizzo della BI per dashboard, utente e warehouse. Costruisci Viste Metriche e una Dashboard AI/BI sulle tabelle di sistema per ottenere visibilità sull'utilizzo della tua BI.
Inizia
Non è necessario implementare l'intero stack contemporaneamente. Inizia da dove vedrai il maggior impatto:
- Costruisci (o convalida) il tuo schema a stella di livello Gold con tabelle gestite, chiavi primarie/esterne e clustering liquido
- Abilita Predictive Optimization sul tuo catalogo per gestire automaticamente
OPTIMIZE,VACUUMe la raccolta di statistiche - Definisci Viste Metriche per i tuoi KPI aziendali principali — inizia con SQL o l'interfaccia utente di UC Explorer
- Abilita la materializzazione delle Viste Metriche per le tue metriche più trafficate
- Monitora i risultati — punta le dashboard alle Viste Metriche e traccia le prestazioni delle query tramite le tabelle di sistema
Databricks fornisce ottimizzazioni ad ogni livello dello stack di serving BI. Le tabelle gestite, il clustering liquido e Predictive Optimization minimizzano i dati scansionati e il calcolo speso. Le Viste Metriche centralizzano la tua logica aziendale in un livello semantico governato che serve dashboard, Genie e agenti AI in modo coerente. La materializzazione offre prestazioni di query sub-secondo senza pipeline di pre-aggregazione manuali. Insieme, questi livelli si accumulano — riducendo sia la latenza delle query che il costo totale di proprietà.
Inizia definendo la tua prima Vista Metrica su una tabella di livello Gold esistente e abilitando la materializzazione. Consulta le risorse qui sotto per iniziare.
- Panoramica delle Viste Metriche di Unity Catalog
- Visualizzazione delle Viste Metriche in AI/BI
- Interrogazione delle Viste Metriche da un Editor SQL
- Implementazione di un Data Warehouse Dimensionale in Databricks SQL
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.