Implementazione di un data warehouse dimensionale con Databricks SQL: Parte 1
Definizione degli oggetti dati
di Bryan Smith, Lorenz Verzosa, Krishna Satyavarapu, Peyman Mohajerian e Jesse Heravi
- Implementa data warehouse dimensionali in Databricks SQL per ottimizzare le prestazioni delle query.
- La struttura del modello fisico in Databricks SQL, inclusa la creazione di tabelle dimensionali e di fatti, viene eseguita con istruzioni SQL CREATE TABLE.
- È importante aggiungere commenti descrittivi a tabelle e colonne per una migliore gestione dei metadati.
Sempre più organizzazioni stanno spostando i loro carichi di lavoro di data warehouse su Databricks. La natura elastica della piattaforma e i significativi miglioramenti al suo motore di esecuzione delle query hanno permesso a Databricks di stabilire record mondiali sia per le prestazioni delle query di data warehouse che per le prestazioni in termini di costi, rendendola un'opzione sempre più interessante per il consolidamento dell'infrastruttura di analisi.
Per supportare questi sforzi, in precedenza abbiamo pubblicato articoli su come Databricks supporta vari approcci di progettazione di data warehouse. In questa serie di articoli, vogliamo esaminare più da vicino uno degli approcci più popolari al data warehousing, la modellazione dimensionale, un modello di progettazione caratterizzato da star- e snowflake schemas, e approfondire i modelli standardizzati di estrazione, trasformazione e caricamento (ETL) ampiamente adottati a supporto di questo approccio.
Per rendere queste informazioni ampiamente accessibili alla community della modellazione dimensionale, aderiremo strettamente ai modelli classici associati a questo approccio di modellazione. Queste informazioni saranno distribuite nei seguenti articoli:
- Parte 1: Definizione degli Oggetti Dati (Dimensionali) (questo articolo)
- Parte 2: Costruzione dei Workflow ETL per le Dimensioni
- Parte 3: Costruzione dei Workflow ETL per i Fatti
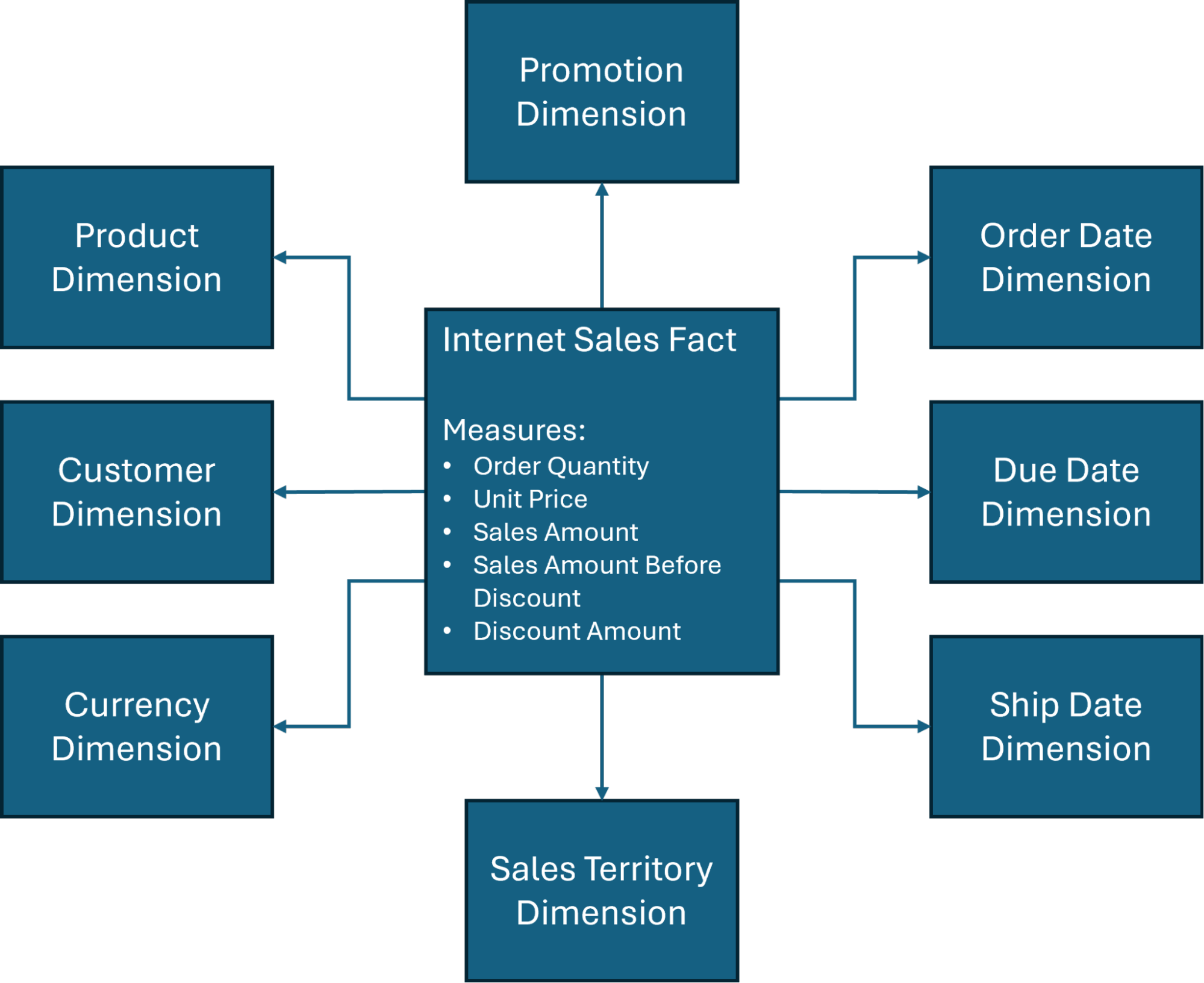
Inoltre, concentreremo le nostre discussioni di progettazione su uno degli schemi a stella più comunemente utilizzati (Figura 1) nel database AdventureWorksDW, un database di esempio creato da Microsoft e ampiamente utilizzato per scopi di formazione su data warehouse e Business Intelligence.
Cos'è la modellazione dimensionale nel data warehousing?
La modellazione dimensionale ottimizza l'archiviazione dei dati per prestazioni di query veloci. Strutturando i dati in fatti e dimensioni, è possibile analizzare facilmente i dati da più prospettive. Permette inoltre di esplorare i dati da varie angolazioni contemporaneamente (analisi multidimensionale).
Quali sono le quattro dimensioni di un data warehouse?
Come indica la Figura 1, ci sono diverse dimensioni coinvolte nello schema a stella del data warehousing, ma le quattro dimensioni principali del data warehousing includono tipicamente le seguenti:
Tempo: Questo fornisce un quadro di tracciamento storico ed è essenziale per valutare trend o condurre confronti. È possibile categorizzare i dati in base a intervalli di tempo specifici – giorni, settimane, anni – per ottimizzare i cambiamenti stagionali del business o la gestione dell'inventario.
Cliente: Le organizzazioni necessitano di insight accurati su chi sta acquistando i loro prodotti. Informazioni come nome, informazioni di contatto e dati demografici possono offrire una segmentazione di mercato utile e determinare decisioni come la spesa pubblicitaria o le strategie di marketing complessive.
Prodotto: Questa dimensione definisce quali beni o servizi vengono analizzati e può essere utile per condurre un'analisi delle prestazioni per determinare quanto viene venduto, il tasso di vendita e le opportunità di crescita futura.
Posizione: Contestualizzare dove si sono verificati gli eventi – geograficamente o operativamente – può aiutare le organizzazioni a prendere decisioni critiche basate su dove è probabile che risiedano i loro clienti.
Il modello fisico
All'interno della Piattaforma Databricks, fatti e dimensioni sono implementati come tabelle fisiche. Queste sono organizzate all'interno di cataloghi, simili ai database, ma con maggiore flessibilità per l'ampiezza degli asset informativi supportati dalla piattaforma. I cataloghi sono poi suddivisi in schemi, creando confini logici e di sicurezza attorno a sottoinsiemi di oggetti nel catalogo (Figura 2).
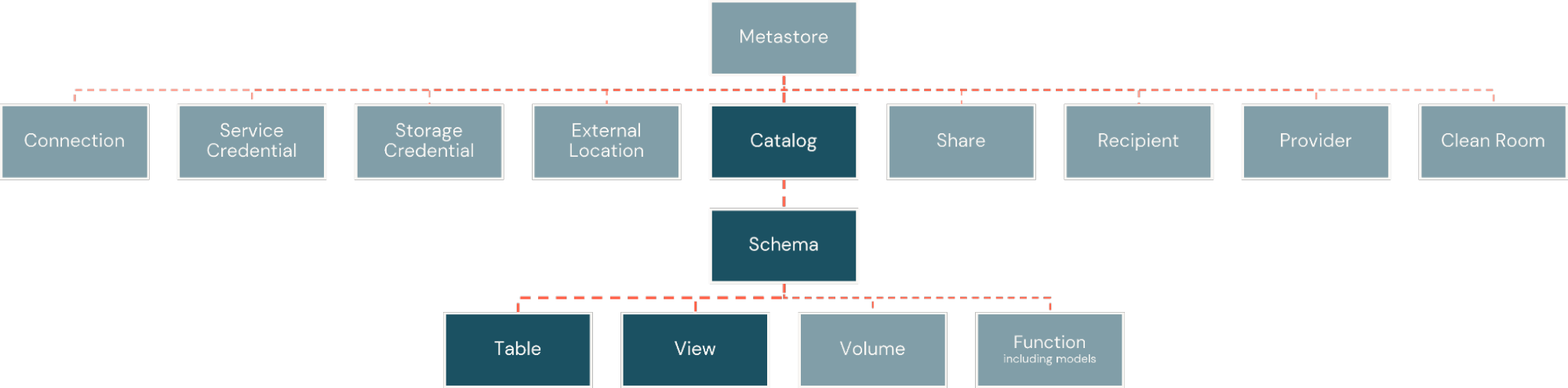
Tabelle delle dimensioni
Le tabelle delle dimensioni aderiscono a un insieme relativamente rigido di modelli strutturali. Un identificatore sequenziale, una chiave surrogata, è tipicamente definita per supportare un collegamento stabile ed efficiente tra le tabelle dei fatti e la dimensione. Seguono solitamente identificatori univoci dai sistemi operativi (spesso definiti chiavi naturali o chiavi di business), insieme a una raccolta denormalizzata di attributi di business correlati. Dietro gli identificatori ci sono solitamente una serie di colonne di metadati destinate a supportare i processi ETL in corso. All'interno della Piattaforma Databricks, possiamo implementare una tabella delle dimensioni utilizzando l'istruzione CREATE TABLE, come mostrato qui per la dimensione cliente:
Colonne identity
In questo esempio, per la colonna della chiave surrogata, CustomerKey, utilizziamo una colonna identity che crea automaticamente un valore BIGINT sequenziale per il campo durante l'inserimento delle righe. Se utilizziamo l'opzione ALWAYS o BY DEFAULT con la colonna identity, dipende se vogliamo proibire o consentire l'inserimento dei nostri valori per questo campo.
Voce membro mancante
Un pattern comune implementato con le tabelle dimensionali è la creazione di una voce membro mancante. Questa voce viene utilizzata in scenari in cui i record fattuali arrivano con un collegamento mancante o sconosciuto a una dimensione e possono essere creati con un valore di chiave surrogata predeterminato, come mostrato qui quando viene utilizzata l'opzione BY DEFAULT:
Campi identity
Come best practice, quando si inseriscono valori in un campo identity, è meglio assicurarsi che i metadati del campo identity vengano aggiornati tramite un'istruzione ALTER TABLE con l'opzione SYNC IDENTITY:
Tipi di dati
Per la chiave di business/naturale e altri campi collegati ai dati nei sistemi sorgente, dovremo allineare i tipi di dati dei sistemi sorgente con i tipi di dati supportati dalla Databricks Platform (Tabella 1). Per i campi di metadati in cui viene utilizzato un valore bit, come 0 o 1, si noti che spesso utilizziamo un tipo di dati INT invece dei tipi di dati BOOLEAN o TINYINT per semplificare un po' la gestione dei letterali.
|
BIGINT |
DECIMAL |
INTERVAL |
TIMESTAMP |
MAP |
|
BINARY |
DOUBLE |
VOID |
TIMESTAMP_NTZ |
STRUCT |
|
BOOLEAN |
FLOAT |
SMALLINT |
TINYINT |
VARIANT |
|
DATE |
INT |
STRING |
ARRAY |
OBJECT |
Tabella 1. I tipi di dati supportati dalla Databricks Platform
Tabelle fattuali
Anche le tabelle fattuali seguono le loro convenzioni strutturali. Composte principalmente da misure e riferimenti a chiavi esterne a dimensioni correlate, le tabelle fattuali possono includere anche identificatori univoci per i record transazionali (o altri attributi descrittivi in una relazione quasi uno a uno con i record fattuali), definiti dimensioni degenerate. Possono anche includere campi di metadati per supportare il caricamento incrementale (alias estrazione delta) dei dati dai sistemi sorgente. All'interno della Databricks Platform, potremmo implementare una tabella fattuale utilizzando l'istruzione CREATE TABLE simile a quanto mostrato qui per la tabella fattuale delle vendite Internet:
Foreign key references
Come accennato nella sezione precedente sulle tabelle delle dimensioni, i tipi di dati nell'ambiente Databricks sono mappati in modo flessibile a quelli utilizzati dai sistemi sorgente. I riferimenti alle chiavi esterne tra le tabelle dei fatti e delle dimensioni possono anche essere resi espliciti utilizzando l'istruzione ALTER TABLE come mostrato qui:
Note: Se preferisci definire i vincoli di chiave esterna come parte dell'istruzione CREATE TABLE, puoi semplicemente aggiungere un elenco separato da virgole di clausole FOREIGN KEY (nella forma FOREIGN KEY (foreign_key) REFERENCES table_name (primary_key) subito dopo l'elenco delle definizioni delle colonne.
Metadati e altre considerazioni
Il fascino del modello dimensionale risiede nella sua relativa accessibilità per gli analisti aziendali. Tenendo presente questo, molte organizzazioni adottano convenzioni di denominazione per fatti e dimensioni, come i prefissi Fact e Dim negli esempi precedenti, e incoraggiano l'uso di nomi lunghi e autoesplicativi per tabelle e campi che spesso deviano significativamente dai nomi utilizzati nei sistemi operativi sorgente.
Tenendo conto di ciò, è importante notare i limiti di Databricks sulla denominazione degli oggetti. Questi includono:
- I nomi degli oggetti non possono superare i 255 caratteri
- I seguenti caratteri speciali non sono consentiti:
- Punto (.)
- Spazio ( )
- Barra (/)
- Tutti i caratteri di controllo ASCII (00-1F hex)
- Il carattere DELETE (7F hex)
Inoltre, è importante notare che i nomi degli oggetti non sono sensibili alle maiuscole e sono, di fatto, memorizzati nel repository dei metadati in minuscolo. Se ciò potesse creare problemi di leggibilità degli oggetti, potresti considerare l'adozione di una convenzione snake case per migliorare la leggibilità di alcuni nomi di oggetti.
Indipendentemente dalle tue convenzioni di denominazione, è una buona idea definire commenti descrittivi per tutti gli oggetti e i campi all'interno del data warehouse. Questo viene fatto tramite l'uso dell'istruzione COMMENT ON per gli oggetti tabella e l'istruzione ALTER TABLE per i singoli campi, come dimostrato qui:
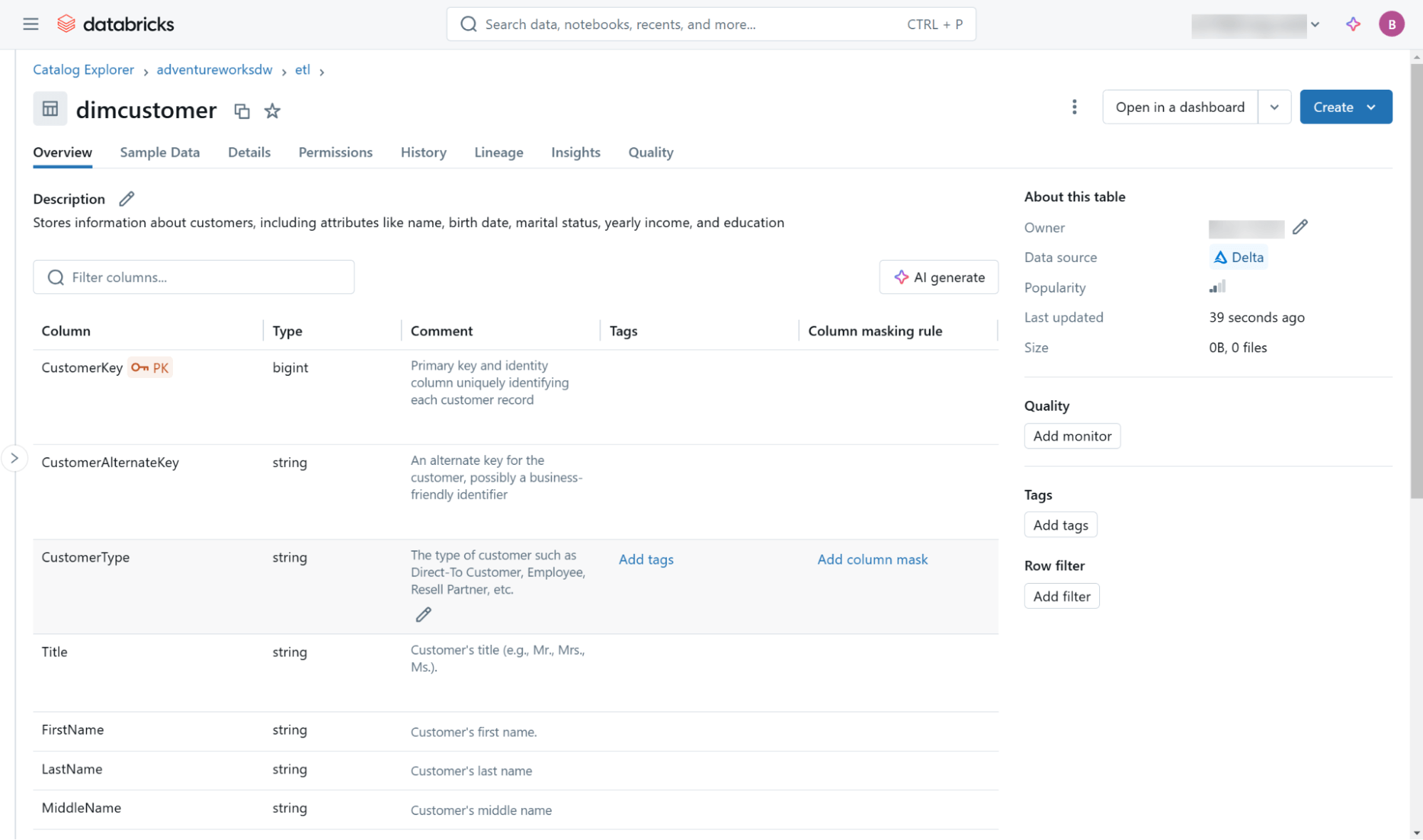
Questi e altri metadati (incluse le informazioni sulla lineage) sono accessibili tramite l'interfaccia utente Databricks Catalog Explorer (Figura 3) e tramite oggetti nello schema delle informazioni integrato presente in ogni catalogo.
Infine, questo blog affronta la creazione di tabelle di fatti e dimensioni puramente dalla prospettiva dell'adesione ai principi di progettazione dimensionale. Se desideri esplorare alcune opzioni aggiuntive per la definizione delle tabelle che considerano ottimizzazioni di prestazioni e manutenzione, consulta questo blog sull'ottimizzazione delle prestazioni dello schema a stella.
Passaggi successivi: implementazione dell'ETL della tabella delle dimensioni
Dopo aver affrontato le basi della creazione di tabelle di fatti e dimensioni, nel prossimo blog ci concentreremo sull'implementazione dei pattern ETL che supportano le tabelle dimensionali, con particolare attenzione ai pattern di dimensione a variazione lenta (SCD) di tipo 1 e 2 utilizzando sia Python che SQL. Infine, la Parte 3 tratterà come l'ETL per queste tabelle può essere implementato.
Per saperne di più su Databricks SQL, visita il nostro sito web o leggi la documentazione. Puoi anche dare un'occhiata al tour del prodotto per Databricks SQL. Se desideri migrare il tuo data warehouse esistente a un data warehouse serverless ad alte prestazioni con un'ottima esperienza utente e un costo totale inferiore, Databricks SQL è la soluzione: provalo gratuitamente.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.